







1. 研究问题
现有的主动立体方法难以在极端照明和复杂场景中进行可靠的深度估计,原因是照明图案独立于重建算法和环境照明而设计,无法端到端学习最佳照明图案和重建算法。
2. 研究方法
提出一种以端到端的方式联合学习结构光图案和重建网络的方法,该方法由衍射光学元件和神经网络参数化。首先依据波动光学和几何光学为主动立体引入了一个可微混合成像模型,对结构光图案进行参数化。然后提出一个三目重建网络,以监督的方式联合学习最佳的结构光图案(Polka lines)和重建网络,Polka lines可用于特定的环境照明。又提出以自监督学习的方式微调重建网络,以补偿优化DOE的制造误差以及模拟训练图像和真实捕获图像之间的域偏移。
2.1 可微成像模型
为了联合学习照明图案和重建算法,文章提出用于主动立体视感知的可微成像模型,模拟主动立体视觉系统中的光传输,模型包含两部分:
(1)投影图案建模(波动光学)
(2)立体图像建模(几何光学)
先给出立体视觉系统的结构,如Fig 1所示,由立体相机和照明模块组成,照明模块是由激光投射器照明的DOE构成。
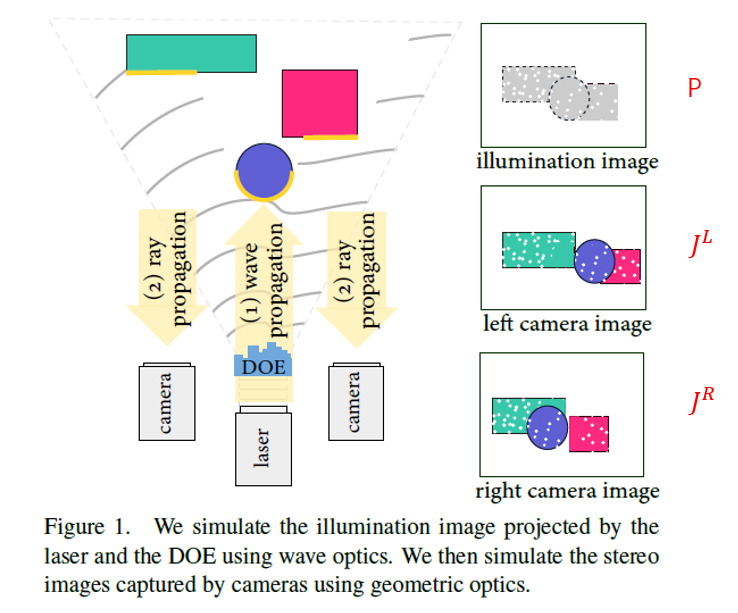
投影图案建模
依据波动光学,激光投射器打出去的光 U U U可以用幅值A和相位 ϕ \phi ϕ表示。幅值和光功率有关,是固定的,相位和空间位置有关。对空间离散化,每一个位置用 ( x , y ) (x,y) (x,y)表示,采样的分辨率是 N ∗ N N*N N∗N(文章设置N=1000,也就是说照明图案的原始分辨率是1000*1000),采样的像素间隔是 u u u(文章设置 u = 1 μ m u=1\mu m u=1μm,这是原始的采样间隔)。
DOE上的相位延迟:
激光经过DOE(DOE是衍射光学元件,其实就是一个多缝夫琅禾费衍射元件)时,相位会发生延迟
ϕ
d
e
l
a
y
\phi_{delay}
ϕdelay,
ϕ
d
e
l
a
y
\phi_{delay}
ϕdelay跟DOE的高度
h
h
h、激光波长
λ
\lambda
λ、DOE对激光的反射率
η
λ
\eta_{\lambda}
ηλ有关,如下式:
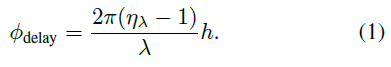
所以,激光经过DOE后,其相位会变成:
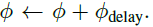
