






Domain-Agnostic Priors for Semantic Segmentation Under Unsupervised Domain Adaptation and Domain Generalization
在无监督领域适应和领域泛化下的领域不可知先验用于语义分割
作者:Xinyue Huo · Lingxi Xie · Hengtong Hu · Wengang Zhou · Houqiang Li · Qi Tian
摘要
在计算机视觉中,深度神经网络面临的一个重大挑战是调整不同图像领域的不同属性。为了研究这个问题,研究人员一直在调查一个实际的设置,即深度神经网络在标记的源领域上训练,然后转移到未标记的或甚至看不见的目标领域。主要困难在于潜在的领域差距,这本质上是由于在源领域的过拟合。因此,引入泛化先验以缓解这个问题是重要的。从这个角度来看,本文提出了一个新颖的框架,强制视觉特征与领域不可知先验(DAP)对齐。具体来说,我们研究了两种先验,(i)语言引导的嵌入和(ii)类级关系,我们认为可以构建更多这样的先验。我们的框架,称为DAP,在目标领域未标记甚至看不见的无监督领域适应(UDA)和领域泛化(DG)上进行了评估。我们在合成数据集(即GTAv和SYNTHIA)和真实数据集(即Cityscapes)上执行转移语义分割的标准基准。实验验证了DAP在所有任务中的有效性,具有竞争性的准确性。特别是,语言引导的先验在UDA中工作得足够好,而类级先验作为DG的有用补充。提出的框架为领域转移提供了启示,即从其他模态中获得的更好代理可能是有益的。
关键词
无监督领域适应 · 领域泛化 · 语义分割 · 领域不可知先验
1. 引言
近年来,计算机视觉中的数据分析方法迅速发展。大规模注释图像数据集使得可以训练用于各种任务的深度神经网络。然而,数据注释的高成本限制了它们的应用,特别是在像语义分割这样的密集预测任务中。当从标记的源领域转移到未标记或未知的目标领域时,现有的领域差距经常导致准确性显著下降。因此,增强模型在不同领域间的可转移性已成为计算机视觉社区的一个重要点。在本文中,我们专注于两个经典的迁移学习任务,即无监督领域适应(UDA)和领域泛化(DG),用于语义分割。这两项任务都假设模型将从源领域的语义监督中学习,并能够将知识转移到任何目标领域。不同地,UDA假设目标领域上有图像数据(无标签),但DG假设目标领域完全未知,即仅在测试阶段可用图像。上述设置在现实世界应用中非常有用,特别是本文研究了一个实际场景,其中源领域涉及具有免费标签的合成数据,目标领域包含真实数据,其中人类注释是昂贵的,摆脱这些可以节省很多成本。UDA和DG的主要挑战来自于潜在的领域差距,即源和目标领域的数据分布非常不同,因此训练的深度神经网络可能在源领域上过拟合。我们认为,这种现象比分类更重地导致了语义分割的不准确性,因为分割通常依赖于区分相似对象(例如,自行车与摩托车,道路与人行道等),但当它们之间的微妙差异被不可控的领域差距和缺乏注释所淹没时,这些相似对象很容易被混淆。

我们在图1中展示了一个典型的例子。在本文中,我们提倡引入可以很好地跨领域泛化的先验的重要性。我们的解决方案是提取一组领域不可知先验(DAP),作为视觉特征学习过程中的软约束。DAP可以以不同的形式出现,我们研究了两个方面,即(i)每个类的预训练语言模型生成的高维嵌入向量和(ii)类级关系。我们期望这样的先验不受视觉领域的影响(例如,无论图像数据是合成的还是真实的),因此纳入它们的深度学习模型不太可能在源领域上过拟合。以下,我们详细阐述了如何将DAP应用于UDA和DG场景。一个简单的插图如图2所示。对于UDA分割任务,我们基于一个名为DACS(Tranheden等人,2021年)的经典教师-学生框架构建了我们的方法。它应用ClassMix(Olsson等人,2021年)混合源和目标数据,以便可以同时使用源和混合数据进行训练,以减轻领域差距。对于每个类别,我们定义了一个由预训练语言模型产生的固定和高维嵌入向量。这个过程是离线的,并且与训练数据(即领域不可知的)无关。然后,我们根据每张图像的标签图生成这些向量的嵌入图。通过一个只需要大约7%额外训练计算量的辅助模块,将图像特征强制与嵌入图对齐。研究了两种类型的领域不可知嵌入,即one-hot向量和word2vec特征(Mikolov等人,2013年)。这两种都在迁移学习过程中都显示出了改进。对于DG分割任务,没有目标数据可访问。我们在RobustNet(Choi等人,2021年)上实现了我们的算法,其中实例选择性白化(ISW)用于规范化浅层特征。
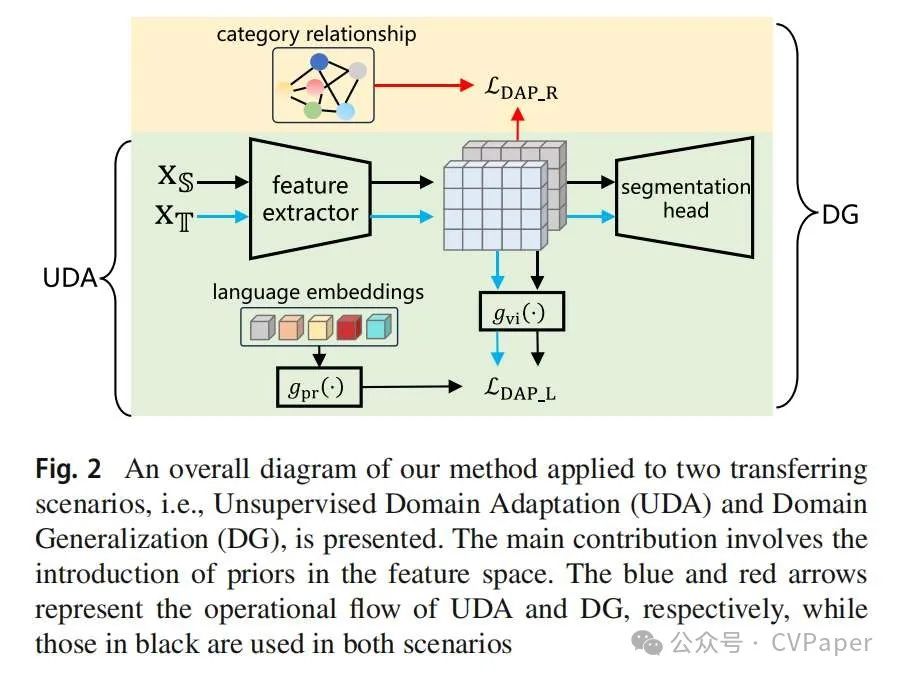
对于深层特征,我们设计了两个领域不可知的先验规则来规范化它们。一方面,我们强制网络使用交叉熵损失将图像特征与同一类别的先验向量对齐。另一方面,我们通过计算每个类别的平均特征之间的余弦相似性来建立类级关系。这种关系被强制在当前批次和整个数据集中保持一致。使用KL散度损失函数来衡量差异。这两种先验,一个显式的和一个隐式的,都在转移到看不见的目标领域时有效地转移了有用的知识。为了验证我们方法的有效性,我们进行了跨合成图像数据和真实图像数据的转移实验。对于UDA,我们将GTAv和SYNTHIA(源领域)转移到Cityscapes(目标领域)。我们的方法报告了令人满意的分割准确性,mIoU分数分别为59.8%和64.3%。当DAP建立在更强大的变换器骨干上时,结果提高到69.0%和61.9%。对于DG,我们首先将从GTAv学到的知识转移到(完全看不见的)Cityscapes,并在相反的方向(从Cityscapes到GTAv)进行转移。其他数据集,包括BDD100K,Mapillary和SYNTHIA,直接用作测试集。无论使用哪种源数据,我们的方法都比ISW和其他基线表现出更高的平均准确性。所有上述结果表明,用领域不可知先验对特征进行规范化可以有效地训练预期在各种领域之间转移的深度神经网络。DAP先前作为会议论文(Huo等人,2022年)发表,在其中我们分析了语义相似类别之间的混淆问题,并验证了用于UDA分割的语言模型提取的先验的有效性。
