







 文章讲述了如何使用Dify框架进行大模型应用开发,包括接入大模型、搭建在线服务、编写FastAPI代码以及设计工作流和Prompt。着重展示了通过Dify实现文字处理和表格生成的实际步骤。
文章讲述了如何使用Dify框架进行大模型应用开发,包括接入大模型、搭建在线服务、编写FastAPI代码以及设计工作流和Prompt。着重展示了通过Dify实现文字处理和表格生成的实际步骤。
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
文章目录
Dify框架
Didy是一个开源的 LLM 应用开发平台。
本文以文字识别、文字整合、表格填入三步功能组合的铭牌信息提取功能为例,介绍Dify框架在多模态大模型开发的基本流程。
多模态大模型实现这一功能,相比于传统的OCR系统,其 通用性更强、开发更快、模型对抽取结果的后处理能力更优秀。
使用示例
本案例实现路径:
- 输入:图像
- 处理过程:文字提取、矫正、信息整合
- 输出:json数据及整理后的excel表格文件
- 注意:excel表格文件生成功能需搭建一个在线的服务(很简单)
步骤1:Dify大模型能力接入
首先在设定界面接入智谱AI的API,当然此处不限大模型厂家,只要具备多模态能力的大模型均可,离线模型如OmniLMM等亦可。


上图中glm-4v即具备视觉能力的多模态大模型。
步骤2:在线服务
该服务是为了服务于excel表格生成后,为用户提供的下载功能。
即大模型返回一个链接,通过该链接用户可下载大模型所生成的excel文件。
只需要在服务器启动服务,语句如下:
python -m http.server 9707
注,9707为端口,注意该服务不要和其他服务端口冲突。
步骤3:代码
from fastapi import FastAPI, HTTPException, Depends
from typing import List, Optional
import re
import json
import datetime
import pandas as pd
from pydantic import BaseModel
app = FastAPI()
def post_processing(input_data):
# 使用正则表达式匹配{}之间的内容
pattern = r'{(.*?)}'
match = re.search(pattern, input_data, re.DOTALL)
# 匹配后做数据后处理
if match:
match = '{' + match.group(1) + '}'
json_str = match.replace('\n', '').replace(',}', '}')
return json_str
else:
return str({'error':'llm out error!'})
@app.get("/generate")
def get_table(input_str = Depends(post_processing)):
# 将字符串转换为字典
data_dict = json.loads(input_str)
for k, v in data_dict.items():
if type(v) == list:
data_dict[k] = [' '.join(v)]
else:
data_dict[k] = [v]
df_json = pd.DataFrame(data_dict)
# 读取excel文件
df_excel = pd.read_excel('/home/gputest/lyq/py_file/result.xlsx', engine='openpyxl')
# 将json数据追加到excel的DataFrame中(这里简单地追加到末尾)
# 注意:你可能需要根据你的数据结构和需求调整这一步
df_excel = pd.concat([df_excel, df_json], ignore_index=True)
# 保存修改后的excel文件
# 获取当下时间并format
formatted_time = str(datetime.datetime.now().strftime("%Y_%m_%d_%H%M%S"))
df_excel.to_excel(formatted_time+'.xlsx', index=False, engine='openpyxl')
return 'http://172.19.138.52:9707/'+formatted_time+'.xlsx'
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="172.19.138.52", port=3000)
上述代码中
return ‘http://172.19.138.52:9707/’+formatted_time+‘.xlsx’
这一语句是配合步骤2生成下载链接的。
其他代码,则是对大模型整合的json代码做后处理和表格对齐填充工作,之后发布为一个可访问调用的API业务。
步骤4:Dify项目构建——python功能API引入
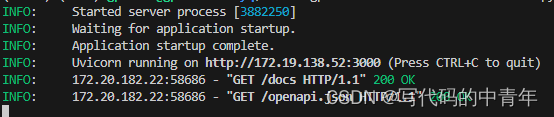
运行服务成功如下所示:

运行API成功如下所示:
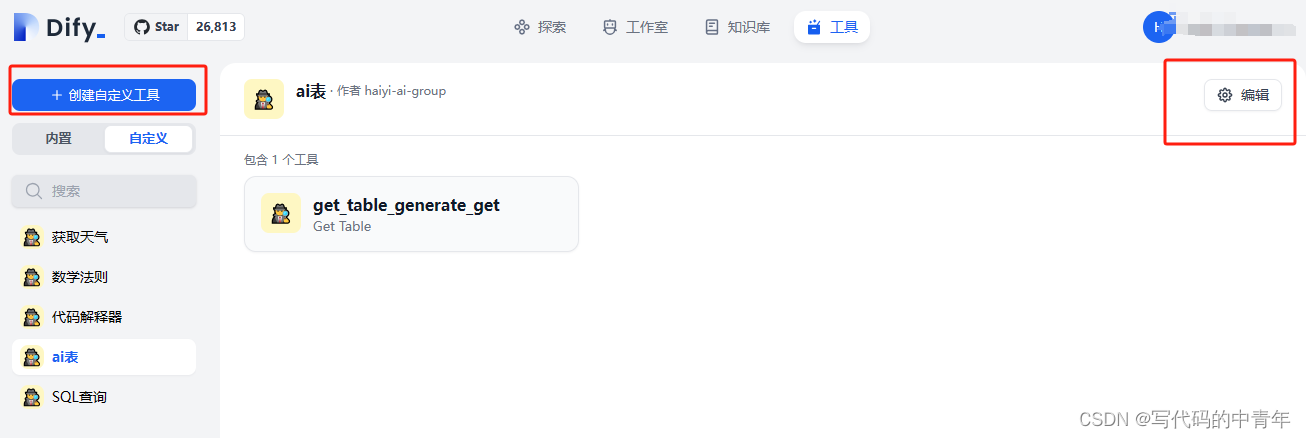
进入Dify,找到工具页面自定义工具:
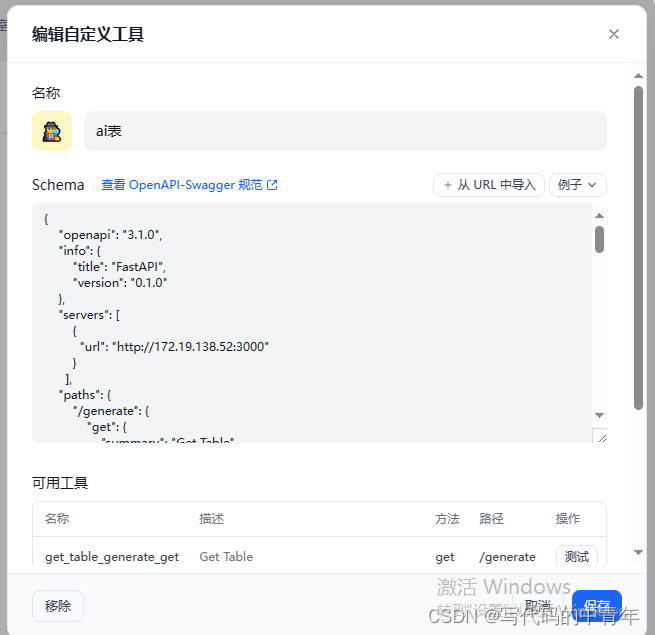
在schema中填入API对应内容:
Schema:
{
"openapi": "3.1.0",
"info": {
"title": "FastAPI",
"version": "0.1.0"
},
"servers": [
{
"url": "http://172.19.138.52:3000"
}
],
"paths": {
"/generate": {
"get": {
"summary": "Get Table",
"operationId": "get_table_generate_get",
"parameters": [
{
"required": true,
"schema": {
"title": "Input Data"
},
"name": "input_data",
"in": "query"
}
],
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {}
}
}
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
}
}
}
}
}
},
"components": {
"schemas": {
"HTTPValidationError": {
"properties": {
"detail": {
"items": {
"$ref": "#/components/schemas/ValidationError"
},
"type": "array",
"title": "Detail"
}
},
"type": "object",
"title": "HTTPValidationError"
},
"ValidationError": {
"properties": {
"loc": {
"items": {
"anyOf": [
{
"type": "string"
},
{
"type": "integer"
}
]
},
"type": "array",
"title": "Location"
},
"msg": {
"type": "string",
"title": "Message"
},
"type": {
"type": "string",
"title": "Error Type"
}
},
"type": "object",
"required": [
"loc",
"msg",
"type"
],
"title": "ValidationError"
}
}
}
}
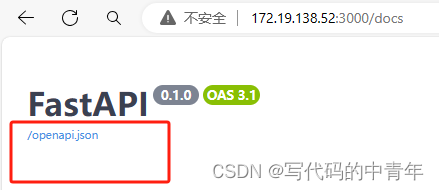
上述内容获取方式:

步骤3中启动了API服务,访问172.19.138.52:3000/docs即可点击下图红框获取。
步骤5:Dify项目构建——工作流串接及Prmpot设计
构建工作流如下:

部分细节(prompt、多模态配置、前后输入)如下:
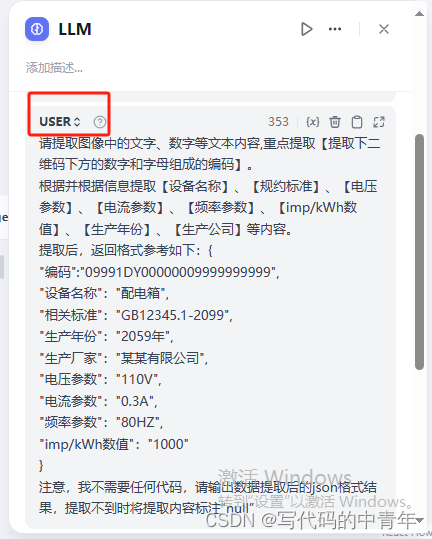
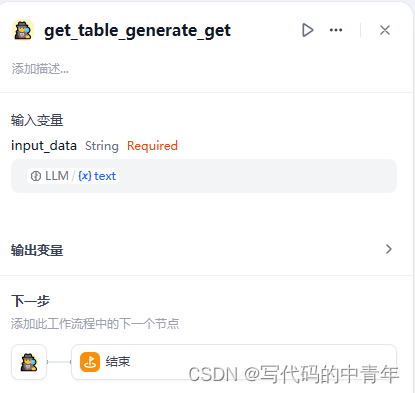
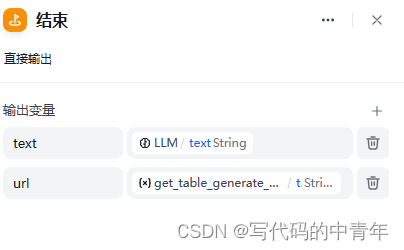
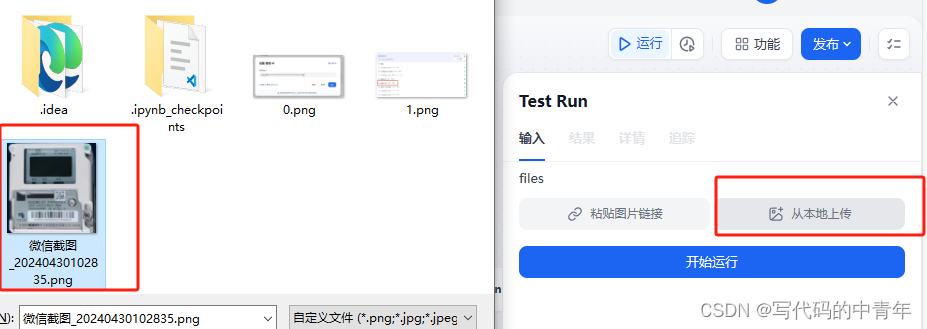
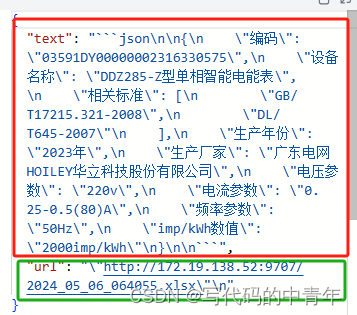
最后,该服务即可搭建为一个API或url聊天链接,测试结果如下:
输入图片:




















 2580
2580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











