






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文想与大家分享一下我们在使用人工智能技术自动生成数据标签方面所做的工作。
在我们深入了解我们的方法之前,首先让我们了解一下数据标签是什么。
在机器学习中,数据标记只是识别原始数据(图像、视频、音频文件、文本文件等)的过程,并添加一个或多个有意义且信息丰富的标签以提供上下文,以便机器学习模型可以从中学习和推断。
大多数最先进的机器学习模型高度依赖于大量标记数据的可用性,这是监督任务中必不可少的一步。各种用例都需要数据标签,包括计算机视觉、自然语言处理和语音识别。
传统上,到目前为止,标记数据的这一繁琐而平凡的过程主要是由人类完成的。为了帮助人类从零开始尽可能减少数据标记的工作和努力,我们提出了一种自动化算法解决方案,旨在减少大量手动工作。
在这里,将讨论计算机视觉任务。计算机视觉仅仅是复制人类视觉(人眼视觉)的复杂性和对周围环境的理解。计算机视觉任务包括获取、处理、分析和理解数字图像的方法,以及从现实世界中提取高维数据以产生数字或符号信息的方法,例如以决策的形式。
在计算机视觉领域,有许多不同的任务。将不详细介绍这些任务,例如分类、检测、分割等。但是,下图提供了这些任务的清晰概述和目标,并给出了上下文中对象的示例——“香蕉”。
一个示例上下文-标记数据的需求
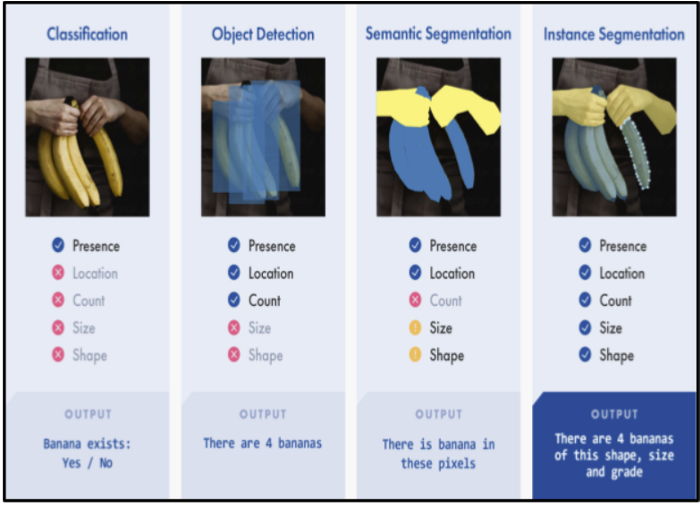
对于检测对象“香蕉”的监督模型,注释标签被馈送到模型,以便它可以学习香蕉像素的表示,并在上下文中对其进行定位,然后可以使用上下文来推断不可见/新数据。
实例分割任务旨在检测对象,定位这些对象,并提供它们的数量、大小和形状信息。
我们使用这样一种最先进的实例分割模型——“Mask R-CNN”作为我们框架的核心主干,但在这里,我们可以根据其需求和目标使用任何其他网络体系结构。
我们坚持使用mask R-CNN,因为它可以有效地检测图像中的对象,同时为每个对象生成高质量的分段掩码。对于我们检测到的新冠病毒感染的特定测试用例,感染区域的精确位置至关重要,因此像素级检测在这种情况下更合适。
我们的方法
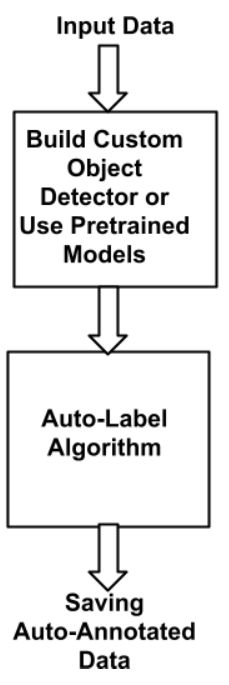
我们工具的管道如下图所示,主要由检测器和跟踪器、自动标签模块和I/O模块组成,用于将机器注释标签输出并保存到磁盘。
步骤1:-目标检测和跟踪以进行像素级分类
一个定制的弱训练mask-RCNN模型用于检测极少数标记实例(<10个样本)的新冠病毒感染。
为了标记感染区域,我们使用VGG图像注释器(VIA)图像注释工具。这是一个简单和独立注释图像,音频和视频的软件。
VIA在web浏览器中运行,不需要任何安装或设置。完整的VIA软件可以放在一个独立的HTML页面中,页面大小小于400KB,在大多数现代web浏览器中作为离线应用程序运行。
VIA是一个完全基于HTML、Javascript和CSS(不依赖于外部库)的开源项目。VIA由Visual Geometry Group(VGG)开发,根据BSD-2条款许可证发布,可用于学术项目和商业应用。
检测器用于获取本地化的掩码、边界框和类。接下来,为了沿着输入视频数据流对多个感染区域进行统一跟踪和标记,我们使用了中心点跟踪算法。下面给出了我们的mask RCNN covid检测器的一个片段。
# 使用MaskRCNN进行对象检测
def MaskRCNNDetection(self, frame, epsilon=None, auto_mask=True):
'''
通过掩码来检测帧中的对象
:param frame: BGR格式的图像。
:type frame: :class:`numpy.ndarray`
:param None epsilon: 仅用于具有一致性,没有在算法中使用
:param bool auto_mask: 是否自动掩码
:return: 返回带有边界框的帧的副本。
:rtype: :class:`numpy.ndarray`
'''
frame_copy = frame.copy()
result = self._models['mrcnn'].detect([frame_copy])[0]
N = result['rois'].shape[0]
if N == 0:
return frame_copy
rects = []
object_info = []
for i in range(N):
y1, x1, y2, x2 = result['rois'][i]
rects.append((x1, y1, x2-x1, y2-y1))
# 保存掩码以删除手动注释工作
if auto_mask:
self._autoLabel(frame, rects, result['masks'])
mask = np.where(result['masks'].any(axis=2), 255, 0)
mask = mask.astype(np.uint8)
masked = cv2.bitwise_and(frame_copy, frame_copy, mask=mask)
# print(frame.shape, mask.shape, masked.shape)
add_thread = Thread(target=self._addAllFeatures,
args=(rects, masked, object_info))
add_thread.start()
object_ids = self._update(rects)
