






题目:Few-Shot Stereo Matching with High Domain Adaptability Based on Adaptive Recursive Network
基于自适应递归网络的少样本立体匹配算法及其高领域适应性
作者:Rongcheng Wu, Mingzhe Wang, Zhidong Li, Jianlong Zhou, Fang Chen, Xuan Wang & Changming Sun
摘要
基于深度学习的立体匹配算法因其在机器人视觉和自动驾驶等领域的优异表现而得到了广泛的研究。然而,这些算法需要大量的标记数据进行训练,并面临领域适应性不足的问题,这限制了它们的应用性和灵活性。本文针对这两个缺陷,提出了一个少样本训练的立体匹配模型,具有高领域适应性。在模型中,立体匹配被构建为在可能的解空间中的动态优化问题,并提出了一种多尺度匹配成本计算方法,以获得应用场景的可能解空间。此外,设计了一个自适应递归的3D卷积神经网络,以从可能的解空间中确定最优解。实验结果表明,所提出的模型在训练需求和领域适应性方面优于现有的立体匹配算法。
关键词
立体匹配、自适应递归网络、多尺度匹配成本计算、少样本学习、领域适应性
引言
立体匹配作为计算机视觉中的一个重要和核心问题,已广泛应用于机器人视觉、增强现实、目标检测、3D重建、遥感和自动驾驶等领域。其主要任务是基于由两个相机(或一个相机与运动)捕获的两张图像(即左图和右图)来确定三维几何或深度。与使用三个或更多相机进行深度估计相比,使用两个相机的立体匹配由于其更接近人类双眼视觉系统而受到了更大的关注。
在数学上,作为一个病态问题,立体匹配可以被构建为一个三阶段的优化任务。在第一阶段,通过计算左图中的像素与其在右图中可能对应的像素之间的相似性来获得匹配成本。第二阶段的目标是通过匹配成本聚合和视差优化来确定两幅图像中的对应像素,这是核心步骤,并且在很大程度上决定了立体匹配的性能。最后一步是视差细化,通过计算沿水平坐标的对应像素之间的差异来获得视差图,并使用亚像素插值或一些噪声和错误移除过程对其进行细化。
在立体匹配的传统方法中,视差优化通过对具有最低匹配成本的相应像素对进行简单选择,或者通过逐步最小化定义的全局函数来实现,例如通过图割或置信传播。为了平衡计算复杂性与检测精度,还提出了半全局匹配(SGM),在这种方法中,视差优化是通过在多个方向上动态优化能量函数的搜索路径来进行的。这些方法可以在某些类型的应用场景中取得良好的结果,但是,在某些图像区域,如遮挡区域、无特征区域或具有重复模式的高度纹理化区域,它们的性能会显著下降,这无法满足3D成像应用的要求。
最近,深度学习已被扩展到立体匹配中。相关的技术,如卷积神经网络(CNN),被用来替代传统立体匹配流程中的一个或多个组件,例如匹配成本计算、成本聚合或视差细化组件。同时,还提出了一些端到端的网络来执行立体匹配的整个过程。一般来说,基于深度学习的方法在深度估计精度和适应上述困难图像区域方面优于传统算法。然而,这些方法,特别是端到端网络,需要大量的标记数据进行训练,这意味着高存储需求和大量的数据标记工作。更重要的是,这些网络在与训练数据不同的应用场景中表现不佳,并且需要使用目标应用场景中的一组标记数据进行重新训练,才能达到可接受的性能。因此,除了深度估计精度外,训练需求以及领域适应和泛化能力是限制基于深度学习的立体匹配的应用和发展的主要因素。
最近的工作专注于提高立体匹配的领域适应能力,并尝试通过领域转换、泛化或在特定级别对齐它们的特征来解决合成和真实领域之间的领域差距。在实际应用中,存在各种类型的应用场景。仅仅考虑通常训练的合成样本和少量真实样本之间的差异是远远不够的。因此,如何实现一个高效且广泛适用的立体匹配模型是一个更具挑战性和理想的任务,因为目标应用场景的图像通常不在训练数据中。
在这项工作中,我们旨在解决这一挑战性问题以及巨大的训练需求限制,并提出了一个具有高领域适应性的少样本训练立体匹配模型。在该模型中,立体匹配被构建为在可能的解空间上的动态优化问题,这包括两个阶段。在第一阶段,提出了一种多尺度匹配成本计算方法,以获得当前应用场景的可能解空间,以及用于后续优化网络的约束信息,以提高其对具有不同局部特征的图像块的适应性。在第二阶段,提出了一个自适应递归的3D卷积神经网络,以从可能的解空间中确定最优解。实验结果表明,所提出的方法通过20次拍摄学习就能达到与最先进方法相当的结果。同时,所提出的模型在适应不同场景的领域适应性方面也优于代表性方法。
本工作的主要贡献总结如下:(1) 将立体匹配构建为在可能的解空间上的动态优化问题,所提出的递归3D卷积神经网络可以进行少样本训练。因此,可以大大减轻当前立体匹配工作中巨大的训练需求限制。(2) 所提出的多尺度匹配成本计算方法可以为当前应用场景提供一个相对全面的可能解空间,所提出的递归3D卷积神经网络只关注解空间的优化,而不是当前领域的语义信息和上下文。(3) 因此,所提出的模型在训练需求和领域适应性方面对当前立体匹配的最新技术进行了改进。
本文的组织如下:第2节简要回顾了相关主题和工作。第3节提出了递归3D卷积神经网络以及多尺度匹配成本计算方法,并进行了分析。第4节给出了实验结果和讨论,第5节是结论和未来的工作。
3 少样本训练的领域自适应立体匹配模型
所提出的立体匹配模型,如图 1 所示,由两个主要组成部分构成:(1) 多尺度匹配成本计算,以及 (2) 自适应递归三维卷积神经网络(3D CNN)。多尺度匹配成本计算组件的主要任务是确定由匹配成本信息 M c M_ c Mc 和索引信息 M i M_ i Mi 以及自适应递归3D CNN所需的递归约束信息 M R M_ R MR 形成的可能解空间。然后,自适应递归3D CNN 递归地细化和压缩解空间,直到满足相应的递归约束 M R M_ R MR。最后,可以从矩阵 M i M_ i Mi 中剩余的数据形成视差图。
