






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达导读
本文将详细介绍如何将红酒瓶上的曲面标签展平并做文字识别。(公众号:OpenCV与AI深度学习)
背景介绍
本文的目标是让计算机从一张简单的照片中读取一瓶红酒上标签文字的内容。因为酒瓶标签上的文本在圆柱体上是扭曲的,我们无法直接提取并识别字符,所以一般都会将曲面标签展平之后再做识别,以提升准确率。

第一部分:传统方法提取标签
以上图为例,先尝试使用传统图像处理方法提取标签轮廓。
【1】转为灰度图 + 自适应二值化


【2】高斯滤波平滑 + 固定阈值二值化
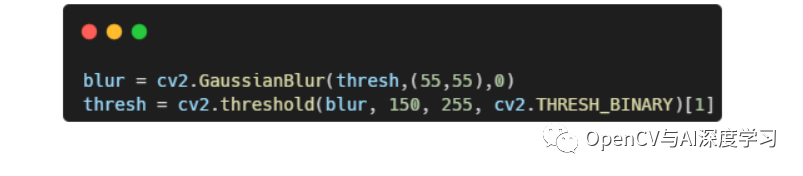

【3】轮廓提取排序,查找最大面积轮廓
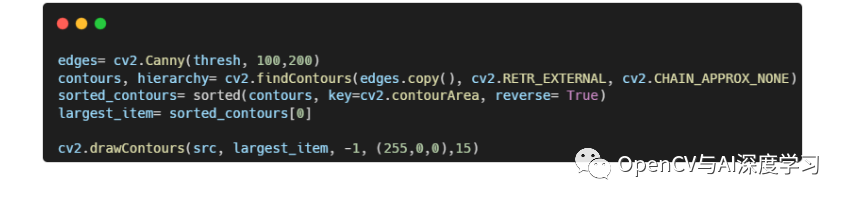

【4】批量测试,检测算法稳定性

批量测试后发现在其他图片上并不能很好的提取标签轮廓,所以我们需要考虑其他方法来解决。
第二部分:使用深度学习图像分割网络(U-Net)提取标签
【1】准备数据集(图像 + mask标签)

【2】训练U-Net网络模型
U-Net网络代码(TensorFlow实现):
def build_model(self, Config):
inputs = tf.keras.layers.Input((256,256,3))
s = tf.keras.layers.Lambda(lambda x: x / 255)(inputs)
#Contraction path
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = tf.keras.layers.Dropout(Config['contraction_1_dropout'])(c1)
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = tf.keras.layers.MaxPooling2D((2, 2))(c1)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = tf.keras.layers.Dropout(Config['contraction_2_dropout'])(c2)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = tf.keras.layers.MaxPooling2D((2, 2))(c2)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = tf.keras.layers.Dropout(Config['contraction_3_dropout'])(c3)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = tf.keras.layers.MaxPooling2D((2, 2))(c3)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = tf.keras.layers.Dropout(Config['contraction_4_dropout'])(c4)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(c4)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = tf.keras.layers.Dropout(Config['contraction_5_dropout'])(c5)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)
#Expansive path
u6 = tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = tf.keras.layers.Dropout(Config['expansive_1_dropout'])(c6)
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6)
u7 = tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = tf.keras.layers.Dropout(Config['expansive_2_dropout'])(c7)
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7)
u8 = tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = tf.keras.layers.Dropout(Config['expansive_3_dropout'])(c8)
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8)
u9 = tf.keras.layers.Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1], axis=3)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = tf.keras.layers.Dropout(Config['expansive_4_dropout'])(c9)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)
outputs = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(c9)
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
return model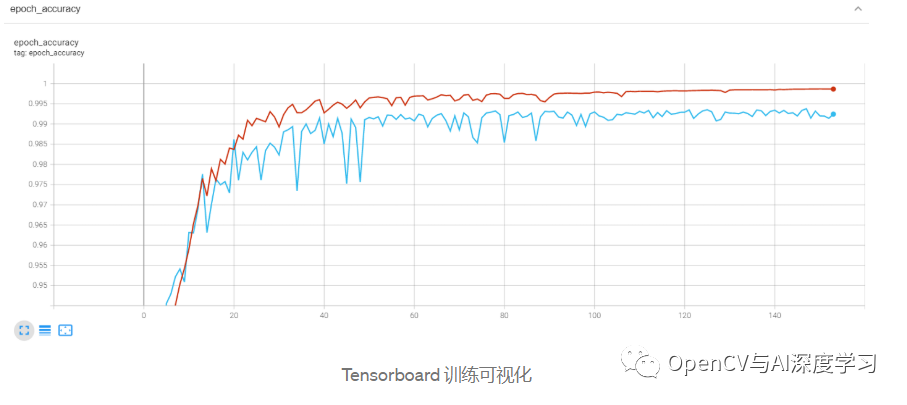

