







0.前言
AI模型部署的常见方案
参考: pytorch模型转TensorRT模型部署
- cpu: pytorch->onnx->onnxruntime
- gpu: pytorch->onnx->onnx2trt->tensorRT
- arm: pytorch->onnx->ncnn/mace/mnn
在这里我们使用的是GPU的模型部署:pytorch->onnx->onnx2trt->tensorRT
1.环境的搭建(Linux)
重要的依赖
- CUDA
- cudnn
- TensorRT
- pytorch
CUDA的安装
step1.你需要查看你电脑显卡驱动所支持的最大CUDA版本
查看GPU信息的命令
watch -n 0.5 nvidia-smi

比如卡驱动所支持的最大CUDA版本
CUDA Version: 12.0
step2.下载CUDA
链接: CUDA下载官网:CUDA Toolkit Archive | NVIDIA Developer
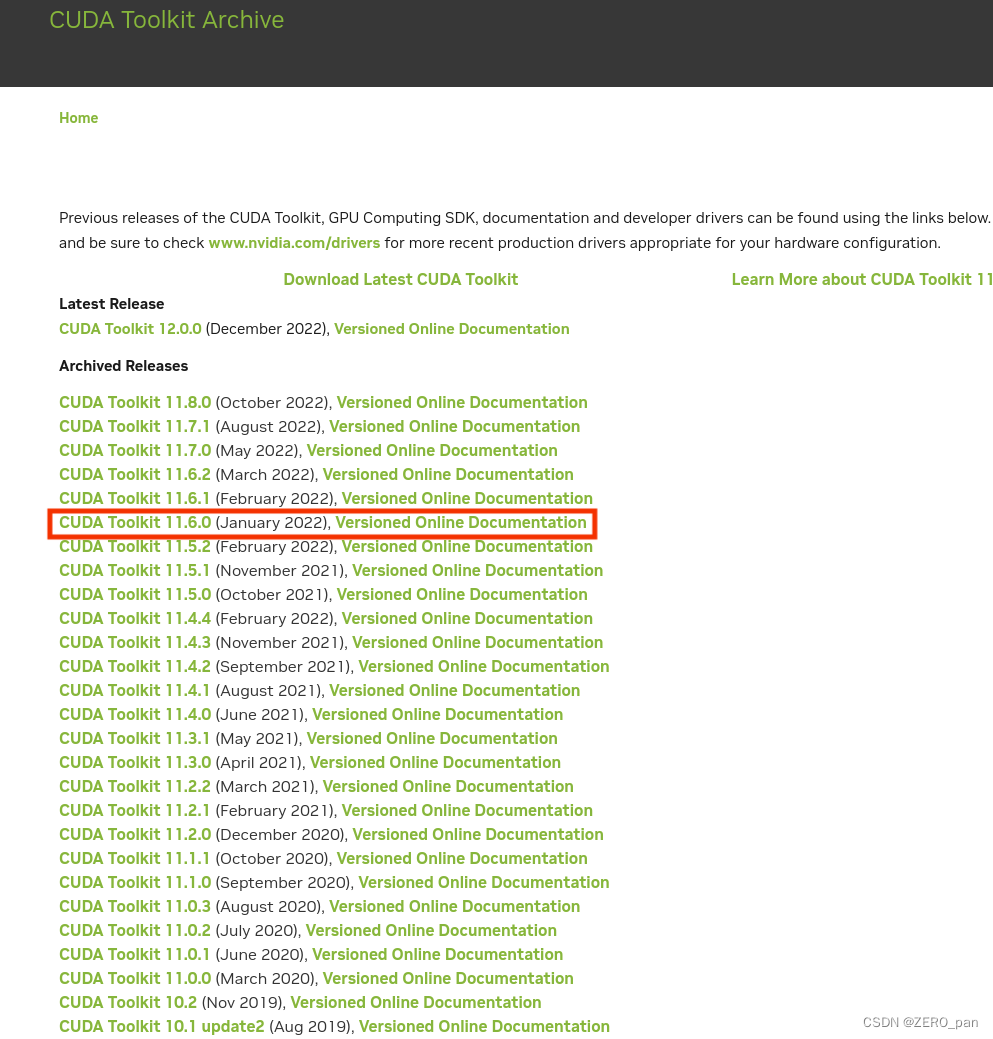
下载之后你将得到一个.run的文件

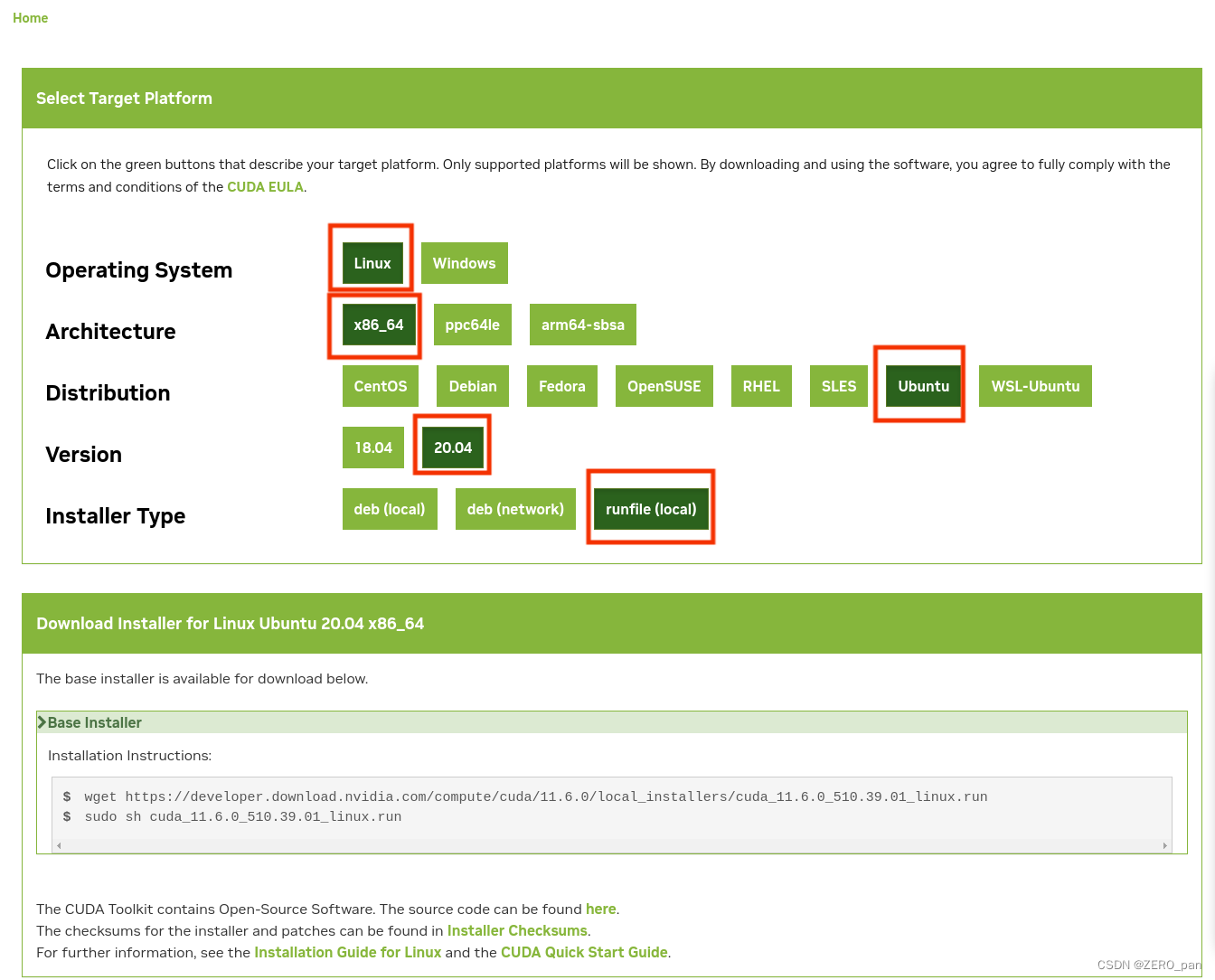
step3.进行安装
