







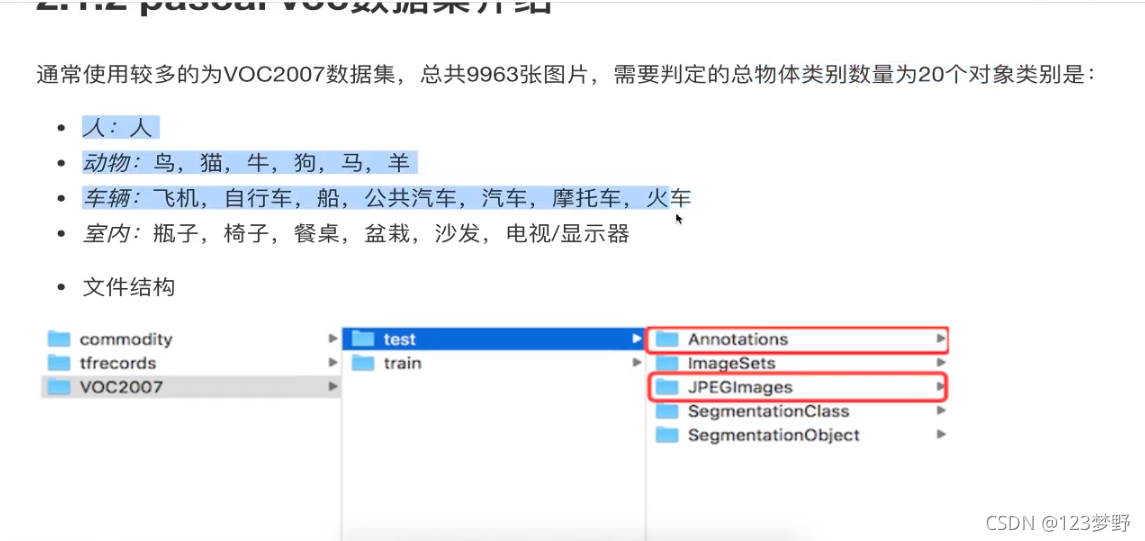
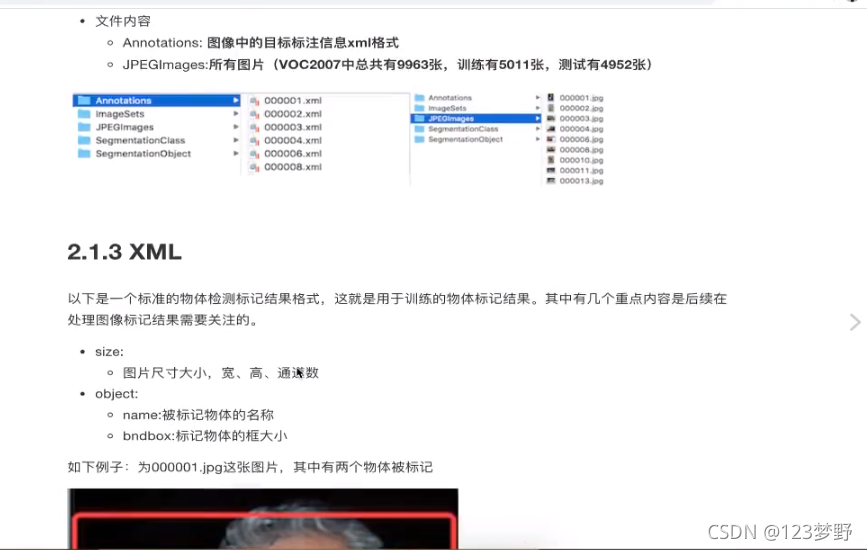
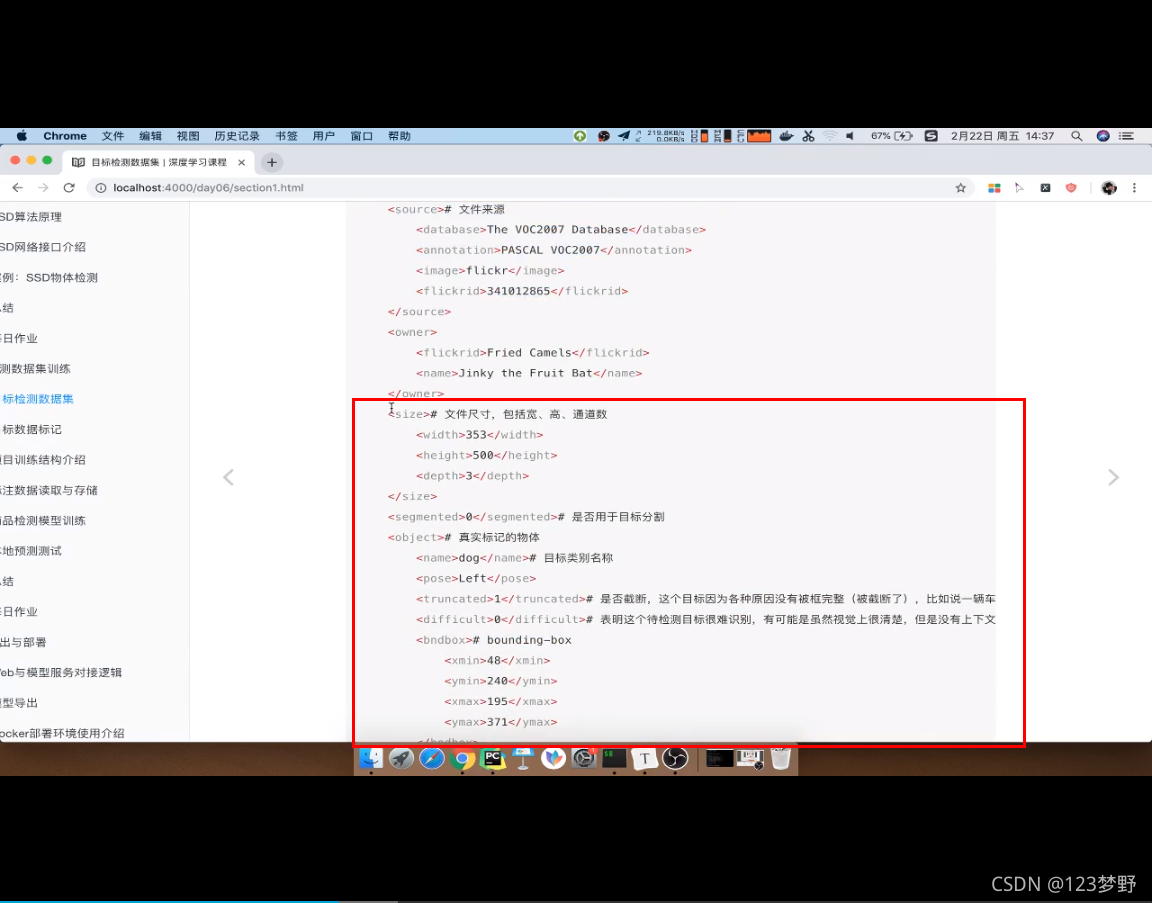
检测数据集介绍
商品检测数据集处理
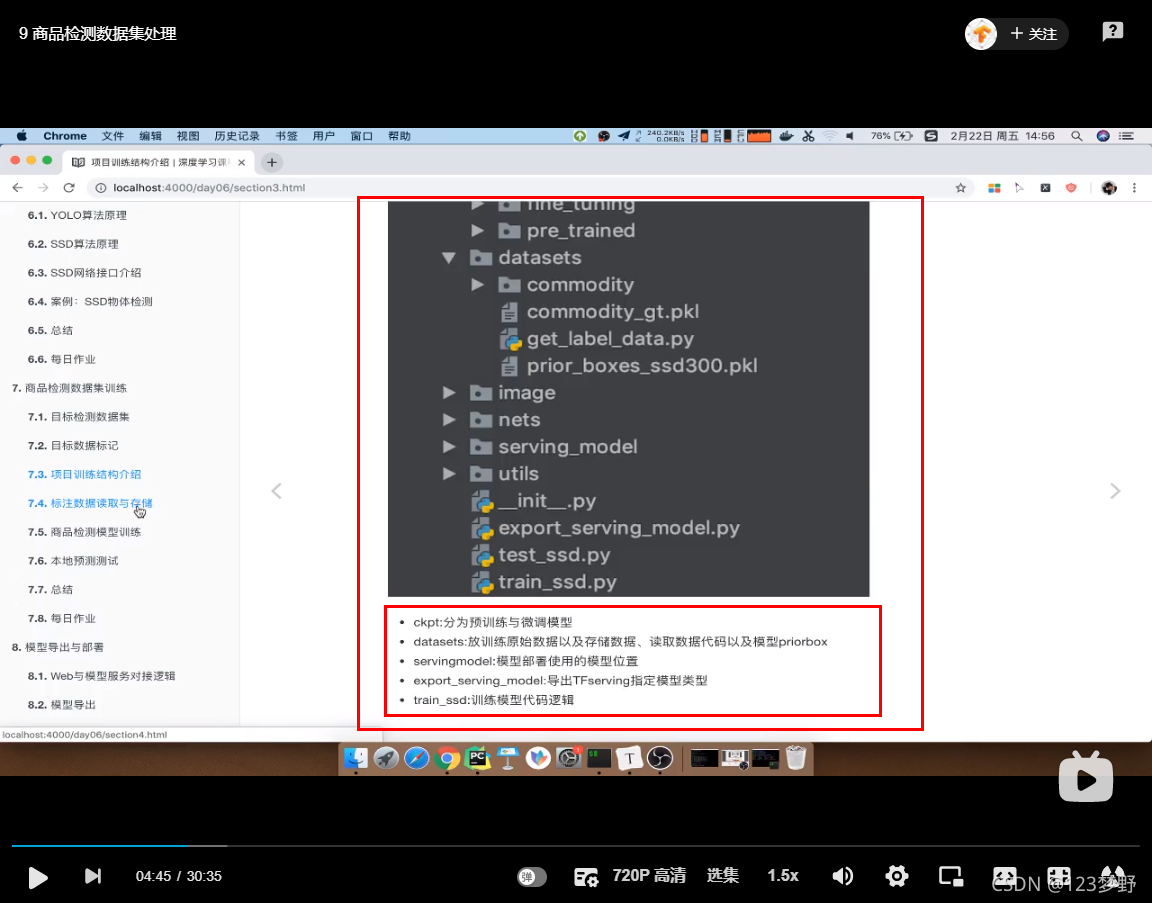
from xml.etree import ElementTree as ET
import os
import numpy as np
import pickle
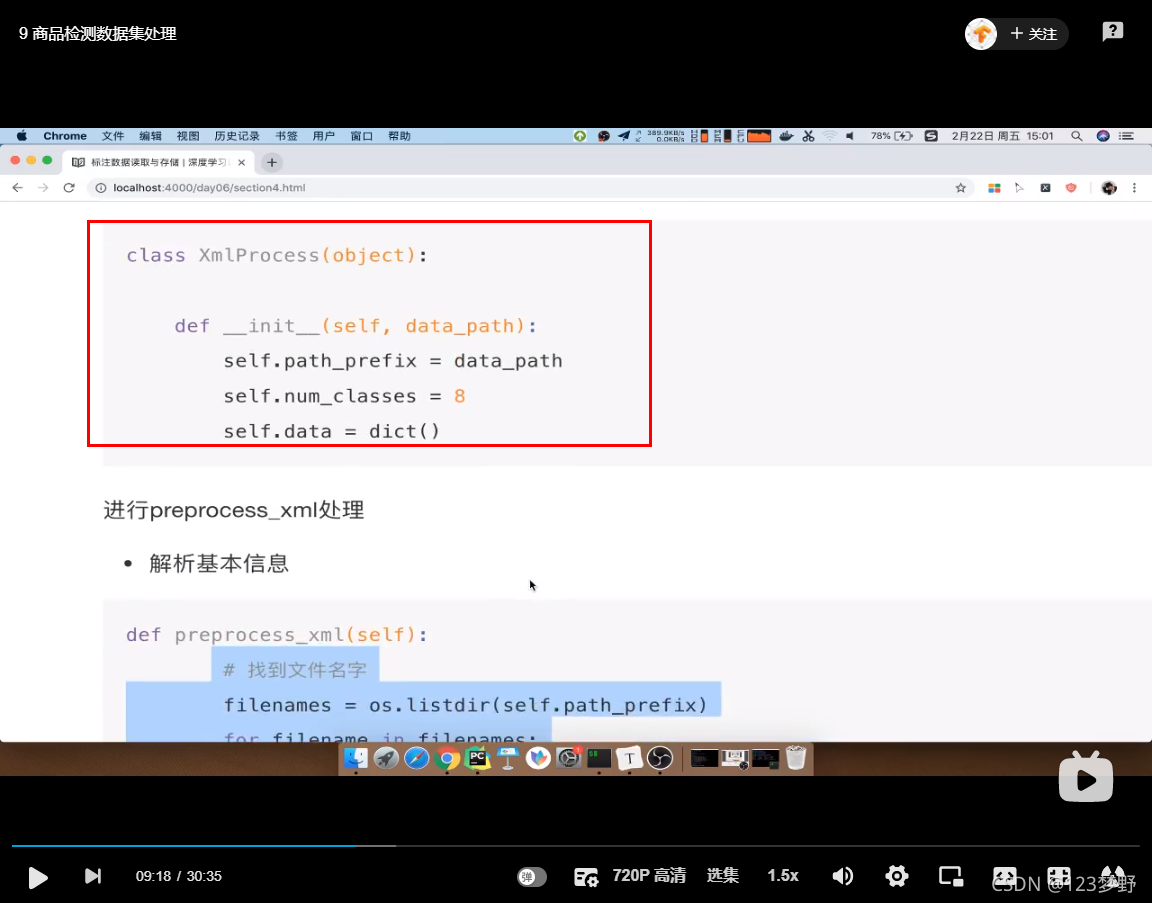
class XmlProcess(object):