在这个扩展版本中,我们观察到这种混淆也存在于另一个代表性的转移任务中,即DG分割。在这个场景中,我们在特征空间中对这些类别进行了统计比较,并提出了一个新的框架,引入了两种类型的先验来减轻这种混淆。不仅包括来自预训练语言模型的先验,还包括来自类别关系的隐式先验。根据DG任务的特定性,我们在输入数据中添加了一个简单但有效的增强操作,以弥补缺少的目标数据。具体来说,我们将随机值乘以频域数据的低频部分。这种增强操作在消融研究中可以发现显著提高了两种先验的能力。除了在DG中的扩展之外,我们还在更强大的基线上改进了UDA结果,并设计了一个更受限制的投影结构,以便在网络显示出高能力拟合数据时将先验信息纳入视觉训练。总之,我们为更难的转移任务引入了更多的丰富先验,并在合成数据和真实数据之间的转移中取得了优异的性能。总之,这项工作的主要贡献在于提出和实现了领域不可知先验(DAP),以协助领域转移(无论是UDA还是DG)分割。我们研究了两个例子,包括显式的语言引导先验和基于关系的隐式先验,后者在目标数据完全看不见时是一个很好的补充。作者的工作为使用更复杂的先验和/或更有效的约束预计在未来将被探索指明了道路。
3 我们的方法
在本节中,我们引入了领域不可知先验来规范UDA和DG分割中深层的特征。鉴于DG任务的特殊性,新框架还从输入层面实施以协助特征层面的学习。我们将首先在第3.1节中描述这两个任务的设置。随后,在第3.2节中讨论在转移过程中语义相似类别之间的混淆问题。最后,领域不可知先验(DAP)的框架分别在第3.4和3.5节中说明UDA和DG的语义分割。
3.1 问题设置
无监督领域适应(UDA)涉及两个领域,每个领域都有不同的数据分布。源领域,表示为S,带有像素级注释,而目标领域,用T表示,缺少任何标签。我们假设S和T中的类别集是相同的。与S相关的训练集表示为DS = {(xS n, yS n)}N n=1,其中xS n表示高分辨率图像,yS n提供相应的像素级语义标签。数据集T,没有真实的标签,表示为DT = {(xT m)}M m=1。UDA的最终目标是利用DS和DT训练一个模型,使其在看不见的测试集T上表现出色,表示为DT。对于领域泛化(DG),我们仅在训练期间访问带有像素级标签的源领域图像,表示为DS = {(xS n, yS n)}N n=1。训练好的模型在几个目标领域上进行评估,这些目标领域共享一个共同的类别空间。这些目标领域数据用DT = {DT, j}J j=1表示,其中J是目标领域的数量。DG任务的目标是提取更基本和泛化的语义信息,而不是将学到的分布适应于特定的目标。模型的转移能力体现在其在多个目标上的平均准确性上。
3.2 语义相似类别的混淆
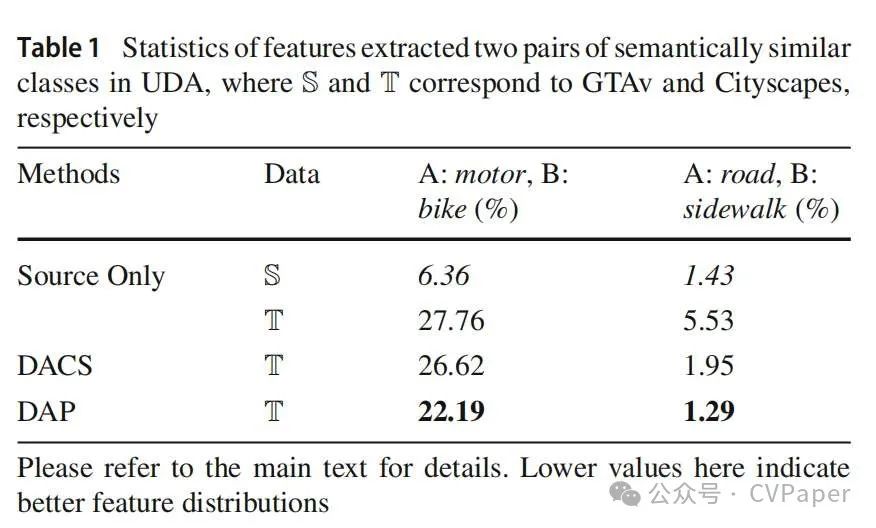
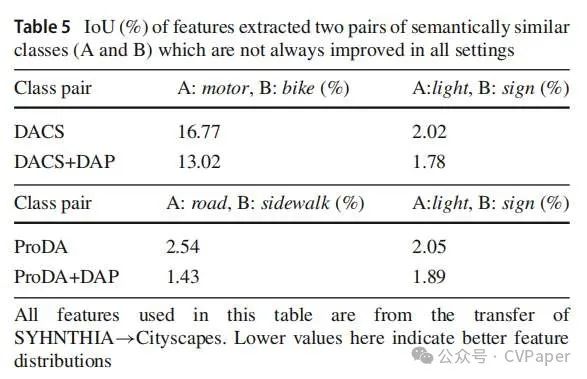
尽管已经提出了许多方法来增强转移稳定性,但在语义相似类别之间仍然出现了显著的误判。当这些类别在数据集中占比较少的分数时,这个问题变得尤为突出;例如,在整个数据集中,摩托车类别的像素仅占0.1%。随后,我们对DACS(Tranheden等人,2021)的结果进行了进一步分析,DACS是最近提出的一种代表性UDA方法。图1中的一个示例图展示了摩托车和自行车类别经常被误识别为彼此。类似的混淆也出现在道路和人行道之间。根据DACS的预测,自行车类别中有显著的20.8%被错误地分类为摩托车。这种混淆显著削弱了转移的可靠性。考虑到观察到的现象,我们提供以下分析:由于无法直接利用目标域图像xT m的真值监督,将这些图像映射到源域可以促进它们语义对应关系的 learning。图像级转移技术,例如基于GAN的方法(Zhu等人,2017;Hoffman等人,2018),以及标签级模拟,如classmix和cutmix,本质上将xT m视为源图像。这种训练方法类似于学习一个将目标域特征投影到源空间的转移函数,目标域数据以弱监督的方式进行训练。因此,目标图像的视觉表示以近似和估计的方式获得,这可能会引入错误。除了上述假设之外,我们还进行了更直观、定量的特征比较。首先,我们提取了两个语义相似类别A和B的最后一层特征。这些特征集分别表示为F·A和F·B,上标代表它们来自哪个域,例如S或T。然后,对于每个特征集,我们计算均值向量μ和协方差矩阵Σ。从多元高斯分布N(μ·, Σ·)中,采样一组点P,可以从点PA和点PB之间的重叠中直观地看出类别之间的混淆程度。为了更定量地测量,我们计算rA作为来自PA的一个点在N·B中具有更高密度的概率,以及rB在相反情况下的概率。这两个分布之间的重叠可以表示为IoU值,计算公式为(rA + rB) / (2 - rA - rB)。在源域中,模型通过将它们的分布分开,有效地区分了A和B,解决了混淆问题。在目标域中,由于缺乏强大的监督,导致N T A和N T B之间的距离减小。这导致这两个分布保持交织在一起,即导致它们之间的IoU变大。UDA模型在GTAv→Cityscapes转移上的详细定量结果如表1所示。在语义相似的类别对中,如摩托车与自行车以及道路与人行道之间,混淆很明显。同样,我们从表2中突出了两个从GTAv训练的DG模型的例子:道路与人行道和人与骑手。值得注意的是,当ISW(后来引入的DG基线方法)和我们的技术依次加入时,相似类别的IoU逐渐减少。