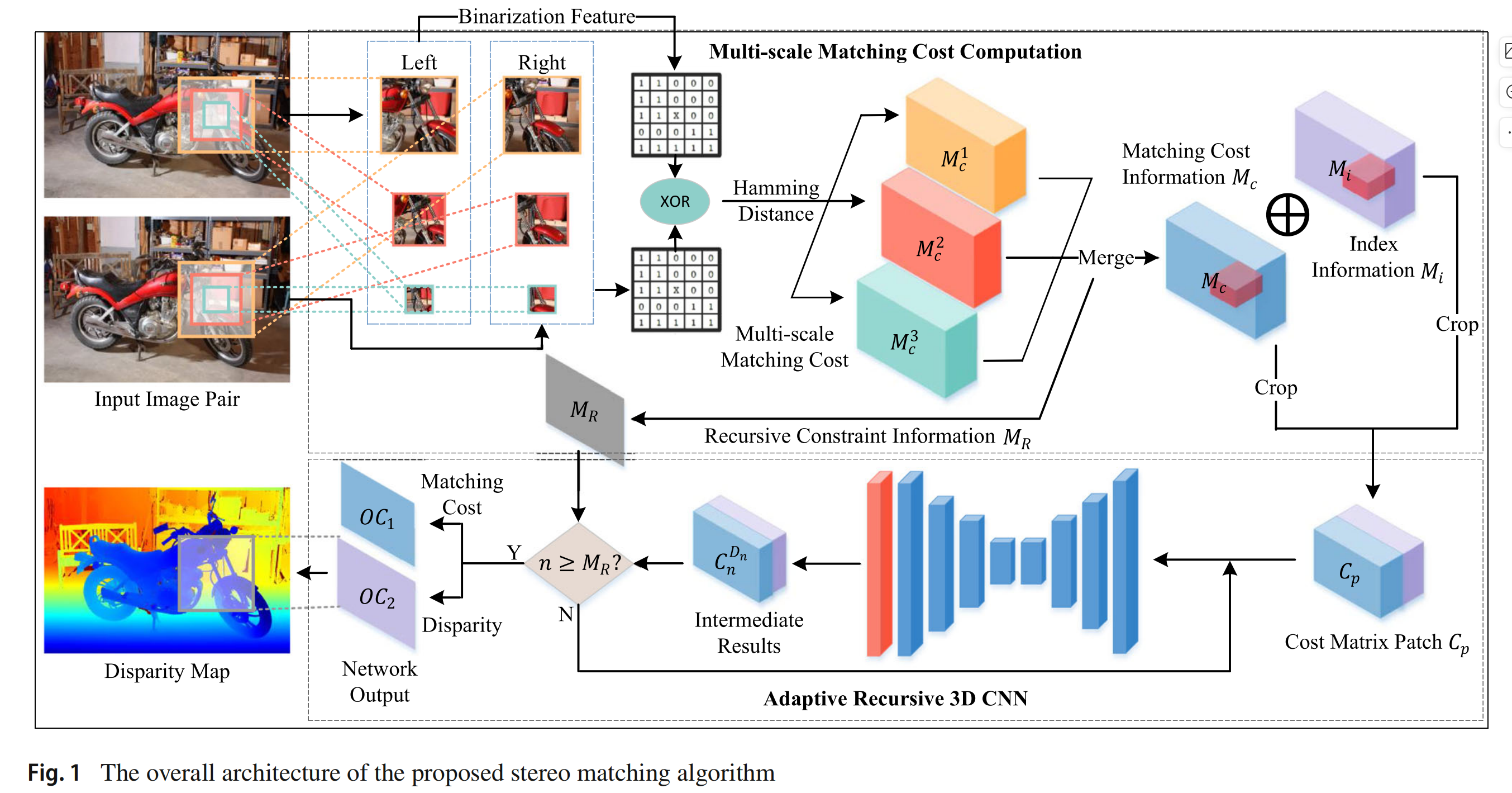
3 少样本训练的领域自适应立体匹配模型
所提出的立体匹配模型,如图 1 所示,由两个主要组成部分构成:(1) 多尺度匹配成本计算,以及 (2) 自适应递归三维卷积神经网络(3D CNN)。多尺度匹配成本计算组件的主要任务是确定由匹配成本信息 M c M_ c Mc 和索引信息 M i M_ i Mi 以及自适应递归3D CNN所需的递归约束信息 M R M_ R MR 形成的可能解空间。然后,自适应递归3D CNN 递归地细化和压缩解空间,直到满足相应的递归约束 M R M_ R MR。最后,可以从矩阵 M i M_ i Mi 中剩余的数据形成视差图。
3.1 多尺度匹配成本计算
对于任何图像像素 I ( x , y ) I(x, y) I(x,y),其在尺度 j j j 下的二值化特征可以通过以下公式计算:
B j ( x , y ) = ⨁ I ( n ) ∈ P ξ ( I ( x , y ) , I ( n ) ) B_ j(x, y) = \bigoplus_ {I(n) \in P} \xi(I(x, y), I(n)) Bj(x,y)=I(n)∈P⨁ξ(I(x,y),I(n))
其中 P j P_ j Pj 表示与尺度 j j j 对应的图像块, I ( n ) I(n) I(n) 是 P j P_ j Pj 内的像素。 ⨁ \bigoplus ⨁ 表示按位连接操作, ξ ( . ) \xi(.) ξ(.) 是人口普查辅助函数,定义为 (Zabih & Woodfill, 1994):
ξ ( I ( x , y ) , I ( n ) ) = { 0 , 如果 I ( x , y ) > I ( n ) 1 , 其他情况 \xi(I(x, y), I(n)) = \begin{cases} 0, & \text{如果 } I(x, y) > I(n) \\ 1, & \text{其他情况} \end{cases} ξ(I(x,y),I(n))={0,1,如果 I(x,y)>I(n)其他情况
给定由两个相机捕获并校正的立体图像 I l I_ l Il 和 I r I_ r Ir,任何左图像素 I l ( x , y ) I_ l(x, y) Il(x,y) 与其在右图中具有视差 k k k 的可能对应像素 I r ( x ′ , y ′ ) I_ r(x', y') Ir(x′,y′) 在尺度 j j j 下的相似性可以通过它们二值化特征的汉明距离来度量,可以表示为:
C j ( x , y , k ) = ⨁ I ( x , y ) ∈ P ( B j l ( x , y ) ⊕ B j r ( x ′ , y ′ ) ) C_ j(x, y, k) = \bigoplus_ {I(x,y) \in P} (B^l_ j(x, y) \oplus B^r_ j(x', y')) Cj(x,y,k)=I(x,y)∈P⨁(Bjl(x,y)⊕Bjr(x′,y′))
其中 ⊕ \oplus ⊕ 表示异或运算, y ′ y' y′ 对于校正图像等于 y y y。因此,对于两个立体图像,尺度 j j j 下的匹配成本可以通过以下公式获得:
M j c ( x , y , k ) = 1 − C j ( x , y , k ) max k C j ( x , y , k ) M^c_ j(x, y, k) = 1 - \frac{C_ j(x, y, k)}{\max_ k C_ j(x, y, k)} Mjc(x,y,k)=1−maxkCj(x,y,k)Cj(x,y,k)
一般来说,对于小的感受野,使用上述公式计算出的二值化特征具有较高的区分能力,但对噪声和异常值敏感。相反,随着感受野的增加,二值化特征的区分能力降低,但鲁棒性增加。因此,在本文中,为了平衡区分能力和鲁棒性,考虑了三个尺度,分别为 5 × 5 5 \times 5 5×5, 3 × 3 3 \times 3 3×3,和 2 × 2 2 \times 2 2×2,并可以通过以下公式获得两个立体图像的匹配成本 M c M_ c Mc:
M c ( x , y , k ) = ∑ j = 1 3 M j c ( x , y , k ) M_ c(x, y, k) = \sum_ {j=1}^{3} M^c_ j(x, y, k) Mc(x,y,k)=j=1∑3Mjc(x,y,k)
以及相应的归一化索引 M i M_ i Mi 也可以通过以下公式生成:
M i ( x , y , k ) = k K M_ i(x, y, k) = \frac{k}{K} Mi(x,y,k)=Kk
其中 K K K 表示 k k k 的最大值。匹配成本 M c M_ c Mc 和归一化索引 M i M_ i Mi 形成了两个立体图像的可能解空间,并将由自适应递归3D CNN 递归细化。为了为自适应递归3D CNN 提供所需的相关信息,并提高其对不同尺寸图像的适应性,匹配成本 M c M_ c Mc 和归一化索引 M i M_ i Mi 被同步划分为 128 × 128 128 \times 128 128×128 的非重叠块,在 x-y 平面上形成可能的解子空间 C p C_ p Cp 作为自适应递归3D CNN的输入。
一般来说,对于不同的图像块,立体匹配的难度不同,错误更可能发生在视差较大的区域。因此,对于不同的子空间 C p C_ p Cp,所提出的递归3D CNN的递归深度是自适应的,并根据相应图像块的特征进行调整。也就是说,对于具有较大视差补丁的区域,所提出的网络应该有更大的递归深度,以充分利用匹配成本信息进行视差估计。