def __init__(self,file_path):
self.xml_path = file_path
self.num_classes = 8
self.data = {}
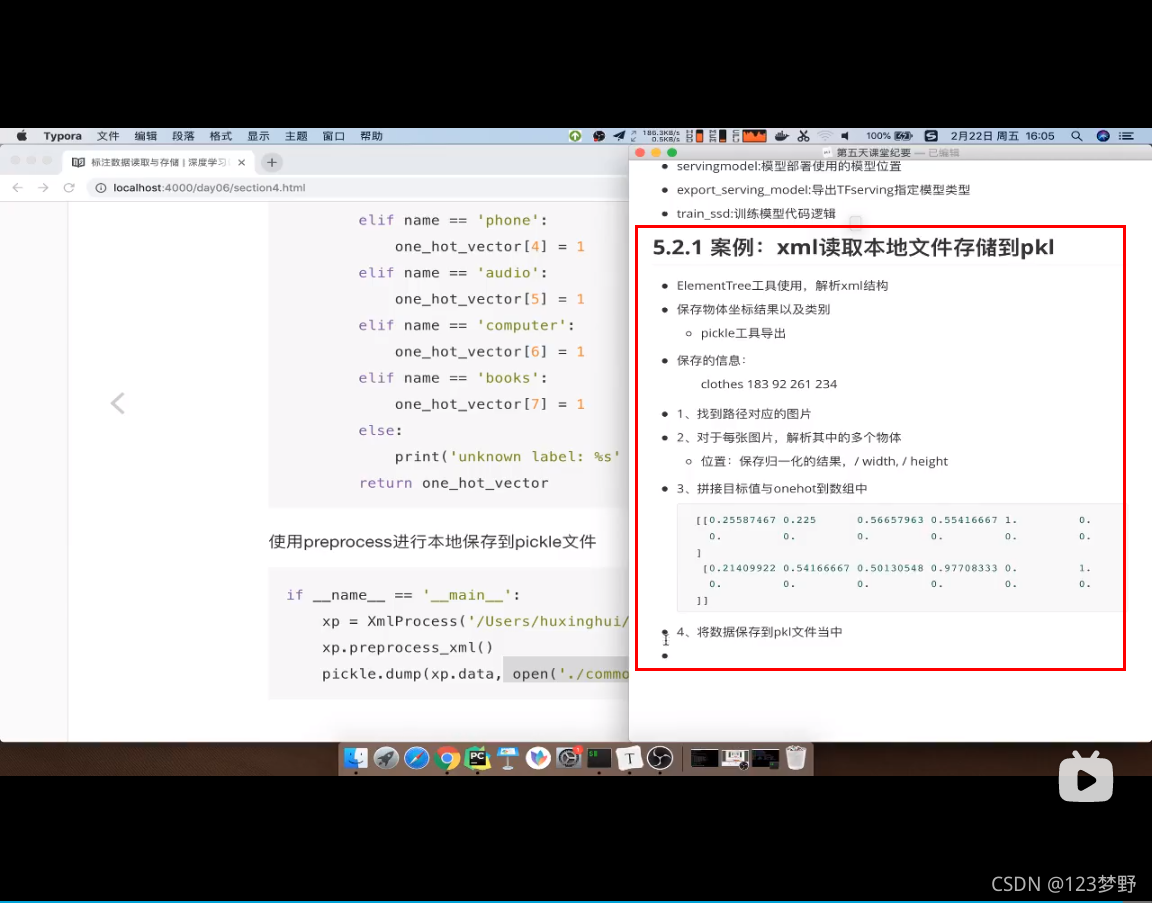
def process_xml(self):
"""
处理图片的标注信息,解析图片大小,图片中所有物体位置,类别
存入序列化的pkl文件
:return:
"""
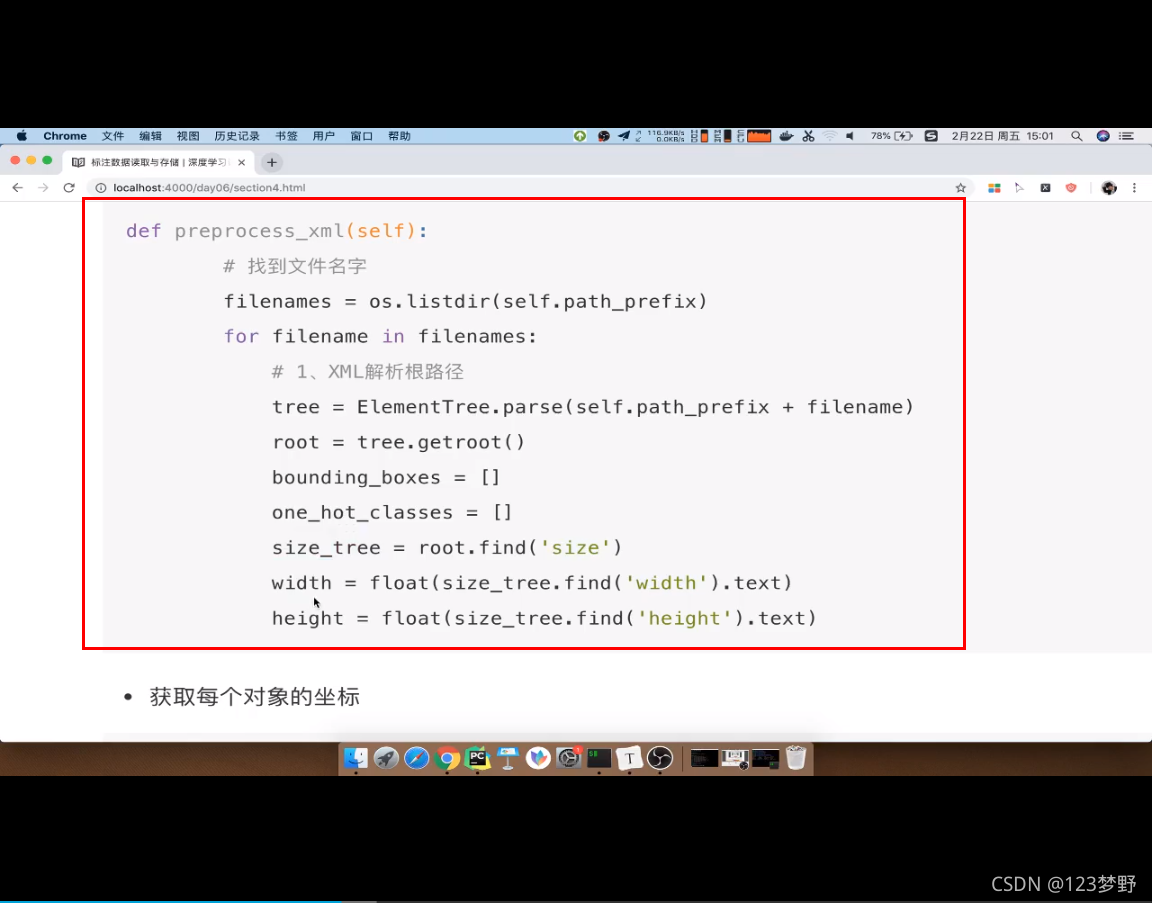
#1.找到路径对应的图片
for filename in os.listdir(self.xml_path):
et = ET.parse(self.xml_path+filename)
