







目录
建模实例简介
VMD-CNN-BiLSTM-Attention 是一种结合信号分解、深度学习和注意力机制的高性能预测模型,适用于复杂时间序列数据的分析与预测。
该模型首先通过变分模态分解(VMD)将原始信号分解为多个相对平稳的子模态,有效降低非线性和非平稳性干扰;随后利用卷积神经网络(CNN)提取各子模态的局部时空特征;再通过双向长短期记忆网络(BiLSTM)双向捕获序列的长期依赖关系;最后引入注意力机制(Attention)动态分配不同时间步和特征的重要性权重,增强关键信息的学习能力。
实验表明,该模型在金融、气象、能源等领域的预测任务中,相比单一模型或传统组合模型,在精度、鲁棒性和泛化性上均有显著提升,尤其适合处理高噪声、多尺度的复杂序列预测问题。
关键词:变分模态分解 · 卷积神经网络 · 双向LSTM · 注意力机制 · 时间序列预测
对于实例的代码逐句详解,详见另一篇博客:
1.应用场景
+ 金融领域
-
股票价格/汇率预测:分解高频噪声,捕捉市场趋势与突发事件的影响
-
风险管理:对波动性、极端事件(如暴跌)进行预警
+ 能源与工业
-
电力负荷预测:处理天气、节假日等多因素耦合的用电量波动
-
风电/光伏功率预测:解决可再生能源发电的间歇性与不稳定性问题
+ 气象与环境
-
气温/降水量预测:建模多尺度气象信号(如季风、短时强降雨)
-
空气质量指数(AQI)预测:关联污染物扩散的时空依赖性
+ 交通与物流
-
交通流量预测:融合周期性与突发拥堵模式(如节假日、事故)
-
货运需求预测:分析经济指标、季节性的非线性影响
2.关键数学概念补充
1. VMD(变分模态分解,Variational Mode Decomposition)
原理:
-
一种自适应信号分解方法,将原始时间序列分解为多个有限带宽的模态分量(IMF),每个IMF围绕一个中心频率振荡。
-
通过变分优化约束各模态的带宽和重构误差,避免传统方法(如EMD)的模态混叠问题。
在模型中的作用: -
预处理阶段降低原始数据的非平稳性和噪声,使后续网络更易捕捉有效特征。
2. CNN(卷积神经网络,Convolutional Neural Network)
原理:
-
通过卷积核滑动提取局部空间特征(如时间序列的短期趋势、突变点)。
-
池化层降低维度,保留关键信息。
在模型中的作用: -
对VMD分解后的每个子模态分别进行局部特征提取(如峰值、波动模式),形成高阶特征表示。
3. BiLSTM(双向长短期记忆网络,Bidirectional LSTM)
原理:
-
LSTM单元通过门控机制(输入门、遗忘门、输出门)解决长期依赖问题。
-
双向结构(前向+后向LSTM)同时捕捉时间序列的历史与未来上下文依赖。
在模型中的作用: -
整合CNN提取的特征,建模序列的全局时序规律(如周期、趋势)。
4. Attention(注意力机制)
原理:
-
通过计算不同时间步或特征的权重分布,动态聚焦关键信息(如突变时刻、重要模态)。
-
常用缩放点积注意力(Scaled Dot-Product Attention)。
在模型中的作用: -
抑制噪声干扰,增强对重要时间点或模态分量的建模能力,提升预测鲁棒性。
组合模型的协同优势
-
VMD:信号分解 → 降低复杂度
-
CNN:局部特征提取 → 捕捉细节
-
BiLSTM:时序依赖建模 → 理解全局规律
-
Attention:自适应加权 → 聚焦关键信息
模型构建原理
整体架构 ——
采用分解-重构-预测的范式:
-
VMD预处理:将原始电力负荷序列分解为多个IMF分量(本征模态函数)
-
分量并行预测:对每个IMF分量分别建立CNN-BiLSTM-Attention子模型
-
结果集成:将各分量预测结果相加得到最终预测值
核心组件功能 ——
-
CNN层(Conv1D + MaxPooling1D):
-
局部特征提取:通过卷积核捕捉短期时序模式
-
降维:减少参数量并增强特征鲁棒性
-
-
BiLSTM层:
-
双向时序建模:正向/反向LSTM捕捉长短期依赖关系
-
-
Attention机制:
-
动态权重分配:突出关键时间步的贡献
-
结构:Permute→Dense(softmax)→Multiply实现注意力加权
-
1.模型假设与约束条件
数据假设 ——
-
平稳性:VMD要求信号具有有限带宽的准平稳特性
-
线性可分性:IMF分量需满足线性叠加重构条件
-
时间相关性:n_in历史步长(5步)需包含预测的有效信息
模型约束 ——
-
输入维度:固定长度滑动窗口(n_in×or_dim)
-
归一化要求:必须使用MinMaxScaler统一量纲
-
计算资源:并行训练多个子模型需较高显存
2.核心数学原理
VMD分解 ——
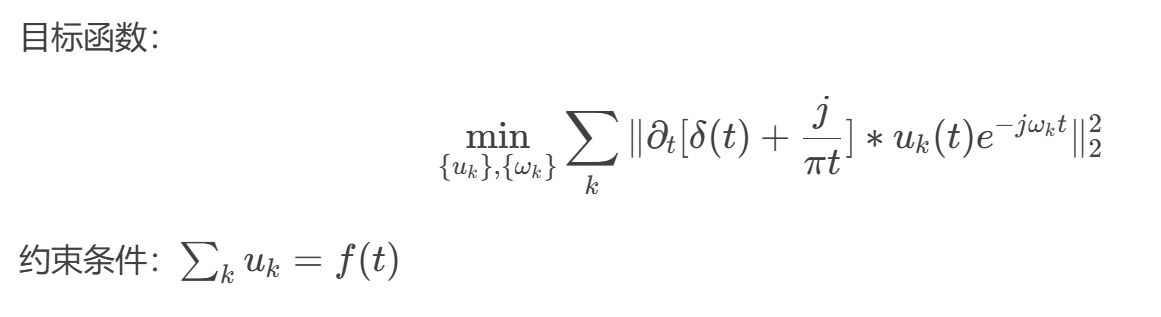
Attention机制 ——
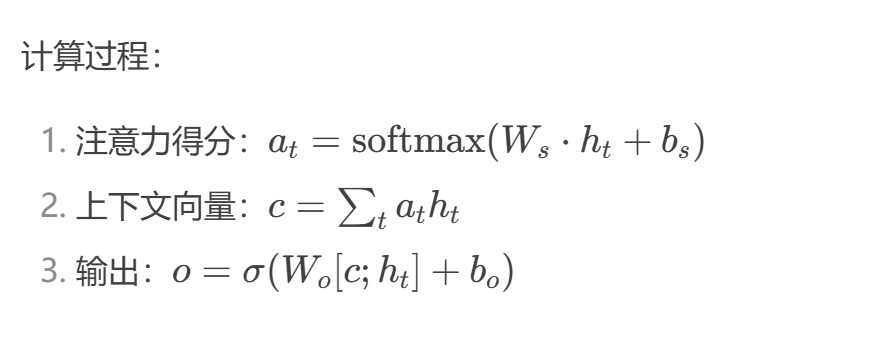
损失函数 ——
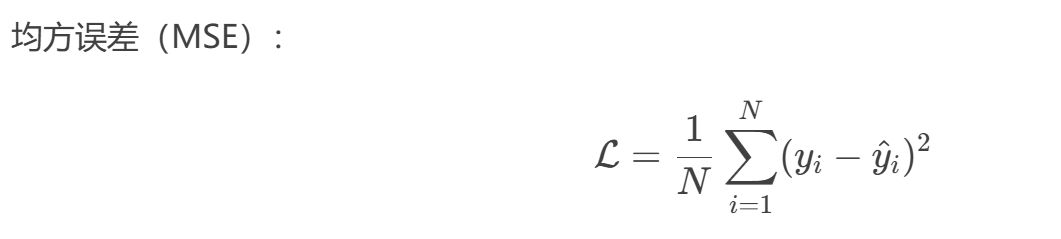
3.模型参数
数据参数
| 参数 | 取值 | 说明 |
|---|---|---|
n_in | 5 | 历史时间步数 |
n_out | 1 | 预测步长 |
or_dim | values.shape[1] | 原始特征维度 |
scroll_window | 1 | 滑动步长 |
模型参数
| 组件 | 参数 | 取值 | 作用 |
|---|---|---|---|
| CNN | filters | 64 | 卷积核数量 |
