






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
前言
当数据集没有任何标签时,该怎么办?
无监督学习是一组机器学习算法和方法,这些算法和方法处理这种“非基于事实”的数据。
这篇文章将介绍什么是无监督学习,它与大多数机器学习有何不同,在实现过程中遇到的一些挑战。
什么是无监督学习
无监督机器学习不能直接应用于回归模型,因为它不知道输出值可能是什么,因此不可能像通常那样训练模型。
可以这样理解:当你在学校参加考试时,会有问题和答案;你的分数取决于你的答案与实际答案(或答案键)的接近程度。但是想象一下,如果没有答案,只有问题。
你如何给自己打分?
现在把这个框架应用到机器学习中。传统的机器学习任务中数据集有标签(想想看:答案键,并遵循“X导致Y”的逻辑。例如:我们可能想弄清楚Twitter上粉丝多的人他(她)的工资是否更高。我们认为我们的输入(Twitter关注者)可能会导致我们的输出(工资),我们试图近似这种关系是什么。
星星代表数据点,机器学习算法将拟合出一条直线来表达输入和输出的相关性。但是在无监督学习中,是没有输出数据的。我们只有输入数据推特粉丝数,就好像考试没有答案一样。
那么,无监督学习的目标到底是什么呢?当我们只有没有标签的输入数据时,我们该怎么办?
无监督学习的类别
聚类
任何企业都需要集中精力了解客户:他们是谁,是什么在驱动他们的购买决策?您通常会有不同的用户组,这些用户组可以根据几个条件进行划分。这些标准可以很简单,比如年龄和性别,也可以很复杂,比如角色和购买流程。无监督学习可以帮助你自动完成这项任务。集群算法将遍历您的数据并找到这些自然集群(如果它们存在的话)。对你的客户来说,这可能意味着一群30多岁的艺术家和另一群拥有狗的千禧一代。通常可以修改算法查找的聚类数目,从而调整这些组的粒度。有几种不同类型的聚类算法你可以使用:k-means聚类:将您的数据点聚集成K个互斥集群。如何为K选择正确的数字是很复杂的。
Hierarchical聚类:将数据点聚集到父集群和子集群中。您可以将您的客户划分为更年轻和更年长的层级,然后在这些组中继续划分为各自的集群。
probabilistic聚类:将您的数据点按概率规模聚集成集群。
任何集群算法通常都会输出所有数据点及其所属的集群。由您来决定它们的含义,以及算法究竟找到了什么。与许多数据科学一样,算法也只能做这么多:当人类与输出交互并创造意义时,价值就产生了。
数据压缩
即使过去十年在计算能力和存储成本方面取得了重大进展,仍然有必要尽可能地保持数据集的小而高效。这意味着只在必要的数据上运行算法,而不进行太多的训练。无监督学习可以通过降维过程来帮助解决这个问题。
降维依赖于信息理论:它假定大量的数据冗余,而你最能代表一个数据集的信息只有实际内容的一小部分。在实践中,这意味着以独特的方式组合部分数据来传达意义。
有一些常用的算法来降低维数:主成分分析(PCA) -找出可以表示数据中大部分方差的线性组合。
