







Advances and Open Problems in Federated Learning
联邦学习
-
两种联邦学习变体:
- 跨设备cross-device FL,主要应用于数字产品;
- 跨企业cross-silo FL;主要应用于再保险财务风险预测、药物发现、电子健康记录挖掘[162]、医疗数据分割、智能制造等。
-
Cross-device FL特征与挑战:
- 中心服务器仅负责协调训练,理论上对用户数据一无所知,存在半可信或恶意安全模型假设;
- 用户节点数量庞大,如何高效实现大批量用户并行化;
- 用户通信开销受限,如何减少传输消息大小,同时不影响任务正常执行;
- 用户大部分时间内是离线的,如何最小化用户计算开销;
- 用户是否可靠,如何支持用户退出鲁棒;
- 通信链路是否可靠,如何应对传输延迟甚至是丢包问题?
- 用户拥有数据数量不平衡,如何确定用户的更新权重;
- 用户数据孤岛且数据为非独立同分布,如何克服数据分布导致的收敛困难问题;
- 用户数据是否可靠,如何应对不规则数据造成的不良影响;
- 此外,还可能存在内部恶意敌手(用户或协作服务器)和外部恶意敌手攻击(例如投毒攻击、拜占庭攻击等)。
提高联邦学习效率和有效性
-
non-IID可能情况:数据分布Pi ≠ \ne = Pj for different clients i and j;Rewriting Pi(x, y) = Pi(y | x) Pi(x) = Pi(x | y) Pi(y);
- 特征分布倾斜:Pi(y | x)相同,Pi(x)不同(例如手写数字有笔迹的特征区别,仍被分类为同一类别)–>单一全局模型,特征鲁棒;
- 标签分布倾斜:Pi(x | y) 相同,Pi(y)不同(例如袋鼠只在澳大利亚,同样是袋鼠,却在中国被判定不是袋鼠类)–>学习真正正确的标签;
- 相同特征,不同标签:Pi(x)相同,Pi(y | x)不同(例如评价标准不同,同一张图像被划分为不同类别);
- 相同标签,不同特征:Pi(y)相同,Pi(x | y) 不同(例如白天和晚上,同一个类别,对应的图像也会不同);
- 每个用户端拥有的数据数量不同;
注意:在现实中,通常上述几种可能情况的混合。
-
IID数据下的优化问题
- 分布式非凸模型问题的收敛速率问题;
- 分布式用户的模型更新速率不一致导致全局模型收敛问题,解决方法包含选择部分更新完的用户用于聚合模型、时间窗口用于用户更新不同数量的样本、异步方法等;但异步方法可能很难与差分隐私或安全聚合等免费技术相结合。
- 每轮训练用户数量,每轮本地更新迭代次数等超参数选择;
-
non-IID数据下的优化问题
- Non-IID数据下的一些先验假设:


- 固定假设下的现有解决方案:
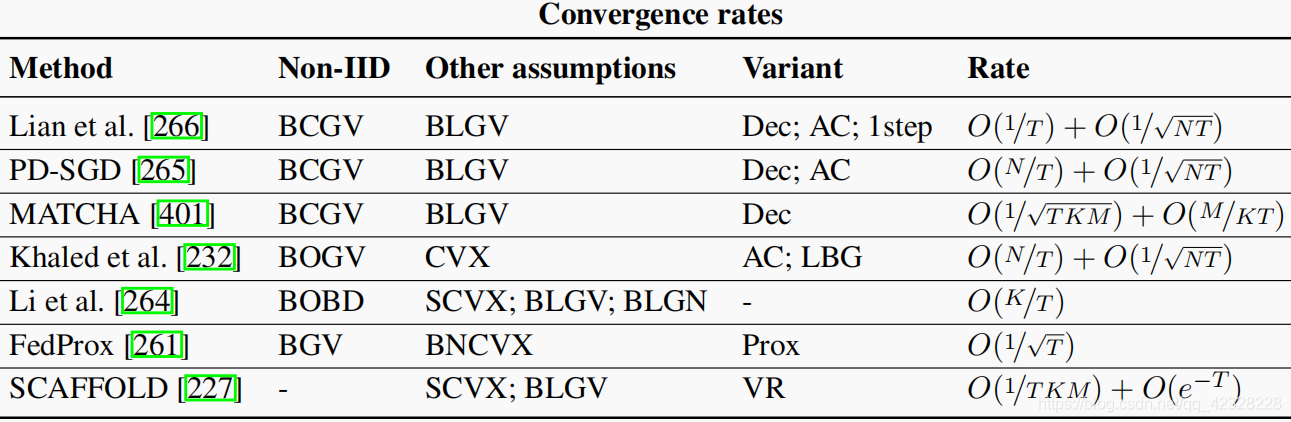
- Non-IID数据下的一些先验假设:
-
多任务学习:每个客户的本地数据集学习问题作为一个单独的任务,而不是作为一个单独分区数据集的碎片。
-
全局模型实现个性化模型:微调、迁移学习、领域适应、个人局部模型插值;元学习(根据少量样本寻找一组模型函数F,在未知任务驱使下可以快速建立F与最优任务函数f的联系;机器学习用于学习未知样本的标签,元学习用于学习未知任务的模型);
-
联邦学习模型一定比局部模型好吗?不一定,如何量化联邦学习对局部模型的改善程度?联邦量化学习?联邦度量学习?
-
超参数优化:提高全局模型准确率,提高通信和计算效率;探索鲁棒性的超参数优化算法,相同的超参数值适用于许多不同的真实世界数据集和架构。
-
网络架构优化:神经网络搜索NAS,例如权值不可知神经网络,声称只有神经网络体系结构,无需学习任何权值参数,可以对给定任务的解决方案进行编码。
-
通信压缩:上传梯度压缩;下传模型压缩;
用户数据隐私保护
-
威胁模型:
- 用户端:诚实但好奇的用户端可以验证从服务器收到的所有消息,但不能篡改训练过程;恶意的用户端可以验证从服务器接收到的所有消息(包括模型迭代),并可以篡改训练过程,任意偏移目标任务。
- 协作服务器:诚实但好奇的服务器可以验证发送到服务器的所有消息(包括梯度更新),但不能篡改训练过程;恶意服务器可以验证发送到服务器的所有消息,并可以篡改训练过程。
- 模型需求者:联邦学习的计算结果向模型需求者透露了多少关于用户端数据的隐私?
- 最终的模型可以部署在很多用户端上,模型流通的隐私也是值得注意的问题。
-
安全计算工具:
- 差分隐私:添加随机性噪声,包含本地差分隐私、分布式差分隐私、混合差分隐私;
- 安全多方计算:两个或两个以上的参与者协作来模拟一个完全可信的第三方;
- 同态加密:应用层面通常采用部分同态加密;
- 可信执行环境:TEE提供了在远程机器上可靠地运行代码的能力,即使你不相信机器的所有者/管理员,通过限制包括管理员在内的任何一方的能力。
-
可验证计算将使一方能够向另一方证明,它已忠实地对其数据执行了所需的行为,而不会损害数据的潜在保密性;例如零知识证明(ZKPs)、可信执行环境(TEE)或远程验证(硬件安全);
攻击和失败的鲁棒
-
敌手攻击:(训练)数据荼毒攻击;(训练)模型更新攻击;(推理)规避攻击(抵御采用对抗样本训练,对抗白噪声鲁棒)等;
-
模型更新攻击(模型荼毒):
- 无目标拜占庭攻击,抵御采用中值聚合等;
- 目标后门攻击,抵御采用零知识证明等,即用户有能力证明上传的模型更新是使用有效图像进行正确计算的,同时不泄露用户隐私。
- 用户共谋发起协同攻击:目前还没有十分有效的方案,如何检测用户是否共谋?如何防御用户共谋?
-
数据荼毒攻击:防御采用拜占庭鲁棒的聚合器等;数据消毒;模型剪枝(后门攻击通常会触发后门神经元,因此剪枝掉未激活的神经元是一种可行方法);
-
用户是否可以共谋:
- 不能共谋;
- 更新内合谋:当前用户参与者可以协调对当前模型更新的攻击。
- 交叉更新合谋:过去的用户参与者可以与未来的参与者协作,攻击未来对全局模型的更新。
-
恶意用户参与率:即单次参与攻击(跨设备FL);即连续参与攻击(跨企业FL);
-
恶意用户自适应性:静态敌手,必须在攻击开始时确定攻击参数;动态敌手,可以随着训练的过程动态调整攻击参数或策略。
-
非恶意故障:客户端报告故障(用户中途退出、用户上传延迟);数据管道故障(通信质量或其他传输故障);噪声模型更新(低质量数据、由传输质量导致的噪声数据)。
-
隐私性与鲁棒性的均衡:安全聚合,基于相似距离的证明方案,各种线性和非线性处理方法。
联邦学习的公平性约束
-
衡量用户参与贡献:参与时间周期;梯度更新频率(延迟);数据数量;数据质量;用户数据与目标任务的匹配程度等;
-
公平、隐私、鲁棒、效用、效率的权衡;
-
联邦数据集:
- EMNIST数据集:包含数字10、大写英文字符26、小写英文字符26,共62类,共671,585张图像;联邦版本将数据集分割为3400个不平衡的客户端,这些客户端由数字/字符的原始编写索引;non-iid的分布来自于每个人独特的写作风格。EMNIST: extending MNIST to handwritten letters
- iNaturalist数据集:适合研究联邦迁移学习和跨企业FL设置;包含对世界各地各种生物的大量观察。根据地理位置或观测结果的作者进行划分?按照生物所属的类群来划分?iNaturalist
- 适合计算机视觉的联邦数据集:包含由26个街道摄像机生成的900多张带注释的街道图像,带有详细边界框注释的7个对象类别;Real-world image datasets for federated learning
参考文献
2019_Advances and Open Problems in Federated Learning

















 8284
8284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