| kernel_size | 2 | 卷积窗口大小 | |
| BiLSTM | units | 128 | 隐藏层神经元数 |
| Attention | Dense units | time_steps | 时间步注意力维度 |
训练参数
| 参数 | 取值 | 说明 |
|---|---|---|
| batch_size | 32 | 小批量梯度下降 |
| epochs | 50 | 训练轮次 |
| validation_split | 0.25 | 验证集比例 |
| optimizer | Adam | 自适应学习率 |
算法实现
1.伪代码
# 1. 数据预处理阶段
FUNCTION preprocess(data_path):
# 加载原始数据
raw_data = LOAD_CSV(data_path)
vmd_components = LOAD_EXCEL("VMD.xlsx") # VMD分解结果
# 数据标准化
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(raw_data)
# 滑动窗口构造
FUNCTION create_dataset(data, n_in, n_out):
X, Y = [], []
FOR i FROM 0 TO len(data)-n_in-n_out:
X.append(data[i:i+n_in]) # 输入窗口
Y.append(data[i+n_in:i+n_in+n_out]) # 输出窗口
RETURN (array(X), array(Y))
RETURN (scaled_data, vmd_components)
# 2. VMD-CNN-BiLSTM-Attention模型
FUNCTION build_model(input_shape):
inputs = Input(shape=input_shape)
# CNN特征提取
cnn = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
cnn = MaxPooling1D(pool_size=2)(cnn)
# BiLSTM时序建模
reshaped = Reshape((cnn.shape[1], cnn.shape[2]*cnn.shape[3]))(cnn)
bilstm = Bidirectional(LSTM(128, return_sequences=True))(reshaped)
# Attention机制
attention = Permute((2,1))(bilstm)
attention = Dense(bilstm.shape[1], activation='softmax')(attention)
attention = Permute((2,1))(attention)
weighted_output = Multiply()([bilstm, attention])
# 输出层
flattened = Flatten()(weighted_output)
outputs = Dense(n_out)(flattened)
RETURN Model(inputs, outputs)
# 3. 训练与预测流程
FUNCTION main():
# 数据准备
raw_data, vmd_components = preprocess("电力负荷预测数据2.csv")
# 分量并行训练
predictions = []
FOR EACH imf IN vmd_components.T: # 遍历每个IMF分量
# 合并原始特征与IMF分量
combined_data = CONCATENATE(raw_data[:,:-1], imf)
X, Y = create_dataset(combined_data, n_in=5, n_out=1)
# 构建并训练模型
model = build_model(X.shape[1:])
model.fit(X, Y, epochs=50, batch_size=32)
# 预测当前分量
predictions.append(model.predict(X_test))
# 结果集成
final_prediction = SUM(predictions) # 各分量预测结果相加
# 评估
calculate_metrics(Y_test, final_prediction)
# 执行入口
IF __name__ == "__main__":
main()2.编码思路
编码思路说明 ——
1. 数据流设计
-
分层处理:采用"数据预处理→分量训练→结果集成"的三段式架构
-
滑动窗口:通过
create_dataset函数实现时序样本的滚动构造 -
维度对齐:使用Reshape层确保CNN输出与BiLSTM输入维度兼容
2. 关键实现技巧
-
VMD集成:
-
将原始特征与每个IMF分量拼接(
CONCATENATE操作) -
各分量模型独立训练避免交叉干扰
-
-
注意力机制实现:
-
通过两次Permute调整维度顺序
-
Softmax归一化生成时间步权重
-
Multiply层实现特征加权
-
-
并行化处理:
-
使用循环并行训练多个IMF分量模型
-
预测结果通过
SUM实现线性重构
-
3. 工程化考虑
-
内存优化:按需加载数据分块(适合大数据场景)
-
可扩展性:通过
input_shape参数支持不同尺寸输入 -
评估模块化:独立评估函数支持灵活指标扩展
