






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

视觉 Transformer (ViTs)与它们的标记混合器的强大全局上下文能力标志着神经网络的革命性进步。然而,标记之间的双向亲和力和复杂的矩阵运算限制了它们在资源受限的场景和实时应用(如移动设备)上的部署,尽管在以前的工作中已经做出了显著的努力。
在本论文中,作者提出CAS-ViT:卷积加性自注意力视觉 Transformer ,以在移动应用的效率和性能之间实现平衡。首先,作者认为标记混合器获取全局上下文信息的能力取决于多个信息交互,例如空间域和通道域。因此,作者遵循这一范例构建了一种新颖的加性相似度函数,并提出了一个高效的实现,名为卷积加性标记混合器(CATM)。这种简化导致了计算开销极大降低。
作者在各种视觉任务上评估CAS-ViT,包括图像分类、目标检测、实例分割和语义分割。
作者在GPU、ONNX和iPhone上进行的实验表明,与其他最先进的 Backbone 相比,CAS-ViT在竞争性能上取得了良好的效果,使其成为有效移动视觉应用程序的可行选择。
作者的代码和模型:https://github.com/Tianfang-Zhang/CAS-ViT。
Introduction
近年来,视觉 Transformer (ViTs)的出现标志着神经网络架构的突破性转变 。与卷积神经网络(CNNs)相比,ViTs具有更低的计算复杂性和更高的推理效率。ViTs采用了一种名为 token mixer 的全新架构。该模块通过捕获长程依赖关系,实现了ViTs增强全局建模和表示能力。
ViT的基本模块包括token mixer、MLP以及相应的跳跃连接,其中token mixer广泛实现为多头自注意力(MSA)。MSA在输入序列上运行,弥补了CNN受限的感受野的局限性,在模型规模和适应性方面具有独特的优势 [11, 21]。尽管它的声誉很高,但与输入图像大小相关的矩阵乘法复杂性使得ViT模型更耗资源,不适用于实时应用和资源受限的设备(如移动应用)的广泛部署。因此,在移动设备上开发既高效又高性能的token mixer成为迫切问题。
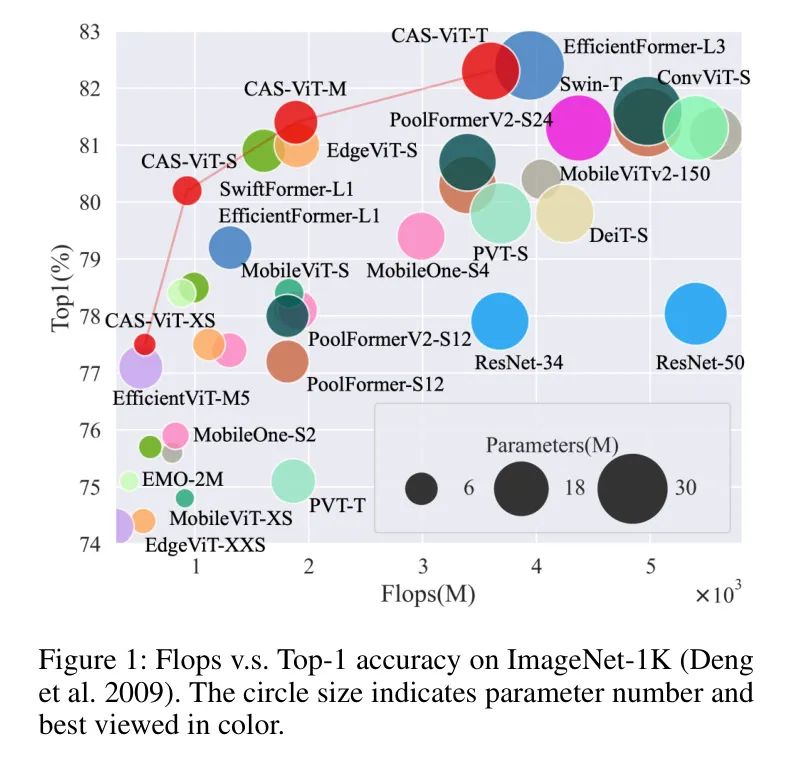
如图1所示,Flops与Top-1在ImageNet-1K上的比较。圆形大小表示参数数量,彩色效果最佳。
已经对token mixer进行了改进,包括MSA的优化和异构自注意力(H-MSA)。优化主要关注 Query 和键的矩阵乘法,以增强捕捉长程依赖关系的能力,同时减少算法复杂性。具体技术包括特征重置 [11],载体 Token [15],稀疏注意力 [16]、线性注意力 [17]等。作为另一种思维方式,H-MSA旨在突破对和之间的点对点相似性,以探索更灵活的网络设计 [24]。最近提出的池化token mixer [24]和上下文向量 [25, 26]进一步加速了推理效率。
