







好消息!加入知识星球,详细阅读本文PDF完整版
论文信息
题目:Progressive Visual Prompt Learning with Contrastive Feature Re-formation
基于对比特征重构的渐进式视觉提示学习
作者:Chen Xu, Yuhan Zhu, Haocheng Shen, Boheng Chen, Yixuan Liao, Xiaoxin Chen, Limin Wang
论文创新点
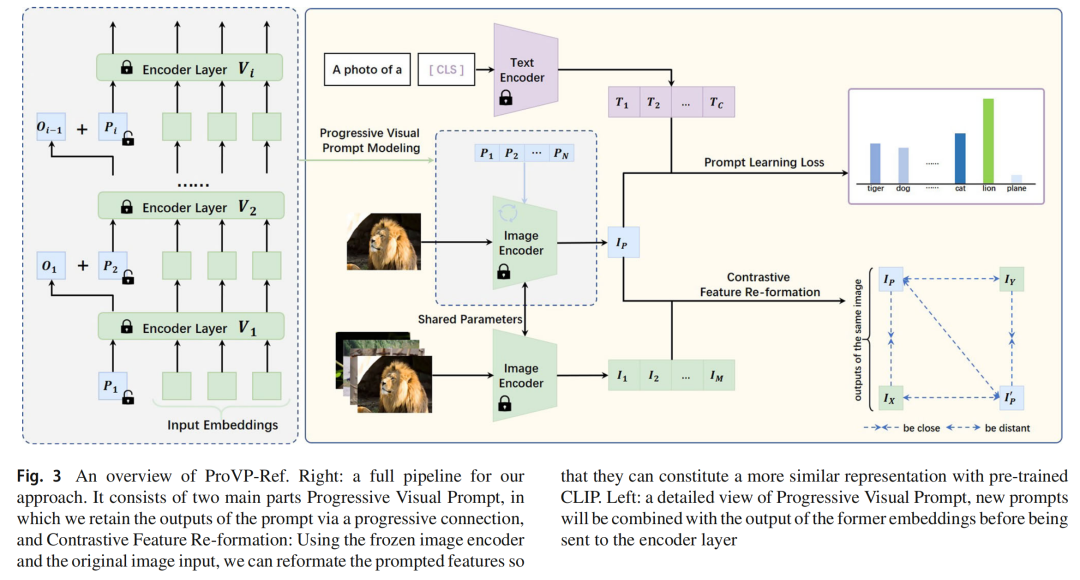
提出ProVP结构:作者提出了渐进式视觉提示(ProVP)结构,该结构建立了相邻层提示之间的连接,每层提示嵌入是新插入提示和前一层提示嵌入输出的组合。
引入对比特征重构技术:为解决提示学习中泛化能力下降的问题,作者提出对比特征重构方法。通过该方法对提示后的视觉特征进行约束,使其与CLIP视觉特征分布不出现显著偏差,在特征空间保留预训练知识,让模型能从预训练特征分布中学习更具泛化性的表示,提高模型在不同任务中的适应性和泛化能力。
探索多模态提示学习:针对ProVP - Ref在部分数据集上受CLIP文本特征可区分性限制的问题,作者提出了扩展的多模态版本ProVP∗ - Ref 。用学习到的文本嵌入替换手工提示,显著提升了在ImageNet和SUN397数据集上的性能。
摘要
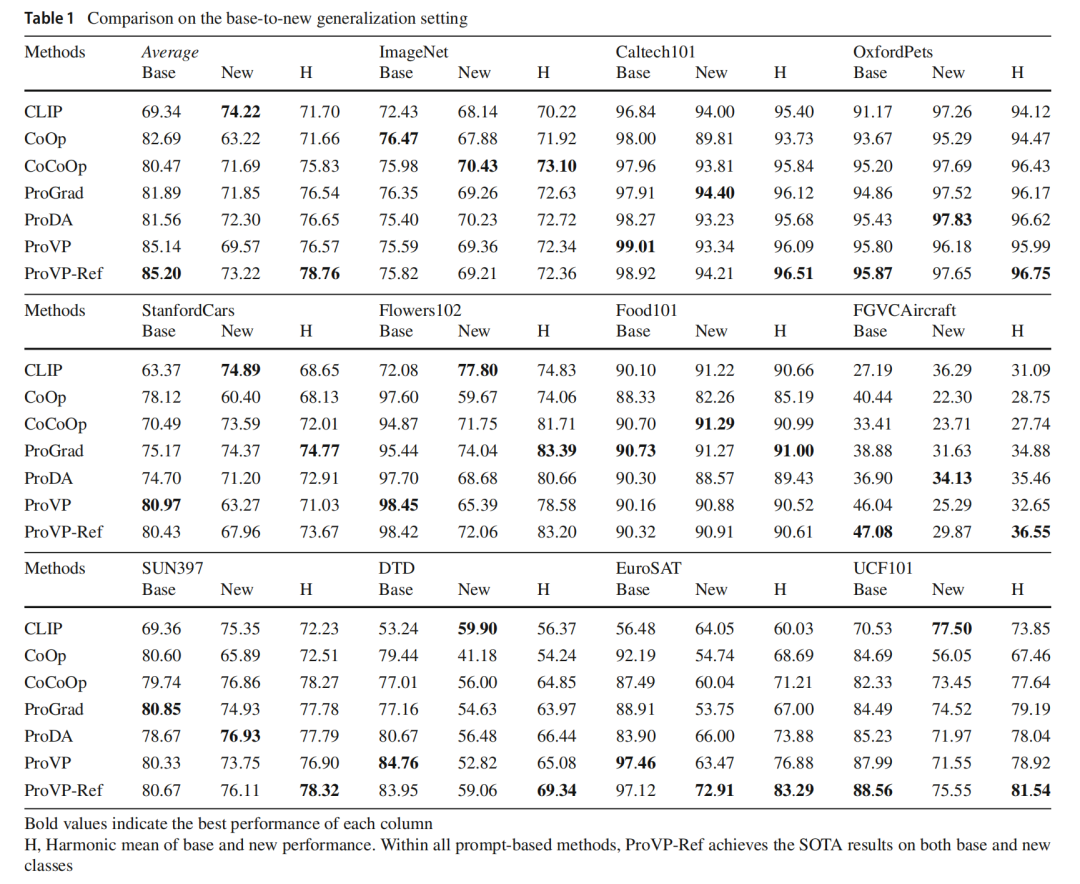
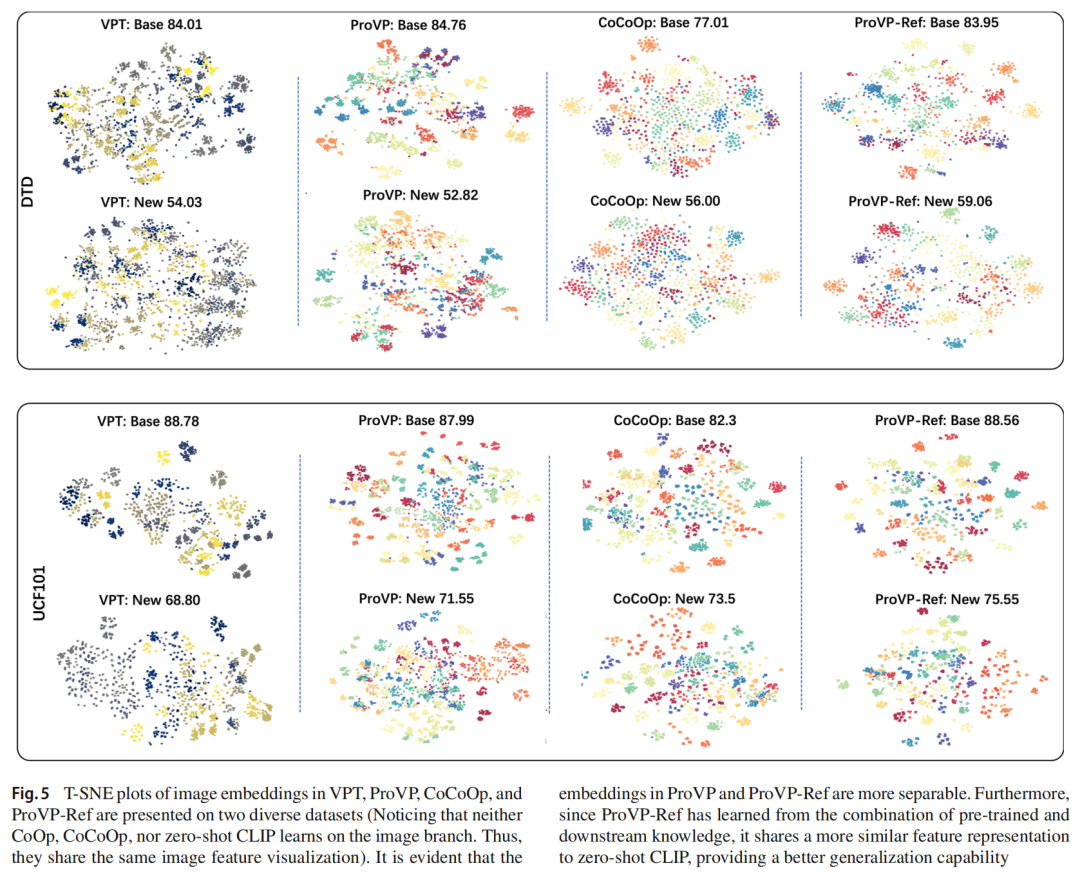
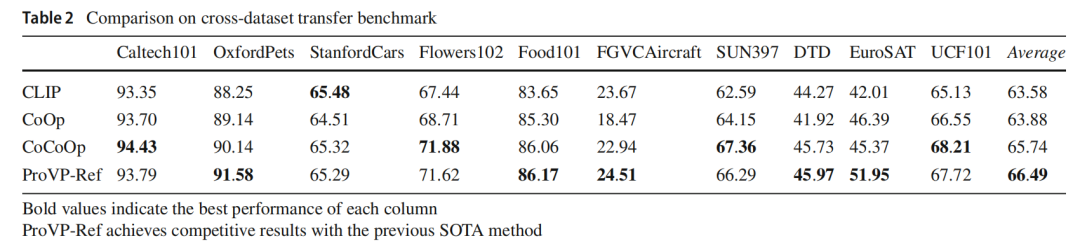
提示学习作为一种有吸引力的替代传统微调范式的方法,可使预训练的视觉语言(V-L)模型适应下游任务。受自然语言处理中提示学习成功的启发,早期研究主要集中在基于文本的提示策略上。相比之下,V-L模型中的视觉提示尚未得到充分利用。将现有的为视觉变换器(ViT)设计的视觉提示方法直接应用到V-L模型中,往往会导致性能不佳或训练不稳定。为了应对这些挑战,本文提出了一种名为渐进式视觉提示(ProVP)的新结构。