sudo chmod +x cuda_11.6.0_510.39.01_linux.run #给文件权限
./ cuda_11.6.0_510.39.01_linux.run

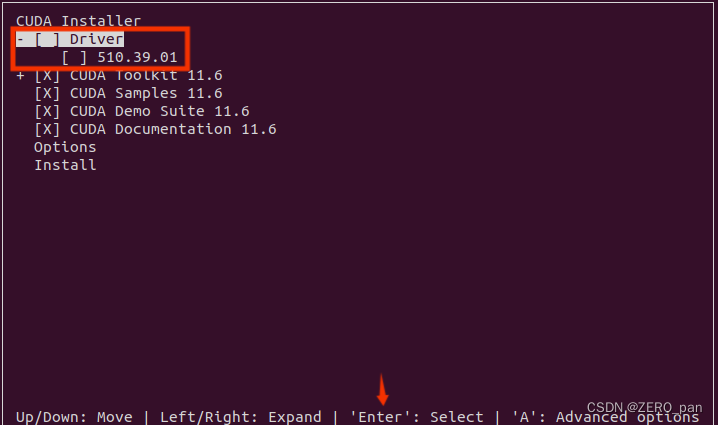
对于已经按照显卡驱动的我们老说,应该按回车取消驱动的安装。
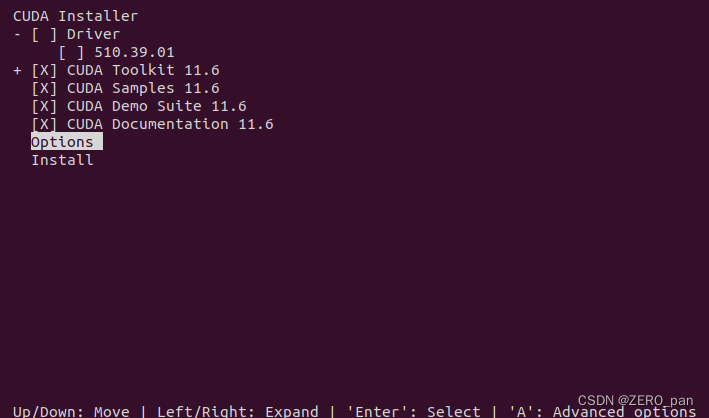
Options中是关于安装路径和链接的设置,我选择默认。
step4.环境变量的设置
安装完成后
cd /usr/local/
你将会看到cuda和cuda11.6,cuda是指向cuda11.6的链接。