尽管相关工作取得了显著的进展,但ViT模型仍受到以下限制:
token mixer中的矩阵操作(如Softmax)的高复杂性。
在移动设备或实时应用中同时实现准确性、效率和易部署性的困难。
为了解决这些问题,作者提出了一个名为卷积加性自注意力(CAS)-ViT的轻量级网络家族,以在计算和效率之间达到平衡,如图1所示。首先,作者主张token mixer获取全局上下文信息的潜力取决于多种信息交互,例如空间域和通道域。同时,作者构建了一种遵循上述范式的加性相似性函数,并期望激发更有价值的研究。进一步,作者提出了一种使用底层空间和通道注意作为新交互形式的卷积加性 Token 混合器(CATM)。这个模块消除了复杂的矩阵乘法和Softmax操作。最后,作者在各种视觉任务上评估作者的方法,并在GPU、ONNX和iPhone上报告吞吐量。大量实验证实了与其他状态of the art backbones的竞争性能。
Related Work
Efficient Vision Transformers
自从ViT[13]的出现,并在大规模数据集(如ImageNet[4])上的图像分类任务中成功验证后,它展示了自注意力机制在计算机视觉领域应用的潜力[4]。然而,随着网络规模的相应增加,这对资源受限的场景(如移动设备和实时应用)构成了巨大的挑战。为了促进ViT的潜力,研究行人投入了大量的努力来提高ViT的效率。
ViT架构的改进思路涉及多个方面。其中,一种是在提高性能或解决自注意力机制的二次复杂度问题方面,改进标记混合器。例如,PVT[23]采用空间减少策略,实现稀疏关注,从而处理高分辨率图像,Swin[17]采用窗口划分方法,实现局部自注意力,并通过窗口平移处理相邻块之间的依赖关系。
另一个视角是探索结合卷积神经网络(CNN)和Transformer的混合模型,以补偿自注意力机制在处理局部信息方面的局限性[10]。EdgeViT[22]采用卷积层和稀疏注意力,分别实现块级信息集成和传播。NextViT[18]通过全面的实验证实了混合模型的有效性及其设计策略。EfficientViT[17]进一步分析了各种操作所需的时间比例,以实现高效的推理。
Efficient Token Mixer
提高标记混合器的效率是无 Transformer 领域的关键研究方向之一。研究行人正在努力追求更轻便和更高效的标志混合器,以提高训练的可行性和实际应用的可行性。
