



一、多目标跟踪概述
多目标跟踪(Multi-Object Tracking,MOT),顾名思义,就是指在同一段影像序列中同时跟踪多个目标。相比单目标追踪,多目标追踪问题要更加复杂。
根据应用场景的不同,跟踪算法分为两类,在线跟踪(online tracking)和离线跟踪(offline tracking/batch tracking)。在线跟踪只能使用当前帧及过去帧的信息对当前帧中目标的位置进行推测,这和人类的跟踪方式相同;而离线跟踪则充分利用整个视频的全部信息,对当前帧进行追踪,不仅可以利用过去帧的信息,还可以利用未来帧。两者主要差别在于应用场景不同,可以理解为,在线跟踪是在拍摄视频的过程中跟踪目标,而离线跟踪则是在视频拍摄完毕,拿到完整的视频后,对目标进行跟踪。因此一般来说,离线跟踪算法的准确率往往会更高。
目前,主流的多目标跟踪方法是TBD(Tracking-by-Dectection),即与目标检测算法相结合的跟踪方法。TBD方法在每一帧都进行目标检测,再利用目标检测的结果进行追踪。现在常用CNN来完成目标检测的任务,和我们的项目契合度非常高。
(更加详细的介绍可以参考博文:https://zhuanlan.zhihu.com/p/62827974)
二、SORT原理
SORT(Simple Online and Realtime Tracking),在2016年被提出,其性能超过了同时代的其他多目标跟踪器。然后,正如它的名字,SORT的原理非常简单,源码只有不到300行!SORT主要由三部分组成:目标检测,卡尔曼滤波,匈牙利算法。
(1)目标检测(Object Detection)
刚才说了,目前主流的跟踪算法常常与目标检测算法相结合,SORT也是其中之一。目标检测的任务就是找到目标的位置,常用一个矩形(bounding box,简称为bbox)将目标框出来,来表示目标的位置。在SORT中,作者使用了Faster RCNN来得到bbox,具体原理这里不展开,大家当一个黑箱来使用就好了。当然,除了Faster RCNN以外还可以用其他的检测算法,如YOLO等。值得一提的是,作者发现目标跟踪质量的好坏与检测算法的性能有很大的关系,通过使用先进的检测算法,跟踪结果质量能够显著提升。
(2)卡尔曼滤波(Kalman Filter)
得到bbox后,我们是否就知道目标的准确位置了呢?从严格上来说,不是的。因为测量总是存在误差的,我们通过目标检测得到的bbox会不可避免地带有噪声,导致bbox的位置不够精确。这时,卡尔曼滤波的作用就体现出来了。
卡尔曼滤波可以通过利用数学模型预测的值和测量得到的观测值进行数据融合,找到“最优”的估计值(这里的最优指的是均方差最小)。比方说,我们现在要知道t帧时某一目标准确的bbox(即,计算估计值),记为。我们已知的是1~t-1帧中目标的bbox。现在我们有两种方法得到t帧的bbox:一是通过数学建模,根据1~t-1的信息来预测出t帧的bbox,记为
;二是通过检测算法,直接测量出t帧的bbox,记为
。卡尔曼滤波做的事情就是利用
和
来得到
,具体分两步实现:预测(predict),即通过数学模型计算出
;更新(update),结合测量值
得到当前状态(state)的最优估计值。
总之,卡尔曼滤波是一种去噪技术,能够在目标检测的基础上,得到更加准确的bbox。
卡尔曼滤波的公式及其推导这里不做展开,网上有很多资料了,这里只列举一些我认为比较好的学习资料:
1、https://www.youtube.com/watch?v=CaCcOwJPytQ(视频,需科学上网,虽然没有中文字幕,但讲得确实好)
2、https://www.bilibili.com/video/av24098897?from=search&seid=16843036953707979301(MATLAB 制作的教学视频,youtube上的有中文字幕)