如果你安装了多了cuda,比如cuda11.6和cuda11.7,那么需要使用cuda11.7时候把cuda这个文件指向cuda11.7,这个操作可能实在安装的时候帮你自动完成的。
设置环境变量
sudo gedit ~/.bashrc
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"
export PATH="/usr/local/cuda/bin:$PATH"
export CUDA_HOME="/usr/local/cuda:$CUDA_HOME"
保存退出后,你需要在每个终端进行刷新
source ~/.bashrc
或者重启你的电脑。
cudnn我们先不安装,等待TensorRT版本确定之后再根据TensorRT的要求的cudnn版本进行安装。如果不这样做,在使用TensorRT时会出现警报,我们最好避免。cudnn的按照将出现在TensorRT的安装章节中。
step5.验证
nvcc -V

Pytorch的安装
step1.安装Miniconda并创建环境用于pytorch的安装
链接: linux安装miniconda3
python版本,我选择3.8
step2.安装pytorch版本
链接: pytorch
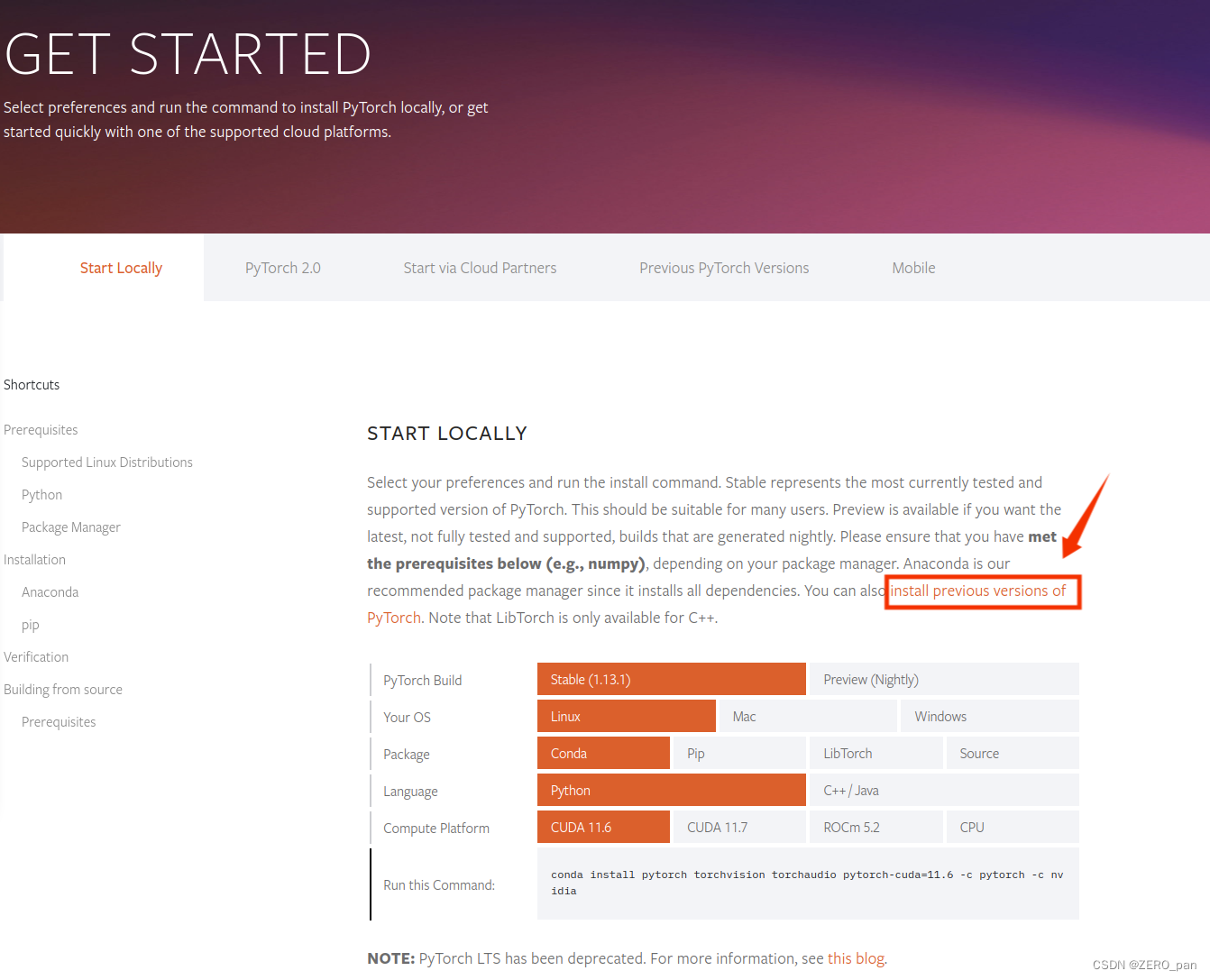