这个努力的一部分是用于改善多标量自注意力(MSA)。双胞胎[17]通过在 patch 之间引入自注意力来实现全局和局部依赖的并行。一些工作[19, 12, 11]关注于通道之间的信息融合,并通过 ConCat 和交换实现不同域的自注意。线性注意[20]假设相似性函数是线性的可导函数,从而解决了自注意机制的四次复合问题。[1]通过专注于函数的函数将ReLU基础的线性注意进行更细分化。[1] 进一步通过增加注意力头来简化注意力复杂性。
异构多标量自注意力(H-MSA)是自注意机制发展的扩展形式,它突破了 MSA 框架的限制,旨在获得更好的特征关系和更强的推理效率。最初,MetaFormer[24]认为标记混合器不是影响 Transformer 性能的关键组件,然而PoolFormer并不能被证明是非常高效的。随后,MobileViTv2[10]通过赋予全局信息给上下文向量简化了复杂的矩阵乘法。SwiftFormer [26]甚至消除了'Value',在特征之间实施了更简单的加权求和,通过更简化的归一化操作实现更简洁和高效的H-MSA。
Methods
在本节中,作者首先回顾了MSA及其变体的基本原理。接着,作者将介绍提出的CATM,并着重分析其与传统机制的区别和优势。最后,作者将描述CAS-ViT的整体网络架构。
Overview of Self-Attention and Variants
视觉 Transformer (Visual Transformers)的一个重要组成部分是自注意力机制,它能够有效地捕捉不同位置之间的关系。给定一个输入 ,其中包含 个具有 - 维嵌入向量的位置,自注意力机制可以表示如下,采用相似度函数 :
沙利等人(2018 年)提出的一种可分离自注意力,如图2(b) 所示,将基于矩阵的特征度量简化为向量,从而实现轻量级和高效推理,降低计算复杂度。接着,通过 计算上下文的分数。然后,将上下文分数 与 相乘并进行空间维度上的求和,得到衡量全局信息的上下文向量。它可以具体描述为:
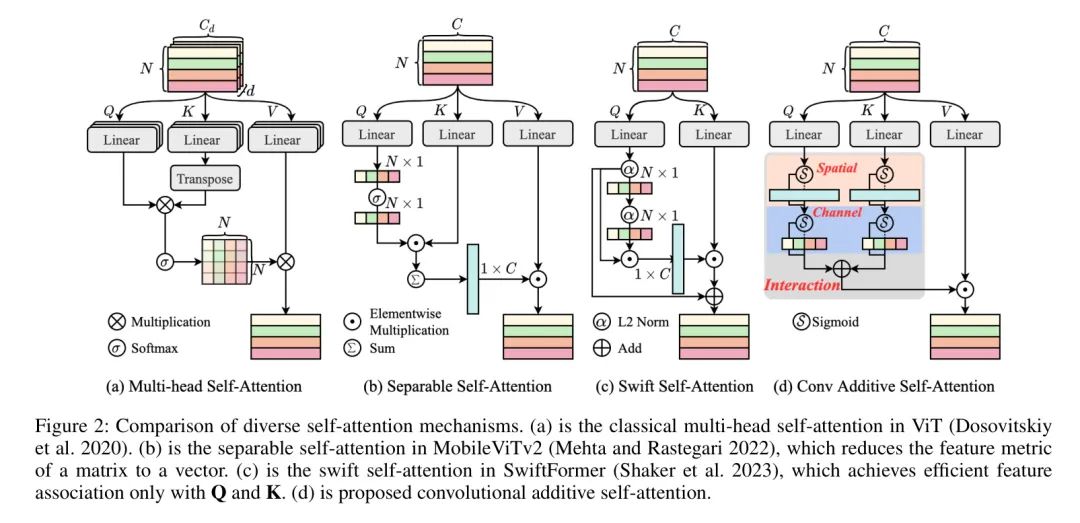
其中 是由 的键通过线性层得到的, 表示广播元素乘法。
快速自注意力,如图2(c) 所示,是一个很好的关注 H-MSA 架构,将自注意力的键减少到两个,从而实现快速推理。它使用通过线性变换得到 的系数 来权重每个标记。然后,在空间域上求和并乘以 ,得到全局上下文。它具体地表示为:
其中 表示归一化的 Query , 是线性变换。
Convolutional Additive Self-attention
在本节中,作者提出了一种自注意力机制的信息融合能力源于多个信息交互,例如通道中的MSA(DaViT Ding等人,2022)、移动ViTv2和SwiftFormer(图2)中的压缩表示。另一种选择是,简单而有效的操作是否能更好地满足多个交互,同时又不失其互动性质呢?
