






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达都听说过较小的LLM(大型语言模型)和较小的文本分类器是如何在ChatGPT的回应上进行训练的。但现在,我们正进入一个新时代,图像可以被LLM精确解释。直到现在,ChatGPT的视觉能力只是一个有趣的派对把戏,但该模型的最新改进使其多模型可以胜过许多专为视觉任务构建的模型。虽然这是一个巨大的改进,但视觉问题尚未完全解决。ChatGPT存在根本性的局限,我们需要使用ChatGPT来克服这些问题。
图像只是一堆排列成方形的数字。你可以将其看作是一个矩阵。到目前为止,我们只能训练模型来解决狭隘的问题,比如分类、定位等。一些模型能够“描述”图像,但由于其准确性和无法辨别图像更复杂方面的能力,它们很快就失败了。这就是ChatGPT派上用场的地方。由于其改进的准确性,我们现在可以要求它以我们需要的方式“标注”图像。
这如何帮助图像标注?
假设我们需要训练一个小型模型,用于那些没有足够的注释的任务。现在,我们可以使用脚本从互联网上收集随机相关的图像,并使用ChatGPT的API来对其进行标注。然后,我们可以要求人工进行审核,这只需要很小一部分的时间,而不是实际标注所需的时间。
为什么训练一个新模型,而不直接使用ChatGPT的API?
在许多情况下,直接在您的产品中使用ChatGPT的API可能是有益的,但有3个主要原因可能不是理想的解决方案。
成本
对于一张224x224x3的图像,获取一个响应的成本约为0.12美元。大多数低成本的注释服务,如由serna.ai运营的服务,提供更低的价格与人工注释员合作。那么为什么要使用这种绕圈子的方法呢?我们可以使用ChatGPT比人更快地对图像进行标注。然后,我们只需要求一个注释员对这些标注进行审查和完善。还可能存在ChatGPT比人更可靠的情况,例如下面的示例1。如果仅仅进行标注就很昂贵,你可以想象为什么在实时运行中这将成为一个禁忌。
延迟
GPT-4通过一个推理API运行,其响应时间可以根据输入和输出的长度而变化,可能需要几秒钟。因此,GPT-4可能不适用于需要即时、边缘级响应时间的计算机视觉任务,比如在智能手机中的应用。
托管GPT-4的局限性
由于GPT-4是通过一个API提供的,企业必须能够访问外部API。GPT-4不适用于需要离线处理的计算机视觉任务。
这个模型的理想用例
虽然这个模型在常见图像中表现得非常好,但在实际使用之前,我们必须在其聊天界面中对其进行广泛测试。在准确性至关重要的场景中,最好使用人工注释员来完成这项工作,或者使用API进行标注,然后请人工对这些标注进行审核。
让我们看一些快速的示例
示例1:
对一个用于在手机上运行的筛选模型进行标注,以检查脸部的光照条件是否足够好,这是基于我们可以提到的自定义因素,然后再将其提供给另一个模型或人工进行进一步分析。