远场波传播:
光经过DOE后,到达场景的传播过程,可以用夫琅禾费远场波传播来建模(这里用到了傅里叶光学的知识),因此,对光波U进行傅里叶变换:

然后投影图案的强度
P
P
P可以表示为:

P
P
P的分辨率和
U
U
U一致(1000*1000),但单个像素的物理尺寸
v
v
v跟深度
z
z
z(传播距离)有关:
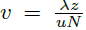
重采样照明图案:
后文会将投影图案和左右图像进行立体匹配,因此要确保两者的像素物理尺寸和分辨率一致。这里就是对照明图案重采样,使照明图案的像素物理尺寸和立体图像的像素物理尺寸保持一致。
立体图像的像素物理尺寸也跟深度
z
z
z有关,是
p
z
/
f
pz/f
pz/f,因此尺寸缩放因子为:
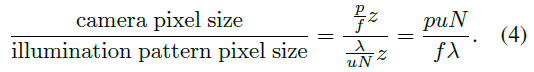
用该缩放因子对照明图案重采样,采用双三次插值算法进行插值计算:
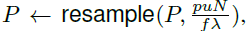
因为缩放因子与深度
z
z
z无关,说明照明图案可以用于各种深度的场景(因为不管什么深度,都可以用这个固定比例进行重采样,然后结合立体图像进行深度感知)。
这里只讲了重采样,后面在制作数据集的时候会讲到resize,使照明图案和立体图像的分辨率保持一致的。
立体图像建模
依据几何光学,直接用强度对光建模,而不是用幅值和相位。光经过镜头进入立体相机传感器,形成一定的强度。
我们先定义几个记号:
D L / R D^{L/R} DL/R:照明图案跟左右相机图像的视差图
I L / R I^{L/R} IL/R:左右相机视点下的场景反射率
O L / R O^{L/R} OL/R:左右相机和投影仪之间的可见区域
P L / R P^{L/R} PL/R:左右相机视点下的照明图案
J L / R J^{L/R} JL/R:左右图像
γ \gamma γ:相机对光的响应(描述曝光和传感器光谱量子效率的标量)
α \alpha α:环境光强度
β \beta β:激光照明的功率
η \eta η:高斯噪声
σ \sigma σ:强度截断函数
使用
D
L
/
R
D^{L/R}
DL/R来warp照明图案P到左右相机视点,然后再与
O
L
/
R
O^{L/R}
OL/R做像素的乘积,我们就可以得到
P
L
/
R
P^{L/R}
PL/R:
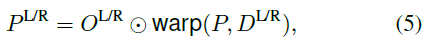
有了左右视点下的照明图案,我们就可以通过朗伯模型来计算左右图像了(因为左右图像的亮度是跟物体表面反射率,环境光强度,照明图案亮度等有关的):
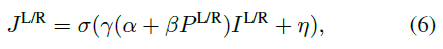
总结:利用波动光学和几何光学构建一个可微成像模型,模拟主动立体系统的光学传输,这个模型可以用来计算照明图案和左右图像,并且基于这个模型,后面构建的三目主动立体网络才能够同时对照明图案和重建网络进行优化。
2.2 三目主动立体网络
主动立体系统中,左右图像之间含有深度信息,同样的,照明图案和左右图像之间同样含有深度信息。基于此,文章考虑两种基线配置:
- 短基线:照明模块和左右相机之间
- 长基线:左右相机之间
基于两种基线配置,文章提出了三目主动立体网络。文章在仿真阶段的网络和真实实验阶段的网络有些区别,下面分别对两个网络展开阐述。
仿真实验阶段网络:
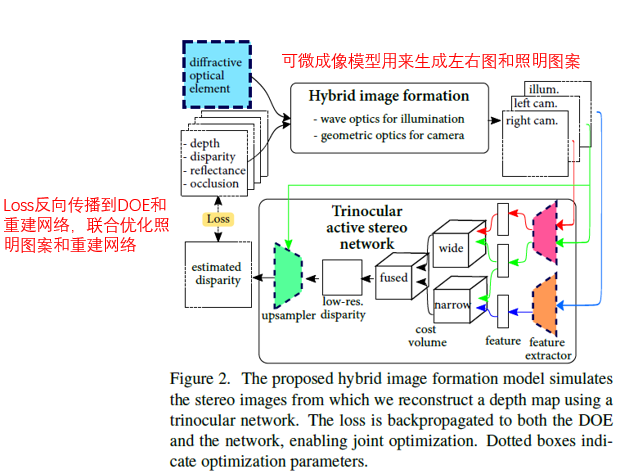
注:仿真网络得到的视差图也没有说明是左右图像之间的视差还是投影图案和左图的视差,有点迷惑。
真实实验阶段网络:
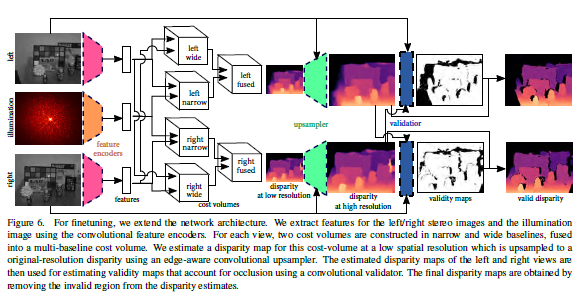
该网络与仿真阶段网络主要有两个不同:
- 对左图和右图都估计视差图(相对于照明图案),其方法和仿真阶段一样。
- 自监督网络validation network,这个网络根据估计的视差图来计算有效区域,将遮挡和高光区域去除掉,具体的思路如下:
- 用文献[4]的左右一致性检测网络,将估计的视差图warp到另一相机视点,然后和原始估计的视差图做差。
- 再结合立体图像,放入validation network,得到左右视点下的有效区域的掩模图像。
损失函数修改如下:

注1:在该网络中,validation network要重新训练,用后面提到的真实数据集中的76个样本用来进行训练,相当于重新训练validation network的参数 ϑ \vartheta ϑ,以及微调训练阶段得到的重建网络参数 θ \theta θ。这种自监督的训练称为离线训练(离线学习),我们可以在实际的深度重建过程引入在线训练(在线学习),这样能够不断的微调网络参数,使得深度效果更好。文章中也没有提到是否应用了在线自监督,笔者认为应该是应用了。