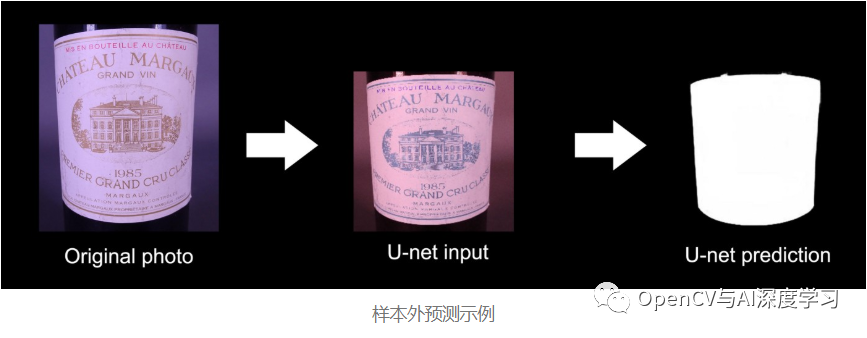
个别因干扰而分割失败的情况(暂时忽略):
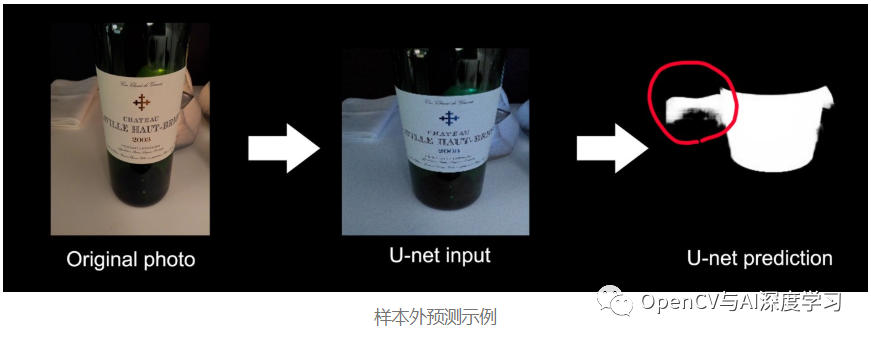
第三部分:曲面标签展平与文字识别
【1】根据分割结果提取6个特征点

调整图像大小、二值化、对齐U-Net预测:
# mask is the U-net output image
# src is the source image
# self is the parent class labelVision
mask = cv2.cvtColor(mask,cv2.COLOR_GRAY2RGB)
mask=cv2.resize(mask,(src.shape[1],src.shape[0]))
mask = np.round(mask) #binary transform
r_src, r_mask = self.align_vertically(src, mask)
如下方法先找到对角线的 A、C、D 和 F 坐标点,并通过计算简单距离计算找到 B 坐标:

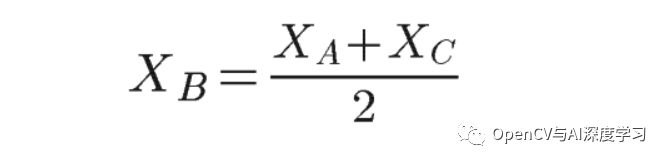
其中 XB 是 B 点的 X 坐标。我们现在可以选择与该 XB 位置对应的图像的列向量 (lambda):
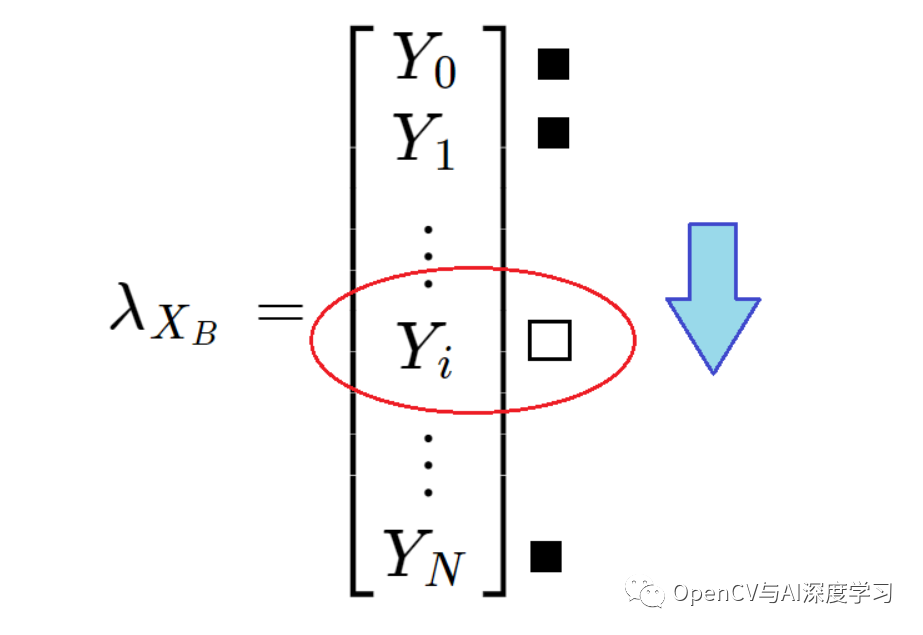
我们在向量中从上到下迭代以找到第一个白色像素以减去 B 点的 Y 坐标。
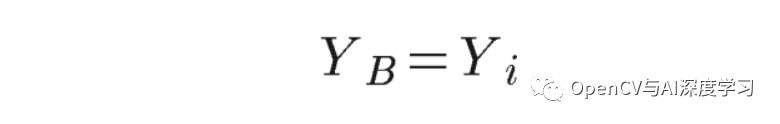
E 点的逻辑是相同的:我们在 D 和 F 点的中间找到列向量,这次我们从下到上迭代,直到找到第一个白色像素。
要获取实现的详细代码,请查看文末代码中的getCylinderPoints方法。
【2】根据6个特征点做曲面展平
网格圆柱投影:

标签展平:

【3】OCR文字识别
原始图像 OCR结果:

展平图像 OCR结果:

虽然展平图像 OCR结果不一定完美,但相比原始图像OCR结果要好很多。
源码下载:
https://github.com/AntoninLeroy/wine_label_reader_toolkit
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