3.3 领域不可知先验减轻混淆
上述混淆本质上是源域过拟合的一种形式。因此,它需要一种特征规范化方法来减轻过拟合。在本文中,我们提供了一个简单有效的解决方案,通过引入与特定域无关的先验。我们知道,从贝叶斯理论中,后验分布,即最终估计P(e | D)与先验P(e)和似然P(D | e)成正比:
其中e是先验的嵌入,P(D | e)代表D在e条件下的分布。同时,NA和NB作为两类分布的近似值,可以表示后验估计的准确性。对于源域,e可以从真值中获得,使得后验分布自然准确。然而,在缺乏标签的目标域中,现有的UDA算法(例如,DACS(Tranheden等人,2021)和DAFormer(Hoyer等人,2022))直接使用源域的e,这可能容易加剧过拟合。为了获得更准确的NT A和N T B的估计,我们提出从先验视图优化后验分布。因此,额外的先验信息被引入到每个类别的特征空间中,并被表示为zT A ∼ NT A和zT B ∼ NT B。我们规定这些信息与任何特定域无关,即从领域不可知先验(DAP)eA和eB映射而来。我们如下表示它们:
其中g(·)是一个可学习的块,将先验对齐到图像特征空间。在实践中,直接提供严格的先验补充像方程(2)一样困难,所以我们将其定义为要最小化的损失项。以下,我们将介绍如何在UDA和DG的两种情况下定义领域不可知先验损失项。
3.4 案例1:UDA分割
3.4.1 基线
UDA主要处理源S和目标T域之间的领域差距。在分割任务中,城市街景作为实验场景。在这里,合成数据(Richter等人,2016;Ros等人,2016)被指定为S,而真实世界数据(Cordts等人,2016)被认为是T。它们之间的领域差距可以通过照明、颜色和风格等直观地观察到。这些差异经常阻碍模型对目标域进行准确预测。减轻这种领域差距的方法之一是自训练,它已得到广泛应用。具体来说,它涉及为xT m生成伪标签ˆyT m,并通常基于平均教师模型(Tarvainen和Valpola,2017)。采用这种策略,DS和扩展的目标集,ˆDT = {(xT m, ˆyT m)}M m=1,都被用来训练在线学生模型f st(x; θst)。同时,教师模型f te(x; θte)通过f st(·)的移动平均值进行更新。生成的ˆyT m的质量在自训练机制中非常重要。为了提高ˆyT m的可靠性,DACS(Tranheden等人,2021)用混合域M的混合输入替换了目标图像。每个混合数据样本被合成为源和目标数据的复合体,由ClassMix(Olsson等人,2021)引导。具体来说,采样一对具有相同分辨率的源和目标数据(xS n, yS n, xT m),在每次迭代中预测一个伪标签ˆyT m。然后,选择一个包含yS n中一半类别的随机子集,并生成一个与xS n一样大的像素级二进制掩码Mn,m。在这个掩码中,如果它们对应的类别属于选定的子集,则将像素分配值为1,否则为0。生成此掩码后,制作混合图像及其标签:
其中⊙表示逐元素乘法。然后DACS训练学生模型f st(x; θst)在(xS n, yS n)和(xM n,m, yM n,m)上。分割损失总结如下:
θθ
其中LCE(·, ·)表示逐像素的交叉熵损失。并且在每次迭代中,教师模型f te(x; θte)通过指数移动平均(EMA)机制更新,即θte ← θte ·η+θst ·(1−η)。η是一个接近1.0的常数,控制更新速度。图3中的黄色阴影部分是DACS的整个流程图。
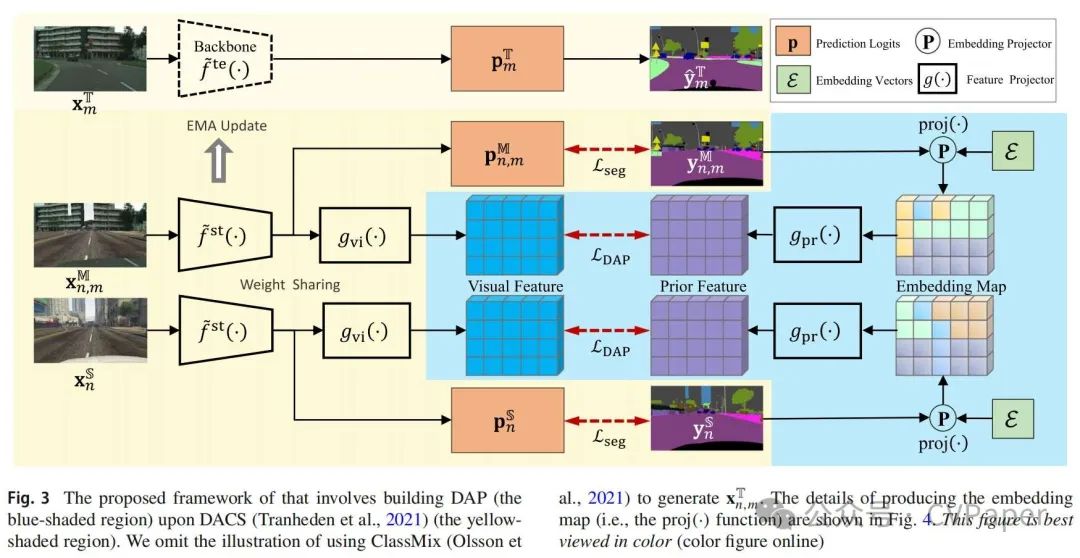
3.4.2 来自语言引导嵌入的先验
应该强调的是,DAP与类别的语义有关,与两个域的数据无关。因此,我们在UDA任务中以两个例子为例说明DAP:即one-hot向量和word2vec嵌入(Mikolov等人,2013)。前者涉及一组C维向量,每个向量对应一个类别。第c类向量Ic中的条目被编码为1,其他为0。这种形式的先验嵌入存在于一个正交空间,不解释任何类关系。后者类型的DAP使用来自预训练语言模型的向量,为每个类别名称提供300维向量。这组嵌入向量表示为E = {ec}C c=1,其中ec是第c类的嵌入向量。在DACS基线的基础上,很容易实现DAP损失项LDAP在特征层面。通过优化这个损失项,我们促进了从源和混合域图像提取的视觉特征与嵌入的领域不可知先验的对齐。LDAP定义如下:
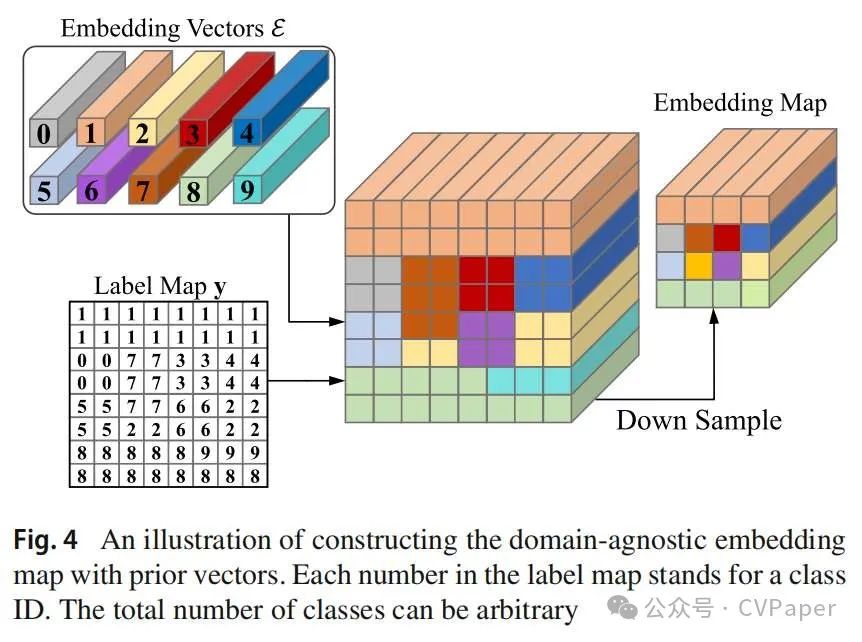
θθ其中是的特征提取器,输出最后一层视觉特征,根据相应的标签将领域不可知嵌入向量映射到图像平面上,随后构建先验嵌入图,稍后将详细说明。而和是可学习的层,将视觉特征和先验嵌入图投影到一个共享空间中。在这个空间中,先验信息可以用来规范视觉特征的学习。的详细过程在图中描述。当提供真实标签或部分伪标签时,我们将每个位置的类索引替换为其对应的先验向量。嵌入图具有与标签相同的分辨率,随后被下采样以与主干输出的维度对齐。为了适应硬类别,我们的框架采用了平滑采样技术,其有效性在消融研究中得到了证明。鉴于先验向量是静态的,不需要梯度反向传播。因此,对齐学习过程仅由和促进。在实现组件后,总体损失函数可以正式表示如下:
LUDA = Lseg + α · LDAP,$$其中 α 是一个常数(设为1.0),用于平衡分割损失和先验调节损失的权重。然后我们可以回到表1,发现我们的方法学习了更稳健的NT A和N T B的特征分布。语义相似的类别(无论是道路与人行道还是摩托车与自行车)具有较小的IoU,混淆明显减轻。我们将在实验中展示DAP损失如何提高模型的区分能力。
3.5 案例2:DG分割
3.5.1 基线
DG分割提出了更大的挑战,因为关于目标域的信息很少。其目标是学习基本的语义概念,而不是专注于源数据S的领域特定信息。一个理想的特征 应该即使在引入领域特定因素时也能保持稳定,其中C和HW分别代表通道数和特征大小。一种流行的方法是通过识别和消除特征中嵌入的领域关系来实现。在特征通道的协方差上进行白化已被证明可以有效地减少风格信息(Li等人,2017b)。在实践中,首先通过实例规范化(Ulyanov等人,2016)获得标准化的浅层特征 ,然后使用其协方差矩阵来实现白化损失 :
其中I是C×C大小的单位矩阵,Σ是特征图的协方差矩阵。在这个函数中,每个两个不同通道之间的关系被学习为零,这是不合理和有害的。最近的方法ISW(Choi等人,2021)被提出来选择性地白化对风格变化敏感的特征通道关系。该方法对单个图像应用两次风格转换,以获得特征协方差矩阵 和 。然后基于 和 之间的方差生成掩码 。掩码的元素对于高方差设置为1,否则为0。ISW损失公式如下:
其中 表示逐元素乘法。LISW最小化了领域敏感的协方差,同时尽可能保持模型的潜在能力。除了规范浅层特征外,我们还通过输入和深层特征的修改来增强DG框架,以补偿缺乏目标域。总体训练过程如图5所示,其中分割损失以绿色表示,两种不同的深层特征规范损失分别以红色和蓝色突出显示。注意,在DG任务中,分割损失仅应用于源域。
θ
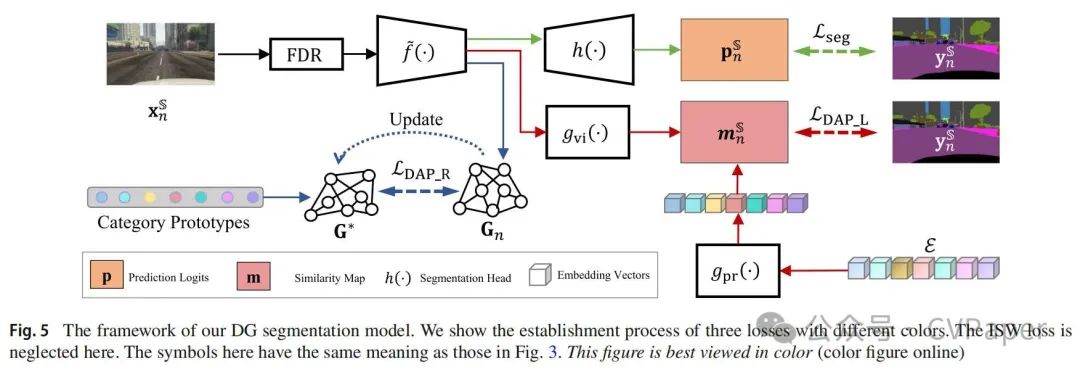
3.5.2 来自语言引导嵌入的先验
众所周知,从深层提取的特征通常捕获更丰富的语义信息(Zeiler和Fergus,2014;Yosinski等人,2015;Girshick等人,2014)。这些特征可以更容易地与抽象类别嵌入对齐。因此,我们在深层特征空间中纳入了一个领域不可知先验。类似地,我们为每个类别提供了一个来自语言模型的先验嵌入ec,并定义了一个DAP损失LDAP_L来对齐视觉特征和先验嵌入。与UDA不同,我们不是直接最小化两个特征图之间的距离,而是计算视觉特征与所有先验嵌入之间的相似性,可以将其视为类别级别的预测概率。这个DAP损失项LDAP_L在DG中可以这样表述:
θ
其中 和 是可学习的层,将视觉和先验特征投影到一个共同的空间中,×表示矩阵乘法。这里省略了softmax操作。
3.5.3 来自类级关系的先验
LDAP_L以一种直接的方式引入了来自其他模态模型的先验信息。具体来说,这些先验向量集成了语义和类别关系的表示,这在转移过程中直接学习。从另一个角度来看,我们知道这些类别从语义角度有一个相当固定的关系到无论图像的风格和布局如何。例如,骑手类别在语义上与自行车或摩托车类别有着内在的联系。同样,交通标志类别与杆类别密切相关。因此,我们引入了另一种特征规范,具有这种隐式先验,并假设模型包含一个稳定的类别图。在这个图中,每个类别作为节点,它们之间的相互关系作为边。我们从其归一化的特征图中获得xS n的类别图Gn。节点代表每个类别中的平均特征,边En ∈ RC×C定义为节点之间的余弦相似性。因此,这些节点Vn也作为类别原型。一个经验图G*最初是随机设置的。我们采用了一个类别关系一致性损失,表示为LDAP_R,来学习跨图像的隐式先验。
其中KL(, )代表KL散度函数,E*_c和En,c分别是G和Gn中类别c与其他类别的相似性,p(·)是softmax操作。V通过Vn在每次迭代中更新,采用EMA范式。
3.5.4 频域随机化增强
在UDA中,目标和源图像都可以通过各种技术进行风格转换,例如低频信息交换(Yang和Soatto,2020)。考虑到缺乏特定的目标风格,我们调整了图像的低级风格以随机方向。在每次迭代中,采样一个图像xS n,并在频域中获得其幅度an和相位ωn,通过傅里叶变换。然后我们对低频分量的an或ωn执行逐元素乘法,与随机矩阵rn相乘。通过具有新的频域值的逆傅里叶变换构建了具有随机风格的新图像xS n'。该过程用以下函数总结:
或ωω
在我们的实验中,xS n和xS n'以固定概率p随机选择作为输入数据,设为0.5。这种数据增强技术,称为频域随机化(FDR),简单但有效,可以丰富数据分布。图6中有两个示例对。我们可以看到,经过频域随机化(FDR)增强后的新图像在颜色、亮度和风格上有更多的变化。因此,我们的DAP框架在DG中集成了FDR在输入层面,ISW在低层特征,以及我们的两个新的先验损失在深层特征。这些组件共同构成了最终的损失函数,其中γ和λ作为超参数,平衡两个DAP损失的权重。
γλ
同样,回顾表2,我们发现添加我们的领域不可知先验减少了语义相似类别对(道路与人行道和人与骑手)之间的混淆。这表明我们的DG模型具有更强的泛化能力,混淆的风险较小。

3.6 讨论
如上所述,将文本嵌入集成到领域转移分割是一个有意义和新颖的方向,并带来了相当大的准确性提升,这表明语言线索辅助视觉识别的有效性。然而,将视觉特征与文本嵌入对齐的方法仍然是初步的,这为进一步探索留下了空间。
3.6.1 从语言模型中获取更多信息
Word2vec和CLIP模型都学习了许多语义、属性和逻辑知识,这些并没有在这里被完全探索和使用,因为只有几个类别嵌入被纳入我们的框架。目前使用的word2vec特征没有考虑到对应相同语义的不同单词(例如,人可以是行人)。有趣的是,我们尝试通过寻找语义相似的单词来增强先验,但获得的准确性提升很小。这可能需要一个复杂的机制来探索文本世界。此外,尽管这些类别嵌入是学习的一个确定事项,但来自学习模型的特征可能引入了更全面的表现。特别是对于那些多模态预训练模型,如CLIP(Radford等人,2021年)和ALIGN(Jia等人,2021年),可以作为将知识转移到看不见类别的可行中介。