对于每个 C p C_ p Cp,需要估计近似的视差范围,以调整具有适当递归深度的网络。在尺度 j j j 估计的视差可以通过以下公式获得:
D j ( u , v ) = arg max k M j c ( x , y , k ) D_ j(u, v) = \arg\max_ k M^c_ j(x, y, k) Dj(u,v)=argkmaxMjc(x,y,k)
其中 ( x , y ) (x, y) (x,y) 表示 C p ( u , v ) C_ p(u, v) Cp(u,v) 在 x-y 平面上的原始坐标, M j c ( x , y , k ) M^c_ j(x, y, k) Mjc(x,y,k) 如公式 (4) 所定义。位置 ( u , v ) (u, v) (u,v) 处的视差可以通过以下公式估计:
D ( u , v ) = { ∑ j = 1 3 D j ( u , v ) / 3 , 如果 ϵ ( u , v ) < 3 0 , 其他情况 D(u, v) = \begin{cases} \sum_ {j=1}^{3} D_ j(u, v) / 3, & \text{如果 } \epsilon(u, v) < 3 \\ 0, & \text{其他情况} \end{cases} D(u,v)={∑j=13Dj(u,v)/3,0,如果 ϵ(u,v)<3其他情况
其中 ϵ ( u , v ) \epsilon(u, v) ϵ(u,v) 定义为:
ϵ ( u , v ) = ∑ j 1 = 1 2 ∑ j 2 = j 1 + 1 3 ∣ D j 1 ( u , v ) − D j 2 ( u , v ) ∣ / 3 \epsilon(u, v) = \sum_ {j_ 1=1}^{2} \sum_ {j_ 2=j_ 1+1}^{3} |D_ {j_ 1}(u, v) - D_ {j_ 2}(u, v)| / 3 ϵ(u,v)=j1=1∑2j2=j1+1∑3∣Dj1(u,v)−Dj2(u,v)∣/3
通过这种方式,如果三个尺度上的估计足够接近,则可以获得准确的视差。因此,对于 C p C_ p Cp 估计的视差范围为 [ 0 , D C p = max ( D ( u , v ) ) ] [0, D_ {C_ p} = \max(D(u, v))] [0,DCp=max(D(u,v))]。在每次递归中,自适应递归3D CNN(细节将在后面提供)将通过选择适当的匹配成本 M c M_ c Mc 和归一化索引 M i M_ i Mi 沿 z 轴(即 k)将子空间 C p C_ p Cp 细化和压缩一半,对于子空间 C p C_ p Cp,自适应递归3D CNN 的递归深度由以下公式获得:
M R = ⌈ log 2 ( D C p ) ⌉ M_ R = \lceil \log_ 2(D_ {C_ p}) \rceil MR=⌈log2(DCp)⌉
其中 ⌈ ⋅ ⌉ \lceil \cdot \rceil ⌈⋅⌉ 是向上取整操作。
3.2 自适应递归三维卷积神经网络
数学上,给定两个立体图像 I l I_ l Il 和 I r I_ r Ir,对于左图中的任何像素 I l I_ l Il,不难确定所有可能属于相同视差对的右图中的潜在像素。换句话说,第 3.1 节中构建的可能解空间是完整的,并且不可避免地包含正确解。因此,下一个任务是如何从可能的解空间中确定正确解,这通常是一个病态问题,可以通过基于适当全局目标函数的优化程序来解决。为了以高稳定性、准确性和适应性实现此优化任务,设计了一个自适应递归三维卷积神经网络。
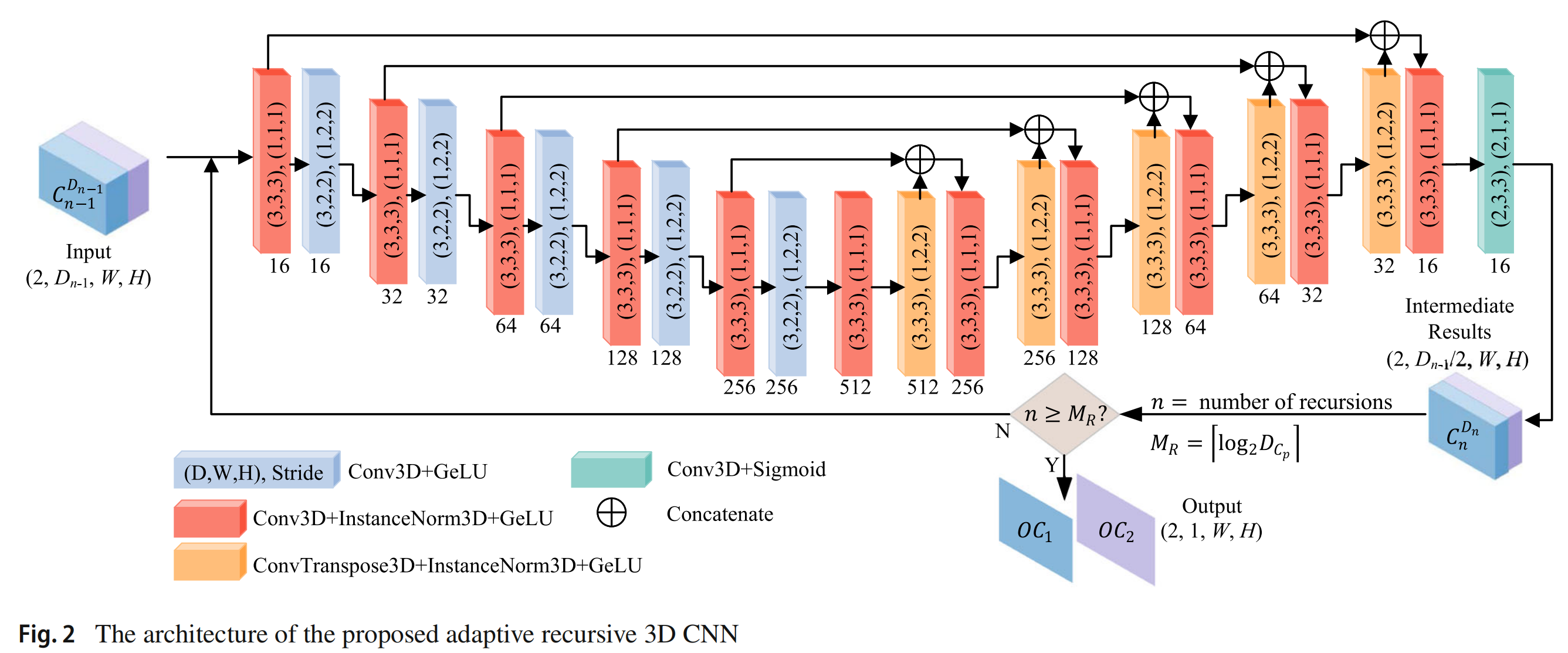
所提出的自适应递归三维卷积神经网络的结构如图 2 所示,网络的主要部分采用 U-Net 结构。值得注意的是,所提出的网络与同名的递归神经网络(RNN)非常不同,后者的输入是依赖时间的序列,并且一步的输入将与前一步的输入共同影响结果。有趣的是,利用先验知识,人类擅长解决这类病态问题,并且通常采取从易到难的路线,即首先排除低概率解,然后从剩余的高概率解中确定最优结果。当然,这个过程的复杂性随着问题的难度而变化。所提出的自适应递归三维卷积神经网络试图模拟人类解决这类问题的可能过程。设 F F F 为所提出的网络学习的函数。然后,所提出的自适应递归三维卷积神经网络的过程可以表示为:
C n D = F ( C n − 1 D ) ∀ n ∈ { 1 , . . . , M R } C^D_ n = F(C^{D}_ {n-1}) \quad \forall n \in \{1, ..., M_ R\} CnD=F(Cn−1D)∀n∈{1,...,MR}
其中 C n D C^D_ n CnD 是第 n n n 次递归的输出结果, C n − 1 D C^{D}_ {n-1} Cn−1D 表示第 n n n 次递归的输入,即第 n − 1 n-1 n−1 次递归的输出结果, n = 1 , 2 , . . . , M R n = 1, 2, ..., M_ R n=1,2,...,MR,且 C 0 D = C p C^D_ 0 = C_ p C0D=Cp。注意 C n D C^D_ n CnD 是一个双通道的三维矩阵,大小为 2 × D n × 128 × 128 2 \times D_ n \times 128 \times 128 2×Dn×128×128,上标 D n D_ n Dn 表示 C n D C^D_ n CnD 的深度大小。
从图 2 可以看出,对于每次递归,输入的深度大小 ( D i n , W , H ) (D_ {in}, W, H) (Din,W,H) 在输出中将变为一半 ( D o u t = D i n / 2 , W , H ) (D_ {out} = D_ {in}/2, W, H) (Dout=Din/2,W,H)。也就是说,在每次递归中,将从解空间中排除一半的低概率解。当递归次数达到 M R M_ R MR 时,输出大小将为 ( 1 , W , H ) (1, W, H) (1,W,H),并且可以从剩余的高概率解中获得最优结果。