代码实现与注释
对于实例的代码逐句详解,详见另一篇博客:
完整代码
import os
import math
import pandas as pd
import openpyxl
from math import sqrt
from numpy import concatenate
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from sklearn.metrics import mean_squared_error, mean_absolute_error,r2_score
from pandas import DataFrame
from pandas import concat
import keras.backend as K
from scipy.io import savemat, loadmat
from sklearn.neural_network import MLPRegressor
from keras.callbacks import LearningRateScheduler
from tensorflow.keras import Input, Model, Sequential
import mplcyberpunk
from qbstyles import mpl_style
import warnings
from prettytable import PrettyTable #可以优美的打印表格结果
from keras.layers import Dense, Activation, Dropout, LSTM, Bidirectional, LayerNormalization, Input
from tensorflow.keras.models import Model
warnings.filterwarnings("ignore")
dataset=pd.read_csv("电力负荷预测数据2.csv",encoding='gb2312')
print(dataset)#显示dataset数据
dataset_vmd = pd.read_excel("VMD.xlsx")
values_vmd = dataset_vmd.values
values_vmd = values_vmd.astype('float32')
values = dataset.values[:,1:] #只取第2列数据,要写成1:2;只取第3列数据,要写成2:3,取第2列之后(包含第二列)的所有数据,写成 1:
values = values.astype('float32')
def data_collation(data, n_in, n_out, or_dim, scroll_window, num_samples):
res = np.zeros((num_samples,n_in*or_dim+n_out))
for i in range(0, num_samples):
h1 = data[scroll_window*i: n_in+scroll_window*i,0:or_dim]
h2 = h1.reshape( 1, n_in*or_dim)
h3 = data[n_in+scroll_window*(i) : n_in+scroll_window*(i)+n_out,-1].T
h4 = h3[np.newaxis, :]
h5 = np.hstack((h2,h4))
res[i,:] = h5
return res
def attention_layer(inputs, time_steps):
# 自定义的注意力机制层
a = Permute((2, 1))(inputs) # 将特征维度和时间步维度互换
a = Dense(time_steps, activation='softmax')(a) # 使用Dense层计算时间步的权重
a_probs = Permute((2, 1), name='attention_vec')(a) # 再次互换维度,使其与原始输入对齐
output_attention_mul = Multiply()([inputs, a_probs]) # 将注意力权重应用到输入上
return output_attention_mul
def cnn_bilstm_attention_model():
# 定义一个包含CNN, LSTM和注意力机制的模型
inputs = Input(shape=(vp_train.shape[1], vp_train.shape[2]))
conv1d = Conv1D(filters=64, kernel_size=2, activation='relu')(inputs)
maxpooling = MaxPooling1D(pool_size=2)(conv1d)
reshaped = Reshape((-1, 64 * maxpooling.shape[1]))(maxpooling) # 重塑形状以适应LSTM层
lstm_out = Bidirectional(LSTM(128, return_sequences=True))(reshaped) # LSTM层
attention_out = attention_layer(lstm_out, time_steps=reshaped.shape[1]) # 注意力机制层
attention_flatten = Flatten()(attention_out) # 展平输出以适应全连接层