3.6.2 构建领域不可知但视觉感知的先验
最后,我们讨论了哪种类型的图像数据可以被认为是提供领域自由信息的。为了解决这个问题,人们可能会寻找像ImageNet(Deng等人,2009年)或概念字幕(Sharma等人,2018年)这样的通用数据集。此外,像CLIP(Radford等人,2021年)这样的预训练图像-文本模型,它已经吸收了超过4亿个图像-文本对,可能会提供见解。重要的是要注意,分离领域特定信息以减轻过拟合是一个重大挑战。这是作者打算在未来研究中继续探讨的一个途径。
4 实验设置
4.1 数据集
UDA和DG分割任务在城市场景上进行评估。主要有两种类型的数据集,即合成数据和真实数据。合成数据集包括GTAv(Richter等人,2016年)和SYNTHIA(Ros等人,2016年)。真实世界数据集包括Cityscapes(Cordts等人,2016年)、BDD100K(Yu等人,2020年)和Mapillary(Neuhold等人,2017年)。UDA分割专注于从合成领域转移到真实领域。DG分割在合成和真实之间进行双向转移。
4.1.1 合成数据集
GTAv源自Grand Theft Auto V游戏,场景是合成的。该数据集包含24,966张图像,每张图像都有像素级语义分割真值。数据集被划分为12,403、6,382和6,181张图像,分别用于训练、验证和测试集。在UDA的背景下,整个数据集用于训练。GTAv与Cityscapes共享19个常见类别。SYNTHIA是另一个广泛的分割数据集,具有像素级注释。具体来说,我们使用它的SYNTHIA-RAND-CITYSCAPES子集,包含9,400张虚拟欧洲风格城市图像,分辨率为1280×760。对于SYNTHIA,我们在UDA中评估了两种设置(13和16个类别)和DG中的一个设置(19个类别)。
4.1.2 真实世界数据集
Cityscapes是一个大规模数据集,分辨率为2048×1024,来自德国主要城市的50个不同城市。训练和验证集分别有2,975和500张精细注释图像。BDD100K是第二个真实世界城市场景数据集,包含7,000张训练图像和1,000张验证图像。这些图像的分辨率为1280×720,收集自美国的某些地点。最后一个,Mapillary,是一个高分辨率和多样化的城市驾驶数据集,包含25,000张图像,其注释包含66个对象类别(其中19个类别与其他类别重叠并被评估)。
4.2 实施细节
4.2.1 UDA细节
我们采用实验设置,这些设置通常在先前工作中使用,以确保公平比较。我们的网络使用Deeplabv2(Chen等人,2017年)框架和ResNet101(He等人,2016年)作为图像编码器的主干。ASPP分类器用于分割头部,1×1卷积层用作视觉和先验元素的特征投影器,分别表示为 和 。这些投影器调整视觉特征和先验嵌入图的通道至256。主干通过在ImageNet(Deng等人,2009年)和MSCOCO(Lin等人,2014年)上的预训练模型进行初始化,其他层随机初始化。输出图被上采样并通过softmax层操作,以与输入尺寸对齐。按照DACS(Tranheden等人,2021)的后续操作,我们将批量大小设置为2个GPU,并使用SGD具有Nesterov加速作为优化器,其基于多项式衰减策略,指数为0.9。特征提取器和特征投影器的初始学习率分别为 和 。优化器的动量和权重衰减分别设置为0.9和 。在训练期间,我们将GTAv和Cityscapes中的图像调整为1280×720和1024×512,并保持SYNTHIA的原始分辨率。调整大小后,这些图像被随机裁剪为512×512。我们还在混合数据上应用额外的颜色抖动和高斯模糊。教师模型以EMA衰减系数 η 0.99更新。我们将总训练迭代次数设置为250K,LDAP的权重 α 设置为1.0。我们在单个NVIDIA Tesla-V100 GPU上训练所有实验,并采用早停设置。双线性插值作为proj(·)的下采样操作,在DAP中至关重要,相关的消融研究在第5.2节中详细说明。
4.2.2 DG细节
为了与我们的基线方法(Choi等人,2021)保持一致,我们采用DeepLabV3+分割框架(Chen等人,2018年),使用各种主干,包括ResNet50(He等人,2016年)、ShuffleNetV2(Ma等人,2018年)和MobileNetV2(Sandler等人,2018年)。在前三个卷积组后添加了三个实例规范化层,ISW损失在这里应用。视觉和先验特征投影器,表示为 和 ,被实现为具有1×1内核的卷积层,输出通道大小为256。预训练的ImageNet(Deng等人,2009年)模型应用于初始化主干。归一化的CLIP嵌入被用作先验向量。我们使用SGD优化器,初始学习率为0.02,动量为0.9,权重衰减为 。多项式学习率调度,指数为0.9,也被采用。我们在Cityscapes上训练了60K次迭代的ResNet50和ShuffleNetV2主干模型,其他模型为40K次迭代。我们在训练期间对图像应用颜色抖动、高斯模糊、随机裁剪、随机水平翻转和随机缩放,范围为[0.5, 2.0]。进行频域随机化增强的概率 设置为0.5。应用于幅度和相位的概率相等。LDAP_L和LDAP_R的权重,即 γ 和 λ,分别设置为1和2。随机矩阵 的范围为[0.5, 1.5]用于幅度,[-1.5, 1.5]用于相位。最后一个输入到分类器的特征是低级特征和高级特征的连接。我们的LDAP_L和LDAP_R应用于最后的连接。类别图 的节点 在开始时随机初始化并归一化,并在每次迭代中以EMA衰减更新,其系数等于0.99。在每次迭代中,只有出现在输入图像中的类别被包括在LDAP_R中,并在 中更新。
