






一、引言
多模态情感分析(MSA)利用语言、视觉和音频等异构模态来增强对人类情感的理解。虽然现有的模型通常侧重于提取跨模态的共享信息或直接融合异构模态,但由于所有模态的平等对待和模态对之间的信息相互传递,这种方法可能会引入冗余和冲突。为了解决这些问题,我们提出了一种解耦语言聚焦(DLF)多模态表示学习框架,该框架包含一个特征解耦模块,用于分离模态共享和模态特定的信息。为了进一步减少冗余并增强语言目标特征,引入了四种几何度量来细化解纠缠过程。进一步开发了语言聚焦吸引器(LFA),通过语言引导的交叉注意力机制利用互补的特定情态信息来加强语言表征。该框架还采用分层预测来提高整体准确性。
二、研究现状
近年来,研究人员对MSA的兴趣日益浓厚。已经提出了许多模态模型来促进MSA,它们可以分为两组:面向表示学习的方法面向多模态融合的方法。前者主要旨在获得对各种模态的高级语义理解,并丰富人类情感的不同线索,从而产生更强大的人类情感编码器。相反,后者强调在各个层面设计复杂的融合策略,包括特征级、决策级和模型级融合,以从多模态数据中得出统一的表示。
三、方法
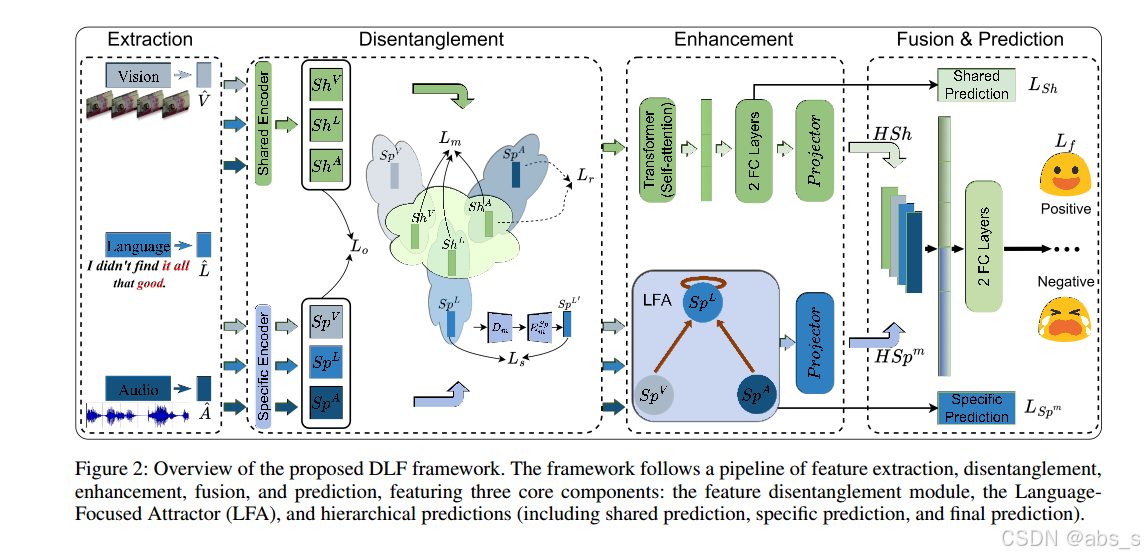
图2:所提出的DLF框架概述。该框架遵循特征提取、解纠缠、增强、融合和预测的流程,具有三个核心组件:特征解纠缠模块、语言聚焦吸引子(LFA)和分层预测(包括共享预测、特定预测和最终预测)。
3.1Feature Disentanglement Module
Feature Disentanglement Module(特征解耦模块)是DLF框架中的关键组成部分,旨在减少多模态信息中的冗余和冲突。该模块通过将不同模态的特征分解为共享和特定模态的特征空间,从而有效地解耦信息。DLF框架采用了以下机制来实现特征解耦:
1.共享与特定模态特征空间的分解
该模块使用一个共享编码器和三个模态特定编码器,将输入的多模态特征分解为共享的(Shm)和特定模态的(Spm)特征空间,分别表示语言(L)、视觉(V)和音频(A)三个模态。
2.几何度量的正则化
为了有效地进行特征解耦,DLF引入了四种基于欧几里得距离和余弦相似度的几何度量,这些度量有助于减少不同模态之间的冗余信息并强化解耦效果。相比传统方法(如KL散度),几何度量在计算效率和直观性上具有优势。
3.特征重构
解耦过程完成后,DLF将共享和特定模态的特征通过连接操作(⊕)进行融合,再通过卷积解码器(D_m)重构出每个模态的输入特征,得到新的特征表示(X′m)。
通过这一过程,特征解耦模块能够有效地分离出模态共享和特定的信息,避免了不同模态间信息的冲突和冗余,从而为后续的多模态情感分析任务提供了更加清晰、干净的输入。
3.2Language-Focused Attractor (LFA)
Language-Focused Attractor (LFA) 是 DLF 框架中的核心组件,旨在通过增强语言模态的表示来提高多模态情感分析(MSA)的性能。LFA的主要目标是利用其他模态(视觉和音频)中的互补信息来增强语言模态的特征表示,从而减少冗余和冲突,提高整体准确性。LFA的工作原理可以概括为以下几个步骤:
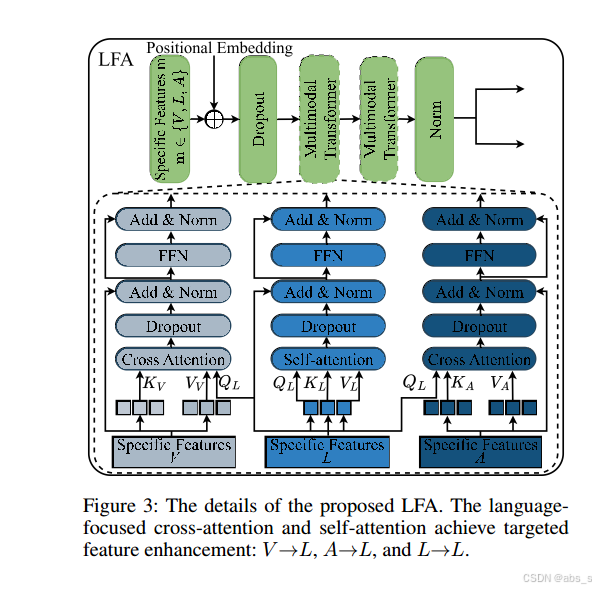
1.语言引导的跨模态注意力机制
LFA通过一个语言查询基础的多模态交叉注意力机制(Language-Query-based Multimodal Cross-Attention)来实现目标。具体来说,LFA使用语言模态(L)的特征作为查询(Query),并通过注意力机制从其他模态(视频和音频)中获取有用的互补信息。这种机制确保了只有与语言模态相关的信息被强化,而其他模态的信息则被适当地引导到语言模态中。
2.语言模态的增强
LFA专门关注如何在多模态特征中提取与语言相关的信息并进行强化。通过将视觉(V)和音频(A)模态的特征与语言模态的特征融合,LFA有效地增强了语言特征的表达能力,特别是在情感分析任务中,语言通常是主导模态。
3.减少冗余和冲突
LFA的设计目标之一是减少模态间的冗余和冲突。在传统方法中,直接融合不同模态的特征可能会导致信息冲突,因为各模态的信息可能不完全一致或存在重复。LFA通过精确地从其他模态引导相关信息,仅增强语言模态的特征,从而减少这种冗余和冲突,提高最终的预测准确性。
4.目标导向的特征增强
LFA的特征增强机制是针对语言模态的,其他模态的信息通过注意力机制以语言为目标进行转移和补充。这种增强方式使得语言模态的情感特征更加精准,同时维持了多模态之间的协同工作。
3.3多模态融合。
如图2所示,模态共享特征首先通过统一的Transformer层进行处理,然后是两个完全连接的层,然后投影到更高级别的共享特征中,表示为HSh。最后,多模态融合层将HSh与HSpm组合在一起,形成最终的多模态特征。
3.4Hierarchical Predictions
DLF 引入了层次化的预测机制,不仅仅依赖于最终的特征融合结果,而是同时考虑了模态共享特征的预测(L_Sh),模态特定特征的预测(L_Sp_m),以及最终的整体预测(L_f)。通过这种方式,模型能够在多个层面上逐步改进预测精度。
四、实验
我们在两个广泛使用的数据集上评估DLF:CMU多模态情绪强度(MOSI)和CMU多模式意见情绪和情感强度(MOSEI)。
评估指标。MSA的性能使用多种指标进行评估:7级精度(Acc-7)、5级精度(Acco-5)、二元精度(Acc-2)、F1评分、模型预测与人类注释之间的相关性(Corr)和平均绝对误差(MAE)。这些指标共同提供了对DLF在各种情绪分析任务中的有效性的全面评估。
五、结论
本文提出了DLF框架来提高MSA的性能。DLF通过遵循特征提取、解纠缠、增强、融合和预测的流水线来产生强大的多模态表示,主要受益于特征解纠缠模块、语言聚焦吸引子和分层预测。通过与11项基线和综合消融研究的比较,广泛的结果证实了DLF的优越性。

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