显然, C p C_ p Cp 的两个输入通道是匹配成本矩阵和视差索引矩阵,包括正确的匹配成本和视差值。因此,获得正确的深度可以转化为一个边界问题,即从可行解空间 C 0 D C^D_ 0 C0D 开始,然后从 C 0 D C^D_ 0 C0D 中选择解 O C 1 O_ {C1} OC1 和 O C 2 O_ {C2} OC2 以最小化目标函数,该函数定义为:
Loss = ∑ x , y ( O C 1 ( x , y ) − C G T ( x , y ) ) 2 + ∑ x , y ∣ O C 2 ( x , y ) − D G T ( x , y ) ∣ + ∑ x , y ∣ O C 2 ′ ( x , y ) − D G T ′ ( x , y ) ∣ \text{Loss} = \sum_ {x,y} (O_ {C1}(x, y) - C_ {GT}(x, y))^2 + \sum_ {x,y} |O_ {C2}(x, y) - D_ {GT}(x, y)| + \sum_ {x,y} |O'_ {C2}(x, y) - D'_ {GT}(x, y)| Loss=x,y∑(OC1(x,y)−CGT(x,y))2+x,y∑∣OC2(x,y)−DGT(x,y)∣+x,y∑∣OC2′(x,y)−DGT′(x,y)∣
其中 C G T ( x , y ) C_ {GT}(x, y) CGT(x,y) 和 D G T ( x , y ) D_ {GT}(x, y) DGT(x,y) 分别代表匹配成本和地面真实深度索引,而
O C 2 ′ ( x , y ) = ∂ O C 2 ( x , y ) ∂ x + ∂ O C 2 ( x , y ) ∂ y O'_ {C2}(x, y) = \frac{\partial O_ {C2}(x, y)}{\partial x} + \frac{\partial O_ {C2}(x, y)}{\partial y} OC2′(x,y)=∂x∂OC2(x,y)+∂y∂OC2(x,y)
D G T ′ ( x , y ) = ∂ D G T ( x , y ) ∂ x + ∂ D G T ( x , y ) ∂ y D'_ {GT}(x, y) = \frac{\partial D_ {GT}(x, y)}{\partial x} + \frac{\partial D_ {GT}(x, y)}{\partial y} DGT′(x,y)=∂x∂DGT(x,y)+∂y∂DGT(x,y)
目标函数 Loss 的目的是使网络获得的匹配成本和深度尽可能正确。同时,一阶导数的引入使得获得的深度图变化准确,并在物体边界处实现精确过渡。
在基于数学的方法中,使用动态规划的优化过程是沿扫描线内部或扫描线之间手动设置的(Hallek et al., 2022)。然而,在此过程中使用的信息受到扫描线的局限,因此无法充分利用解空间中的信息来优化视差。因此,在本文中,我们设计了网络以结合解空间中包含的上下文信息来学习更好的优化过程。

图 3 显示了网络在训练期间的等效结构。如图 3 所示,如果展开递归部分,训练过程相当于图 2 中多个网络块的端到端连接。假设当前网络输入包含 D 0 = 512 D_ 0=512 D0=512( C 512 0 C_ {512}^0 C5120),那么总共需要 9 个网络块。例如, C 128 2 C_ {128}^2 C1282 的输入对应于 C 256 1 C_ {256}^1 C2561 经过一个网络块处理后的输出,或者 C 512 0 C_ {512}^0 C5120 经过两个网络块处理后的输出。因此,网络不会对具有已知和固定视差范围的数据过拟合,并且能够动态适应不同的视差范围。同时,由于网络块之间的权重共享,Loss 函数将迫使网络学习不同阶段不同视差范围输入的共同解,即从 C D n − 1 n − 1 C_ {D_ {n-1}}^{n-1} CDn−1n−1 到 C D n − 1 / 2 n C_ {D_ {n-1}/2}^n CDn−1/2n 最优地压缩输入解空间边界,而不是直接从 C 512 0 C_ {512}^0 C5120 获得结果。因此,通过所提出的网络学习的函数 F F F 在公式 (11) 中可以重写为:
C D n − 1 / 2 n = F ( C D n − 1 n − 1 ) C_ {D_ {n-1}/2}^n = F(C_ {D_ {n-1}}^{n-1}) CDn−1/2n=F(CDn−1n−1)
其中
∀ ( u , v ) , C D n n ( 2 , : , u , v ) ⊂ C D n − 1 n − 1 ( 2 , : , u , v ) \forall (u, v), \quad C_ {D_ n}^n(2, :, u, v) \subset C_ {D_ {n-1}}^{n-1}(2, :, u, v) ∀(u,v),CDnn(2,:,u,v)⊂CDn−1n−1(2,:,u,v)
D
n
=
1
2
D
n
−
1
D_ n = \frac{1}{2} D_ {n-1}
Dn=21Dn−1
这里
{
⋅
}
\{ \cdot \}
{⋅} 表示由特定矩阵元素组成的集合,而
:
:
: 表示沿相应轴的所有坐标。在目标函数 Loss 的约束下,最优解
C
1
M
R
C_ 1^{M_ R}
C1MR 可以通过使用递归结构从
C
0
0
C_ 0^0
C00 获得,可以表示为:
C 1 M R = F ( F ( … F ( C p ) … ) ) C_ 1^{M_ R} = F(F(\ldots F(C_ p) \ldots)) C1MR=F(F(…F(Cp)…))
匹配成本 O C 1 O_ {C1} OC1 和视差图 O C 2 O_ {C2} OC2 是 C 1 M R C_ 1^{M_ R} C1MR 的两个通道。
因此,所提出的网络学习了优化视差的动态规划过程,以及压缩解空间以获得最优解的子结构。动态优化的目标函数定义在公式 (12) 和 (13) 中,状态转移方程的函数 F ( ⋅ ) F(\cdot) F(⋅) 在公式 (11) 中,由所提出的三维卷积神经网络学习并执行,约束条件定义在公式 (14) 和 (15) 中。所提出方法的核心思想是,优化过程中的关键过程,即状态转移方程由所提出的三维卷积神经网络学习并执行,递归结构的引入可以简化网络学习和解决的问题。因此,所提出方法的主要优势是,所提出的三维卷积神经网络专注于学习适当的优化过程,而不是从训练样本中学习图像特征,有效地减少了该模型对训练图像领域和语义偏差的依赖。此外,通过递归结构显著简化了所提出的三维卷积神经网络需要学习的问题,因此可以预期具有少样本学习能力,其局限性是递归结构增加了计算成本。众所周知,对于像立体匹配这样的病态问题,很难直接找到最优解。因此,逐步逼近最优解并获得问题的子结构,例如通过动态规划或信念传播,将显著降低算法的难度。同样,所提出的网络采用了这一思想,可以显著降低训练的难度。同时,由于所提出的网络的输入是匹配成本矩阵,并且网络学习从匹配成本中找到最优解,因此找到最优解的难度也显著低于直接从RGB图像生成估计的深度图,这进一步降低了训练的难度。众所周知,与具有大量训练数据的一般图像分析问题(如目标检测和分类)不同,在现有的立体匹配训练数据集中,无论是训练数据的数量还是覆盖的真实场景都不足以导致特别是对于端到端深度学习网络来说,领域适应或泛化性能差。我们三维卷积神经网络架构的基本思想是将复杂的立体匹配问题转化为重复的递归结构,所提出的自适应递归三维卷积神经网络只学习如何最优地将输入解空间压缩一半,而不是直接获得视差图。由于所学习问题的极端简化,可以预期具有少样本训练能力。
如上所述,所提出的递归三维卷积神经网络主要关注解空间的优化,而不是当前领域的语义信息和上下文。结合少样本训练,可以大大克服训练样本中语义信息过拟合的问题。因此,可以预期该网络具有高领域泛化能力和适应目标应用场景的能力。
4 性能评估和实验分析
在本节中,所提出方法的性能在基准数据集上进行了评估。重点关注了视差估计的准确性、训练需求和领域适应性。与包括 PSMNet (Chang & Chen, 2018)、AANet (Xu & Zhang, 2020)、GA-Net (Zhang et al., 2019)、CFNet (Shen et al., 2021) 和 GWCNet (Guo et al., 2019) 等代表性立体匹配方法,以及一些最先进的领域适应或泛化方法如 DSMNet (Zhang et al., 2020)、StereoGAN (Liu et al., 2020)、AdaStereo (Song et al., 2021)、GraftNet (Liu et al., 2022)、FC-DSMNet (Zhang et al., 2022)、ZOLE (Pang et al., 2018)、MSNet (Cai et al., 2020)、ITSA (Chuah et al., 2022) 和 HVT (Chang et al., 2023) 进行了比较。
考虑了六个包含不同场景的基准数据集,如室内物体、户外驾驶场景、遥感场景和合成数据。详细信息如下:
Middlebury Stereo 2014 数据集 (Scharstein et al., 2014) 是一个高分辨率和高精度的静态室内场景立体数据集,包含 23 对具有地面真实值的图像。
KITTI Stereo 数据集 (Geiger et al., 2012; Menze & Geiger, 2015) 是一个广泛使用的立体数据集,由户外驾驶场景的图像对组成,包含 KITTI 2012 和 KITTI 2015 子集,分别有 194 对和 200 对带有地面真实值的图像。
WHU Stereo 2020 数据集 (Liu & Ji, 2020) 是一个由高分辨率无人机影像形成的大规模多视图立体数据集,包含 8,316 对用于训练的图像对和 2,663 对用于测试的图像对。
WHU Stereo 2023 数据集 (Li et al., 2023) 是一个由高分辨率卫星影像形成的大规模数据集,包含 1,220 对用于训练的图像对、122 对用于验证的图像对和 415 对用于测试的图像对。
SceneFlow 数据集 (Mayer et al., 2016) 是一个由 39,049 个立体帧组成的合成数据集,包含 34,801 个训练数据。
ETH3D 数据集 (Schöps et al., 2017) 是一个包含室内和室外场景的灰度数据集,包含 27 对训练图像对和 20 对测试图像对。
所提出网络的训练采用了 Adam 优化器,参数设置为 η = 0.0001 \eta = 0.0001 η=0.0001, β 1 = 0.9 \beta_ 1 = 0.9 β1=0.9, β 2 = 0.999 \beta_ 2 = 0.999 β2=0.999,和 ϵ = 1 0 − 8 \epsilon = 10^{-8} ϵ=10−8。所提出方法分别使用 20 次和 500 次拍摄学习进行了 100 和 15 个周期的训练。对于其他比较方法,训练策略和超参数设置遵循了论文或开源代码。实验使用 PyTorch 在一台搭载 AMD Ryzen 1920X CPU、64GB RAM 和四块 NVIDIA RTX3090 的个人计算机上进行。