5 UDA结果
5.1 定量结果和可视化
5.1.1 与其他方法的比较
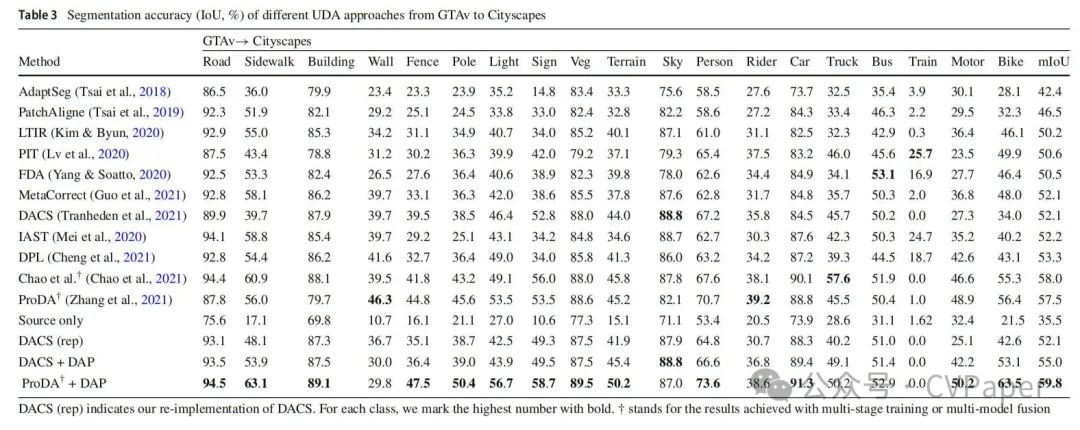
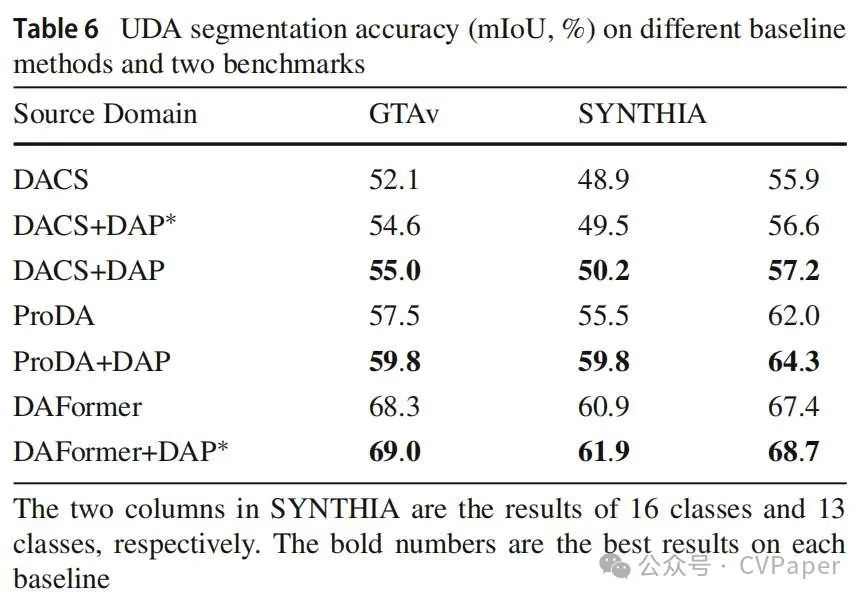
为了评估DAP,我们首先在GTAv→Cityscapes上进行了实验,结果总结在表3中。我们对提出的DAP和基线DACS进行了三次实验,并报告了平均准确性以确保可靠性。我们可以观察到DAP在19个类别上实现了55.0%的mIoU,比基线提高了2.9%。此外,它在所有其他比较方法中都表现最好,除了Chao等人(2021年)和ProDA Zhang等人(2021年)。这里,Chao等人(2021年)整合了包括DACS在内的四个互补模型的结果,以获得集成预测,而DAP使用单一模型;ProDA(Zhang等人,2021年)进行了多阶段训练,以获得显著提高的分割准确性,其在第一阶段的mIoU为53.7%。同样,如表4所示,在SYNTHIA→Cityscapes任务中,结果也显示出这种趋势,即DAP在13或16个类别的mIoU方面超过了所有竞争对手,除了ProDA和Chao等人(Chao等人,2021年)。为了展示DAP可以带来互补的好处,我们也使用DAP的输出作为ProDA第一阶段的伪标签,并保持第二和第三阶段不变。表3和表4显示,它在GTAv→Cityscapes上实现了2.3%的mIoU提升,在SYNTHIA→Cityscapes上实现了4.3%的提升,将性能提升到了新的高度。
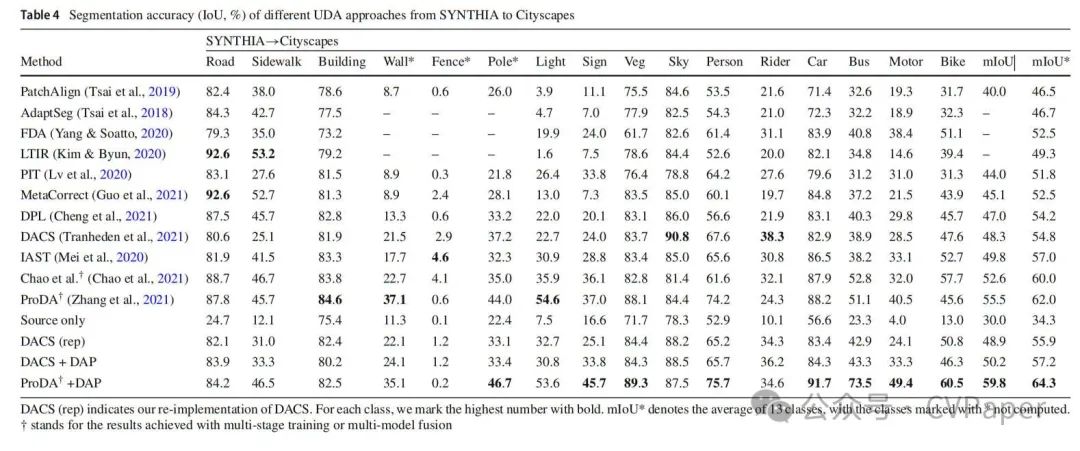
5.1.2 DAP改善语义相似类别
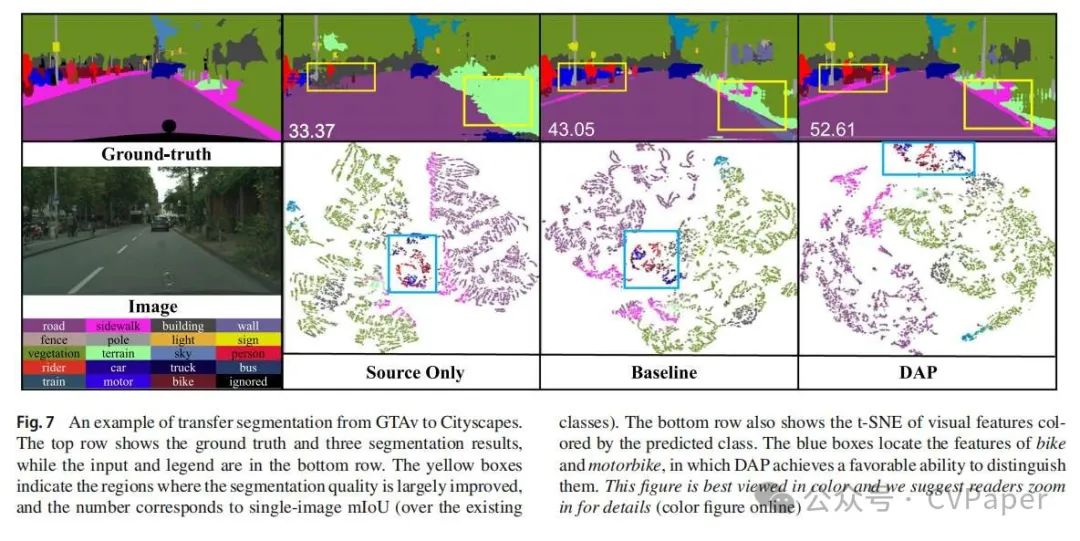
我们可以观察到,将模型从GTAv转移到Cityscapes在分割IoU上取得了显著的改进:自行车从42.6%增加到53.1%,而摩托车从25.1%上升到42.2%,绝对增益分别为10.5%和17.1%。在SYNTHIA上训练的模型报告摩托车增加了9.2%,自行车减少了4.5%,平均改进了2.4%。我们注意到DAP并不总是在混淆对的两边都有所改进。例如,在SYNTHIA→Cityscapes中,道路、自行车和灯的分割mIoUs低于基线。这可以归因于这些类别的IoUs受到其他类别以及基线方法性能的影响。在模糊位置进行预测时,通常需要在相似类别之间进行权衡。领域不可知先验引入的扰动打破了原始的平衡,导致整体改进。为了揭示这一点,我们观察了这些类别对在表5中的特征重叠,并发现DAP一致地减少了重叠。为了更直观的比较,我们展示了一个改进区分自行车和摩托车以及道路和人行道的例子在图7中。随着这些定性的分割结果,特征分布揭示了模型如何区分这些相似的类别。在DAP中,相似对(例如自行车和摩托车)的特征具有更清晰的边界。这一观察与表1中的统计数据一致,表明DAP有效地缩小了自行车和摩托车以及道路和人行道的估计分布之间的IoU。
5.1.3 基于语言的先验辅助视觉识别
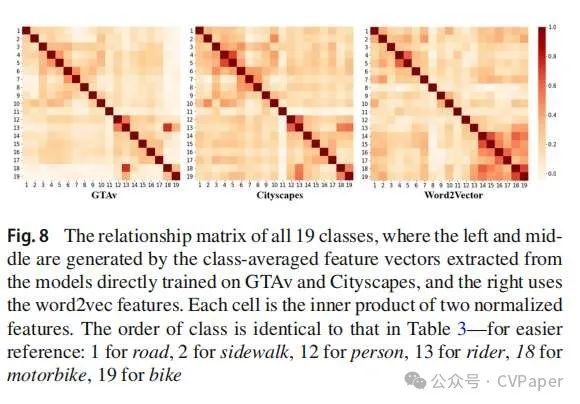
从另一个角度来看,我们研究了这种先验如何提高模型的转移能力。我们从直接在GTAv(源域)和Cityscapes(目标域)上以监督方式训练的两个模型中提取特征。这些视觉特征以及word2vec特征的关系矩阵在图8中描绘。一个有趣的观察是,尽管人和骑手在视觉上相似,导致分割混淆,但它们的word2vec特征并没有那么相关。这种降低的相关性减少了偏见,并提高了两个类别的IoU,如表3所示。word2vec特征分布与视觉特征的分布紧密对齐,证实了这种先验的合理性。
5.1.4 在更强基线上的DAP
除了在卷积主干(ResNet101)上的一般比较外,我们还使用了一个变换器编码器(ViT-Base(Dosovitskiy等人,2020年))进行验证。配置了12个块层,一个768大小的令牌和12个头,编码器用预训练的ImageNet21k模型初始化。我们随机裁剪输入数据并将其调整为768×768。我们使用SGD,基础学习率为0.01和poly衰减。我们采用了一个单层变换器结构作为gpr和gvi。LDAP的权重设置为0.25。在GTAv→Cityscapes实验中,源仅、DACS和DAP报告了分别为49.4%、58.4%和61.1%的mIoUs。对于SYNTHIA→Cityscapes,三种方法在评估16个类别时实现了42.7%、53.2%和59.1%的mIoUs,在评估13个类别时实现了48.1%、60.9%和66.1%的mIoUs。我们的DAP方法仍然保持一致的改进,这证实了DAP在不同主干上的稳定性。我们还直接将当前的DAP损失应用于DAFormer(Hoyer等人,2022年),这是一个更强大的基于变换器的模型,配置了名为Rare Class Sampling(RCS)的类别平衡策略和在特征空间中的thing-class约束。然而,几乎没有改进,因为其强大的拟合数据能力,这个L2损失迅速下降到零,这意味着最优崩溃。因此,我们设计了一个更受限制的对齐结构,如图9所示。
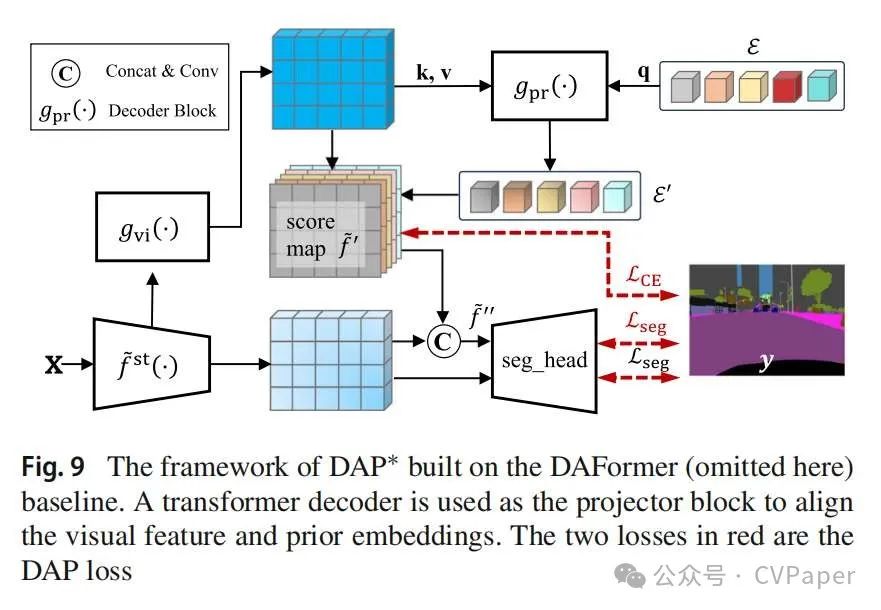