注2:该网络得到的视差图有两个,分别是投影图案和左右图像的视差。具体做深度重建的时候,还需要考虑究竟用的是短基线还是长基线,这取决于用什么视差图。
网络细节:
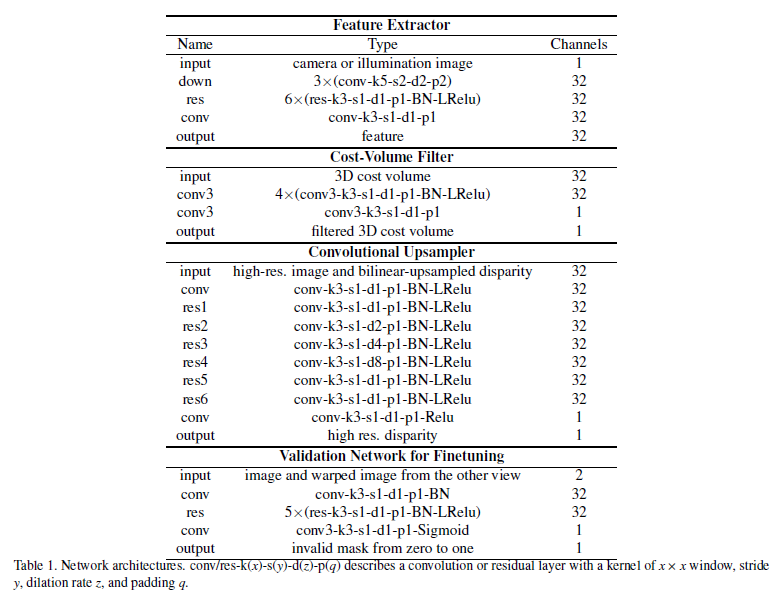
这里面用到的网络还有残差网络。
重建网络
这里的网络结构讲的是仿真网络和真实阶段网络的共同部分
- 输入:
- X L X_L XL:左图
- X R X_R XR:右图
- X i l l u m X_{illum} Xillum:照明图案
对于仿真实验,这些输入由可微成像模型计算得到
对于真实实验,这些输入由极线校正的相机图像得到,后面会说
-
特征提取器:对左右图像和照明图案进行特征提取
-
代价空间计算:基于立体匹配的原理,使用提取的特征计算匹配代价空间
-
左右图像的代价空间
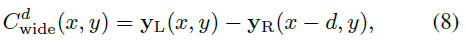
-
左图和照明图案的代价空间
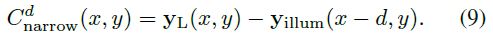
-
总的匹配代价
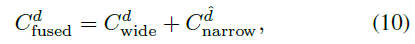
其中:
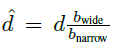
-
-
计算低分辨率视差图:使用一个softmax层,对视差进行回归,得到一幅低分辨率的视差图,参考文献[1]
-
卷积上采样:对低分辨率视差图进行上采样,得到跟原图大小一样的视差图(以左图为参考图像)
联合学习
定义待优化参数的记号:
θ \theta θ:重建网络参数
ϕ d e l a y \phi_{delay} ϕdelay:DOE的相位延迟参数(跟DOE的高度分布有关)
根据网络的前向传播,我们可以得到估计的视差图,用真实视差图对其进行监督,将估计误差反向传播,不断优化上述参数。采用平均绝对误差(MAE)构建损失函数
L
S
L_S
LS,并采用随机梯度下降算法(SGD)对其优化:

在可微成像模型中,我们可以根据不同环境光强度,设置不同的参数,这样,就可以训练出针对于各种环境的的照明图案和重建网络。文章针对一般环境、室内环境和室外环境训练了三个模型。
数据集
文章做了仿真实验和真实实验。下面对两组实验的数据集进行介绍。

- 仿真数据集