4.1 视差估计准确性和训练需求
在本小节中,验证了所提出方法的视差估计准确性和训练需求。选择错误像素百分比 badδD 作为评估指标,定义为:
badδD = 1 N ∑ ( x , y ) ∈ dest ( ∣ dest ( x , y ) − dgt ( x , y ) ∣ > δ D ) \text{badδD} = \frac{1}{N} \sum_ {(x,y) \in \text{dest}} (|\text{dest}(x, y) - \text{dgt}(x, y)| > \delta_ D) badδD=N1(x,y)∈dest∑(∣dest(x,y)−dgt(x,y)∣>δD)
其中 dest 和 dgt 分别是估计的视差图和地面真实值,δD 是误差阈值,通常设置为 1.0 到 3.0 之间的值,N 是像素总数。为了公平比较,在本小节中,所有方法的训练集和测试集都来自同一数据集,以排除领域适应性对实验结果的影响。
在 Middlebury 数据集上,Middlebury 数据集包含总共 33 对静态室内场景的图像对,其中 23 对图像对有地面真实值。在本实验中,随机选择了 20 对图像对形成训练集,剩余的图像被视为测试样本。结果总结在表 1 中。从表中可以看出,所提出方法的视差估计准确性显著优于其他方法,而比较方法的较差性能可能是由于训练数据不足,即 20 对图像对的地面真实值远未达到它们所需的训练样本数量。这表明所提出方法的训练需求远低于比较方法,且所提出的模型更适合于缺乏标记数据的应用场景。

在 KITTI 数据集上,KITTI 2012 子集包含 194 对图像对,KITTI 2015 子集包含 200 对图像对。所有图像对都是从户外驾驶场景捕获的,并且包含遮挡。对于训练我们的模型,从 KITTI 2015 中随机选择了 20 对图像对,而其他网络则使用 KITTI 2015 中的全部 200 对图像对进行训练。KITTI 2012 子集被视为所有方法的测试集。在 KITTI 2012 子集上获得了 bad3.0 指标的平均值。为了验证它们在图像遮挡存在时的性能,分别列出了非遮挡区域(NOC)和整个图像(OCC)的 bad3.0 指标,结果列在表 2 中。从结果中我们观察到两点:(1) 所提出方法用 20 对图像对训练的视差估计准确性明显高于 PSMNet、AANet、GA-Net 和 GWCNet,并且略低于使用整个 KITTI 2015 子集训练的 CFNet。这表明所提出方法具有少样本学习能力。(2) 对于包含遮挡区域的图像,所提出的用 20 个样本进行少样本训练的模型达到了相对较高的估计准确性,这表明所提出的模型对图像遮挡具有较高的鲁棒性。

在 SceneFlow 数据集上,SceneFlow 数据集包含 39,049 对合成图像对,形成三个子集:FlyingThings3D (26,056)、Monkaa (8,591) 和 Driving (4,392)。从 SceneFlow 数据集中随机选择了 20 对图像对用于训练所提出的方法,而比较方法则使用了 5,000 对随机选择的图像对进行训练。剩余的 Driving 子集中的样本用于测试。结果显示在表 3 中。可以看出,即使使用了 5,000 个训练样本,一些方法如 GWCNet 仍然比所提出的方法表现得差得多,而其他方法需要比所提出的方法多 250 倍的数据才能达到相似的性能,这表明所提出的方法能够更有效地利用少量数据进行学习。这一特性在实际应用中非常重要,当在不熟悉的环境中部署算法时,研究人员只需要获得非常少量的样本,就能使所提出的方法获得满意的结果。

在 WHU Stereo 2023 数据集上,WHU Stereo 2023 是一个由高分辨率卫星图像形成的大规模数据集,包含 1,220 对用于训练的图像对、122 对用于验证的图像对和 415 对用于测试的图像对。对于这种特殊的场景,即卫星图像立体匹配,地面真实值包含负视差(He et al., 2022; Li et al., 2023),这需要在立体匹配方法中特别处理。所提出的自适应递归三维卷积神经网络适用于负视差情况,只要在计算多尺度匹配成本时考虑负视差。给定候选视差范围 [−S1, S2],在所提出的自适应递归三维卷积神经网络中(如图 2 所示),视差图 O C 2 ( x , y ) O_ {C2}(x, y) OC2(x,y) 可以通过以下公式获得:
O C 2 ( x , y ) = − S 1 + K × C 1 M R ( 2 , 1 , x , y ) O_ {C2}(x, y) = -S1 + K \times C_ 1^{M_ R}(2, 1, x, y) OC2(x,y)=−S1+K×C1MR(2,1,x,y)
其中 K = S 1 + S 2 K = S1 + S2 K=S1+S2 表示匹配成本矩阵 M c ( x , y , k ) M_ c(x, y, k) Mc(x,y,k) 中索引 k 的最大值。注意,索引矩阵 M i ( x , y , k ) M_ i(x, y, k) Mi(x,y,k) 已通过公式 (6) 归一化到 [0, 1]。因此,与公式 (6) 中的 k 对应的视差值与候选视差范围相关联。对于视差范围 [−S1, S2],与 k = (0, 1, 2, …, K = S1 + S2) 对应的视差值是 k − S1。显然,实际的视差值可以通过使用公式 (18) 获得。因此,所提出的自适应递归三维卷积神经网络可以直接处理负视差情况。在本实验中,比较了适用于负视差情况的代表性立体匹配方法,包括 SGM (Hirschmuller, 2008)、StereoNet (Khamis et al., 2018)、PSMNet (Chang & Chen, 2018) 和 HMSM-Net (He et al., 2022)。