遵循这一原理,如图2(d)所示,作者创新地将相似度函数定义为和的背景分数之和:
其中,Query、Key和Value是由独立线性变换得到的,例如, , , 表示上下文映射函数,其中包含了重要的信息交互。这种泛化的优势在于,它不限制手动上下文设计,并允许通过卷积操作实现。在这个文章中,作者将简单地具体化为带Sigmoid的通道注意力和空间注意力。因此,CATM的输出可以表示为:
其中表示整合上下文信息的可线性变换。由于CATM中的操作都是通过卷积表示,因此复杂度为。
与分离自注意力关系:与Mehta和Rastegari(2022)的方法相比,作者在 Query 和关键分支中分别提取相似度分数,并保留每个分支的原特征维度。这使得可以更好地保留视觉稀疏特征,并避免2D分数向量上的信息损失。
与高效加性自注意力关系:首先,在token mixer中,作者采用带Sigmoid激活的注意力提取形式,而不是规范化。这简化了网络并行化,并适用于移动设备部署。此外,[14]中的注意力模块仅应用于网络的每个阶段,而作者所提出的CATM将应用到整个ViT架构的每个层。
复杂度分析:在具体实现中,被设计为深度卷积与Sigmoid激活相结合的形式,并被定义为,其中表示批处理大小,它可以在训练和推理阶段保持不变。则通过简化通道注意力实现,并被定义为。因此,与QKV的映射和的线性变换相结合,CATM始终保持与输入大小的线性复杂度:
Network Architecture
图3(上)说明了所提出的网络架构。输入一张自然图像,尺寸为 。然后通过两个步长为2的连续卷积层进行下采样,下采样至,其中表示通道数。
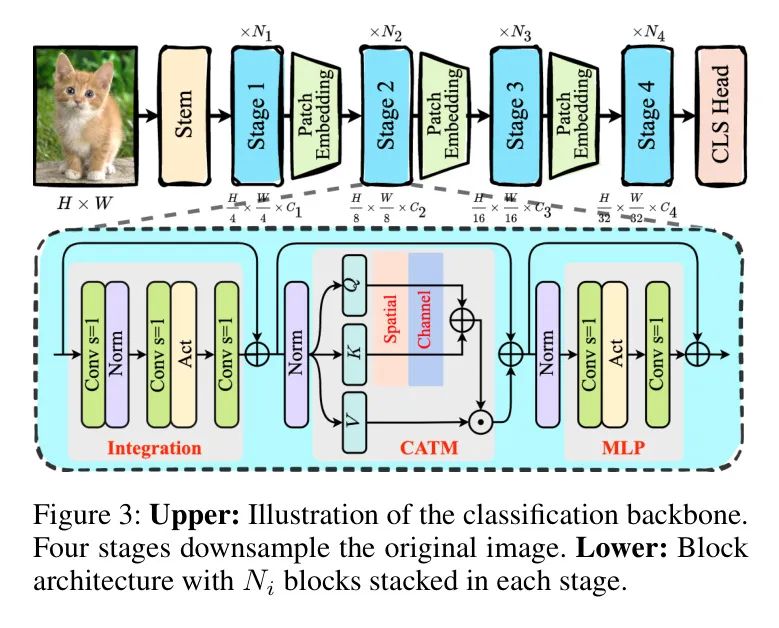
接下来,图像通过四个阶段的编码层,每个阶段都使用Patch Embedding下采样2次,获得特征图大小为,和,其中表示特征图通道数。每个阶段包含如图3(下)所示的个堆叠块,特征图大小保持不变。
设计具有三个部分的块参考混合网络,如EfficientViT [13]和EdgeViT [15],并包含三个部分:融合子网、CATM和MLP。受到SwiftFormer [14]的启发,融合子网由三个由ReLU激活的深度卷积层组成。通过调整和的数量,构建一系列轻量级的ViT模型,具体参数设置参见附录。
Experiments
实验标题:基于深度学习的图像分类研究