3、https://blog.csdn.net/heyijia0327/article/details/17487467(博客,通俗易懂地介绍了卡尔曼滤波的公式及其推到)
4、https://www.bilibili.com/video/av24225243(徐亦达的机器学习课程,有详细的公式推导)
https://github.com/roboticcam/machine-learning-notes(徐老师的github资源)
(3)匈牙利算法(Hungarian Algorithm)
匈牙利算法是一种数据关联(Data Association)算法,其实从本质上讲,跟踪算法要解决的就是数据关联问题。假设有两个集合S和T,集合S中有m个元素,集合T中有n个元素,匈牙利算法要做的是把S中的元素和T中的元素两两匹配(可能匹配不上)。结合跟踪的情景,匈牙利算法的任务就是把t帧的bbox与t-1帧的bbox两两匹配,这样跟踪就完成了。
要想匹配就需要一定的准则,匈牙利算法依据的准则是“损失最小“。损失由损失矩阵的形式来表示,损失矩阵描述了匹配两个集合中某两个元素所要花费的代价,具体看下面这个例子(来自wiki)
你有三个工人:吉姆,史提夫和艾伦。 你需要其中一个清洁浴室,另一个打扫地板,第三个洗窗,但他们每个人对各项任务要求不同数目数量的钱。 以最低成本的分配工作的方式是什么? 可以用工人做工的成本矩阵来表示该问题。例如:
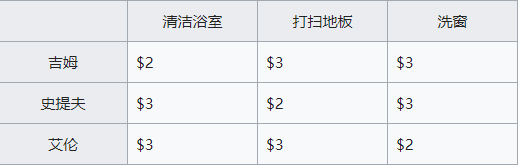
当把匈牙利方法应用于上面的表格时,会给出最低成本:为6美元,让吉姆清洁浴室、史提夫打扫地板、艾伦清洗窗户就可以达到这一结果。
定义了损失矩阵后,就可以按照匈牙利算法来求解了。在python中,可以用sklearn.utils.linear_assignment来实现。具体的实现方法,可以参考https://zh.wikipedia.org/wiki/%E5%8C%88%E7%89%99%E5%88%A9%E7%AE%97%E6%B3%95
(4)SORT的具体实现
理解了上面这些组件后,SORT的原理就显得特别简单了。SORT将卡尔曼滤波预测的和目标检测算法得到的
,用匈牙利算法进行匹配,在用
和
更新当前状态,得到
,作为追踪的结果。
上面说了,匈牙利算法在使用前需定义损失矩阵。SORT利用和
的IOU(交并比)来定义损失矩阵。比如损失矩阵Costij就表示前一帧第i个bbox与这一帧第j个bbox的IOU。
(选读)SORT中Kalman滤波采用线性匀速模型,状态向量描述成
![]()
其中,u,v表示bbox的中心坐标,s表示面积,r表示横纵比(SORT中认为对每个目标而言,r是不变的常数;而在deepSORT中则不是),头上带点的是相应的变化率(速度)。
其他的一些技术细节,如追踪器的创建与销毁,这里不再展开,感兴趣的朋友可以阅读原文。
三、SORT性能
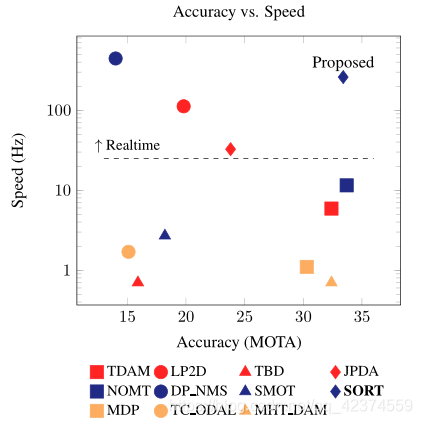
SORT正如它的名字,简单(simple)而能满足实时性(realtime)。一方面,它的原理简单,易于实现;另一方面,正因为简单,它的速度极快,在Intel i7 2.5GHZ/16GB的配置上能达到260HZ(不含目标检测耗费的时间)。同时,由于目标检测技术的引入,跟踪的准确度也大大提升,可以说很好的权衡了准确度和速度。 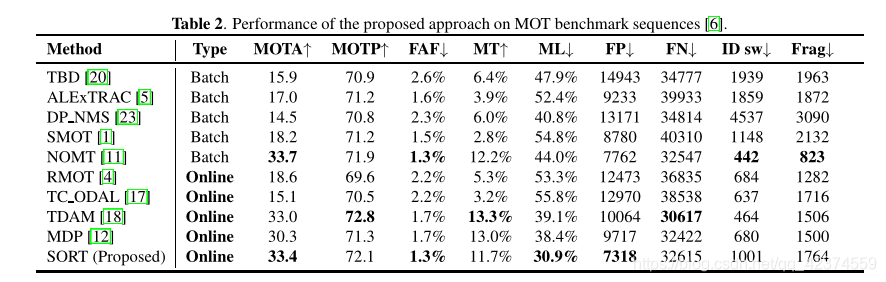

















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