在这里你可以选择更多pytorch的版本,根据你所安装的cuda版本选择。
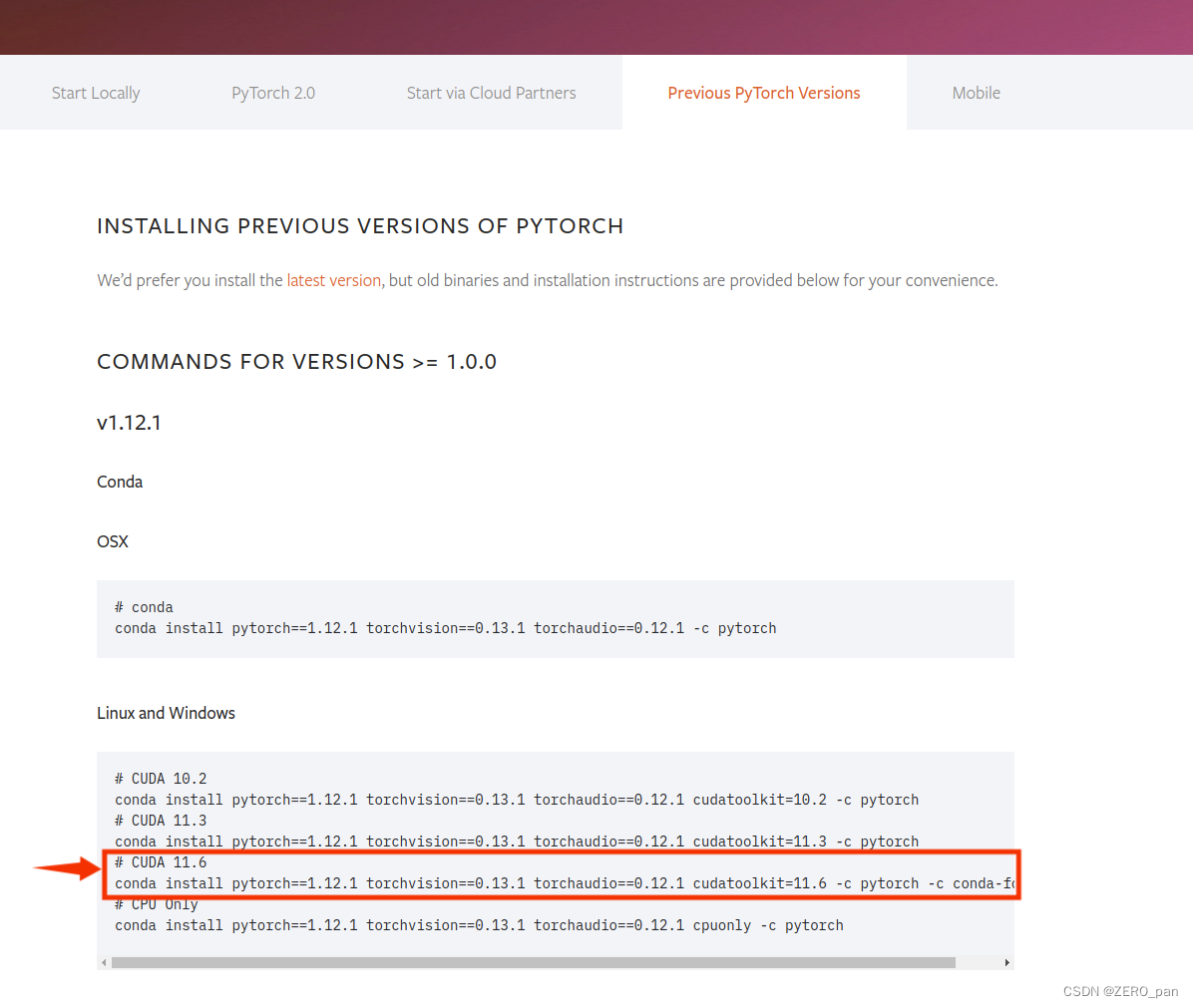
我选择的版本
1.12.0+cu116
TensorRT的安装
step1.下载TensorRT
链接: NVIDIA TensorRT Download
选择一个版本进行下载,注意确保这个版本所支持的CUDA与你的版本对应。
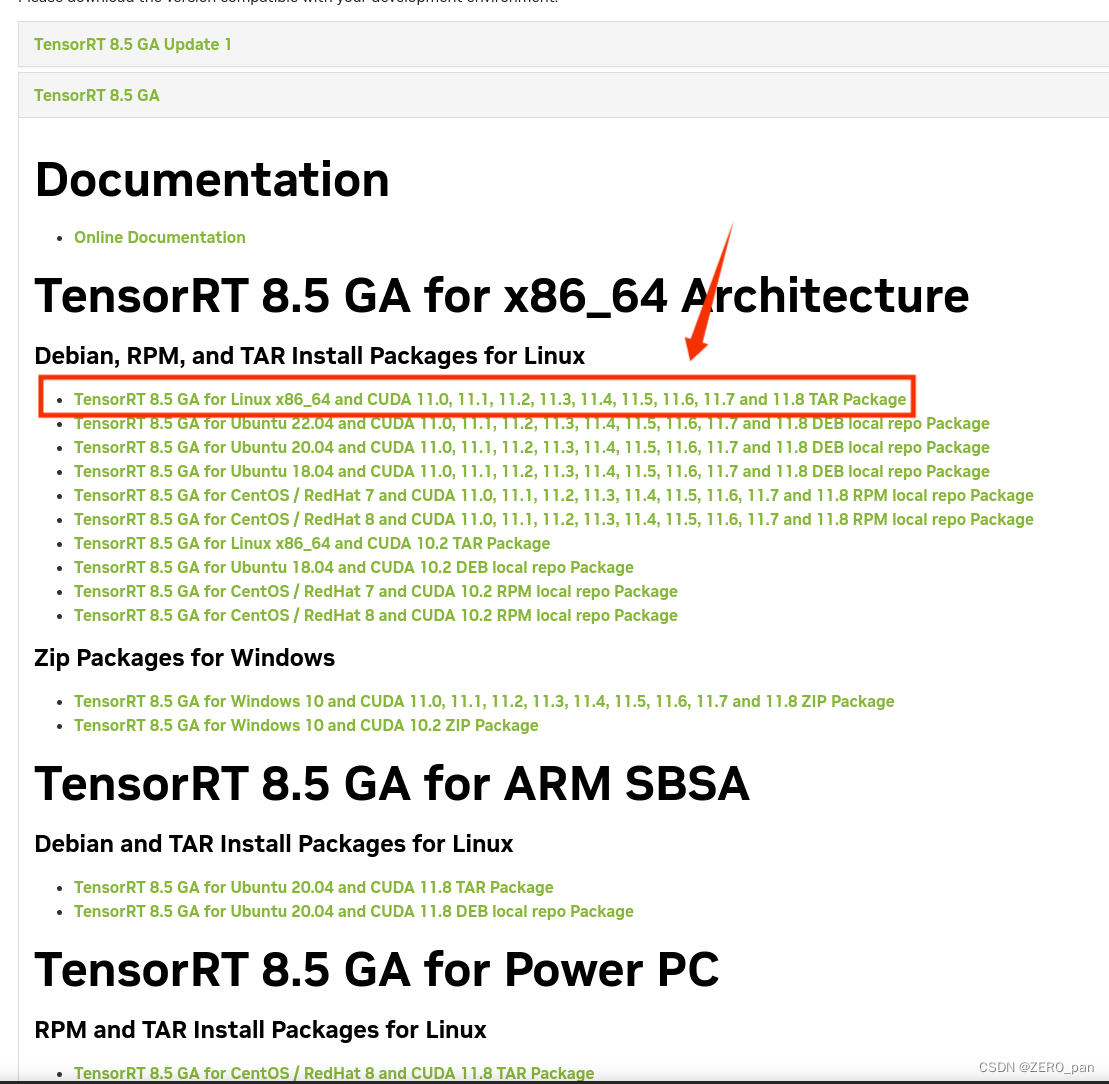
我的下载所得

下面我们去安装cudnn,TensorRTu要求按照的cudnn版本是8.6.