ChatGPT评估特定用例的照明条件
示例2:
您正试图训练一个基于闭路电视的模型,根据地板的清洁程度自动呼叫清洁工或机器人。您无法依赖LLM来完成这项任务,因为计算成本和响应时间将使其在多个摄像头上全天候运行时成本高昂。
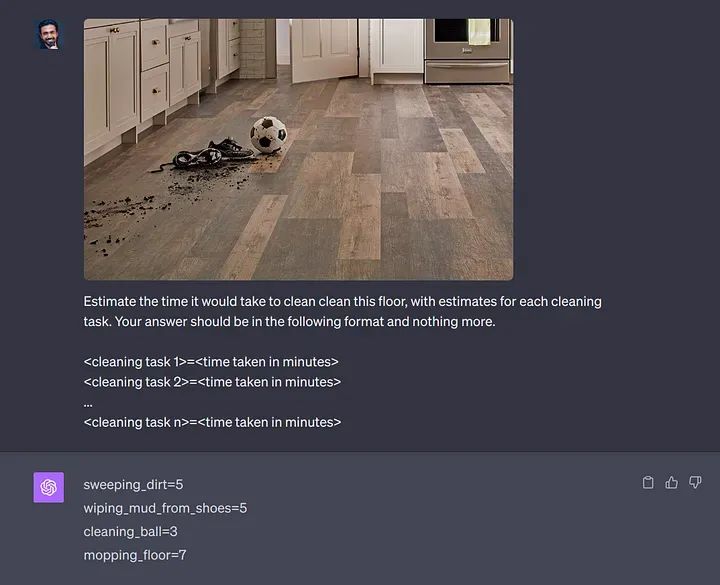
ChatGPT估计清洁地板所需的时间
示例3:
您正试图训练一个模型,快速分析一个人走进建筑物。
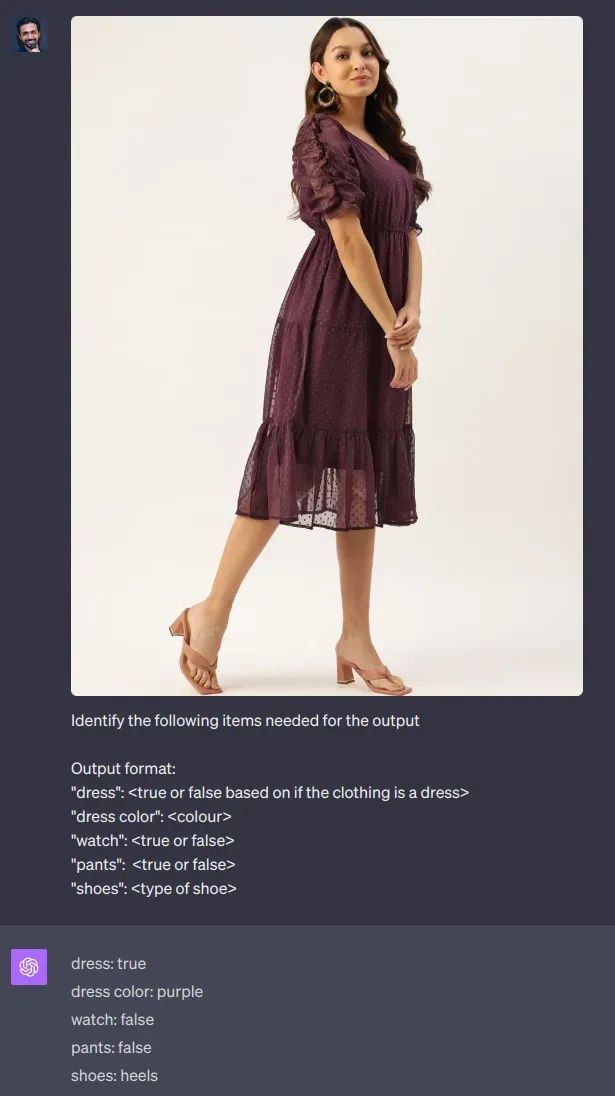
ChatGPT识别图片中的女士的各种属性,如她的服装颜色、手表等。
尽管这些令人印象深刻,但该模型尚不是完美的,如下所示:
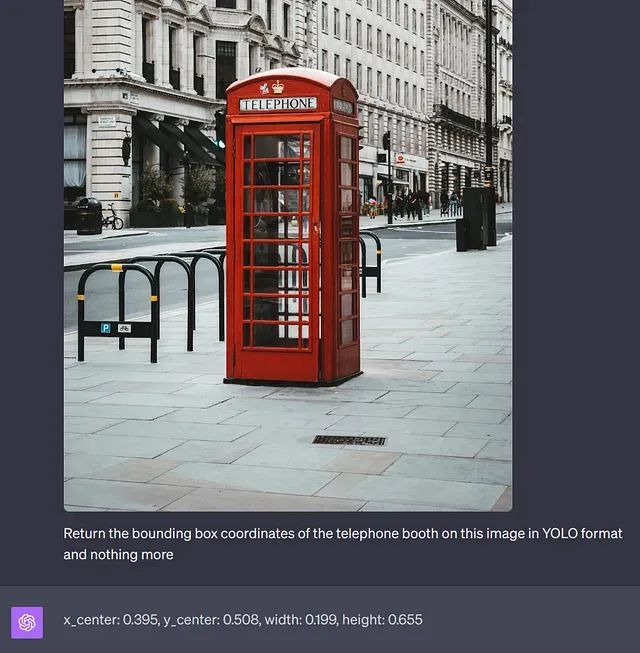

ChatGPT错误地返回电话杆的边界框坐标
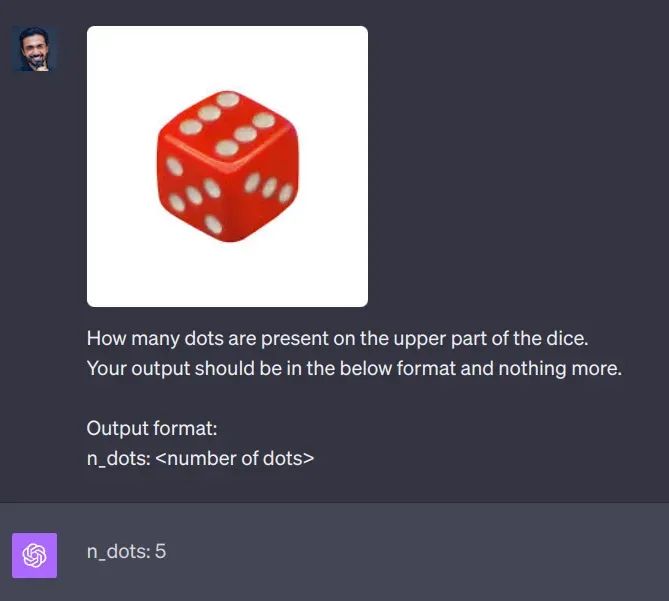
ChatGPT错误地计算骰子上的点数
如何在我的应用程序中使用这种方法
上传一些图像到ChatGPT,尝试一些不同的提示,看看它是否达到您的期望。
如果其准确性至少达到90-95%,则使用ChatGPT的API,并正确提示它以获得简单的输出,就像上面的示例一样
编写一个脚本将这些输出转换为有用的注释格式
将这些注释上传到像cvat.ai这样的注释平台,或者上传到像roboflow这样的付费注释平台,并请人工注释员修复任何错误
结论
尽管这看起来很不错,但这并不是解决所有问题的灵丹妙药。在适合的地方使用它,并考虑其他可用的自动化方法。
如果您需要帮助解决与计算机视觉相关的任何问题,包括注释,请给我发送电子邮件至rishi@serna.ai。我们为您的所有计算机视觉需求提供端到端的解决方案,包括开发、部署和低成本高效率的注释。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