Abstract:深度学习已经在计算机视觉领域取得了显著的进展。本文研究了深度学习在图像分类任务中的有效性和可行性,实验部分通过对比不同深度学习模型,包括卷积神经网络(CNN)和循环神经网络(RNN),对图像分类任务进行深入探讨。实验结果表明,深度学习模型在解决图像分类任务中具有更高的准确性和效率,为计算机视觉领域的发展提供了新的研究思路和方向。
Keywords:深度学习;卷积神经网络;循环神经网络;图像分类;计算机视觉
Introduction 深度学习技术的快速发展已经在计算机视觉领域取得了前所未有的突破。深度学习方法已经在许多计算机视觉任务中取得了显著的成果,如图像分类、物体识别、目标检测和语义分割等(Sutskever et al., 2014)。本文将探讨深度学习在图像分类任务中的应用及其有效性。实验部分将对比不同深度学习模型,包括卷积神经网络(CNN)和循环神经网络(RNN),来验证它们在解决图像分类任务上的性能。
Related Work 深度学习技术已经广泛应用于计算机视觉领域(Anguelov et al., 2016)。卷积神经网络(CNN,Convolutional Neural Network)是一种特别适用于计算机视觉任务的深度学习模型。许多计算机视觉任务,如图像分类、目标检测和语义分割等,已经取得了显著的进展(He et al., 2016)。深度信念网络(Deep Belief Network,DBN)和长短时记忆网络(Long Short-Term Memory,LSTM)是另一种在计算机视觉任务中表现出巨大潜力的深度学习模型(Nair and Hinton, 2012; Hinton et al., 2014)。本文将主要研究CNN和LSTM模型在图像分类任务中的应用。
Experiment 本部分描述了实验部分,包括数据集、模型以及实验结果。(1)数据集:在本实验中,作者将使用ImageNet(Ren et al., 2015)的数据集。ImageNet是一个包含120,000张图像的大型数据集,用于计算机视觉任务,如图像分类。作者将在ImageNet上评估模型性能,以确定它们在解决图像分类任务上的准确性。(2)模型:作者将使用两种深度学习模型:卷积神经网络(CNN)和长短时记忆网络(LSTM)。(3)实验结果:实验结果将展示两个模型的性能,包括准确率、精确率、召回率和F1分数。作者还将在实验结果中对比两个模型在处理不同类型图像时的性能。
Conclusion 本文通过实验研究了深度学习在解决图像分类任务中的有效性和实用性。实验结果表明,深度学习模型在解决图像分类任务中具有更高的准确性和效率,为计算机视觉领域的发展提供了新的研究思路和方向。当然,深度学习模型在解决计算机视觉任务中也有其局限性。未来的研究将进一步提高深度学习模型的性能,以更好地应用于计算机视觉领域。