root = et.getroot()
#print(root)
#获取图片基础属性
#获取size
size = root.find('size')
width = float(size.find('width').text)
height =float(size.find('height').text)
depth = float(size.find('depth').text)
print(width,height,depth)
#2.对于每张图片,解析其中的多个物体
bounding_boxes = []
one_hots = []
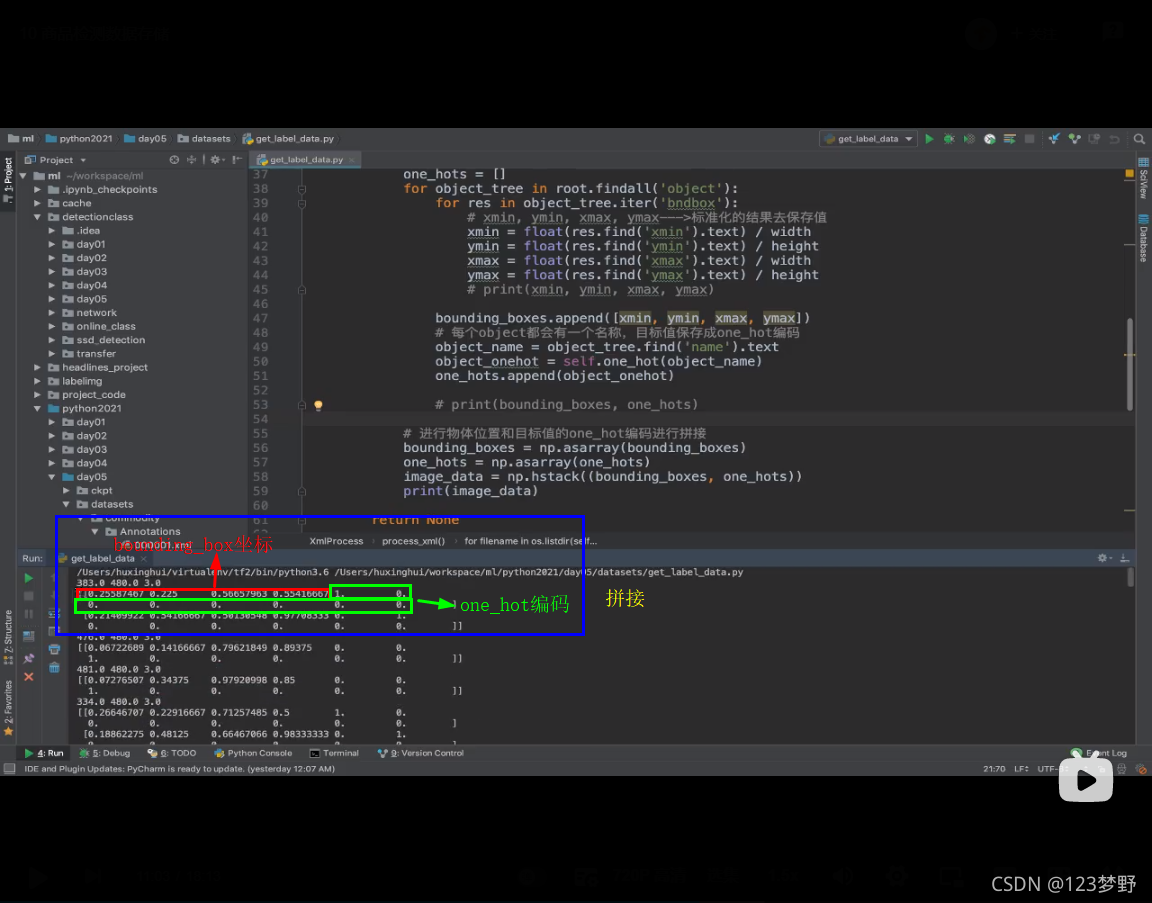
for object_tree in root.findall('object'):