奇异值分解(SVD)——将数据分解成另外三个更小的矩阵的乘积。
这些方法以及它们的一些更复杂的同类方法都依赖于线性代数中的概念,将一个矩阵分解成更易于理解和信息的部分。
数据降维可能是良好的机器学习算法流程中重要的组成部分。以计算机视觉这个新兴领域的图像中心为例,如果您可以将训练集的大小减少一个数量级,就可以显著降低计算和存储成本,同时使模型运行得更快。这就是为什么在成熟的机器学习管道的预处理过程中,会使用PCA或SVD处理图像。
生成模型
生成模型是一类非监督学习模型,其中训练数据是给定的,新样本是从相同的分布中产生的。这些模型必须发现并有效地学习给定数据的本质,以尝试生成类似的数据。这种模型的长期益处是它能够自动学习给定数据的特征。
生成模型的一个常见例子是图像数据集生成。给定一组图像,生成模型可以生成一组与给定图像相似的图像。无监督的深度学习
不出所料,无监督学习也被扩展到神经网络和深度学习。这一领域仍处于初级阶段,但在无监督模式下深度学习的一个流行应用被称为自动编码器。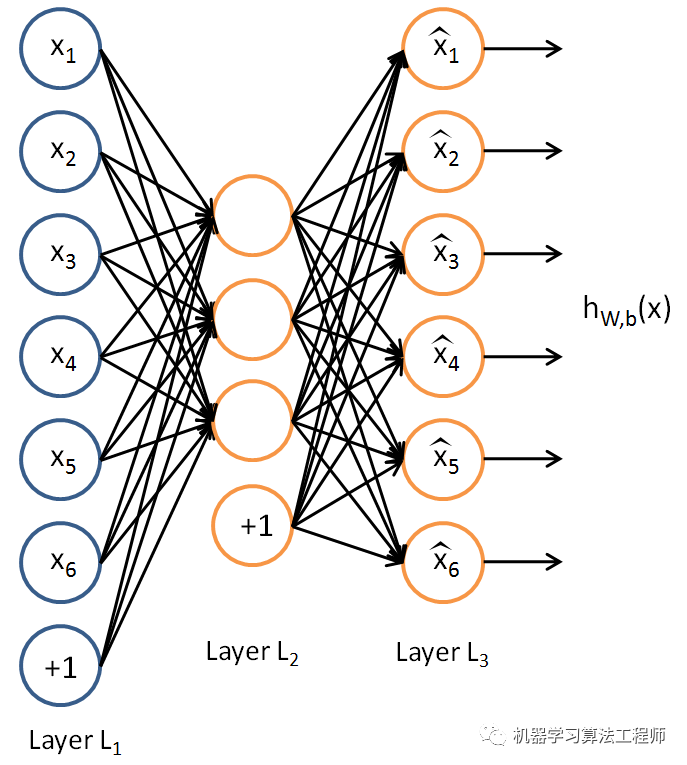
自动编码器遵循与上述数据压缩算法相同的原理——使用更小的特性子集来表示原始数据。与神经网络类似,自动编码器使用权重来尝试将输入值塑造成所需的输出;但是这里的巧妙之处在于输出和输入是一样的!换句话说,自动编码器试图找出如何最好地表示我们的输入数据本身,使用比原来更少的数据量。
自动编码器已经被证明在诸如物体识别等计算机视觉应用中是有用的,并且正在被研究和扩展到音频和语音等领域。
应用无监督学习中的挑战
除了寻找合适的算法和硬件等常规问题外,无监督学习还提出了一个独特的挑战:如何判断你是否完成了任务。
在监督学习中,我们定义了调优决策的指标阿里驱动模型。像precision 和recall这样的指标可以让你知道你的模型有多精确,然后调整模型的参数来增加这些提高性能。
因为在无监督学习中没有标签,所以几乎不可能得到一个合理的、客观的关于你的算法有多精确的度量。例如,在集群中,您如何知道K-Means是否找到了正确的集群?首先,您是否使用了正确数量的集群K?
“非监督学习对我有用吗?”。这个问题完全取决于你的业务环境。在我们的客户细分实践案例中,只有当您的客户分组正确时,集群才能很好地工作。测试你的非监督学习模型的最好(但也是最危险的)方法之一就是在现实世界中实现它,然后看看会发生什么!设计一个A/B测试——有或没有输出的算法集群——可以是一种有效的方式来查看它是否是有用的信息或完全错误的。
参考文献:
文章翻译自:
- [Introduction to Unsupervised Learning](https://algorithmia.com/blog/introduction-to-unsupervised-learning)
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