该设计旨在加强相邻层提示之间的交互,从而以一种类似实例特定的方式,更有效地将图像嵌入传播到更深的层。此外,为了解决可学习提示在训练期间泛化能力下降的常见问题,作者进一步引入了一种用于视觉提示学习的对比特征重构技术。该方法可防止提示后的视觉特征与固定的CLIP视觉特征分布出现显著偏差,确保其具有更好的泛化能力。结合ProVP和对比特征重构技术,作者提出的方法ProVP-Ref显著稳定了训练过程,并增强了V-L模型中视觉提示学习的适应性和泛化能力。为了证明该方法的有效性,作者在11个图像数据集上对ProVP-Ref进行了评估,在少样本学习和基类到新类泛化设置下,在其中7个数据集上取得了最先进的结果。据作者所知,这是第一项展示视觉提示在V-L模型中比该领域以前的文本提示方法性能更优的研究。
3. 方法
3.1 回顾CLIP
CLIP(Radford等人,2021)由解耦的文本和图像编码器对组成。图像编码器旨在将图像编码为低维特征表示,可以是类似CNN的模型,如ResNet-50(He等人,2016),也可以是ViT(Dosovitskiy等人,2021)。文本编码器采用(Vaswani等人,2017)中设计的Transformer编码器架构,将原始输入文本转换为隐藏的文本表示。CLIP在大规模图像文本数据集上使用语言 - 图像对比学习策略进行训练。具体来说,给定一个小批量的文本图像对,模型最大化配对文本和图像特征的相似度,同时最小化未配对的特征相似度。在4亿个图像文本对的大规模高质量训练集的支持下,CLIP获得了强大的泛化能力,能够处理具有挑战性的开放词汇问题,如零样本图像识别。在预测图像标签时,CLIP通过将手工制作的模板(例如,“a photo of a [cls]”)输入文本编码器,为类别标签生成文本表示。这些句子用于获取每个类别的特定嵌入,然后用于计算分类分数,即与图像特征表示的余弦相似度。记 为包含下游任务 个类别的标签集, 为相应的文本模板,令 和 分别为CLIP的文本和图像编码器,则CLIP的识别分数计算如下:
其中 是CLIP学习的温度参数, 表示余弦相似度。
