






一、论文阅读
1、Abstract
(1)作者想解决什么问题(Question)?
现有的检测工作基本都依靠密集检测器(特征框数量过多,并且在整张图像上提取特征,效率低,拉慢速度?)为什么不使用稀疏检测器优先?
(2)作者通过什么理论/模型来解决这个问题(method)?
Sparse R-CNN(一种纯稀疏的方法),使用总数为N,稀疏的可学习的目标提取框,让目标识别器更好的进行分类和定位。
(3)作者给出的答案是什么(answer)?
将成千上万个目标候选框减少到N个可学习的提取框,避免将所有精力放在目标候选框的设计中和多对一标签分配
最重要的是最终的预测是不经过非极大值抑制处理直接输出。
论证了精度、运行时间和训练收敛在COCO数据挑战中表现很好。结果:45.0 AP
作者希望这个工作能启发在当前目标检测优先使用密集检测的工作者重新思考
2、Introduction
(1)为什么研究这个课题?
目前的缺陷:
a、会产生一些冗余和近似的结果,需要进行非最大值抑制处理(NMS)
b、在训练中多对一标签的分配问题,让网络对启发式的分配规则敏感[2, 58, 60]
c、最终性能在很大程度上受尺寸、长宽比、锚点数量、参考点密度和建议生成算法的影响。
由于密集检测算法的缺陷,以及受到DETR的启发
密集检测器一直严重依赖于候选目标的设计,而Sparse R-CNN中的候选目标是可以学习的,因此避免了所有与手工设计锚点相关的努力。
(2)目前课题进行到了哪一阶段?
目前,成功的检测基本都是密集检测器优先。将滑动窗口范式这种分类器应用在一个密集图像网格,引领了检测方法多年。
现在主流的单目标检测是事先在一个密集的特征图网格中标记或者引用点,然后预测目标的边界框的缩放和偏移,以及相应的种类。尽管密集到稀疏检测器在一组稀疏的提取框上工作,但是它们的提取框产生算法还是建立在密集的候选框之上。
DETR建议将目标检测作为一个直接和稀疏集合的预测问题,其输入仅为100个可学习的目标查询。最终的结果直接输出无需任何手工设计的后处理。尽管框架简单而奇妙,但DETR要求每个目标查询都与全局图像背景相交互。这种密集特性不仅减缓了他的训练收敛速度,还阻碍了它建立一个用于目标检测的完全稀疏流程。
(3)作者使用的理论是基于哪些假设?
假设稀疏性表现在两个方面:稀疏的框和稀疏的特征。
稀疏框意味着只有少量的初始框就足以预测图片的所有对象。
稀疏特征意味着每个框的特征不需要和这张图片上的所有特征进行交互
These sparse candidates are used as proposal boxes to extract the feature of Region of Interest (RoI) by RoIPool or RoIAlign .
这些稀疏的候选项被用作建议框,通过感兴趣区域池化和感兴趣区域对齐来提取感兴趣区域(ROI)的特征
因为只使用四维坐标只能粗略地描述物体,缺少姿势和形状的特征,,所以引进了一个新的提取特征的概念建议特征,它是一个高维的潜在向量。它有期望编码丰富的实例特征。
特别的是,建议特征为它专有的目标识别头产生一系列定制参数。我们称这个操作为动态实例交互头。
本文的head更加灵活,而且在准确性方面领先。
Sparse R-CNN成功的关键是:以独特的建议特征而不是固定参数为条件的head公式
提取框和提取特征和其他参数一起都是随机初始化和优化的
Sparse R-CNN最显著的特征是在任何时间的输入输出都是稀疏的。初始的输入是一组稀疏的建议框和建议特征,以及一对一动态实例交互。流程中即不存在密集候选,也不存在与全局(密集)特征的交互。
3、Conclusion
(1)文章的缺陷?
(2)作者关于课题的构思?
希望构建一个真正纯稀疏模型来做目标检测,然后为了解决四维坐标信息量太少,使用一组固定稀疏的可学习目标建议被提供给动态头进行分类和定位。解决了之前密集检测器的部分缺陷,不需要非最大值抑制处理,精确度、训练时间和寻来你收敛都表现的很好。希望可以启发后面做目标检测工作者对稀疏检测器的思考。
(3)?
4、Table
(1)Table1
用两种不同的Sparse R-CNN检测与其他不同的检测算法公平比较,如下图所示