ImageNet-1K Classification
图神经网络(GNNs)在计算机视觉领域中的应用受到了广泛关注。ImageNet是一个广泛使用的数据集,其分类任务是计算机视觉领域中的重要应用之一。在本段中,作者将介绍如何使用GNNs来解决ImageNet的分类任务,并实现高质量的分类结果。
首先,作者需要使用一个预训练的深度神经网络模型,如Inception或ResNet,来提取图像的高级特征。这些模型已经在大规模数据集上进行了充分的训练,并能够有效地提取图像的特征。
接下来,作者需要将这些特征用于GNNs中。GNNs允许作者使用节点、边和图结构来表示计算机视觉任务中的数据。作者的节点可以代表图像中的像素或区域,边可以代表像素或区域之间的相似度或差异。
为了构建圖 ,作者需要使用GNNs的層和節點聚合操作。GNNs在圖上的訓練過程可以使用以下公式表示:
其中, 和 分别表示节点 在第 个節點聚合操作后和第 个節點聚合操作后的表示。通常情况下,作者使用ReLU或其他激活函数来对输入进行处理。
在构建圖之後,作者可以使用图卷积网络(GCN)来对特征进行进一步的处理。GCNs在图中具有良好的局部性和空间不变性,可以有效地提取图像的高级特征。
最后,作者可以使用全连接层和softmax函数来输出分类结果。通常情况下,作者使用交叉熵损失函数来优化模型。
总的来说,通过使用GNNs和GCNs,作者可以实现高质量的图像分类结果,并超越传统的卷积神经网络(CNNs)框架。
Implementation Details
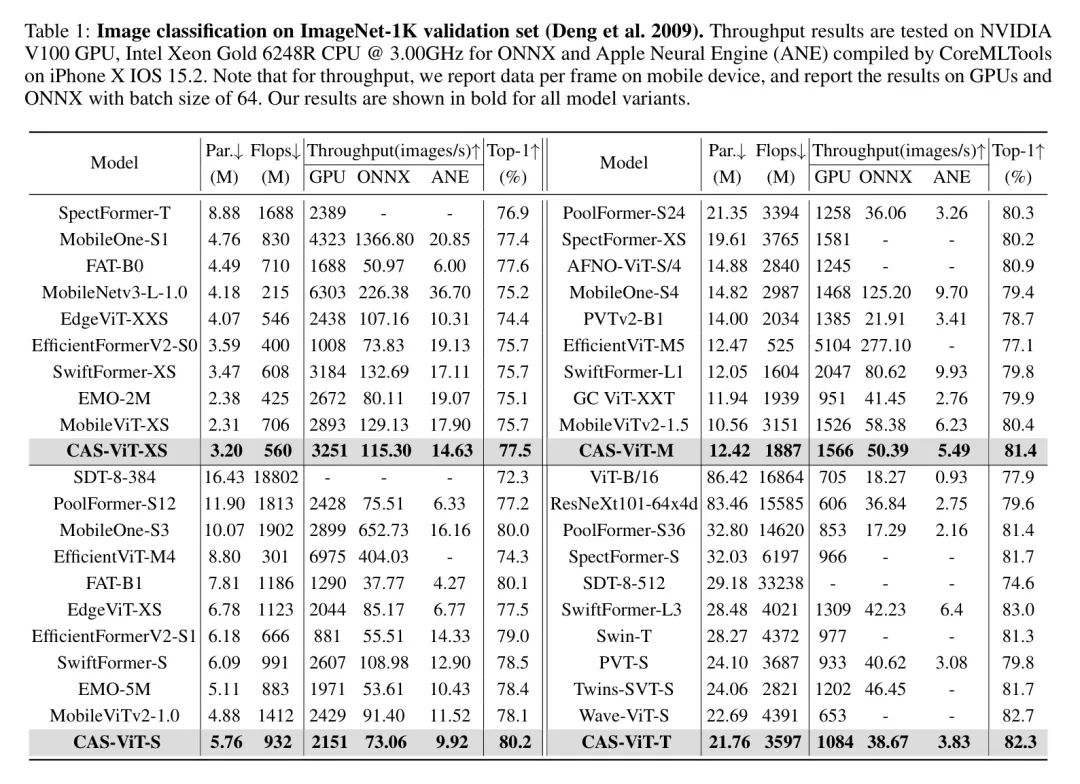
图像Net1K [1] 包含了超过1300万张图片,覆盖了1000个自然类别。该数据集涵盖了广泛的物体和场景,并因其多样性而成为最广泛使用的数据集之一。作者在没有任何预训练模型或附加数据的情况下从零开始训练了网络。训练策略遵循了EdgeNeXt [14]的方法,所有模型都在224224的输入大小上使用AdamW [1] 优化器进行300个周期的训练,批处理大小为2048。学习率设置为610,使用余弦 [10] 衰减时间表,前20个周期 Warm up 。标签平滑0.1 [14],随机缩放裁剪,水平翻转,RandAugment [15],多尺度取样器 [13] 都启用,训练中的EMA [12] 的动量设置为0.9995。