对于所提出的方法,从训练集中随机选择了二十 (20) 对图像对进行训练,而比较方法则使用了完整的训练集 (1,220 对图像对) 进行完全训练,测试集用于评估。结果显示在表 4 中。可以看出,即使使用了 1,220 个训练样本,比较方法如 StereoNet (Khamis et al., 2018) 和 PSMNet (Chang & Chen, 2018) 的性能仍然低于所提出的方法。只有经过完全训练的 HMSM-Net (He et al., 2022),该网络专门设计用于解决负视差问题,其性能优于所提出的方法。同时,从 WHU Stereo 2023 数据集的训练集中随机选择了 10、20、50 和从 100 到 200 个样本,以 20 为增量,用于训练,WHU Stereo 2023 数据集测试集上的错误像素百分比总结在图 4 中。可以看出,所提出的模型用 20 个样本进行少样本训练就可以达到可接受的性能,并且随着训练样本数量的增加,错误像素的百分比会降低,但当训练样本数量超过 120 时,错误像素的百分比变化很小。

可以得出结论,所提出的模型用 20 个样本进行少样本训练就可以达到或甚至超过代表性网络在大量数据上训练的性能,并且对图像遮挡具有很高的鲁棒性。换句话说,所提出的方法具有足够的少样本学习能力。这对于提高立体匹配的适用性和灵活性非常重要。
4.2 领域适应性
在本小节中,验证了所提出模型在少样本训练下的领域适应性。众所周知,到目前为止,提高立体匹配领域适应性的努力有两种:一种是使用目标领域或类似领域的少量训练样本对训练良好的网络进行微调;另一种是领域适应或泛化方法,它们试图通过领域转换、泛化或对齐技术来解决合成和真实领域之间的领域差距。因此,比较了代表性的立体匹配方法及其微调版本,以及一些最先进的领域适应或泛化方法。实验条件如下:(1) 测试样本和训练样本来自不同的数据集;(2) 所提出的方法进行了少样本训练。对于比较方法,有四种情况:(1) 少样本训练;(2) 完全训练;(3) 完全训练和微调;(4) 领域适应或泛化方法。
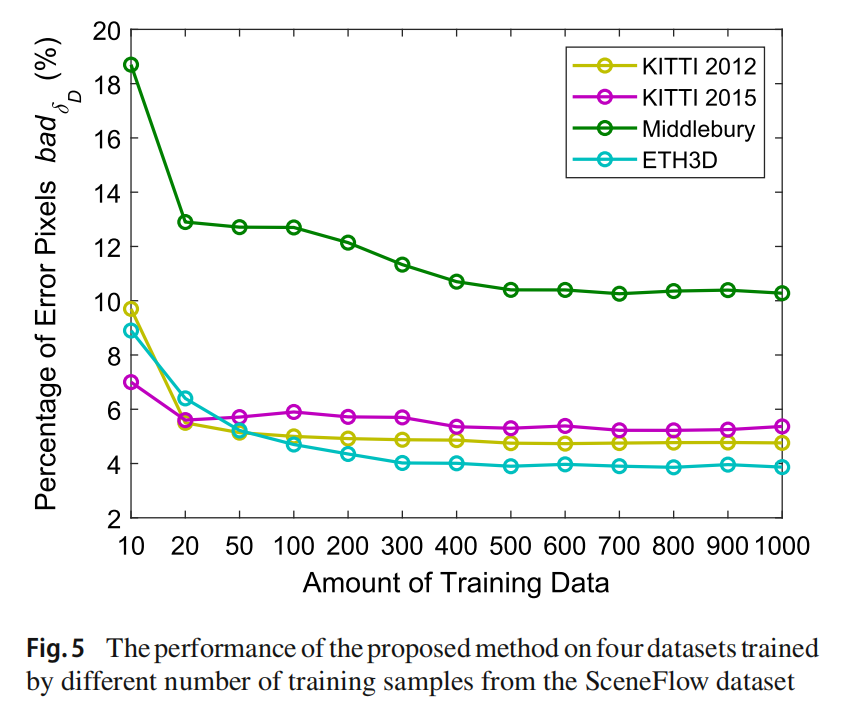
为了说明不同训练样本和训练样本数量对少样本训练下所提出模型性能的影响,从 SceneFlow 数据集中随机选择了 200 个样本,并将其分成十个互不相交的训练集。所提出方法在每个训练集上训练的性能指标获得。最小值、最大值和平均值显示在表 5 中。可以看出,所提出方法的性能在十次实验中仅波动约 0.31%。此外,从 SceneFlow 数据集中随机选择了 10、20、50 和从 100 到 1000 个样本,以 100 为增量,用于训练,KITTI 2012、KITTI 2015、Middlebury 和 ETH3D 数据集上的错误像素百分比总结在图 5 中。从这些结果中,我们有几个观察。首先,所提出模型的少样本训练性能对训练样本的选择不敏感。其次,在所有四个数据集上,用 20 个样本训练的所提出模型都能达到可接受的性能。第三,通常,随着训练样本数量的增加,错误像素的百分比会降低,但当训练样本数量超过 500 时,错误像素的百分比变化很小,因此在后续实验中,考虑了所提出模型在 20 次拍摄学习和 500 次拍摄学习下的两种版本。
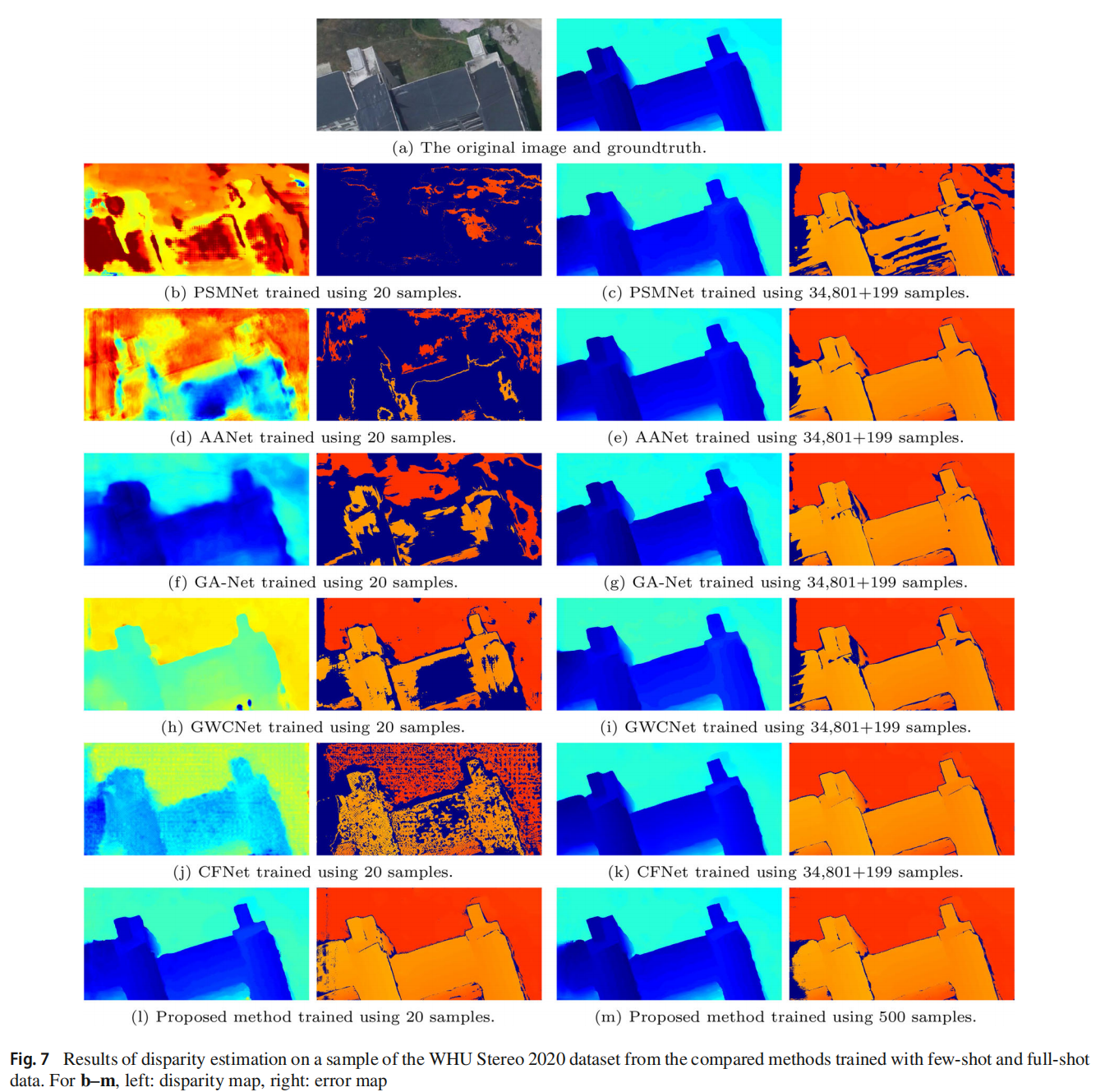
少样本对比少样本。在这个实验中,所有方法都使用 Middlebury 数据集中的 20 对图像对进行了少样本训练。KITTI 2012 子集、KITTI 2015 子集和 WHU 2020 数据集被用于测试。两个 KITTI 子集上带有遮挡区域(OCC)和非遮挡区域(NOC)的平均 bad3.0 指标在表 6 中列出,一个样本的估计视差图和相应的误差图显示在图 6 中。WHU 2020 数据集上的结果在表 7 和图 7 中显示。可以看出,在有遮挡或无遮挡区域中,所提出的方法在所有比较方法中排名第一,而且大多数比较方法在 20 次拍摄训练下不能很好地跨域工作。



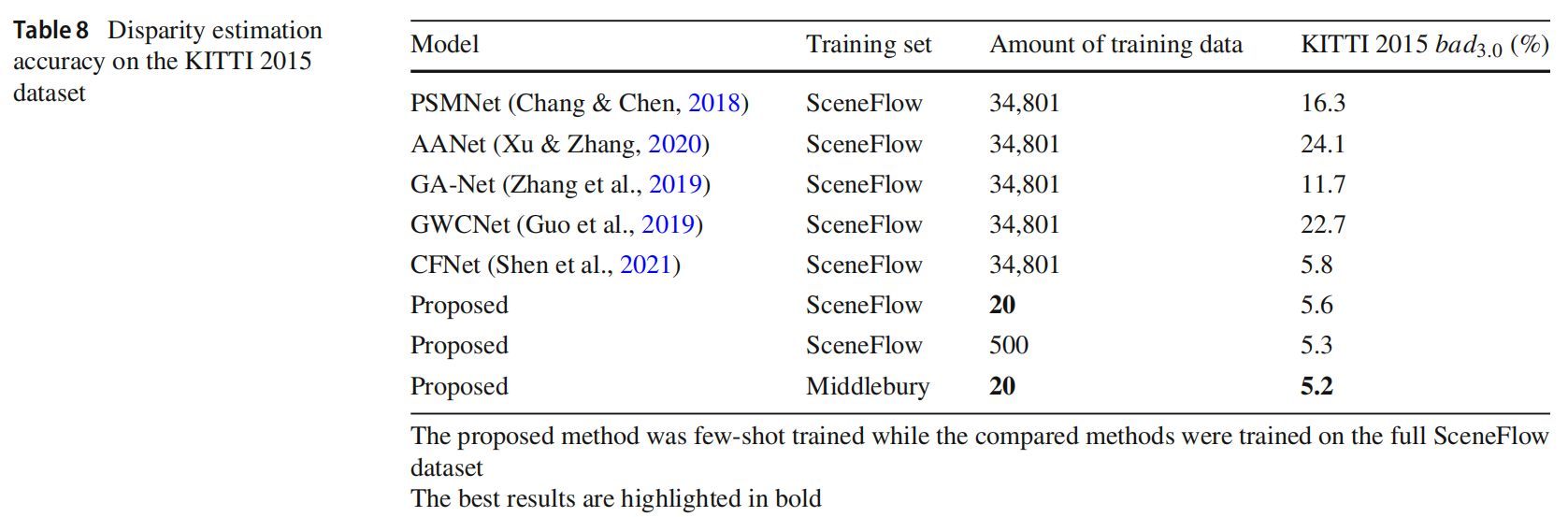
少样本对比完全训练。在上述实验中,比较方法的较差性能是由于它们的领域适应性差和训练数据不足造成的。为了突出领域适应性的影响,在本实验中,所有比较方法都使用 SceneFlow 数据集的 34,801 个训练样本进行了训练,而所提出模型则使用从 SceneFlow 数据集中随机选择的 20 或 500 个训练样本进行了训练,然后使用 KITTI 2015 数据集作为测试集。结果显示在表 8 中。可以看出,用 20 个样本进行少样本训练的所提出模型在跨域视差估计准确性方面明显高于其他训练良好的方法。这表明在领域适应性方面,少样本训练的所提出模型优于其他训练良好的方法。从表 6 和表 8 也可以看出,即使所提出模型是用不同的数据集进行少样本训练,所获得的跨域性能也非常接近,这表明所提出的方法具有鲁棒的领域适应能力,与训练样本的特征关系不大。
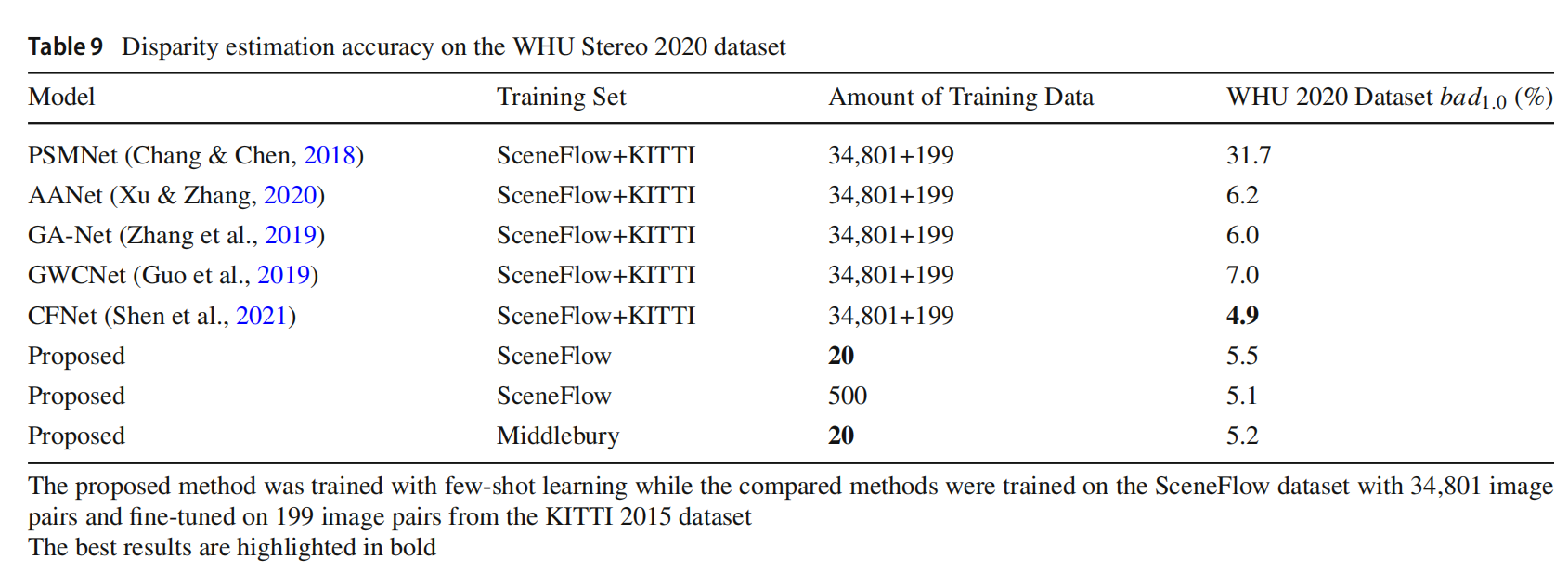
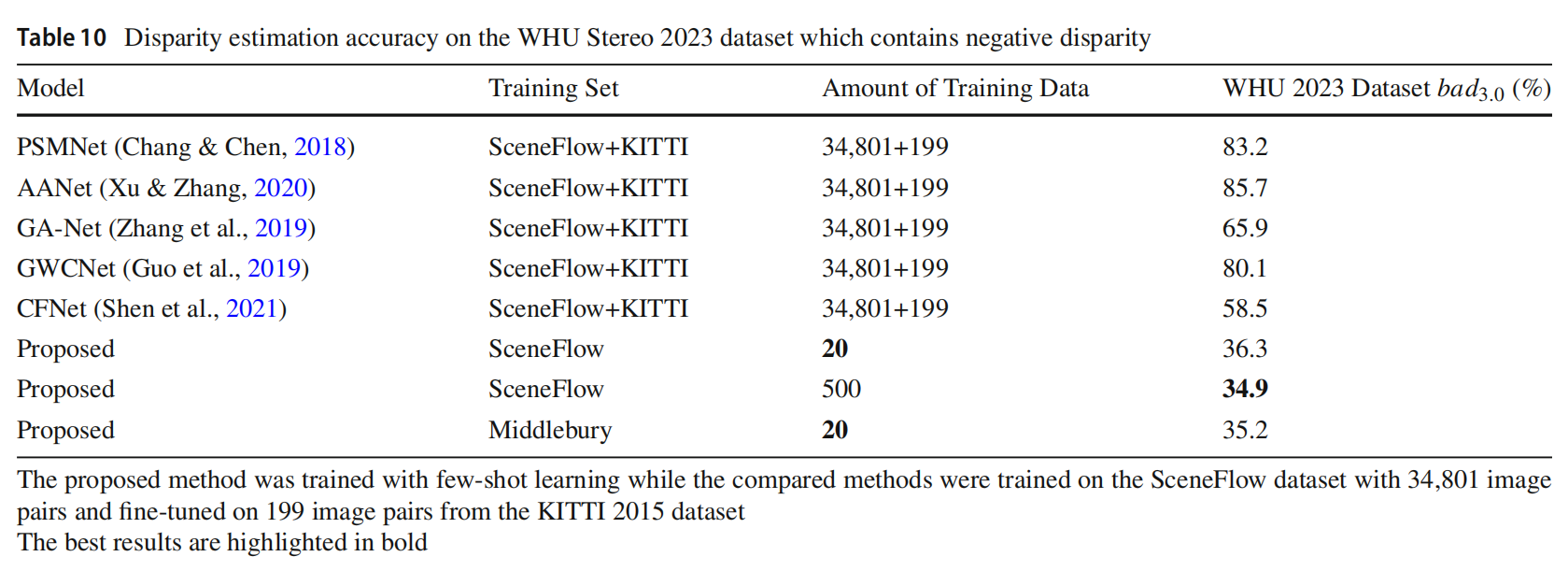