- 文献[2]的合成被动立体RGB数据集(包含视差图 D L / R D^{L/R} DL/R,这里的视差图是左右图之间的视差,注意:文章没有把视差图交代清楚,因为文章既用到左右图视差,也用到投影图案和左右目的视差,但如果投影仪放在立体相机中间,那么投影图案和左右目的视差应该是左右图视差图的一半。)
- 根据文献[3]从RGB图像中获得 I L / R I^{L/R} IL/R。
- 根据 D L / R D^{L/R} DL/R(左右目视差图)计算 O L / R O^{L/R} OL/R(这里的 O L / R O^{L/R} OL/R是左右目的遮挡区域),然后再将遮挡图水平缩小一半,得到的就是照明视角和左右目的遮挡区域 O L / R O^{L/R} OL/R。
- 将上面得到的所有图像全部都resize成照明图案大小。这里回应前面重采样照明图案那一小段说的保持分辨率一致。
- 数据集中,21718个样本用作训练,110个样本用作测试。
- 真实数据集
- 立体相机拍摄左右图像,并用已经标定好的系统参数进行畸变校正和极线校正。
- 照明图案是已知的,和仿真图案一致。
- 76个室内环境的真实立体图案用作自监督微调,这些样本是用来训练自监督模块的参数以及微调仿真阶段得到的重建网络的参数的。
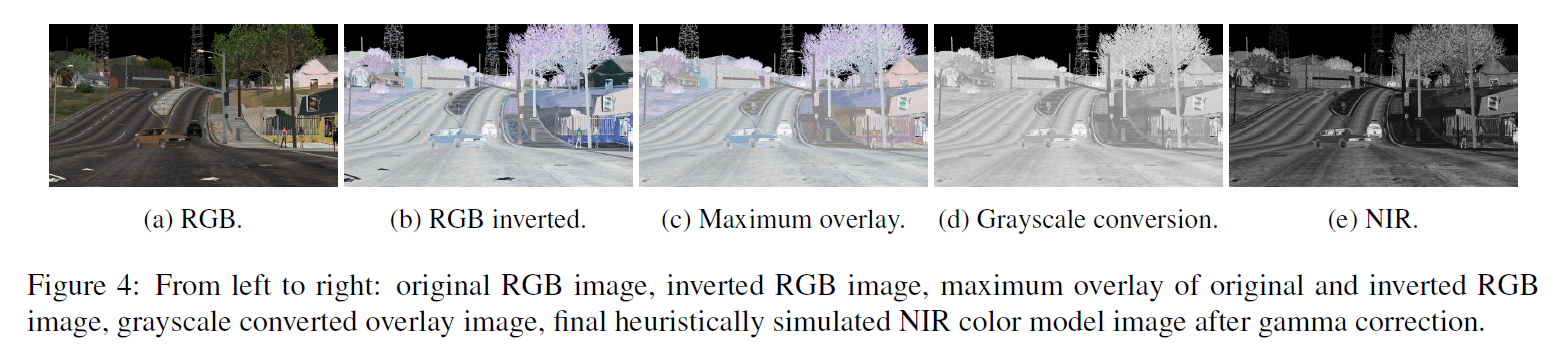
获取NIR reflectance map I L / R I^{L/R} IL/R的方法:
-
将原始RGB图像反转;
-
将原始RGB以及反转RGB图像中每个像素的每个通道的最大值挑选出来,称为I_{NIR}
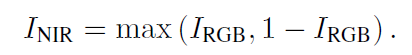
-
对I_{NIR}进行灰度变换得到Y
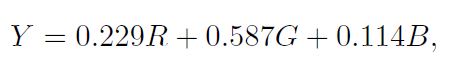
-
Y代表NIR的亮度,由于第二步的最大重叠操作,图像的亮度变得很大,因此使用gamma变换降低亮度,gamma = 0.25,得到最终的NIR灰度图。
过程如下图所示。
3. 实验分析
3.1 仿真实验
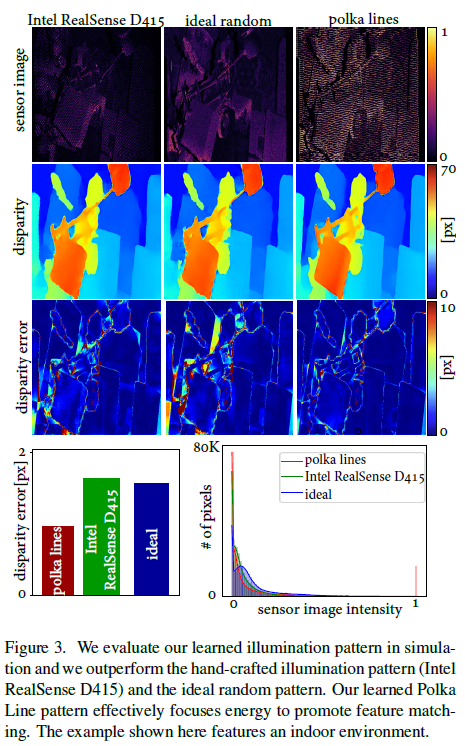
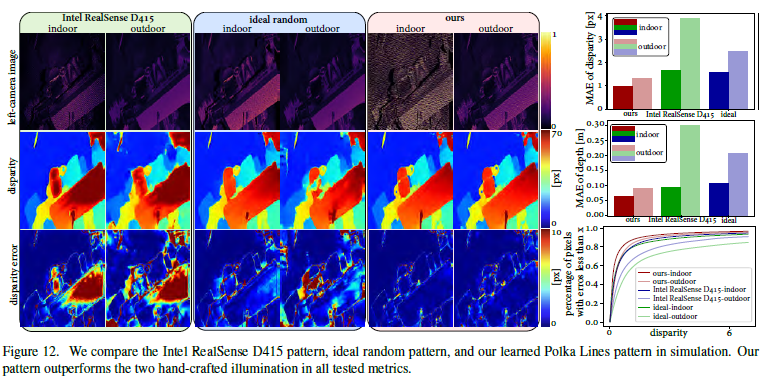
- Polka lines 照明图案:这里是通过改变公式(6)中的环境参数,模拟了室内外环境,然后通过视差图的重建结果对比了三种图案, 结果显示Polka lines 的效果最好。原因有二:
- 相比于固定强度的图案,Polka lines图案有变化的灰度级。
