






摘要:热图在夜晚或者其他光照条件差的情况下检测行人效果很好,但是在白天效果却很差。为了解决热图在白天效果差的问题,大多都是融合热图和Rgb图。而我们却是通过用热图的显著图来对热图增强,以便进行更好的检测,尤其是在白天的情况下。只用了热图,没用rgb图,模型最好的表现相对于baseline的白天和黑夜的情况,miss rate分别降低了13.4%和19.4%。
1、 引言
热图和rgb图对行人检测能够优势互补,但是想要同时获得热图和rgb图对却很难,并且要对齐并注释精准更难,稍微对不齐就会导致检测器的性能。故此驱动本文思路,仅仅用热图完成行人检测。
前人定义图片中某个像素点的显著性为这个像素点与周围像素点在颜色、方向、运动和深度等方面与周围像素点的不同。在一个场景中寻找显著性物体可以解释为一种视觉上的注意力机制,这种机制会表明哪些像素点属于这个显著性物体。利用这个机制就可以假设利用热图和显著性图就可以提升检测器的性能。
为了验证我们的假设,首先建立了以faster r-cnn在热图上的检测为基准的结果,然后用加上利用静态(PiCA-Net)和深度学习(R3-Net)方法生成的显著图的检测结果与基准结果进行比较,实验表明加上显著图的结果更好。此外,由于深度学习方法(R3-Net)生成显著图需要像素级别的注释,故我们注释了KAIST的一部分子集。
本文关键贡献:
1) 第一次有人用显著图来提升在热图上做行人检测的性能。
2) 开源了像素级别的注释。
2、相关工作
行人检测:略
显著性检测:研究了几十年了。有一个比较好的综述在文中所提到的[1]论文中。最近出了很多用CNN做显著性检测的方法。如DHSNet, Holistically-Nested Edge Detector等,本文用了两个最先进的网络,PiCA-Net和R3-Net来生成显著图,并对显著性行人检测额数据及进行基准测试。
3、 方法
3.1 用faster r-cnn在热图上做基准测试
主干网络可以是vgg16或者ResNet101表二中有相关结果。
3.2 我们的方法:用显著图来提升检测性能
白天的时候,人与周围环境很难区分。因为显著图丢弃了所有的在热图里的语义信息,所以如果只用显著图的话就很有问题,故采用同时输入显著图和热图来训练,即用显著图来增强热图来训练。做法也很简单,就是用提取的显著图(单通道)来替换3通道的热图的一个通道,如图1(a)。这样这个三通道的新图既保留了原始热图的语义信息,又通过显著通道表明了图片中的显著部分。然后将这个新的3通道的图片投入faster r-cnn进行训练,如图1(b)。
3.2.1静态显著性
用openCV库中提供的方法提取静态显著性。但是用这种方法提取的显著图不仅高亮行人,还高亮了图片中其他物体,如天空。

3.2.2 深度显著网络
研究了两种最先进的深度显著性网络。
PiCA-Net:是像素级别的语义注意力网络,会为每一个像素都生成与其他每一个像素点的相关性的注意力图(attention map)。他是用双向LSTM(Bidirectional LSTM)来在一个像素点水平和垂直方向进行扫描获取全局语义。用卷积神经网络在这个像素点邻近区域执行获取局部语义。最后用U-Net结构来层级地(hierarchically)整合PiCA-Nets获得显著目标检测。
R3-Net使用Residual Refinement Block(RRB)循环迭代地学习gt与显著图之间的残差。RRB在每次循环迭代时选择性的利用低层特征与高层特征来精细化显著图,具体就是通过将之前的学习到的显著图添加到学习到的残差上进行精细化。
这两种方式获得显著图只高亮了行人。

3.3 数据集:重新标注KAIST数据实现显著性行人检测。
从kaist训练集中挑选了1702张图片(白天每15帧采样一张,晚上每10帧采样一帧),其中白天有913张图片,晚上789张图片,共包含4170个行人实例,用这些作为训练集。然后从kaist测试集中挑选了362张图片,其中193个白天的,169个夜晚的,共计1029个实例。做同样的标注,作为测试集。
实际上这些标注都不够精准,所有并不适合语义分割任务,但是用来生成显著图并不需要像语义分割一样严格的要求,足够了。
4 实验
4.1 数据集和评估方案
用kaist数据集,训练集每3帧采样一帧,测试集每20帧采样一帧。排除遮挡,修剪,小于50像素的行人实例。这样训练集共获得7601张图片(4755白天,2846夜晚),测试集2252张图片(1455白天,797夜晚)。
评估用Log Average Miss Rate(LAMR)以及False Positives Per Image(FPPI)以及mAP(iou=0.5)。为了评估显著图,使用了两种评估方案:1)F-measure score (Fβ):是准确率和召回率的加权调和平均数。2)Mean Absolute Erroe(MAE):计算每个像素点与gt中对应的像素的差值的绝对值之后,所有像素点对应差值求和后取平均值。
4.2实现细节
4.2.1 faster r-cnn实现行人检测
基于jwyang的开源实现并做了些小调整,首先移除vgg16的第五个max-pooling层。原始vgg用3个scales,每个scale有3种ratios的anchor。本文也用3个scales,但是每个scale采用9个ratios[0.05, 4]的anchor,在之间。本文用imagenet预训练模型,固定主干网络的前两层进行微调。
4.2.2深度显著性网络
用的是带自制标注的kaist训练集。
其他PiCA-Net和R3-Net的一些训练超参数。用的都是开源的代码实现。
4.3结果与分析
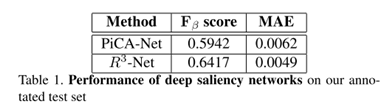
4.3.1深度显著性网络在kaist显著性行人检测数据集的性能。
用的是自制标注的kaist测试集。由于r3-Net用了个什么玩意操作(fully-connected CRF),效果会稍微好点。
4.3.2使用显著图加持进行热图检测行人检测的结果分析
结果如图6
仅使用热图(miss rate):白天 44.2%,晚上40.4%。晚上效果更好。
使用显著图加持的热图(miss rate):
静态显著图:白天39.4%,相对于只用热图,提升了4.8%。晚上40.5%无任何提升。
深度网络生成的显著图:看下表。

4.3.3 对显著图提升行人检测的分析

5 结论与以后工作
两点贡献:
1是公开注释
2是显著图
未来方向:将训练显著网络的过程加入到主干网络,实现共享卷积以及端到端的多任务训练类似rpn于fast rcnn。将显著图加入到Rgb图中实现同样的效果。















 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