3.1 视觉提示调整
视觉提示调整(Jia等人,2022)将可学习的标记嵌入(视觉提示)插入到ViT(Dosovitskiy等人,2021)的输入潜在空间中,并在冻结模型骨干的同时对其进行调整。VPT提出了两种类型的视觉提示:VPT - 浅层和VPT - 深层,后者在迁移学习任务中表现更好。形式上,用 表示一组 个可学习的 维提示,用 表示第 层 的原始输入嵌入,VPT - 深层在具有 层的ViT(Dosovitskiy等人,2021)中显示提示插入为:
尽管VPT在ViT(Dosovitskiy等人,2021)等视觉骨干网络中被证明是有效的,但作者发现在V-L模型中训练VPT - 深层更具挑战性:每层提示的独立学习可能会混淆优化方向,增加训练难度,并使模型对超参数敏感。此外,VPT中每层随机初始化的提示可能会对模型输出造成显著扰动,增加灾难性遗忘和过拟合的风险。
3.2 渐进式视觉提示学习
观察VPT-Deep中的公式(2),我们发现训练不稳定的一个潜在原因:提示策略不一致。在VPT-Deep中,每个提示仅对其所在层的传播有贡献,在第 层之后,插入提示 的输出 会被丢弃。新插入的提示与输出没有关联且随机初始化,这给提示后的特征带来了显著干扰。相反,这些被丢弃的提示输出可能包含关于输入实例和预训练知识的丰富信息,对后续计算有益。然而,直接将这些输出与新插入的提示一起用于下一层,会使更深层可学习提示的长度不断增加,当长度过大时,会严重干扰学习到的特征表示,导致特征空间中相邻层的不对齐。在实践中,我们观察到这种简单的结构难以收敛,进一步损害了泛化能力。
为了更有效地利用这些被丢弃的提示,我们提出了一种新的提示学习结构——渐进式视觉提示(ProVP),它利用渐进连接将新插入的提示嵌入和前一个输出结合起来。形式上,在ProVP中,视觉编码器的提示策略重新表述为: 对于第一层 ,有 ; 对于后续层,有 , ,其中 是渐进衰减系数。在不持续增加提示长度的情况下,我们的方法通过在 的控制下,结合提示输出和新提示,保留前层学习到的信息。此外,在文献(Jia等人, 2022)中验证了提示的位置是等效的(例如, 与 效果相同),我们遵循文献(Jia等人, 2022)中的设置,在图像嵌入和‘[CLS]’标记之间插入视觉提示。