- Polka lines的方向是局部变化的,可以作为匹配的可区分特征。
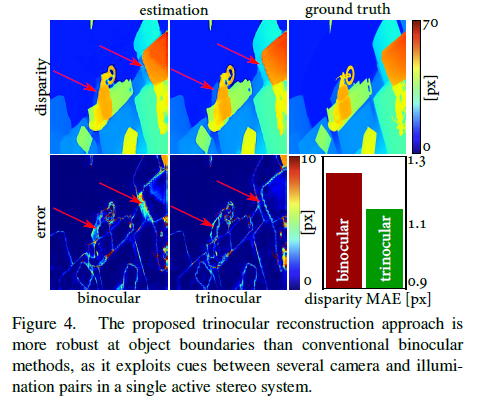
- 三目重建网络学习:将本文的联合学习方法和传统的双目方法作对比,结果显示本文的方法在物体边界、遮挡区域的精度更高。
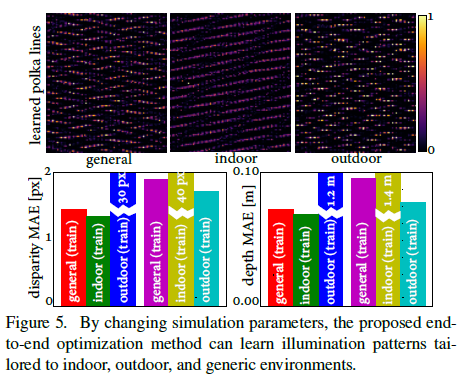
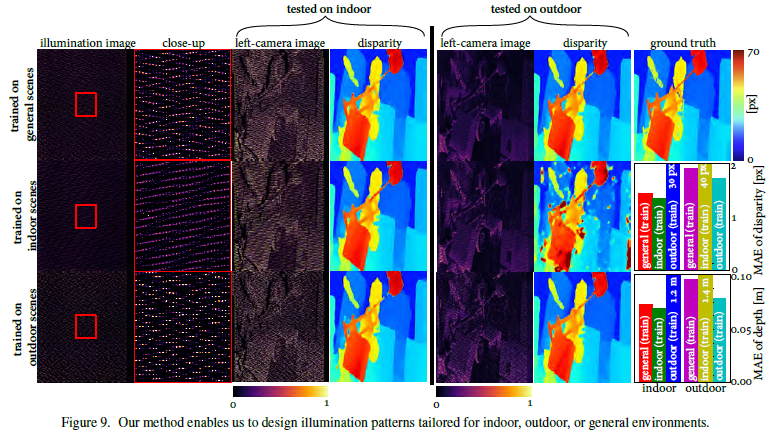
- 特殊环境照明图案,有两个实验:
-
通过改变公式(6)的环境参数和求解优化问题公式(11),得到了室内、室外、一般三种环境光环境的Polka lines图案。

-
通过改变公式(6)的噪声项,模拟强噪声(标准偏差为0.6)和普通噪声(标准偏差为0.02)环境下的Polka lines。

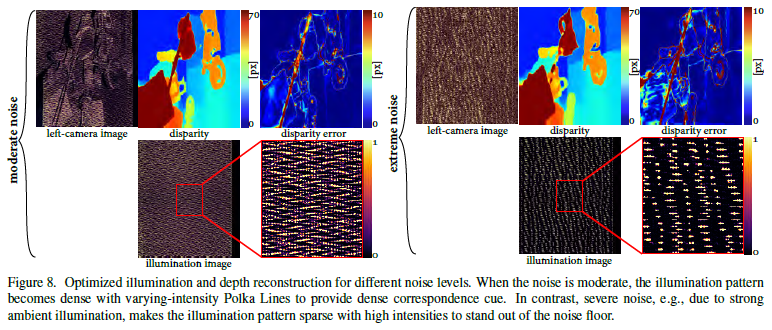
-
总结:上述关于不同环境、噪声的实验中,结果显示出不同的Polka lines图案,说明文章的算法可以根据不同环境来优化出相应的最佳照明图案。
-
- DOE相位设计:
-
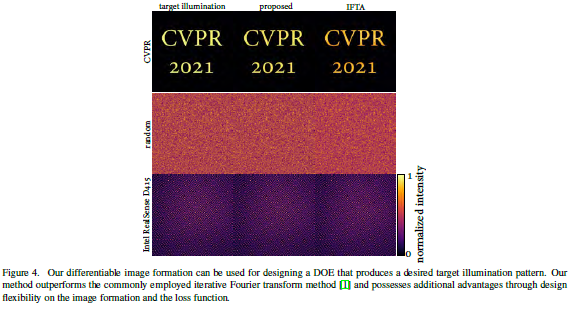
文章的可微成像模型还可以通过迭代优化来生成给定的照明图案,如下面公式所示, I i l l u m I_{illum} Iillum根据可微成像模型建模, I t a r g e t I_{target} Itarget是给定图案,可以通过Adam优化器来优化迭代,从而生成 I t a r g e t I_{target} Itarget一样的图案。
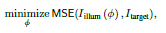
-
通过与最新方法IFTA对比,文章的可微成像模型生成的图案与target图案更接近。

-
- 可微成像模型生成图案的应用:
- 设定特定的DOE高度图(根据不同需求),我们可以通过可微成像算法算出照明图案。
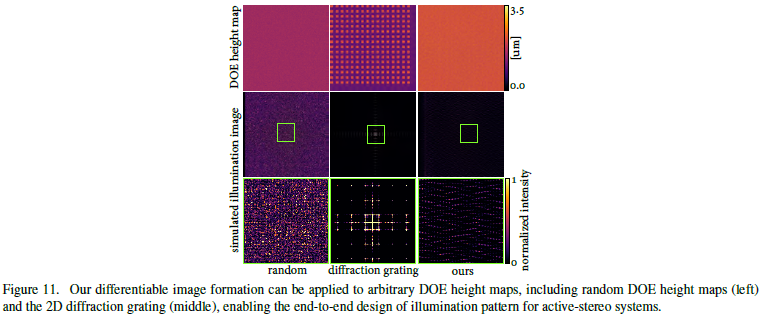
- 用上面得到的图案作为初始化图案,然后进行端到端网络训练优化,得到的最终图案大致相同,说明网络的高鲁棒性。

- 设定特定的DOE高度图(根据不同需求),我们可以通过可微成像算法算出照明图案。
3.2 真实实验
-
实验配置:
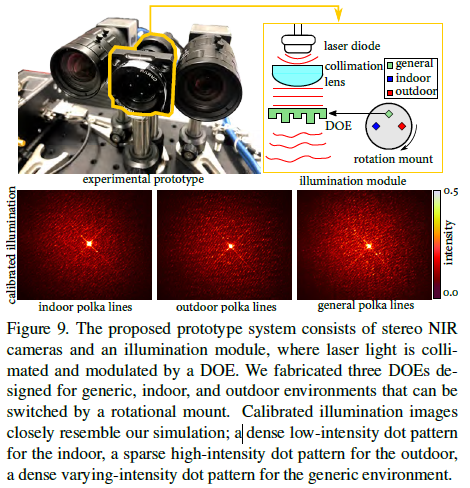
