









where does the error come from?(误差从何而来?)
-
回顾:
上节课说选择不同的Model,在Training Data和Testing Data中有不同的error,而且越复杂的Model不一定会有越小的error
我们本节课要做的就是知道这个error来自什么地方。
其实这个来自两个,一是来自bias偏差,其二是来自variance方差。
-
Estimator估计量:
现在我们已知宝可梦进化后的CP值f^,所以我们可以根据Training Data训练机器找到一个最小的Loss function :f * ,但是 f * 不可能直接与f ^ 相等的,只能说f *是 f ^ 的估计值。就好像打靶,靶中心就是我们已知的宝可梦进化后的CP值f^,可能我们通过训练数据得到的最小的Loss function在如下图靶的一位置上,那么f^和f *中间相隔的error,就是由两件事造成的,一个是bias,一个是variance。

-
举一个概率的例子
现在有一个变量x,现在我想估测他的mean平均值,怎么做?
假设变量x他的平均值是μ,他的方差variance是o²,那要估测x的mean平均值该怎么做呢?
那我们就举例n个点{x1…xN}
再把这个n个点算平均值得到m,那n个点算出的平均值m会和μ一样吗?
很显然,除非取无穷个点,不然是不会等于μ的
但我们可以算一个m的期望值,算很多个m的平均值不一定与u相等,他会散布在μ的周围,但m的期望值会正好等于μ。

那m会在μ的周围散布得多开呢?取决于variance方差
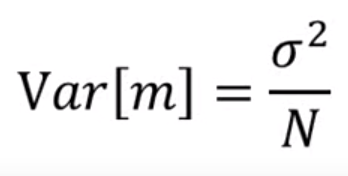
如果取多的N,也就是点的个数,越多,他就会越集中,反正越少就越分散。

-
-
回到Regression回归的问题上来(把求出function比喻成打靶)
比如现在估测的是靶的中心,这是我们的target目标(已知的宝可梦进化后的CP值f^),根据Training Data训练机器找到一个最小的Loss function :f*可能就在如下图的位置,f * 这个位置和红心之间,这个error取决于两件事,第一是瞄准的位置在哪,也就是Estimator估计量:f *是不是bias偏差,那怎么知道Estimator估计量f *是不是bias偏差呢?把这个Estimator估计量f *的期望值算出来就是了。如下图较大蓝色的点就是瞄准的位置,他与靶心之间就是Bias,那么他与原f *点之间就是射出去的偏移(子弹射出去是会有偏移的)Variance方差。所以说error取决于这两件事,bias与variance。

而下图是表示的,偏差bias很大(瞄准的位置与原点位置),但variance方差很小

下图表示的是没有bias偏差,只有variance方差,所以他会落在靶心周围

下图表示的是bias偏差和方差都很小

-
稍微总结一下弹幕
variance就是方差,表示数据的离散程度,越小越聚集。
比如你的Loss function设计的不好,就会有巨大的bias偏差。
-
平行宇宙例子解释说明variance方差和bias偏差
假设现在我在不同的平行宇宙中抓了十只宝可梦作为Training Data训练数据去找到f*(最小的Loss function的值),但在不同宇宙抓到的十只宝可梦都是不一样的。假设我们还是使用同一个Model,就会得到不同的f*。
假设在100个平行宇宙中的model还是y=b+w*xcp ,那么这100个平行宇宙中找到的f*的分布就如下图所示。

但如果换一个model,就得到另一个样子

如果我们看较简单的model找出的f*之间的方差的话,他们与最好的f*是差不多的,简单的model就是比较集中的,他们的Variance方差是比较小的,如果考虑比较复杂的model,他的方差是比较大的。

Bias:假设我们有很多很多的f*,把他们都平均起来,找他的平均值,看他与靶心的接近程度,我们会发现他们跟靶心是有一定距离的。假设靶心f^的曲线如下图曲线。

实验的结果如下图,红色线代表我们取5000次的f*,蓝线表示5000f*的平均值,我们发现蓝线和黑色的曲线还是有一定差距的。

但我们把Model换成较为复杂的三次式,那么他的红线蓝线黑线如下图,会发现取完平均值之后会与靶心更加接近了。

五次曲线平均起来发现更加接近了

所以说如果是一个简单的Model,他会有一个比较大的bias,如果是比较复杂的Model,他的bias会比较小。
我们说我们的model是一个function set ,我们用一个范围来表示这个function set,当我们设定好一个model的时候,我们最好的function就只能从这个function set 里面挑出来,如果是一个简单的model,他的范围是比较小的(在上节课说过,越简单的model是越复杂model的子集),他可能还没有包含你的目标(靶心),如果没有包含你的target,那么再怎么取平均,依然永远取不到target。如果取比较复杂的model的话,那他的范围就很大了,他就很有可能包含我们的target,平均起来就容易取得到。

-
总结结论与解决方案

如上图,横轴1~5代表model的复杂程度,红线代表bias的误差,绿线代表方差的误差,同时被考虑时,就是蓝色的线。
-
比较简单的Model的Bias偏差比较大,但方差Variance比较小
-
比较复杂的Model的Bias偏差比较小,但方差Variance比较大
-
也就是当Model从简单趋向于复杂时,对靶心瞄的越来越准,但他的方差就会越来越大。
-
如果你的Model无法适应训练数据Training Data,那么说明bias大了,也就是代表图中蓝色的点无法适应我的Model,那么说明当前Model和正确的解是有一定的差距的,需要对Model进行改进,叫做Underfitting。
-
如果在Training Data上得到小的Error,但是在Testing Data中得到大的Error这意味着你的Model的variance比较大,代表的就是Overfitting。
-
而应对Underfitting和Overfitting时,如果bias大了,去重新设计Model(比如考虑更多的值)。如果是Variance大了,那就需要增加我们的Data,是很有效控制Variance的方法。如果还不行的话,就加入Regularization
-
所以我们现在遇到的问题就是这样
往往有很多Model需要选择,还有很多参数可以调。
通常我们是在Bias偏差和Variance方差之间做一些平衡。
我们希望找一个Model能让Bias和Variance都够小,合起来给我们最小的Testing Data。
以下的事情是我们不该做的,比如我们现在手上有Training Set和Testing Set。
我现在有三个Model,我分别用三个Model中的每一个,分别去找他的Training data中的error,得到error最小的那个Model就是我们认为的好的。但是我们不能直接用在未知的Testing Set中,因为这个Testing Set的数据他是从来没有见过的,而我们通过Training data选出的Model用在我们自己的Testing Set中虽然是最好的,但自己的Testing Set和完全未知的Testing Set是不同的,最明显的就是他们的bias会有不同。

那怎么做才是比较可靠的?
我们需要把Training Set分为两组,一组是用来train Model,另一组用来选择Model
















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