for res in object_tree.iter('bndbox'):
#xmin,ymin,xmax,ymax---->标准化的结果去保存值
xmin = float(res.find('xmin').text) / width
ymin = float(res.find('ymin').text) / height
xmax = float(res.find('xmax').text) / width
ymax = float(res.find('ymax').text) / height
#print(xmin,ymin,xmax,ymax)
bounding_boxes.append([xmin,ymin,xmax,ymax])
#每个object都会有一个名称,目标值保存成one_hot编码
object_name = object_tree.find('name').text
object_onehot = self.one_hot(object_name)
one_hots.append(object_onehot)
#print(bounding_boxes,one_hots)
#进行物体位置和目标值的one_hot编码进行拼接
bounding_boxes = np.asarray(bounding_boxes)
one_hots = np.asarray(one_hots)
image_data = np.hstack((bounding_boxes,one_hots))
print(image_data)
self.data[filename] = image_data
return None
def one_hot(self,name):
one_hot_vector = [0]*self.num_classes
if name == 'clothes':
one_hot_vector[0] = 1
elif name == 'pants':
one_hot_vector[1] = 1
elif name == 'shoes':
one_hot_vector[2] = 1
elif name == 'watch':
one_hot_vector[3] = 1
elif name == 'phone':
one_hot_vector[4] = 1
elif name == 'audio':
one_hot_vector[5] = 1
elif name == 'computer':
one_hot_vector[6] = 1
elif name == 'books':
one_hot_vector[7] = 1
else:
print('unknown label:%s' % name)
return one_hot_vector
if __name__=='__name':
xp=XmlProcess()
xp.process_xml()
print(xp.data)
pickle.dump(xp.data,open(".pkl",'wb'))















 2234
2234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