- 使用立体相机和Laser-DOE照明模块来搭建实验系统,文章使用16级光刻技术制作了一个DOE,而且可以根据旋转角度的不同而打出针对于室内、室外、一般环境的照明图案,打出的照明图案和仿真图案基本一致。
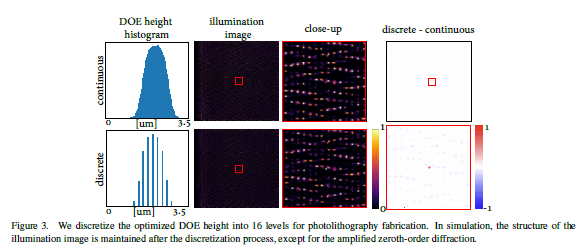
- 文章对16级光刻技术制作的DOE做了仿真实验,离散化的16级高度DOE打出的光和连续高度的DOE打出的光基本一致,除了零阶衍射分量被放大了。
- 使用立体相机和Laser-DOE照明模块来搭建实验系统,文章使用16级光刻技术制作了一个DOE,而且可以根据旋转角度的不同而打出针对于室内、室外、一般环境的照明图案,打出的照明图案和仿真图案基本一致。
-
深度重建,这里也有两个实验:
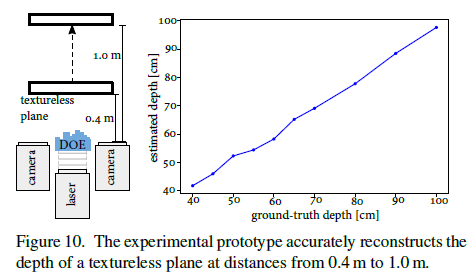
- 在0.4m到1.0m的距离内,对无纹理平面进行深度重建,从图中可见,估计的深度与真实深度几乎一致。
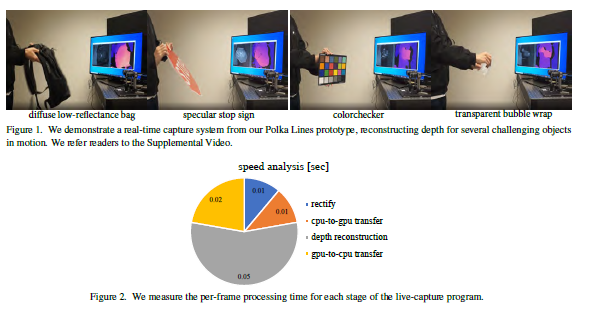
- 复杂场景的深度重建,包括复杂物体,动态移动,无纹理物体,环境光从无到有,算法速度可以达到10fps。文章的算法是用Python写的,如果用C++写,速度可以更快一些。

- 在0.4m到1.0m的距离内,对无纹理平面进行深度重建,从图中可见,估计的深度与真实深度几乎一致。
-
对比,有两组实验:
-
用Polka lines图案和Realsense图案的重建效果作对比
-
为了确保实验结果可靠,先在仿真阶段进行辐射校正保证两个图案的平均照明强度一致。
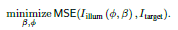
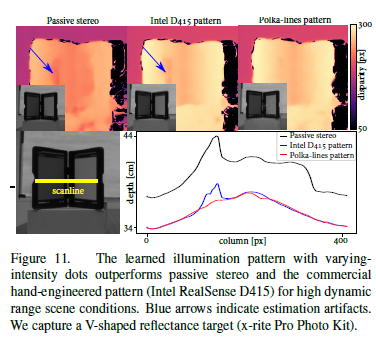
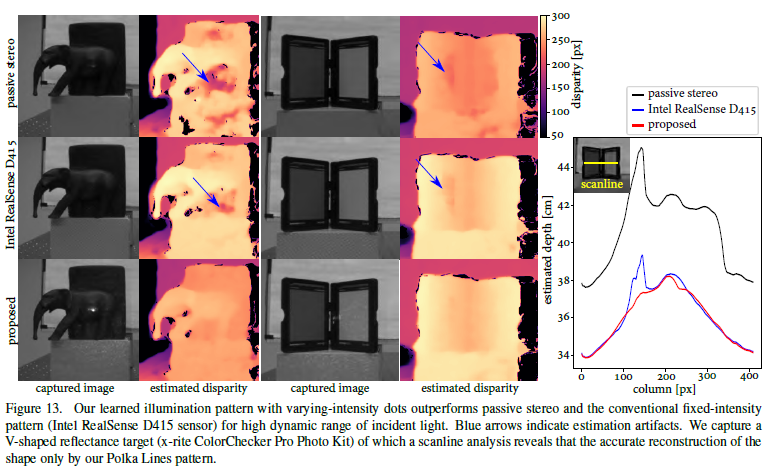
-
上面公式中,先给定一个目标图案,通过迭代优化得到相位 ϕ \phi ϕ和Laser光功率 β \beta β
-
然后用得到的 β \beta β来归一化Realsense打出的照明图案强度,这里应该是因为Realsense的激光强度可以调节。
-
用 β \beta β作为超参数,通过端到端网络来训练Polka lines图案。然后制作DOE。
-