for i, object_id in enumerate(object_ids):
object_info[i]['id'] = object_id
for (x, y, w, h), object_id in zip(rects, object_ids):
# 在输出帧上绘制对象的ID和对象的质心
centroid = [x + w//2, y + h//2]
text = f'covidInfectionMaskID-{object_id:03d}'
cv2.putText(frame_copy, text, (centroid[0] - 10, centroid[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# 在感染周围绘制边界框
cv2.rectangle(frame_copy, (x, y), (x+w, y+h), (0, 255, 0), 2)
# cv2.circle(frame_copy, (centroid[0], centroid[1]), 2, (0, 0, 255), -1)
add_thread.join()
self._output.append(object_info)
self._gf = pd.DataFrame(object_info)
self._gf = self._gf[self._gf_params]
return frame_copy步骤2:-逐帧数据标记
来自预训练的检测器模型的推理用于获取边界框的位置,并创建json元数据。
一旦使用Mask RCNN对帧进行分割,就会生成相应的感兴趣区域(ROI)。此外,生成每个ROI的掩码,然后在整个图像帧上进行轮廓检测。然后,从轮廓中提取(x,y)坐标。最后,这些形状、区域和坐标属性逐帧保存到磁盘中。
下面给出了我们的自动标记算法的片段。
def _autoLabel(self, img, rects, masks):
with open(self._via_export_json, 'r') as fr:
json_file = json.load(fr)
regions = []
N = len(rects)
for i in range(N):
mask = masks[..., i]
mask = np.where(mask, 255, 0).astype(np.uint8)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(contours) == 1:
contour = contours[0].reshape(-1, 2)
x = list(map(int, contour[:, 0]))
y = list(map(int, contour[:, 1]))
regions.append({
'shape_attributes': {
'name': 'polyline',
'all_points_x': x,
'all_points_y': y
},
'region_attributes': {}
})
fn = f'covid{self._last_image_count + 1}.png'
fp = join(self._auto_mask_dir, fn)
if cv2.imwrite(fp, img):
filesize = getsize(fp)
info = {
'filename': fn,
'size': filesize,
'regions': regions,
'file_attributes': {}
}
json_file[fn+str(filesize)] = info
self._last_image_count += 1
# 保存数量
with open(self._last_img_fn, 'w') as fw:
fw.write(str(self._last_image_count))
# 保存JSON文件
with open(self._via_export_json, 'w') as fw:
json.dump(json_file, fw)示例-新冠病毒-19感染检测和自动标记
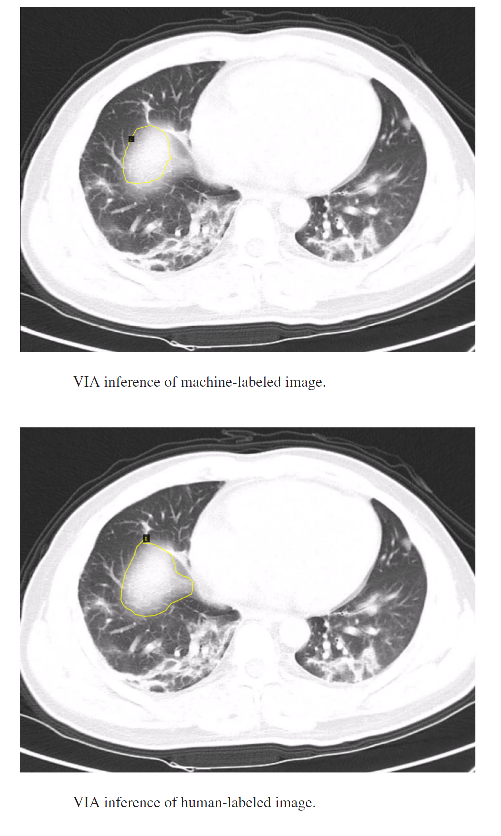
我们测试了我们的方法,目的是为新冠病毒感染区域自动生成计算机标签。
机器生成标签和人工标注标签的结果如下所示。可以看出,自动注释引擎生成的合成标签质量相当好,可用于重新训练对象检测模型或生成更多可用于不同任务的注释数据。
总结
数据标记是一项非常重要的任务,也是有监督学习管道的关键组成部分之一。
这是一项需要大量手动操作的任务。那么,我们就可以让这些平凡的、劳动密集型的、耗时的工作中的大部分由机器自主驱动,从而最大限度地减少人类的大部分任务。
注意:-我们的工具目前处于alpha测试阶段。目前,我们设计的框架基于mask R-CNN和VIA注释格式。
我们还希望将我们的原型推广到包括不同的最先进的检测器,例如YOLO和相应的YOLO兼容注释格式。此外,我们还计划集成COCO注释格式。它值得将所有不同的图像注释集成为我们框架的一部分,同时为设施提供不同的库,即Torch、TensorFlow、Caffe等。
在这里查看github页面https://github.com/ajayarunachalam
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 2956
2956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









