











🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
SD模型原理:
微调方法原理:

目录
2. CLIP 文本编码器【权重不变,更改Embedding】
论文
https://arxiv.org/pdf/2208.12242
前情提要
摘录于:https://zhuanlan.zhihu.com/p/639229126
DreamBooth是由Google研究团队于2022年发布的一种通过将自定义主题和概念注入扩散模型的微调技术,它只借助少量数据集(3-5张图像)微调Stable Diffusion系列模型,让其能够学习稀有或个性化的图像特征。DreamBooth技术使得SD系列模型能够在生成图像时,更加精确地添加特定的主题、对象或风格。

DreamBooth首先为特定的概念寻找一个稀有的特定描述词[V]作为编码载体,同时设置基础类别[Class]组成全新的数据标签,这个特定的描述词一般需要是稀有的(比如说设置“sks”作为上图中书包的描述词[V]),之所以选择稀有描述词,是希望SD模型没有该描述词的先验知识,否则该描述词容易在模型先验和新注入概念产生混淆。同时基础类别[Class]是对这个特定概念的粗粒度类的描述,通过将稀有描述词[V]和基础类别[Class]绑定【标识符+类别要和类别同时出现】(举个例子:上图中的书包可以设定为[V][Class] = "a sks bag"),AI绘画模型可以在基础类别[Class]的基础上再绑定稀有描述词[V]的特征。
DreamBooth技术可以对SD系列模型的U-Net部分进行微调训练,同时DreamBooth技术也可以和LoRA模型结合,用于训练DreamBooth_LoRA模型。
同时,由于在少量数据上对模型微调容易产生“overfitting and language drift”问题,这里为了防止过拟合,设计了一个class-specific prior preservation loss(基于SD底模型生成相同Class的图像加入batch里面一起训练)来进行正则化。拿上面的书包例子,就是用SD模型生成一些普通书包的图像作为正则集【类别约束】。
正则化在机器学习中是一种用于防止模型过拟合的技术,通过在损失函数中添加惩罚项来约束模型的复杂度。具体到AI绘画领域,正则化有两种理解思路:
1. 锚定概念:在AI绘画模型训练前,先通过正则化预先固定一些关键的特征信息(图像信息、文本信息、条件信息等),使模型在训练过程中以这些先验信息为基础,进行优化学习。
2. 限制偏离:在训练过程中,正则化不断调整模型,防止其偏离预期轨道,限制模型的自由发展,确保生成图像的质量和一致性。

到这里,Rocky可以帮大家总结一下DreamBooth技术的特点:
- 稀有描述词[V]和基础类别[Class]绑定:使用稀有描述词将特定主题注入SD系列模型和LoRA系列模型中。
- 正则集【类别约束】:为了防止模型过拟合【和语义漂移】,使用class-specific prior preservation loss来正则化模型的训练过程。
- DreamBooth技术能够在保持模型泛化能力的基础上,让模型学习到特定主题的特征。
- 如果我们不启用正则集数据和class-specific prior preservation loss,这时训练过程将和fine-tune微调训练一致。
概念
基于扩散模型(Diffusion Models) 的个性化模型微调方法,最早由 Google Research 团队提出。通过仅少量特定对象的图片对预训练的大型扩散模型进行微调,从而生成包含该特定对象的高质量图像。这种技术使得模型可以生成具有个人定制元素的图像,而不需要大量的新训练数据。
它的提出既不是为了训练人物也不是为了训练画风,而是为了能使用少量训练图像,完美的还原细节特征。
DreamBooth 的关键贡献是能够将一个对象(例如一个人的照片或特定物品)“注入”到预训练模型中,从而生成包含该对象的新图像,同时保持预训练模型的多样性生成能力。
1. DreamBooth 的主要原理
利用了少量定制数据(如 3-5 张目标对象的照片),并且在不破坏原始模型生成能力的情况下,教会模型生成新的对象。
DreamBooth 的训练过程主要包括两个阶段:
- 个性化微调阶段:向模型传递少量关于特定对象的图片,并引导模型将该对象“嵌入”到图像生成过程中。
- 条件生成阶段:模型在推理阶段可以通过输入特定的文本提示,生成包含特定对象的图像。
2. 训练过程关键步骤
DreamBooth 的工作流程大致如下:
(1)对象数据的准备
- 用户提供一小部分特定对象的照片,通常是 3-5 张。这些图片中对象的姿态、背景、光照等尽可能多样化,以帮助模型更好地捕捉对象的多样性。
- DreamBooth 将该对象分配给一个独特的“标识符”(identifier)用作类提示(class-prompt),如
"S*",这个标识符将作为生成对象的条件被添加到文本提示中。例如,如果对象是一个特定的狗,可以为该对象分配"S* dog"作为条件提示。【“标识符+类别”和“类别”要成对出现】
(2)将对象注入模型
- 训练过程基于预训练的扩散模型(如 Stable Diffusion)。模型已经在大规模数据集上进行了训练,可以生成各种不同的对象和场景。
- DreamBooth 将用户提供的特定对象图像和文本提示输入到模型中,并进行微调训练。为了不破坏模型的已有生成能力,DreamBooth 通过将该对象的图像嵌入到模型的潜在空间(latent space)中,并通过特定的 Text Embedding(文本嵌入) 让模型将此对象与输入的标识符相关联。
(3)交替约束生成
- 为了保持模型生成的多样性,DreamBooth 在训练过程中对模型施加了某些约束——类别约束【或者正则化数据集】,这种约束使用的是类提示。通过这个类条件的约束,模型能够避免过度拟合到特定对象,从而保留生成其他对象的能力。
“类提示(class-prompt)【或者正则化数据集】”技术,避免过度拟合到特定对象。例如,给定
"S* dog"作为特定对象的标识符,DreamBooth 同时会使用类似"a dog"这样的通用提示来指导模型生成与这个类相关的其他对象。【“标识符+类别”和“类别”要成对出现】
(4)损失函数与正则化
DreamBooth 的损失函数设计结合了预测噪声残差和正则化损失。关键是要在保持生成能力和不破坏模型多样性的情况下,对模型进行微调。
-
预测噪声残差:这个损失函数确保了模型能够理解并记住对象的特征。这是标准的扩散模型损失函数,通常是预测噪声残差的均方误差(MSE)损失。公式如下:

- 正则化损失:为了防止模型过拟合于少量的定制对象,正则化部分通过“类提示”对模型进行约束,保证模型在生成特定对象时,仍然保持类的多样性。
正则化损失可以通过使用与通用类提示生成的图像(例如,使用 "a dog" 作为提示生成的图像)与个性化对象生成的图像进行比较,并限制它们之间的差异。这确保了模型不会过度拟合于某个特定对象,而是保留类的多样性。
以下是一个常用的正则化损失公式的形式,结合了类别提示和个性化对象提示的生成:
该公式的作用是通过通用类别提示
"a dog"来生成图像并约束【微调】模型生成的噪声残差与通用对象图像保持一致。这种约束使得模型不仅能生成特定对象"S* dog",还能够生成符合整体类别的对象(即生成其他“狗”类图像的能力)。
总体损失结合
整体而言和VAE的损失函数很像。

3. 训练阶段
DreamBooth 的训练流程可以分为以下几个步骤:
(1)冻结大部分权重
-
冻结 U-Net 其他部分的权重:为了保持模型原有的生成能力,DreamBooth 通常会冻结 U-Net 中大部分的卷积层和其他层,这些部分不会被更新。这意味着模型的基础图像生成能力不会受到影响。【有时会选择性地微调少量的高层或底层卷积层,以便更精细地控制图像特征的生成,但通常不会微调所有卷积层。这些层可以帮助模型更好地生成特定细节】
-
仅微调 Attention 层:模型中的 Cross-Attention 层 和 Self-Attention 层 是主要的微调目标。这些层直接负责处理文本与图像的交互,因此通过调整这些层的权重,可以让模型学会生成特定的个性化对象。
(2)前向传播:计算 Attention 输出
在前向传播过程中,模型会使用定制数据(即微调数据)来生成新的 Attention 输出。
在每个训练时间步中,模型首先进行前向传播。对于 Attention 层,具体过程如下:
-
输入:模型接收一张加噪的图像
和文本提示(如 "S* dog"),文本提示会通过 CLIP 文本编码器 转换为文本嵌入 c。
-
Attention 机制:在 Cross-Attention 中,模型会利用文本嵌入 c 生成 Key(K) 和 Value(V),而图像潜在特征
-
计算 Attention 输出:
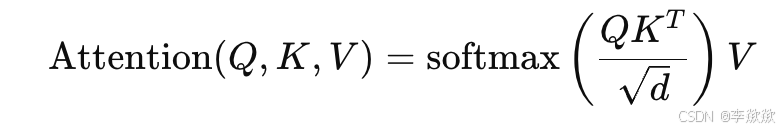
-
其中,d 是特征维度,Softmax 操作帮助计算文本与图像特征的相关性。Attention 输出将用于【噪声处理,不仅仅是去噪】去噪过程中的下一步。
-
Attention 层的输出 和 噪声去除的过程 在扩散模型中并没有直接出现在标准的噪声公式中。Attention 层的作用是帮助模型将文本提示与图像潜在特征结合。前向扩散中包含的原始图像
就是在Attention层调整潜在特征后的图像。
将Attention层调整后的原始图像,逐步加噪,生成噪声图像序列。这一部分与标准扩散模型一致:

(3)损失函数:计算误差
微调时,DreamBooth 使用了与标准扩散模型相似的损失函数,但还包括一个正则化损失项,用于防止模型过拟合到少量定制数据。
损失函数:DreamBooth 的损失函数包括以下两部分(如上提到的):
1. 噪声预测误差:与标准扩散模型一致,DreamBooth 使用 均方误差(MSE) 来计算模型预测噪声残差与真实噪声的差异:预测噪声![]() 和真实噪声
和真实噪声之间的差值
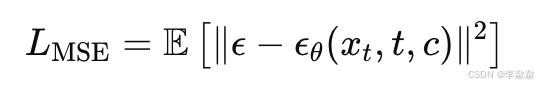
2. 类提示正则化(Class-Prompt Regularization):为了避免过拟合,模型会同时在一些通用类条件下进行生成训练。通过这种方式,模型不仅能生成特定对象,还能继续生成与该对象相关的其他类别对象。【使用类提示进行类别约束】。

(4)反向传播:计算梯度并更新权重
在前向传播结束后,DreamBooth 会通过反向传播算法来计算损失相对于 Attention 层权重的梯度,并根据梯度调整权重矩阵W(三个矩阵)的权重。具体步骤如下:
-
计算梯度:通过反向传播,DreamBooth 计算损失相对于 Query(Q)、Key(K) 和 Value(V) 矩阵的梯度。
- 对于每一层的权重矩阵 W,计算其梯度:
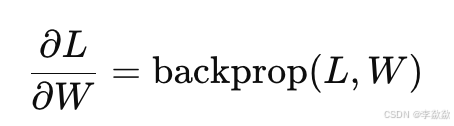
- 其中,L 是损失函数,W 是权重矩阵。
- 对于每一层的权重矩阵 W,计算其梯度:
-
更新权重:通过梯度下降法(如 Adam 优化器),更新 Attention 层的权重矩阵 W。每次更新后的权重为:
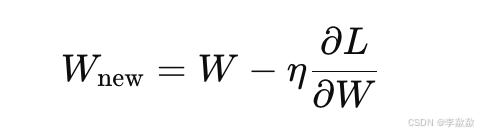
- 其中,η 是学习率。学习率控制了每次更新的幅度,通常 DreamBooth 使用较小的学习率,以确保模型的微调不会导致剧烈变化。
(5)训练迭代
重复训练:上述的前向传播和反向传播过程会在整个训练数据上重复多次(多个 epoch)。在每次迭代中,模型通过不断调整 Attention 层的权重,逐渐学会如何生成符合文本提示的定制化图像。
4. 推理阶段
在推理阶段,经过微调的扩散模型能够根据用户输入的文本提示生成包含特定对象的新图像。推理过程如下:
- 输入文本提示:用户输入
"S* dog playing in the park"这样的提示。 - 文本编码:CLIP 模型对文本提示进行编码,生成文本嵌入向量。
- 图像生成:模型基于文本嵌入生成图像,使用反向扩散过程逐步去噪,从随机噪声生成目标图像。
5. DreamBooth 的关键创新
- 少量数据学习:只需要少量图像(通常 3-5 张)就可以训练一个模型生成个性化图像。
- 类别约束正则化:通过类提示词进行类别约束,引入(class-prompt)正则化,使得模型不会只记住特定对象,而是保留了对该对象所属类别(如“狗”)的生成能力,从而可以在不同场景、姿势、光照条件下生成该对象。
- 高质量图像生成:由于模型基于预训练的大规模扩散模型,生成的图像具有极高的质量和细节。
6. DreamBooth 的应用场景
-
个性化头像生成:用户可以上传自己的几张照片,然后通过 DreamBooth 微调模型,使得模型可以根据不同的提示生成用户的个性化头像,例如在不同场景或风格中的形象。
-
定制产品设计:商家可以上传特定商品的照片,模型经过 DreamBooth 微调后,可以根据不同的场景生成该商品的定制化图像,用于市场营销或广告制作。
-
影视和游戏中的角色定制:影视制作或游戏开发者可以使用 DreamBooth 技术,快速生成定制化的角色模型,并让这些角色适应不同的场景和姿势。
-
个性化内容生成:艺术家、设计师可以使用 DreamBooth 微调扩散模型来生成符合特定设计风格或包含特定元素的内容。
7. DreamBooth 的优缺点
优点
- 少量数据:仅需少量图片,便可以生成带有特定对象的高质量图像。
- 个性化生成:允许通过微调生成具有定制化元素的图像。
- 生成质量高:基于大型预训练扩散模型,生成的图像细节丰富、质量高。
缺点
- 微调开销大:虽然 DreamBooth 只需要少量数据,但训练仍然需要显著的计算资源,特别是在大规模预训练模型上进行微调。几乎改变了U-Net的每一层。
- 潜在的过拟合:如果正则化不足,模型可能会对特定对象过拟合,从而损失生成其他相关对象的能力。
8. 模型微调改变的层
在使用 DreamBooth 微调 Stable Diffusion(SD) 模型的过程中,为了保持模型原有的生成能力,DreamBooth 通常会冻结 U-Net 中大部分的卷积层和其他层,这些部分不会被更新。主要的结构调整集中在模型的 U-Net 结构以及部分 文本编码器(CLIP) 上。以下是 DreamBooth 微调过程中对 Stable Diffusion 模型中不同模块的具体改变:
1. U-Net 网络结构