step2.cudnn的安装
链接: cuDNN Download
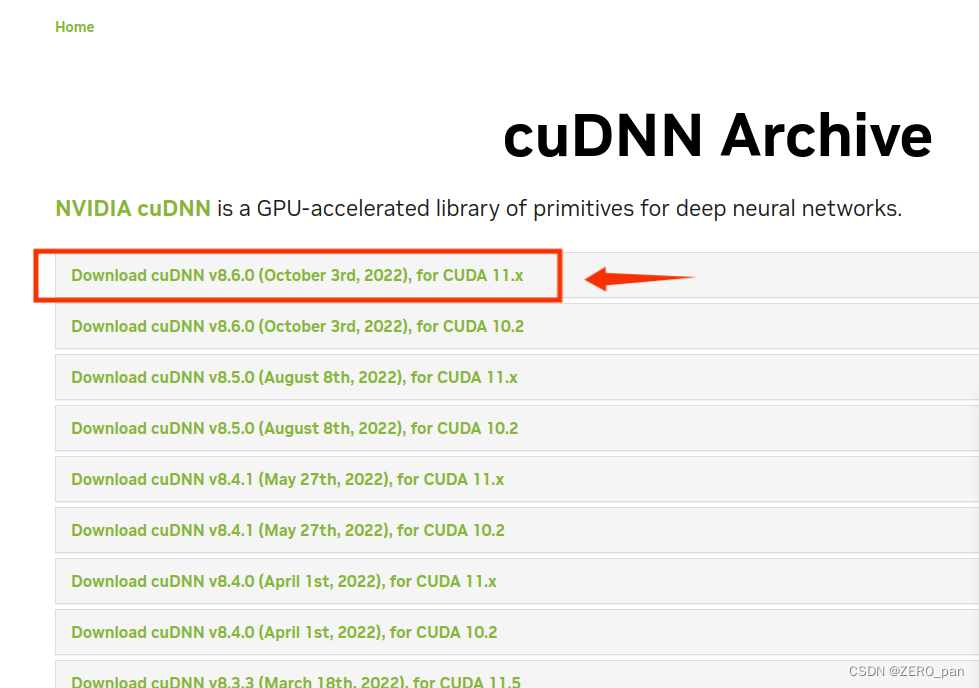
下载解压后你将得到

之后使用命令将include和lib中的文件复制到cuda-11.6的文件夹中,/usr/local/cuda-11.6

链接: Linux之cuda、cudnn安装及版本切换
sudo cp include/cudnn* /usr/local/cuda-11.6/include/
sudo cp lib/lib* /usr/local/cuda-11.6/lib64/
sudo chmod a+r /usr/local/cuda-11.6/include/cudnn* /usr/local/cuda-11.6/lib64/libcudnn*
step3.TensorRT-python的安装
切换到pytorch环境
conda activate pytorch
进入TensorRT-python的安装文件夹中

根据你的python版本按照
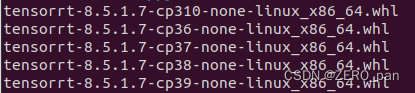
pip install tensorrt-8.5.1.7-cp38-none-linux_x86_64.whl
pip list

之后你的pytorch环境中才可以
import tensorrt as trt
打印环境信息
import torch
import cv2
import tensorrt
print(torch.__version__)# 1.12.1+cu116
print(torch.version.cuda)# 11.6
print(torch.backends.cudnn.version())# 8600
print(cv2.__version__)
print(tensorrt.__version__)
注意,cudnn版本的打印适合tensorrt有关的,如果你更新了cuda或者cudnn的版本,那么你需要重新安装pytorch环境中的tensorrt工具包。
torch.backends.cudnn.version()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