首先,我们使用一个变换器解码器块,与交叉注意力和前馈层一致,将先验嵌入E投影到一组新的嵌入E'中,其中包含了从视觉特征gvi( \tilde{f} )投影的信息。然后我们用gvi( \tilde{f} )和E'计算得分图 \tilde{f}':\tilde{f}' = gvi( \tilde{f} ) × E'^T 。按照DenseCLIP(Rao等人,2022年)的设计, \tilde{f}和 \tilde{f}'被联系在一起,并通过一个1×1卷积层投影到一个与 \tilde{f}相同通道数的新特征 \tilde{f}'' 。\tilde{f}''将输入到分割头部,并计算为分割损失。最终损失由三部分组成:
β
其中β是一个常数(设为0.5)。·在Lseg(·)中表示从哪个特征获得预测结果。与原始结构相比,这种设置从特征空间和最终预测结果中对齐了先验信息。在表6中,我们可以看到LDAP将强大的基线从68.3%提高到69.0%,在GTAv→Cityscapes上。对于SYNTHIA→Cityscapes,DAP在16个类别上实现了1.0%的提升,在13个类别上实现了1.3%的提升。当我们将新结构,即LDAP*,应用于DACS时,仍然有比基线更好的趋势,但比原始的DAP稍低。我们认为DACS框架的特征空间适合较弱的约束。
5.2 诊断研究
5.2.1 不同类型的领域不可知先验
为了研究先验如何影响转移效果,我们在相同设置下列出了四个其他选项,以替代word2vec嵌入(Mikolov等人,2013)。第一种是一组标准化的随机向量,长度为300,每个向量对应一个类别。第二组使用一个19维的one-hot向量来表示每个类。第三组采用CLIP(Radford等人,2021年)语言模型,该模型可以为每个类名生成一个512维的嵌入。最后一组是OpenAI 1文本嵌入,维度为1536。我们对这些实验进行了三次,并展示了平均值。详细的结果在表7中提供。首先,我们的实验揭示了随机向量在GTAv到Cityscapes的转移中略微提高了基线0.2%,但在SYNTHIA作为源数据时降低了0.9%。随机向量没有先验知识,这意味着无法满足的调节不能保证为不同域的特征学习一个合理的空间。值得注意的是,使用随机向量的三次运行的标准差超过了其他方法。例如,在GTAv→Cityscapes上,最佳运行达到了54.4%的mIoU,仅比word2vec低0.6%,而最差的运行下降到49.2%,显著低于基线。当使用one-hot向量时,这两种设置(从GTAv或SYNTHIA转移)都取得了一致的0.9%的改进,并且三次运行的波动性远小于随机先验。因此,使用one-hot向量可以被视为特征空间中的辅助分类器,稳定了模型的性能。第三组先验来自CLIP(Radford等人,2021年)语言模型,使用ViT-B/32主干,将结果提高到54.6%的mIoUs在GTAv→Cityscapes和50.6%的mIoUs在SYNTHIA→Cityscapes。众所周知CLIP是一个更强大、更视觉友好的模型,但结果仅与word2vec(55.0%和50.2%)相当。同样,我们测试了更先进的OpenAI嵌入,但没有显著改进。它将GTAv实验提高了1.1%,但在SYNTHIA场景中降低了基线。这里使用的19个嵌入之间的余弦相似性在0.77和1.0之间,表明直接使用这些关系不是最优的。根据这些结果,我们得出以下考虑:(1)先验的质量在特征空间的调节中非常重要。(2)即使是一个简单的先验也可以减轻由领域转移引起的语义混淆。(3)如果先验包含不同领域之间的一般类别关系,它可以帮助模型意识到语义相似的类别。文本嵌入是实现这一目标的安全有效选择。(4)在这次转移中只有不到20个类别,这些类别在城市场景中是有限的。因此,像CLIP这样的先进先验的全部潜力还没有被充分利用。同时,我们继续探索视觉感知但领域不可知的嵌入方法。

5.2.2 特征插值的重要性
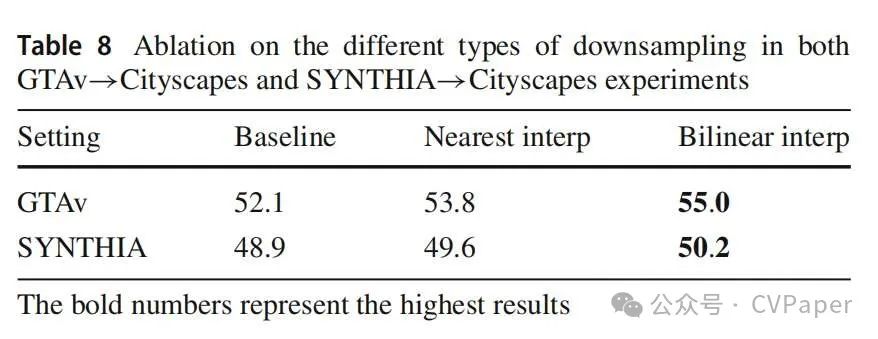
如前所述,proj(·)负责调整先验图的分辨率以与视觉特征对齐。为了探讨这一点,我们在表8中展示了使用不同下采样方法的DAP模型的性能指标。在两种转移场景中,双线性插值优于最近邻下采样,并且在DAP对DACS(Tranheden等人,2021)的改进中占了近一半的准确性提升。直观地看,双线性插值更适合小面积类别,即使在较低分辨率下也能保留它们的学习特征,而最近邻下采样往往会忽略它们。
5.2.3 不同投影结构
函数 和 表示两个关键的可学习层,用于对齐视觉特征和先验嵌入。在表9中,我们检查了这两个模块的不同配置。显然,仅使用一个1×1卷积层对齐这两种类型的特征导致mIoU从55.0%下降到50.5%。鉴于视觉特征和文本嵌入来自不同模态,它们需要更严格的对齐机制。为了解决这个问题,我们保持 不变,同时为 测试了三种独特的架构设计。这些设计中的每一个都提高了基线性能,当使用1×1卷积层时,观察到最佳性能。

5.2.4 参数分析
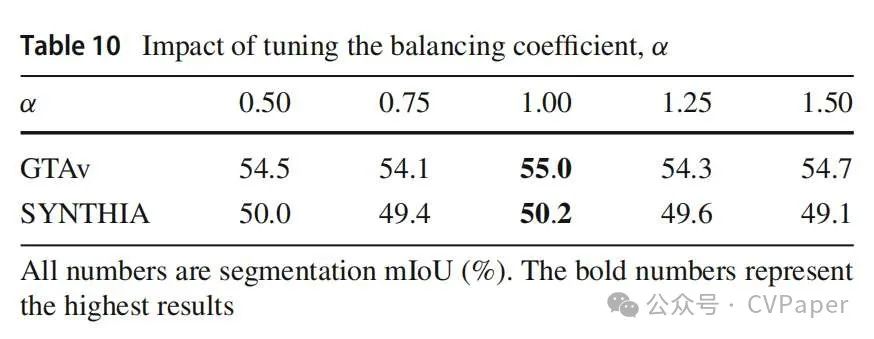
最后,我们研究了平衡 和 之间权重的系数 α 的影响。表10中的结果显示 α 是最佳选项。此外,增加 α 导致的准确性下降比减少它更大,这可能表明 是基本目标,而 作为辅助项。
6 DG结果
6.1 与其他DG方法的比较
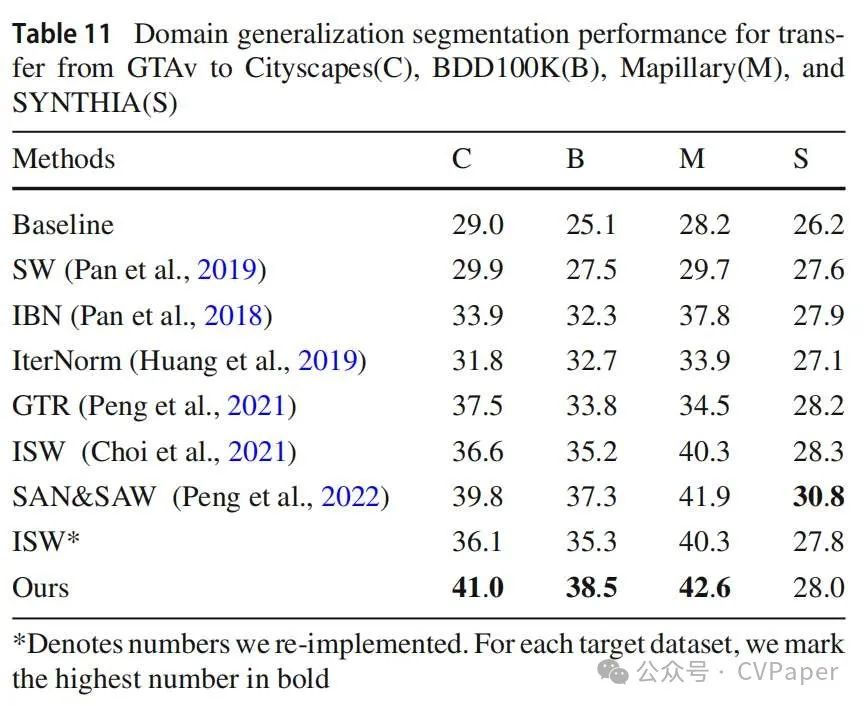
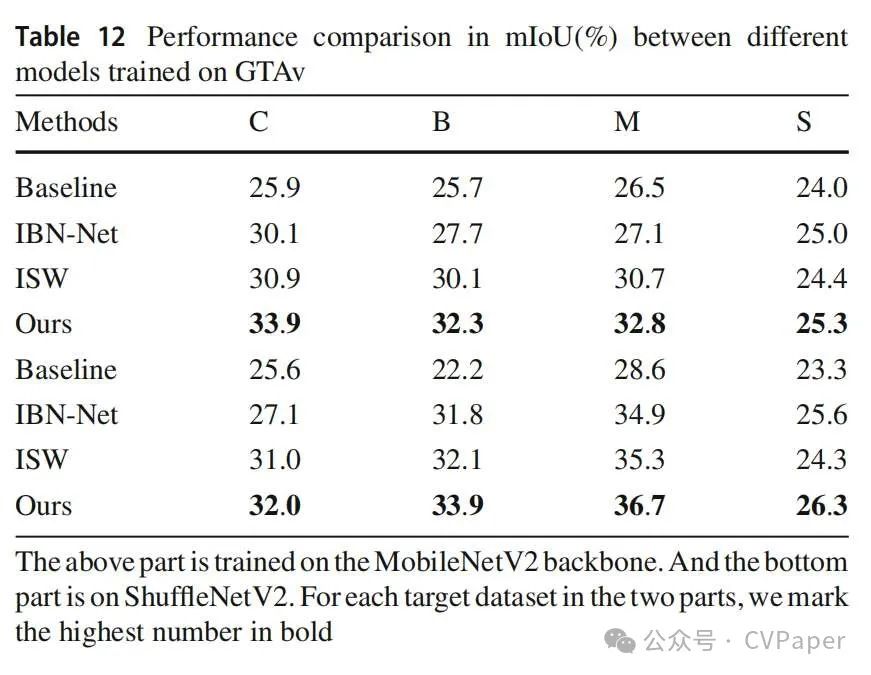
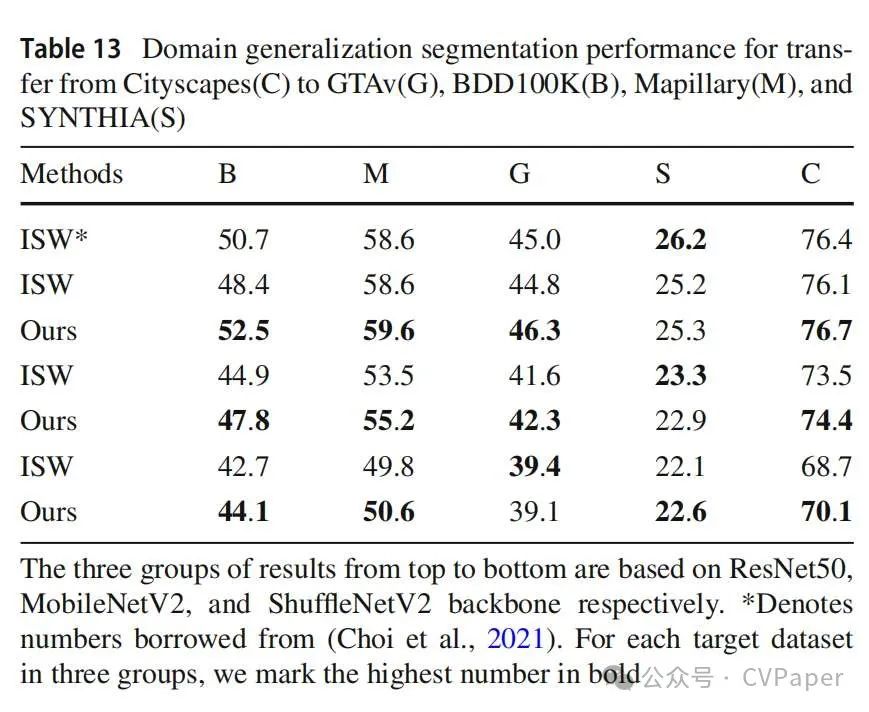