少样本对比完全训练和微调。所提出模型用从 SceneFlow 数据集中随机选择的训练样本进行了少样本训练。所有比较方法都使用 SceneFlow 数据集的 34,801 个训练样本进行了训练,然后使用 KITTI 2015 数据集的 199 个随机选择的样本进行了微调,WHU Stereo 2020 和 WHU Stereo 2023 数据集被视为测试集。结果显示在表 9、表 10、图 7 和图 8 中。可以看出,在 WHU Stereo 2020 数据集上,用 Middlebury 数据集的 20 个样本进行少样本训练的所提出方法的错误率仅略高于 CFNet(高出 0.3%),用 SceneFlow 数据集的 500 个样本进行少样本训练的所提出方法略高于 CFNet(高出 0.2%),但仍然优于其他比较方法,即使这些方法经过了完全训练和微调。在包含负视差的 WHU Stereo 2023 数据集上,少样本训练的所提出方法显示出比经过完全训练和微调的比较方法更好的泛化能力,其他方法的较差性能表明它们很难泛化到负视差。考虑到用于训练的数据量的巨大差距,所提出的方法在领域适应性方面具有极其优越的性能,并且具有少样本学习能力。

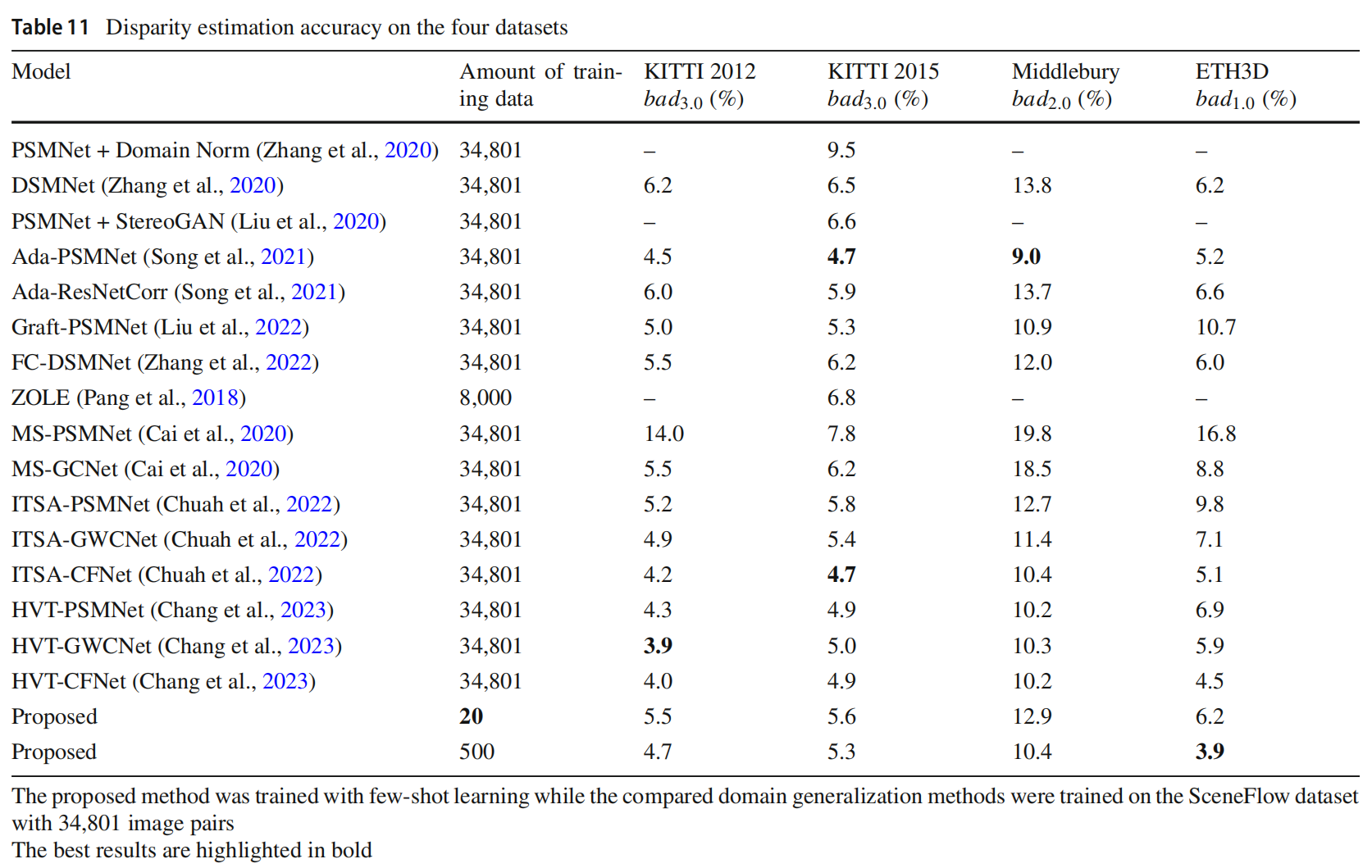
少样本对比最近的领域自适应算法。最近的工作试图通过解决合成和真实领域之间的领域差距来提高立体匹配的领域适应能力。在本小节中,比较了一些最先进的领域适应或泛化方法,包括 DSMNet (Zhang et al., 2020)、StereoGAN (Liu et al., 2020)、AdaStereo (Song et al., 2021)、GraftNet (Liu et al., 2022)、FC-DSMNet (Zhang et al., 2022)、ZOLE (Pang et al., 2018)、MSNet (Cai et al., 2020)、ITSA (Chuah et al., 2022) 和 HVT (Chang et al., 2023),这些方法都是在 SceneFlow 数据集的合成场景上训练的,并且在 KITTI 2012、KITTI 2015、Middlebury 和 ETH3D 数据集上进行了性能评估。值得注意的是,由于 ZOLE (Pang et al., 2018) 的视差范围限制,ZOLE 的训练集只包含 8,000 对图像对。结果显示在表 11 中。可以看出,所有比较的方法都能够从合成场景到真实场景实现出色的领域适应性和泛化性能。对于 KITTI 2012 和 KITTI 2015 数据集,所提出的方法在训练数据集远小于比较的领域自适应方法的情况下,性能仍然优于大多数方法,并且仅略微落后于 Ada-PSMNet (Song et al., 2021)、ITSA-CFNet (Chuah et al., 2022) 和 HVT (Chang et al., 2023)。对于 Middlebury 数据集,用 500 个样本训练的所提出方法的性能优于大多数领域自适应方法,并且仅略微落后于 Ada-PSMNet (Song et al., 2021) 和 HVT (Chang et al., 2023)。对于 ETH3D 数据集,用 500 个样本训练的所提出方法在所有比较方法中排名第一。即使对于用 20 个样本训练的所提出方法,它在所有四个数据集上的性能也优于大多数领域自适应方法,如 DSMNet、MSNet-PSMNet、MSNet-GCNet 和 Ada-ResNetCorr。此外,与 Ada-PSMNet 不同,所提出的方法没有对来自不同数据集的输入数据执行任何领域对齐,因此其领域泛化性能完全由所提出的组件提供。优越的领域适应性和泛化性能可能来自于所提出的网络学习了动态规划设置,这可以显著降低立体匹配这一病态问题的难度,当递归解决这个优化问题时,初始解空间不依赖于任何特定数据集的语义信息。
4.3 消融研究
在我们的消融研究中,评估了所提出的递归结构的有效性。从表 12 可以看出,当不采用递归结构时,准确性较差,错误率 bad3.0 大约为 10%。然后,采用了所提出的递归结构,但没有自适应递归模块,可以将立体匹配转化为固定步骤的近似任务,性能显著提高(约 2-4%),这验证了所提出网络的递归结构的有效性。此外,当采用自适应递归模块时,可以获得适应不同补丁特征的相对全面的解空间。因此,性能进一步提高了约 2%。显然,这个实验验证了所提出的自适应递归网络的有效性,以及将立体匹配转化为多步骤优化过程的思想。对于多尺度匹配成本计算,与单尺度匹配成本相比,多尺度成本矩阵可以过滤掉一些由噪声引起的错误匹配,从而提供了 0.5-1.5% 的性能提升。

4.4 计算成本
在这一部分中,使用SceneFlow数据集来验证所提出方法的计算成本。实验使用PyTorch和Python 3.8在一块NVIDIA RTX3090上进行。所有比较方法对一张大小为960×540的图像进行10次重复运行的平均训练和推理时间如表13所示。可以看出,由于引入了递归结构,所提出的网络在单张图像上的推理和训练速度较慢。但值得注意的是,所提出的网络只需要较少的训练样本就可以收敛。

5 结论
本研究针对基于深度学习的立体匹配算法在训练需求巨大和领域适应性差这两个缺点进行了解决,这些缺点显著限制了这些算法在实际应用中的广度和性能。在本文中,提出了一个具有高领域适应性的少样本训练立体匹配模型。实验结果表明,所提出的模型在训练需求和领域适应性方面优于现有的立体匹配算法。我们的模型在立体匹配任务中具有很大的应用潜力。在未来的工作中,将专注于进一步提高立体匹配的准确性,并可能考虑采用联合网络框架来提高立体匹配的准确性。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准备。
本文信息旨在传播和交流学术,其内容由作者负责,不代表本号观点。文中内容如涉及作品文字。图片等内容、版权和其他问题,请及时与我们联系,我们将在第一时间删文处理。
















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











