







 本文详细介绍了Poisson回归模型在广义线性模型中的应用,针对散布问题和零膨胀问题提出了解决方案,并通过R语言的代码示例进行演示。在仙客来数据集上进行分析,展示了如何处理过散布和零膨胀,以及实施交叉验证的方法。
本文详细介绍了Poisson回归模型在广义线性模型中的应用,针对散布问题和零膨胀问题提出了解决方案,并通过R语言的代码示例进行演示。在仙客来数据集上进行分析,展示了如何处理过散布和零膨胀,以及实施交叉验证的方法。
Poisson回归模型
Poisson回归也是广义线性回归模型中的一中,详细介绍可见之前的博客:
https://blog.csdn.net/qq_42871249/article/details/104339650
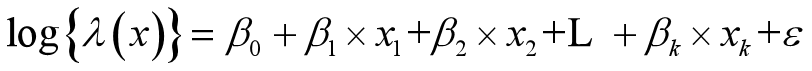
使用 Poisson回归模型时的两个问题
由于广义线性模型的假定很强, 所以当实际数据与假定的分布不符时会产生一些问题. Poisson回归模型也不例外, 人们目前主要关注的是 以下两个问题:
一、散布问题
在Poisson回归模型中, 假定方差和均值相等, 当方差大于或小于 均值时就会出现过散布(overdispersion)问题或欠散布 (underdispersion) 问题. 使用 Poisson回归模型时出现的散布问题的最简单解决办法是使用提到的准 Poisson回归模型, 而且还可以说明方差和均值的关系。准 Poisson 模型拟合代码示例:
glm(y~.,data,family=quasi(variance=“mu^2”,link=“log”))
这里的选项variance=“mu^2” 就把方差看成随着均值平方变化的函数, 这个选项可以输入"constant", “mu(1-mu)”, “mu”, “mu^2”, “mu^3”, 等 等.
二、零膨胀问题

代码介绍:
同样使用:glm(formula, family = gaussian, data, weights, subset, na.action, start = NULL, etastart, mustart, offset, control = glm.control(…), model = TRUE, method = “glm.fit”, x = FALSE, y = TRUE, contrasts = NULL, …)
不同之处在于参数family=possion()
仙客来案例分析
仙客来数据集包含三个自变量,因变量是Flowers开花数目。
直接上代码
w=read.csv("cyclamen.csv");n=nrow(w);m=ncol(w)
for(i in c(1,2,5))w[,i]=factor(w[,i])
table(w[,c(1,2,5)])
w=read.csv("cyclamen.csv");n=nrow(w)
for(i in c(1,2,5))w[,i]=factor(w[,i])
w=w[,-(3:4)]#不需要三行四行所以去掉
a=glm(Flowers~ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