在实际中用积分球测量Realsense的光强度和Polka lines的DOE的光强度,确保平均光强度一致。然后进行深度重建。
-
结果显示,文章的深度图没有伪影,而且对V型面的重建效果最好。而且Polka lines图案的点更小,并具有变化的强度。

-
-
对低反射率的平面物体进行重建,结果显示适合于一般环境的DOE的深度重建效果比适用于室内环境的DOE的深度重建效果更好。也就是说一般环境DOE更适合于对低反射率物体进行深度重建。

-
4. 结论
- 基于波动光学和几何光学,提出了适用于主动立体视觉的新的可微成像模型。
- 设计了一个用于真实环境的三目主动立体网络,使用已知的照明图案(经过仿真过程得到的优化图案)进行深度重建,而且引入了自监督网络(微调参数)对深度进行优化。
- 设计了一个用于仿真训练的可微端到端网络,联合学习Polka lines照明图案和重建网络,通过设置不同的环境参数,Polka lines照明图案适用于不同的环境。
- 通过仿真实验和真实实验,验证了从环境光到强环境光下,本文的方法都可以进行鲁棒的深度重建。
参考文献
[1] Zhang Y , Khamis S , Rhemann C , et al. ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems[J]. 2018.
[2] Mayer N , Ilg E , Hausser P , et al. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation[J]. IEEE, 2016.
[3] Gruber T , Julca-Aguilar F , Bijelic M , et al. Gated2Depth: Real-time Dense Lidar from Gated Images[C]// 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019.
[4] Godard C , Aodha O M , Brostow G J . Unsupervised Monocular Depth Estimation with Left-Right Consistency[J]. 2016.















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