在 DreamBooth 的微调中,U-Net 的多个层会被调整,以便让模型能够生成包含特定对象的图像。具体来说,DreamBooth 主要会调整以下 U-Net 的关键部分:
(1)Cross-Attention(跨注意力)层
-
作用:负责将文本编码器生成的文本嵌入(来自 CLIP)与潜在图像特征进行融合。通过 Cross-Attention,模型能够结合输入的文本提示(如 "S* dog")来调整图像生成。
-
改变:在微调时,Cross-Attention 层中的权重会根据定制对象进行调整,确保特定对象在生成过程中能够与文本提示中的描述相匹配。
- 具体变化:模型通过更新 Query(Q)、Key(K) 和 Value(V) 的线性层权重【就是QKV对应的三个W矩阵权重】,调整文本信息和图像潜在特征的融合方式,使得模型能够生成包含特定对象的图像。
(2)Self-Attention(自注意力)层
- 作用:用于在不同空间区域间建立全局关联,让图像生成过程中的局部特征能够与全局特征保持一致。
- 改变:在微调时,Self-Attention 层的权重会被微调,以适应生成特定的对象,使得对象在图像中的细节能够被准确捕捉。
(3)残差块(ResNet Block)
- 作用:残差块用于在 U-Net 中促进梯度的流动,保持深度网络的稳定性,并在图像生成过程中保留细节。
- 改变:在微调时,DreamBooth 可能会调整残差块中的卷积层,使得模型能够更精确地生成包含目标对象的图像。
2. CLIP 文本编码器【权重不变,更改Embedding】
CLIP 是 Stable Diffusion 用于将文本提示转化为嵌入向量的部分。在 DreamBooth 微调时,CLIP 模型通常不会被大幅修改,但 DreamBooth 会调整文本嵌入的方式Embedding,使其与生成对象更好地匹配。【单看其在CLIP中的更改,和Textual Inversion是一样的。仅微调嵌入,不修改CLIP模型权重】具体的改变包括:
文本嵌入与图像生成的联动
- 作用:CLIP 文本编码器将输入的文本(如 "S* dog" 或 "a dog")转化为向量表示,供 U-Net 中的 Cross-Attention 层使用。
- 改变:在微调过程中,DreamBooth 会调整文本嵌入的作用方式Embedding,使得Embedding在 Cross-Attention 中与特定对象的图像特征更加匹配。这种调整可以保证生成的图像符合输入的文本描述。
3. 微调的范围和深度
DreamBooth 的微调几乎改变了U-Net的每一层。但原有的模型生成能力并没有被破坏,模型依然可以在不同场景中生成其他类型的对象。
- DreamBooth:会对 U-Net 中的所有Cross-Attention 和 Self-Attention 层进行调整,以适应新数据。它在训练过程中使用训练数据计算并直接更新Attention的权重矩阵WQ、WK 和 WV的值。
- LoRA:只会对部分Cross-Attention 和 Self-Attention 层进行局部调整,它在训练过程中使用训练数据计算并间接更新Attention的权重矩阵WQ、WK 和 WV时。通过训练增量ΔW的,采用低秩矩阵分解的方式来减轻计算负担。
其他参考资料
| dreambooth_lora | 全世界 LoRA 训练脚本,联合起来! | https://huggingface.co/blog/zh/sdxl_lora_advanced_script |
| 代码(参考上一层的 Train Dreambooth LoRA with Stable Diffusion XL解释 ) | diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py at main · huggingface/diffusers · GitHub | |
| 代码 | diffusers/examples/dreambooth/train_dreambooth_lora.py at main · huggingface/diffusers · GitHub | |
| dreambooth | DreamBooth | 如何定制属于自己的stable diffusion?Dreambooth原理详解和代码实战-CSDN博客 |
| 使用 Diffusers 通过 Dreambooth 技术来训练 Stable Diffusion | https://huggingface.co/blog/zh/dreambooth | |
| diffusers文档 | https://huggingface.co/docs/diffusers/training/dreambooth? |



















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