数据来源: COCO 2017 val
重要指标: AP 、 AP50 、 AP75 、 APs 、 APm 、 APl(L)、FPS
模型步骤: 第一种是采用100个可学习的建议框,不进行随机剪裁数据增强,用来和主流目标检测器作比较,例如Faster R-CNN和RetinaNet。第二个方法利用300个带有随机剪裁数据增强的可学习建议边框,用于与DETR系列模型相比较。
每个步骤得出的结论: Sparse R-CNN很好的领先于一些主流的检测器。而且Sparse R-CNN-R50的精度已经可以和Faster R-CNN-R101相竞争。
DETR和变形的DETR通常使用较强的特征提取方法,如堆积编码层和可变形卷积。
Sparse R-CNN的增强实现,与这些检测器比较时更加公平。即使使用简单的FPN作为特征提取方法,Sparse R-CNN也具有较高的准确率。
Sparse R-CNN收敛速度比DETR快10倍.与Deformable DETR相比,它的精度更加准确,运行时间更短以及更短的训练时间.
DETR:提出以来,由于一直面临收敛较慢的问题,所以提出了Deformable DETR.两个人都是端到端网络
==发现亮点:==推理时间,此检测器和其他检测器差不多.但是作者设计的动态交互实例头,让有300个提取框的时候运行速度只是降为了22FPS(100个提取框的时候是23帧/秒)
(2)Table 2

数据来源: COCO 2017 test
重要指标: AP 、 AP50 、 AP75 、 APs 、 APm 、 APl(L)、FPS
模型步骤: 使用ResNeXt-101作为骨干网络,Sparse R-CNN 实现 46.9 AP without bells and whistles.通过增加额外的测试时间,Sparse RCNN可以达到51.5AP,与当前最好的模型效果一样.
每个步骤得出的结论:
(3)Table 3

重要指标: AP 、 AP50 、 AP75 、 APs 、 APm 、 APl(L)、FPS
模型步骤: 对Sparse R-CNN使用消融研究,从Faster R-CNN开始,逐渐加入可学习的提取框 、迭代结构和动态头部.所有模型都通过预测损失来进行训练.
刚开始我们天真的直接使用一组可学习的提取框代替了RPN,性能从40.2直接降到了18.5.就发现就算增加更多的全连接层,也没有显著的提升
每个步骤得出的结论:
(4)Table 4
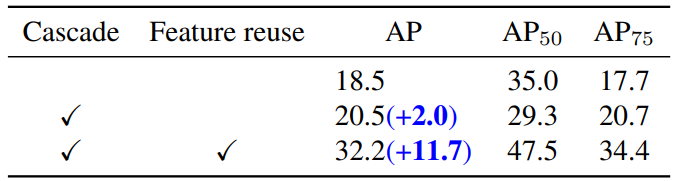
重要指标: AP 、 AP50 、 AP75 、 APs 、 APm 、 APl(L)、FPS
模型步骤: 迭代更新框是一种提高性能的直观想法,但是我们发现简单的级联体系结构并没有很大的区别,见表四.
原因如下:与[2]中精炼到主要定位在目标周围的建议框相比,我们方案的候选更加粗糙,使得很难被优化。
==我们发现,一个建议框的目标对象在整个迭代过程中通常是一致的。因此,可以前面阶段的目标特征可以再次使用,对下一阶段起到重要的作用。比如目标特征编码了丰富的信息像目标姿态和目标位置.
最后我们将目标特征重复使用,在原有的级联基础上,这一特征重复使用的微小改变使得AP大幅提高了11.7。最后,迭代结构带来了13.7的AP改进,如表2第二行所示。
每个步骤得出的结论:
(5)Table 5

模型步骤: 动态头也是使用前面的特征(用一种和迭代架构不一样的方式).不是简单的拼接,而是先用自注意力模块对前一阶段的目标特征进行处理,然后作为建议特征实现当前阶段的实例交互。
自注意力模块被用在目标特征集,是为了对目标之间的关系进行推理。
每个步骤得出的结论:
Sparse RCNN精度达到了42.3AP
(6)Table 6

模型步骤: 初始化提取框.有人会担心建议框的初始化在Sparse R-CNN中起着非常重要的作用。这里,我们研究了不同方法初始化建议框的效果:1.“中心”是指所有建议框在开始时都位于建议框的中心,长和宽都设置为图片大小的0.1倍。2.“图像”意味着所有建议框都初始化为整个图像的大小。3.“网格”是指建议框在图像中被初始化为常规网格,也就是G-CNN中的初始框。4.“随机”表示建议框的中心、长和宽都用高斯分布初始化。
每个步骤得出的结论:
从表5我们能看出Sparse R-CNN的最终性能和建议框的初始化相比是相对稳定的。
(7)Table 7
提取框的数量对结果的影响