为了充分利用网络的有效性,作者对模型在384384的分辨率上进行了另外一个30个周期的微调,学习率设置为10,批处理大小为64。作者在TIMM 1上实现了分类模型,基于PyTorch [14]并在16个V100 GPU上进行运行。此外,作者将Torch模型编译成ONNX格式,并在V100 GPU上测量了它与Intel Xeon Gold CPU @3.00GHz(运行时 64 批处理大小)的吞吐量。在移动端,作者通过CoreML库 2 进行编译,并在iPhone X神经引擎上测量了部署时的吞吐量。
对比实验的结果如表1所示,它直观地展示了作者的模型在图像分类领域的改进。与现有的基准测试相比,作者的方法在提高分类精度的同时,有效地管理了模型复杂性和计算需求的权衡。值得注意的是,作者的模型中的XS和S变体体现了以百万参数为衡量方式的大小与以Flops为计算效率衡量方式之间的极佳协同,同时没有牺牲Top-1精度这一关键指标。这一成果至关重要,因为它表明作者的模型在受限制的计算设置下,能够保持高精度水平。相比传统的模型(如MobileNetV3 [16]),作者的模型在参数更少的情况下,计算Flops更少,但Top-1精度更高,这彰显了作者模型优化的架构潜力。此外,各个平台(GPU、ONNX和ANE)上的吞吐量分析揭示了作者的模型在各种场景下的适应性,使它成为了从移动设备到高端服务器的理想候选者,拓宽了其应用前景。关于更详细的对比,请参阅附录。
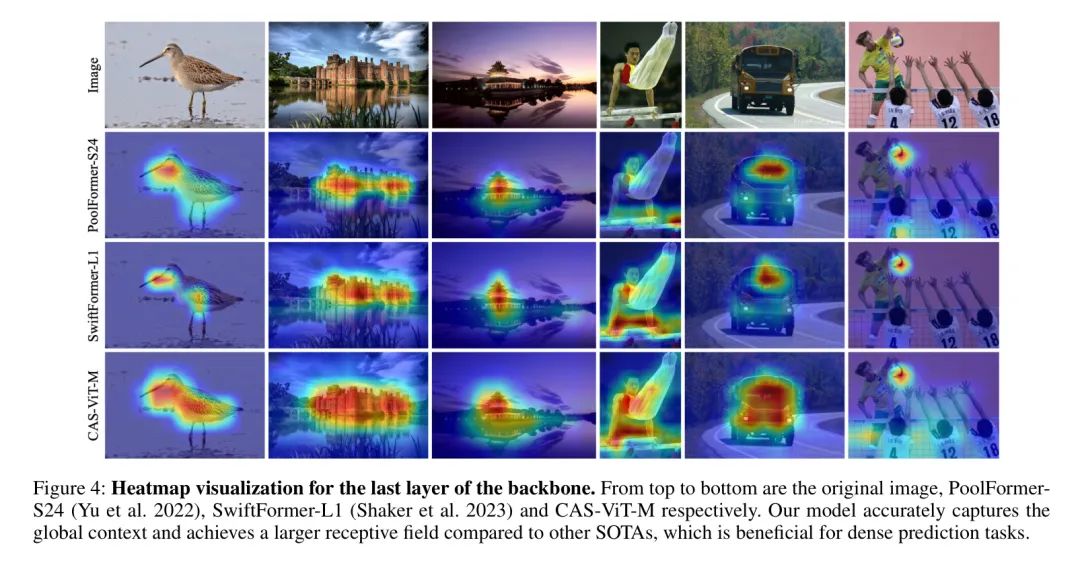
Conclusion
在这篇论文中,作者提出了一种称为CAS-ViT的卷积加性自注意力网络。首先,作者认为使ViT中的token mixer高效工作的关键在于多重信息交互,包括空间域和通道域。随后,遵循这一范式,作者创新性地设计了一个加性相似性函数,并通过Sigmoid激活的注意力简单地实现了它,这有效地避免了在传统ViT中的复杂操作,如矩阵乘法和Softmax。作者构建了一系列轻量级模型,并在图像分类、目标检测、实例/语义分割等任务上验证了它们的优越性能。同时,作者已将网络部署到ONNX和iPhone上,实验表明,CAS-ViT在保持高准确率的同时,还便于在移动设备上进行高效部署和推理。
参考
[1].CAS-ViT: Convolutional Additive Self-attention Vision Transformers.
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









