







bibtex格式的引用
@article{hinton2015distilling,
title={Distilling the knowledge in a neural network},
author={Hinton, Geoffrey and Vinyals, Oriol and Dean, Jeff},
journal={arXiv preprint arXiv:1503.02531},
year={2015}
}
摘要
提高几乎所有机器学习算法性能的一个非常简单的方法是在相同的数据上训练许多不同的模型,然后平均它们的预测结果。不幸的是,使用整个集成模型进行预测很麻烦,并且可能计算成本太高,无法部署给大量用户,特别是如果单个模型是大型神经网络。Caruana和他的合作者[1]已经证明,可以将集成中的知识压缩到一个更容易部署的单个模型中,我们使用不同的压缩技术进一步开发了这种方法。我们在MNIST上取得了一些令人惊讶的结果,我们表明,通过将集成模型中的知识提取到一个单个模型中,我们可以显著改善一个使用频繁的商业系统的声学模型。我们还引入了一种由一个或多个完整模型和许多专家模型组成的新型集成,这些专家模型学习区分完整模型混淆的细粒度类。与专家混合不同,这些专家模型可以快速并行地训练。
1 Introduction
待更新
5.4 专家集成进行推断
在研究专家模型被蒸馏时的情况之前,我们想要查看包含专家的集成模型表现如何。除了专家模型外,我们始终有一个通用模型,这样我们可以处理没有专家的类别,并决定使用哪些专家。给定输入图像 x,我们以两个步骤进行 top-one 分类:步骤 1:对于每个测试案例,根据通用模型找出 n 个最可能的类别。我们称这组类别为 k。在我们的实验中,我们使用了 n=1。步骤 2:然后,我们采用所有的专家模型 m,其易混淆类别子集 Sm 与 k 有非空交集,并称其为活跃专家集 Ak(注意,该集合可能为空)。然后,我们找到所有类别的全概率分布 q,使得其最小化:
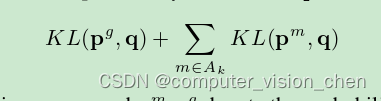
KL 代表 KL 散度,而 p^m, p^g 表示专家模型或通用全模型的概率分布。分布 p_m 是模型 m 所有专家类别以及单个垃圾桶类别的分布,因此在计算其与全概率分布 q 的 KL 散度时,我们将全概率分布 q 分配给模型 m 垃圾桶中所有类别的概率进行求和。
















 5199
5199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











