






K-V cache的原理的学习笔记
首先要明确的一点是K-V cache建立在causal attention的基础之上,即第
t
t
t个token只会与第
t
−
i
t-i
t−i个tokens计算
Q
@
K
@
V
Q@K@V
Q@K@V,这就会出现下图的情况
上述过程用公式表示为:
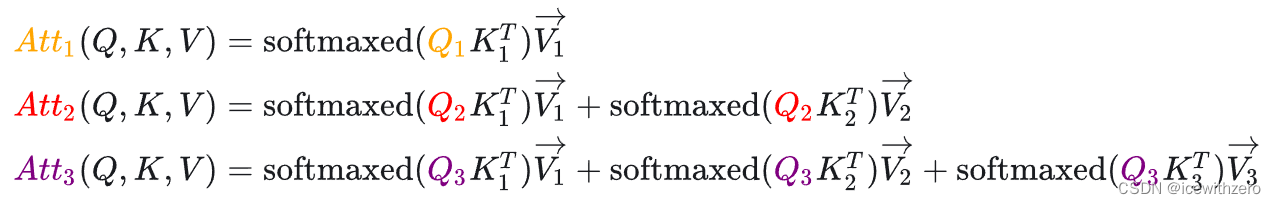
可以看到,当新加入token后,其计算结果只和当前token的
Q
K
V
QKV
QKV、历史token的
K
V
KV
KV有关,因此通过将历史token的
K
V
KV
KV保存下来,可以有效降低计算量。
如下图所示:

参考文献:[1]Transformer推理性能优化技术很重要的一个就是K V cache,能否通俗分析,可以结合代码? - 看图学的回答 - 知乎
[2]理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等
















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









