







 本文介绍了如何使用R语言进行广义线性回归,特别是针对0-1因变量的Logit和Probit回归模型。讨论了广义线性模型的构成,包括随机部分、线性部分和连接函数。文章通过多变量情况下的案例分析,展示了如何运用glm()函数进行模型构建,并探讨了数据集中各变量与因变量的相关性。
本文介绍了如何使用R语言进行广义线性回归,特别是针对0-1因变量的Logit和Probit回归模型。讨论了广义线性模型的构成,包括随机部分、线性部分和连接函数。文章通过多变量情况下的案例分析,展示了如何运用glm()函数进行模型构建,并探讨了数据集中各变量与因变量的相关性。
1、广义线性回归

广义线性模型有三个组成部分:
(1) 随机部分, 即变量所属的指数族分布 族成员, 诸如正态分布, 二项分布, Poisson 分布等等. (2) 线性部分, 即 η = x⊤β. (3) 连接函数 g(µ) = η。 R 中的广义线性模型函数glm() 对指数族中某分布的默认连接函数 是其典则连接函数, 下表列出了 R 函数glm() 所用的某些指数族分布的 典则连接函数.

2、0-1因变量的回归模型
对于因变量为0,1变量的问题,可以考虑两种模型来解决
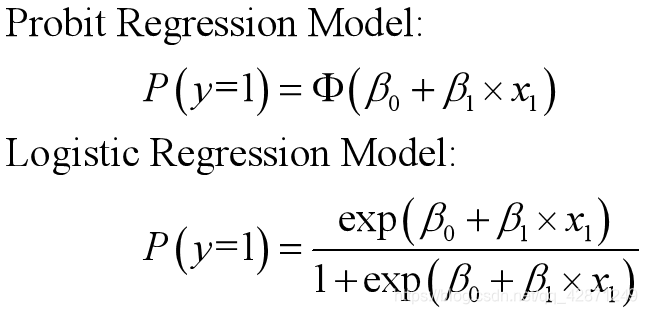
经过Probit变换和Logit变换,两种模型可以写成:
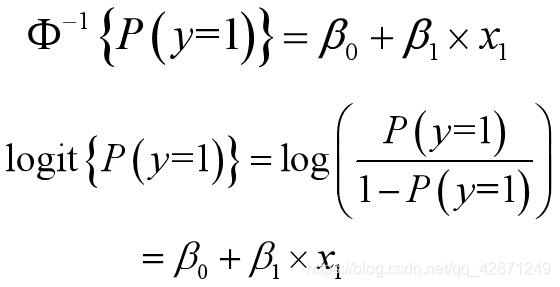
多变量情况:
logit回归

probit回归
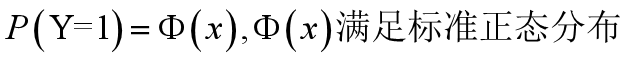
3、案例分析
R中的广义线性回归函数为:glm()
语法为:glm(formula, family = gaussian, data, weights, subset, na.action, start = NULL, etastart, mustart, offset, control = glm.control(…), model = TRUE, method = “glm.fit”, x = FALSE, y = TRUE, contrasts = NULL, …)
与线性回归lm不同之处就在于参数family,这个参数的作用在于定义一个族以及连接函数,使用该连接函数将因变量的期望与自变量联系起来,例如:上面讲到的logit模型和probit模型的参数分别为family= binomial(link=logit)和family= binomial(link=probit).
数据集介绍
数据来自新竹市输血服务中心的记录http://archive.ics.uci.edu/ml/datasets/Blood+Transfusion+Service+Center变量有Recency(上次献血距离研究时的月份),Frequency(总献血次数),Time(第一次献血是多少个月之前),Donate(是否将在2007年3月再献血,1为会,0为不会)
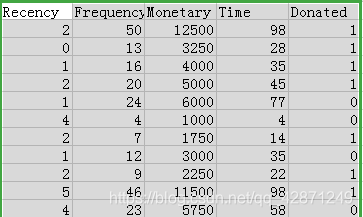
分别三个变量与因变量的相关性
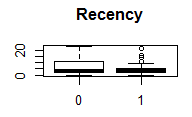
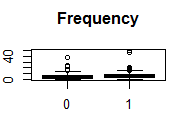
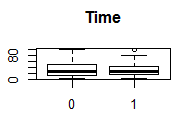
通过图可以看出,三个变量与因变量还是有一定的关系的。
完整代码附上,备注的比较详细,也比较简单。
a<-read.csv("Trans.csv",header=T)
a<-a[,-3] #去掉第三列
names(a)<-c("x1","x2","x3","y") #设置变量名
a1<-a[c(1:400),] #取前400行数据,赋值给a1
a2=a[c(401:748),] #取出从401行开始剩下所有行的数据,赋值给a2
a1[c(1:5),] #展示a1前5行数据
#画图
par(mfrow=c(2,2)) #设置画图模式为2*2的格式
boxplot(x1~y,data=a1,main 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