模型步骤: Faster R-CNN中将提取框从300增加到2000个之后,性能有了显著的提高.所以这里比较了提取框数量为100 \ 300 \ 500时模型的效果.==显示了这个框架可以很好的在不同的环境使用.==但是因为500个提取框会花费更多的时间,所以我们选择使用100和300作为主要的配置.
每个步骤得出的结论: 增加提取框的数量会提升结果,但是也会花费更多的时间.
(8)Table 8
迭代结构中的阶段数目
迭代架构是一种被广泛应用的提高目标检测性能的技术

模型步骤:
每个步骤得出的结论: 选择6个阶段作为默认配置.
(9)Table 9
动态头VS多头注意力
动态头利用建议特征过滤感兴趣区域特征,最终输出目标特征。

模型步骤: 我们发现多头注意力模块为实例交互提供了另一种实现的可能。
与线性多头注意力相比,我们的动态头更加灵活,其参数根据其特定的建议特征而定,并且可以很容易引入更多的非线性容量。
每个步骤得出的结论:
其性能落后了6.6AP。
(10)Table 10
提取特征VS目标查询:
在DETR中提出了目标查询,与提取特征很相似.下面是对他们的比较:

**模型步骤:**目标查询是学习位置编码,引导解码器与图像特征图和空间位置编码的综合进行交互。仅适用图像特征图将导致显著下降。然而,我们的建议特征可以看作是一个与位置无关的特征过滤器。
**结论:**如果去掉空间位置编码,DETR下降了7.8AP。相反,位置编码不会给Sparse R-CNN带来任何收益。
(11)Table 11
关注到Sparse R-CNN在拥挤的场景中表现很好.使用CrowedHuman数据集进行试验(一个极度拥挤的人体检测基准)

重要指标: AP 、mMR \ Recall
模型步骤: Sparse R-CNN训练50轮,在epoch 40时学习率除以10。提案号是500。输入图像的最短边不小于480,最多800,最长边不大于1500。其他细节与COCO数据集相同。
每个步骤得出的结论: 比其他主流的目标检测器效果好一点.Sparse RCNN也可以很好的应用在拥挤的场景.
我们希望稀疏R-CNN可以作为一个坚实的基线用于各种检测场景。
(12)Table 12
自监督预训练:引入自监督方法进行对比
其中DetCo引入了全局图像和局部patch之间的对比学习,scl通过几何平移和缩放操作学习随机裁剪的局部区域的空间一致性表示。

重要指标: AP 、mMR \ Recall
模型步骤: 在Sparse R-CNN中分别使用监督和自监督的方法进行预训练权重来进行比较
每个步骤得出的结论: 自监督学习还是效果更加好点
(13)Table 13

重要指标: AP 、mMR \ Recall
模型步骤: 将现在最火的Transform作为主干网络,与CNN作为主干网络进行比较。其中PVT采用渐进收缩金字塔结构,Swin Transformer使用移位窗口构建层次表示。
每个步骤得出的结论: 可以看出,使用transform作为主干网络的效果更好。
图表
图一:

(1)在密集检测器中,(H*W)大小的目标候选框列举在图像上的所有的k个网格。例如,RetinaNet
(2)在密集到稀疏检测器中,从k个候选框中选择一小部分(N个)候选框,然后通过池化操作来提取相应的图片特征。如,Faster R-cnn
(3)本文使用了稀疏检测器Sparse R-cnn,直接从N中选择以一小部分可学习的目标提取框
learned object proposal 是可学习的目标提取框?
图二:

是RetinaNet、Faster R-CNN、DETR和Sparse R-CNN在COCO val2017上的收敛曲线。Sparse R-CNN从训练效率和检测质量来说比赛表现很好。
看图的话:
RetinaNet、Faster R-CNN和Sparse R-CNN,达到最好的效果测试轮数较少,差不多35轮。其中Sparse R-CNN性能远好于另外两个;
DETR的话,训练轮数太多,且效果差于前面三种
图三

输入:一张图像、一组提取框和提取特征(这是两组可学习的而且可以和其他参数一起优化)
主干网络提取特征图,每一个提取框和提取特征(Proposal Features)输入到其专属的动态头部,生成目标特征。
输出:分类和位置
图四:

动态实例交互伪代码,第k个提议特征为对应的第k个感兴趣区域生成动态参数。Bmm:批处理矩阵乘法;linear:线性投影。
4、Related Work
(1)密集方法
最开始是单级检测器,可直接预测覆盖空间位置、尺度和纵横比密集的锚盒的类别和位置;
最近,有人提出了无锚算法[21,26,45,61,24],通过用参考点代替手工制作的锚盒,使这个管道变得更简单。
都建立在密集的候选对象上,并对每个候选对象进行直接分类和回归。
根据预先定义的原则,这些候选对象在训练时间内被分配到groundtruth对象盒中,例如。,锚点是否与其相应的地面真值具有更高的交集并集(IoU)阈值,或参考点是否落在目标框中的一个。此外,需要NMS后处理[1,51]来去除推断时的冗余预测。
(2)密集到稀疏的方法
最近提出的DETR[3]直接输出预测,不需要任何手工组件,取得了很好的性能。DETR利用一组稀疏的对象查询,与全局(密集)图像特征进行交互,在这个视图中,它可以看作是另一种由密集到稀疏的公式。
(3)稀疏的方法
G-CNN作为先驱;我们的稀疏R-CNN应用了可学习的建议,并取得了更好的性能。同时,引入Deformable-DETR[63],限制每个对象查询只关注参考点周围的一小组关键采样点,而不是feature map中的所有点。
5、Sparse R-CNN
核心想法就是:用一小组提取框代替RPN中成千上万的提取框
(1)主干网络
基于ResNet架构的特征金字塔网络作为骨干网络,从输入生成多尺度特征地图。
我们构建了从p2到p5的金字塔,其中l表示金字塔级别,Pl层的分辨率比输入低2^l。所有金字塔层都有C= 256个通道。详情请参阅[28]。实际上,Sparse R-CNN有可能从更复杂的设计中受益,从而进一步提高其性能,如堆叠编码器层[3]和可变形卷积网络[7],最近的工作DeformableDETR[63]就是在这些基础上构建的。然而,我们将设置与Faster R-CNN[37,28]对齐,以显示我们的方法的简单性和有效性。
(2)可学习的提取框
使用固定的一小组可学习的提取框(N×4)作为区域提案,而不是来自区域提案网络(RPN)的预测。这些提取框由0到1之间的4-d参数表示,表示标准化的中心坐标、高度和宽度。在训练过程中,提取框的参数会使用反向传播算法进行更新。由于可学习的特性,我们在实验中发现初始化的影响是最小的,从而使框架更加灵活。
从概念上讲,这些学习的提取框是训练集中潜在目标位置的统计数据,可以看作是图像中最可能包含目标的区域的初始猜测,而不管输入是什么。
(3)可学习的提取特征
尽管四维提取框是描述目标的一个简明而明确的表达,但是它只提供了目标的粗略定位并丢失了许多细节信息,例如目标姿态和形状。在这里我们引入一个被称为提取特征(Nd)的概念,它是一个高维(例如256)的潜在向量,并被期望编码丰富的实例特征。建议特征的数量和建议框的数量相等,接下来我们将讨论如何使用它。
(4)动态实例交互头
给定N个提取框,Sparse R-CNN首先使用RoIAlign操作来提取每个框的特征。然后使用我们的预测头来生成最终的预测。基于动态算法[23,44],我们提出了动态实例交互头。每个感兴趣区域的特征被输入到其专属的头部进行目标定位和分类,每个头部都以特定的提取特征为条件。
在我们的设计中,提案功能和提案框是一一对应的。对于N提取框,采用了N提取特性。每个RoI 特征将与相应的提取特征交互,过滤掉无效的bins,输出最终的目标特征 ©。对于light设计,我们使用ReLU激活函数进行两次连续的1×1卷积,实现交互过程。这两个卷积的参数由相应的建议特征生成。
只要支持并行操作,交互头的实现细节并不重要。最后的回归预测由一个3层感知计算,分类预测由线性投影层计算。
我们还采用了[2]迭代结构和自注意模块[47]来进一步提高性能。对于迭代结构,新生成的目标框和目标特征将作为迭代过程中下一阶段的提取框和提取特征。由于稀疏特性和轻动态头,它只引入了边际计算开销。在进行动态实例交互之前,将自注意模块应用于目标特征集,对目标之间的关系进行推理。我们的模块只接受对象特性作为输入。
(5)预测损失
集合预测损失。Sparse R-CNN将集合预测损失应用于固定大小分类和边框坐标的预测。基于集合的损失产生预测和真实目标之间的最佳双边匹配。匹配损失的定义如下:L = λcls· Lcls+ λL1· LL1+ λgiou· Lgiou(1)。这里Lcls是预测分类和真实类别标签的焦点损失函数,LL1和Lgiou是归一化中心坐标与预测框和真实框长和宽之间的L1损失和普遍交并比损失。Λcls、λL1和λgiou是各分量的系数。除了只在配对上执行,训练损失和匹配代价是一样的。最终的损失是按照训练批内的目标数量归一化的所有对的总和。R-CNN家族一直被标签分配问题困扰,因为多对一的匹配任然存在。这里我们提供了新的可能性,直接绕过多对一匹配,引入基于集损失的一对一匹配。这是探索端到端目标检测的一次尝试。
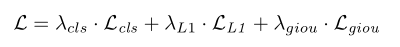















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