outputs = Dense(vt_train.shape[1])(attention_flatten) # 全连接层
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='Adam')
model.summary()
return model
#定义输入和输出
n_in = 5 # 输入前5行的数据
n_out = 1 # 预测未来1步的数据
or_dim = values.shape[1] # 记录特征数据维度
num_samples = 2000 # 可以设定从数据中取出多少个点用于本次网络的训练与测试。
scroll_window = 1 #如果等于1,下一个数据从第二行开始取。如果等于2,下一个数据从第三行开始取
n_train_number = int(num_samples * 0.85) #取出85%作为训练集,剩余的为测试集
n_test_number = num_samples - n_train_number #测试集数量
predicted_data =[]
actual_data = []
# In[7]:
for vmd_num in range (0,len(values_vmd[0])):
imf = values_vmd[:,vmd_num]
imf = imf.reshape(-1,1)
combined_data = np.hstack((values[:,0:-1],imf)) # 把VMD分解的每列数据与原始数据特征列组合到一起
res = data_collation(combined_data, n_in, n_out, or_dim, scroll_window, num_samples)
# 把数据集分为训练集和测试集
combined_data = np.array(res)
# 将前面处理好的DataFrame(combined_data)转换成numpy数组,方便后续的数据操作。
n_train_number = int(num_samples * 0.85)
Xtrain = combined_data[:n_train_number, :n_in*or_dim]
Ytrain = combined_data[:n_train_number, n_in*or_dim:]
Xtest = combined_data[n_train_number:, :n_in*or_dim]
Ytest = combined_data[n_train_number:, n_in*or_dim:]
# 归一化
m_in = MinMaxScaler()
vp_train = m_in.fit_transform(Xtrain) # 注意fit_transform() 和 transform()的区别
vp_test = m_in.transform(Xtest) # 注意fit_transform() 和 transform()的区别
m_out = MinMaxScaler()
vt_train = m_out.fit_transform(Ytrain) # 注意fit_transform() 和 transform()的区别
vt_test = m_out.transform(Ytest) # 注意fit_transform() 和 transform()的区别
vp_train = vp_train.reshape((vp_train.shape[0], n_in, or_dim))
vp_test = vp_test.reshape((vp_test.shape[0], n_in, or_dim))
model = cnn_bilstm_attention_model()
model.fit(vp_train, vt_train, batch_size=32, epochs=50, validation_split=0.25, verbose=2)
yhat = model.predict(vp_test)
yhat = yhat.reshape(num_samples-n_train_number, n_out)
yy = m_out.inverse_transform(yhat) # 反归一化
predicted_data.append(yy)
actual_data.append(Ytest)
pre_test = []
for i in range(0, len(predicted_data[0])):
sum = 0
for j in range(0, len(predicted_data)):
sum = sum + predicted_data[j][i]
pre_test.append(sum)
pre_test = np.array(pre_test)
res = data_collation(values, n_in, n_out, or_dim, scroll_window, num_samples)
values = np.array(res)
actual_test = values[n_train_number:, n_in*or_dim:]
actual_test = actual_test.reshape(num_samples-n_train_number, n_out)
def mape(y_true, y_pred):
# 定义一个计算平均绝对百分比误差(MAPE)的函数。
record = []