首先,我们在GTAv数据集上进行实验,并与其他最近的领域泛化方法进行比较。在表11中,我们列出了在四个目标数据集上的结果:Cityscapes、BDD100K、Mapillary和SYNTHIA。我们的方法在三个真实世界数据集上都优于其他方法,并比ISW基线分别提高了4.9%、3.2%和2.3%的性能。在SYNTHIA上的结果也与其他方法相当,除了(Peng等人,2022)它有不同的数据分割设置。为了扩大比较,我们还采用了两个额外的主干,MobileNetV2和ShuffleNetV2。表12证实了我们的方法在真实世界和合成数据集上都实现了最高的性能指标。
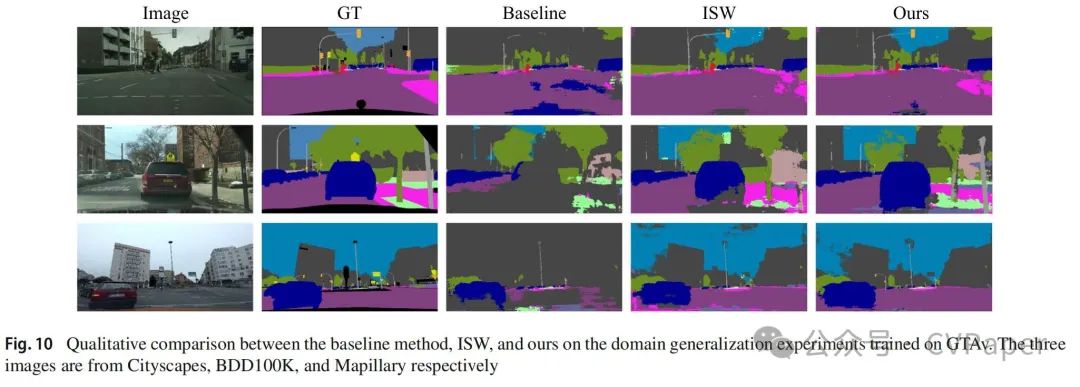
然后我们评估了在真实世界数据集上训练的模型的泛化性能。按照一般设置,Cityscapes被视为源域。我们在表13中列出了三组结果,这些结果是基于不同主干(即ResNet-50、MobileNetV2和ShuffleNetV2)训练的。我们的方法提高了ISW基线的性能,分别提高了1.4%、1.2%和0.6%的平均mIoU。此外,评估在源测试集上的数字也取得了一致的改进。这些结果表明,纳入先验知识使模型能够学习在不同分布中更稳健的特征。接下来,我们分析了对区分语义相似类别的影响。如表14所示,道路和人行道这对类别表现出明显的改进,从64.8%和26.3%分别提高到79.9%和36.6%,绝对增益分别为15.1%和10.3%。这显著地促进了平均IoU的提升。其他像人与骑手、卡车与公共汽车以及自行车与摩托车等类别对也取得了更好的性能。这些结果与表2一致,即特征级别的先验知识规范提供了更大的概率跳出相似性混淆。为了提供更具体的观点,我们在图10中展示了从GTAv训练的转移实验中的定性示例,说明了我们的模型如何纠正混淆错误并细化分割边界。

6.2 诊断研究
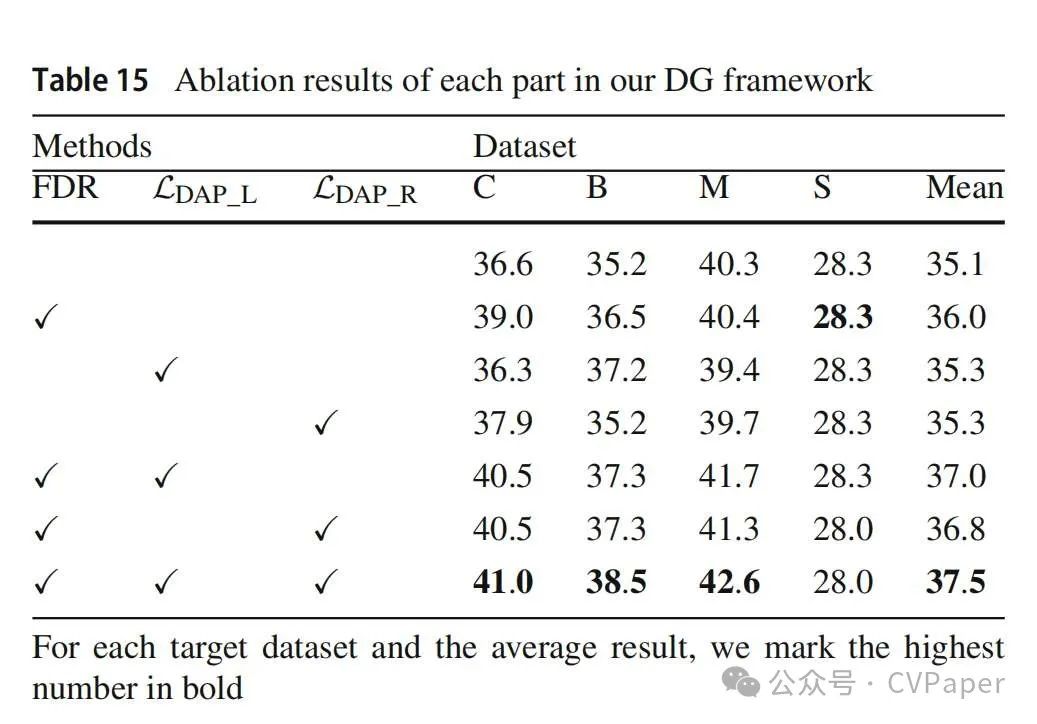
6.2.1 消融研究
我们研究了FDR、LDAP_L和LDAP_R模块对整体性能的个体贡献以及它们如何相互影响。首先,我们分别将它们添加到基线框架(ISW)中。除了FDR之外,其他两个报告的平均mIoU与基线结果接近。不同的目标数据集对它们有不同的响应,例如,这三个模块提高了BDD100K的性能,但对Mapillary和SYNTHIA无效。Cityscapes处于中间状态。当引入强大的数据增强FDR时,这两个损失都提高了性能,分别提高了1.7%和1.5%。根据这些结果,我们认为数据分布的扩展和特征的规范需要在DG任务中合作,这是一种更好的模拟迁移到目标领域的方式。最后,当这三个部分结合在一起时,我们的框架以平均值37.5%的最佳性能实现了最佳性能,这表明两个先验规范可以互补。
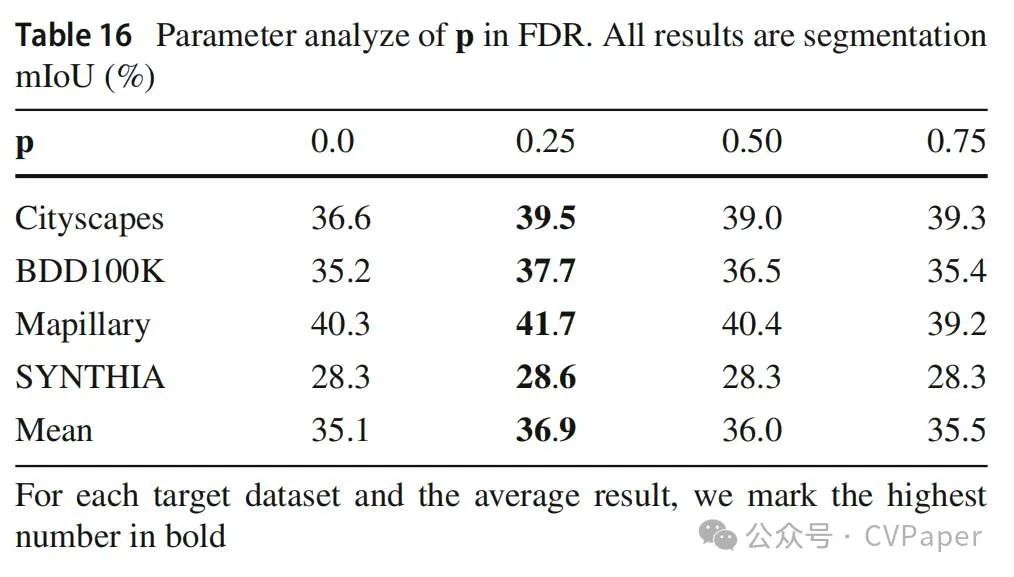
6.2.2 应用FDR的概率
我们定义 为应用于训练数据的FDR的概率。 越大,源域中的数据就越分散。首先,我们在不同 值下训练模型,而不使用LDAP_L和LDAP_R。在表16中,我们可以看到当概率等于0.25时,模型以平均结果36.9%实现了最佳性能,不同的测试数据集显示出一致的趋势。但是当我们在训练过程中引入这两个先验损失时,更大的 可以做得更好。特别是,当 等于0.50时,mIoU为37.5%,当 等于0.25时,仅为36.6%。这个现象再次证明了两个特征级规范需要强大的数据增强的辅助。
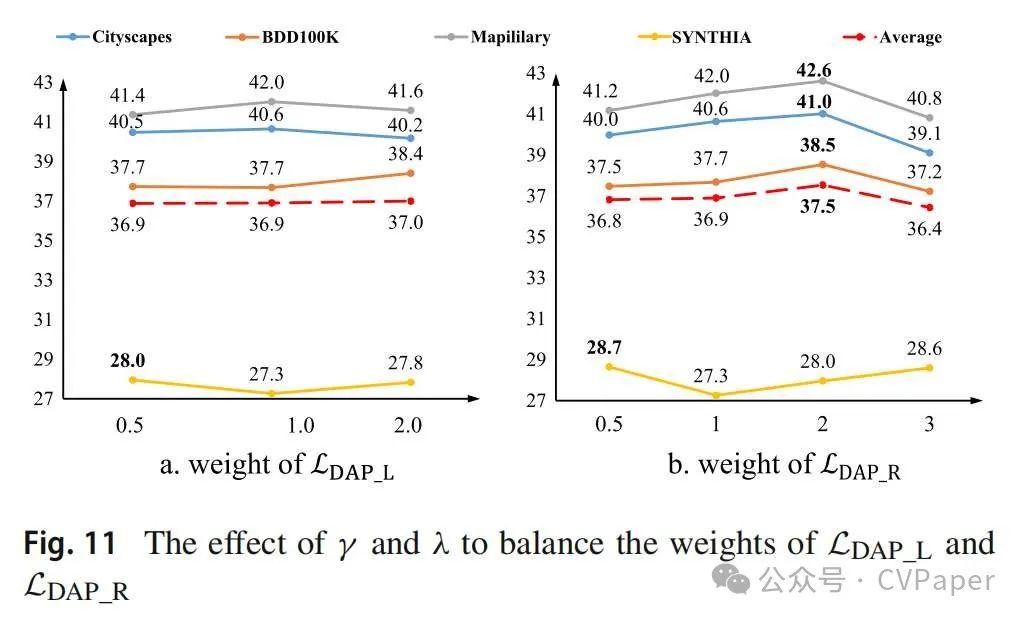
6.2.3 LDAP_L和LDAP_R的权重
控制了整体损失函数中基于语言的嵌入的影响。图11中的左侧图表显示它相对稳定。Mapillary和Cityscapes显示出类似的趋势。BDD100K和SYNTHIA也类似。我们认为 不是一个敏感的参数,因为LDAP_L对分割任务有直接影响,通过 学习得很好。参考 的权重,我们也设置了 为1。然后我们分析了不同 值的影响。右侧的图表显示了真实世界数据集表现出稳定的性能,而SYNTHIA数据集则从更大的 值中受益。为了获得最佳的平均水平结果,我们在实验中设置了 为2。
6.2.4 DAP损失的选择
对于在DG中使用的损失函数,表示为LDAP_L,交叉熵(CE)损失比L2损失实现了更高的准确性,分别为37.5%和36.0%,在从GTAv转移时使用ResNet50主干。相反,在UDA实验中,L2损失优于CE损失(55.0%对53.2%在GTAv→Cityscapes)。L2损失,应用于特征插值步骤之后,有效地对齐了不同域的视觉特征。然而,DG任务的目标是培养一个通用的类别表示,而不是锚定在特定目标域上。因此,CE损失更擅长磨练在单一域数据中学习类别原型。
7 结论
在本文中,我们研究了当源数据到目标测试集存在分布差距时,语义相似类别之间的混淆问题。我们使用贝叶斯理论进行分析,并发现缺乏足够的监督导致了不准确的预测。基于这样的观察,我们引入了一些领域不可知的先验知识来规范特征空间朝向一个共同的表示。我们专注于两个经典的转移分割任务,UDA和DG,并为它们提出了两个框架,并进行了丰富的实验来验证领域不可知先验的有效性。
尽管当前的框架有效地提高了区分语义相似类别的能力,但仍有很大的探索空间。我们认为,像跨模态预训练模型(Radford等人,2021年;Jia等人,2021年)这样的更强先验可以提供更可靠的规范。此外,更复杂的先验嵌入、投影、对齐等设计也可能带来更好的性能。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