与公式(2)中描述的VPT-Deep学习策略相比,ProVP以实例特定的方式起作用:前一个块的提示输出 与图像嵌入深度相关,并随输入而变化,而新插入的提示 仍然与输入无关。因此,下一层 的提示输入 也会因不同图像而变化。与CoCoOp类似,我们发现这种架构优先考虑实例级信息,而不是专注于某类的子集,这有助于防止过拟合,并提高对域转移的鲁棒性。得益于上述优点,与VPT变体相比,ProVP在适应和泛化任务中都具有更好的能力。此外,ProVP中使用的渐进连接加强了模型中相邻层提示之间的交互,减少了性能振荡和对超参数的敏感性,从而使训练更加稳定(更多讨论见进一步研究部分)。
在ProVP调整过程中,设 为带提示的图像编码器, 为文本编码器。我们通过最小化负对数似然来优化模型:
其中 表示one-hot真实标注, 是CLIP学习的温度参数。
3.3 对比特征重构
当通过提示学习使预训练模型适应下游任务时,泛化能力下降的风险是一个普遍关注的问题,例如CoOp等模型在训练后对未见类别的测试性能与零样本CLIP相比显著下降。正如文献(Zhu等人, 2022)所指出的,一个可能的原因是提示学习不当。在学习过程中仅依赖交叉熵损失(公式(5))可能会导致模型忘记预训练的通用知识,而过度关注特定的下游数据,从而损害了从预训练模型继承的泛化能力。
受文献(Zhu等人, 2022)的见解和知识蒸馏方法(Hinton等人, 2015; Phuong和Lampert, 2019)的启发,我们通过利用零样本CLIP的预训练信息来解决这个遗忘问题,并专门为视觉提示学习设计了一种新的训练策略——对比特征重构。与文献(Zhu等人, 2022)中保留零样本CLIP预测不同,我们在预训练图像特征分布的指导下,在特征空间中保持模型的泛化能力。由于视觉模态中随机初始化的提示会导致预训练特征发生显著偏移,训练后提示特征的多样性可能会降低,对文本编码器的可区分性也会降低。我们意识到克服这个问题可以更有效地缓解泛化能力下降,因此引入了一种新的训练策略——对比特征重构,将偏移的特征重新调整为与预训练CLIP相似的分布。