for index in range(len(y_true)):
# 遍历
temp_mape = np.abs((y_pred[index] - y_true[index]) / y_true[index])
# 计算MAPE
record.append(temp_mape)
# 将MAPE添加到记录列表中。
return np.mean(record) * 100
# 返回所有记录的平均值,乘以100得到百分比。
def evaluate_forecasts(Ytest, predicted_data, n_out):
mse_dic = []
rmse_dic = []
mae_dic = []
mape_dic = []
r2_dic = []
table = PrettyTable(['测试集指标','MSE', 'RMSE', 'MAE', 'MAPE','R2'])
for i in range(n_out):
actual = [float(row[i]) for row in Ytest] #一列列提取
predicted = [float(row[i]) for row in predicted_data]
mse = mean_squared_error(actual, predicted)
mse_dic.append(mse)
rmse = sqrt(mean_squared_error(actual, predicted))
rmse_dic.append(rmse)
mae = mean_absolute_error(actual, predicted)
mae_dic.append(mae)
MApe = mape(actual, predicted)
mape_dic.append(MApe)
r2 = r2_score(actual, predicted)
r2_dic.append(r2)
if n_out == 1:
strr = '预测结果指标:'
else:
strr = '第'+ str(i + 1)+'步预测结果指标:'
table.add_row([strr, mse, rmse, mae, str(MApe)+'%', str(r2*100)+'%'])
return mse_dic,rmse_dic, mae_dic, mape_dic, r2_dic, table
mse_dic,rmse_dic, mae_dic, mape_dic, r2_dic, table = evaluate_forecasts(actual_test, pre_test, n_out)
print(table)#显示预测指标数值
## 结果图绘制
from matplotlib import rcParams
config = {
"font.family": 'serif',
"font.size": 10,# 相当于小四大小
"mathtext.fontset": 'stix',#matplotlib渲染数学字体时使用的字体,和Times New Roman差别不大
"font.serif": ['Times New Roman'],#Times New Roman
'axes.unicode_minus': False # 处理负号,即-号
}
rcParams.update(config)
plt.ion()
for ii in range(n_out):
plt.rcParams['axes.unicode_minus'] = False
plt.style.use('cyberpunk')
plt.figure(figsize=(10, 2), dpi=300)
x = range(1, len(actual_test) + 1)
plt.xticks(x[::int((len(actual_test)+1))])
plt.tick_params(labelsize=5) # 改变刻度字体大小
plt.plot(x, pre_test[:,ii], linestyle="--",linewidth=0.5, label='predict')
plt.plot(x, actual_test[:,ii], linestyle="-", linewidth=0.5,label='Real')
plt.rcParams.update({'font.size': 5}) # 改变图例里面的字体大小
plt.legend(loc='upper right', frameon=False)
plt.xlabel("Sample points", fontsize=5)
plt.ylabel("value", fontsize=5)
if n_out == 1: #如果是单步预测
plt.title(f"The prediction result of VMD-CNN-BiLSTM-Attention :\nMAPE: {mape(actual_test[:, ii], pre_test[:, ii])} %")
else:
plt.title(f"{ii+1} step of VMD-CNN-BiLSTM-Attention prediction\nMAPE: {mape(actual_test[:,ii], pre_test[:,ii])} %")
plt.ioff()
plt.show()
















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