设 、 分别为预训练和带提示的图像编码器, 表示一个包含 张图像的小批量。对比特征重构约束同一图像 的提示特征和预训练特征相近,不同图像的特征远离。因此,重构损失 定义为:
结合公式(5)中的传统交叉熵损失,总训练损失可以表示为:
其中 是一个超参数,用于在训练期间调整 的权重。
通过使用 使带提示的精炼特征与预训练分布对齐,经过调整的图像编码器 编码的图像嵌入对文本编码器来说变得更易于识别。因此,我们的方法可以产生更接近零样本CLIP的预测结果,并且在预训练预测与下游真实情况发生冲突时,放宽对预测logits的严格约束,使对比特征重构能够更灵活地运行。受益于这种策略,我们的模型ProVP-Ref可以从预训练特征分布中学习到更具泛化性的表示。此外,我们的模型受预训练知识冲突的影响较小,在存在较大域转移的下游任务中仍然具有适应性。
4. 实验
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与作者联系,作者将在第一时间回复并处理。

#论 文 推 广#
让你的论文工作被更多人看到
你是否有这样的苦恼:自己辛苦的论文工作,几乎没有任何的引用。为什么会这样?主要是自己的工作没有被更多的人了解。
计算机书童为各位推广自己的论文搭建一个平台,让更多的人了解自己的工作,同时促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。 计算机书童 鼓励高校实验室或个人,在我们的平台上分享自己论文的介绍、解读等。
稿件基本要求:
• 文章确系个人论文的解读,未曾在公众号平台标记原创发表,
• 稿件建议以 markdown 格式撰写,文中配图要求图片清晰,无版权问题
投稿通道:
• 添加小编微信协商投稿事宜,备注:姓名-投稿

△长按添加PaperEveryday小编


















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









