







大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
Dify框架
用一句话介绍Dify,我想引用Dify官网的介绍。
比 LangChain 更易用。
众所周知,Langchin是大模型应用开发框架中较早、传播较广、功能集成较多的一个大模型应用开发框架,不少人的大模型研究工作都从langchain开始。
最近犹豫研发需求增加,开发难度提升,langchain框架的开发效率已经不太能满足公司研发团队需求,因此我们另辟蹊径,找到了Dify。
Didy是一个开源的 LLM 应用开发平台。提供从AI workflow 编排、 Agent 构建、Prompt工程、RAG 检索、在线信息接入、多模态能力接入、模型管理等大模型性能提升技术,能够使开发者轻松引入COT、回馈机制、few-shot等大模型性能提升技巧,构建 生成式 AI 原生应用。
可见,Dify已经能够比较全面地覆盖本系列文章之前提到的种种大模型开发技术和技巧,虽然与理想大模型平台有所差距【缺少数据侧模块(数据抓取、数据处理等功能点)和模型侧模块(微调数据集构建、模型微调等功能点)】,但在系统开发侧已经足够优秀。
尤其是,Dify的开发模型属于敏捷开发,可拖拽式构建大模型应用,上手门槛低、开发效率高。
使用示例
本文以一个在线数据引入和RAG项目为例,介绍Dify开发使用。
部署安装
Dify已于github开源
https://github.com/langgenius/dify
拉到项目后,根据项目教程用docker快速部署即可。
且需要根据项目教程配置环境参数。
基本功能
启动网页服务:

登陆账号

可见,dy开发十分简洁,主要功能有:
位于左上角的:空白应用开发、模板开发
位于页面中间顶部的:探索、工作室、工具

其中,从模板开发预定义如下:

可见典型的生成任务、知识库任务、智能体应用任务、工作流编排等等,Dify均提供了应用构建模板。

选择一个模板后顶一下应用名称和描述即可开始设计,如下图所示,其主要是分为节点和关联线两个部分,均可增删改。

比如节点增添可如下所示:




模型配置
在开发大模型服务时,需为框架配置好可用的大模型服务。
入口在如下位置:
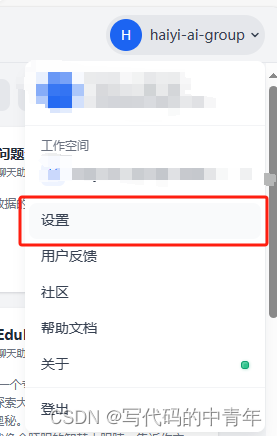
点击后可见界面如下:
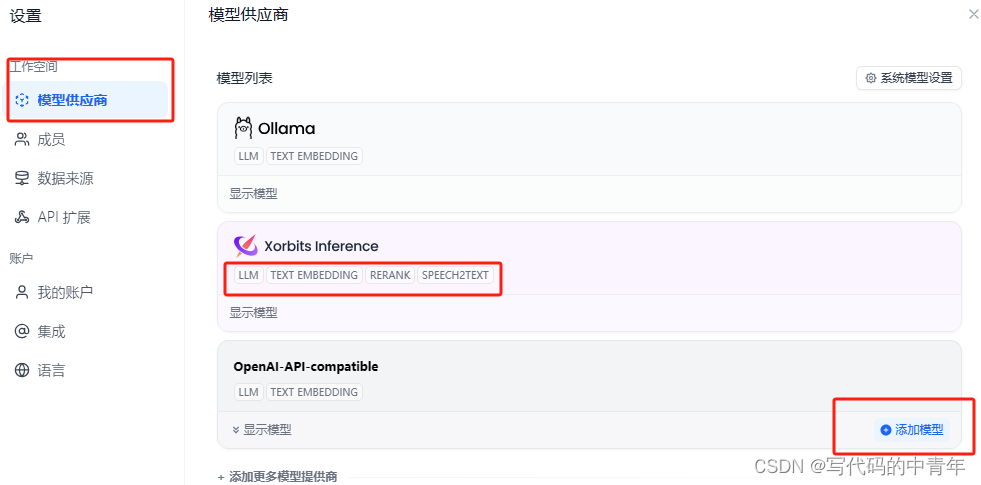
可见,dify支持ollama、OpenAI API等等格式的 模型接入方式(可自行添加更多、自定义更多)。此外,不同模型推理框架还对应词嵌入模型、大语言模型、重排模型等等。最后,模型返回结果格式也和其加载框架有关。此处不多赘述。
本文采用OpenAI API格式的形式进行大模型接入(以kimi chat逆向为例)。
具体流程如下:
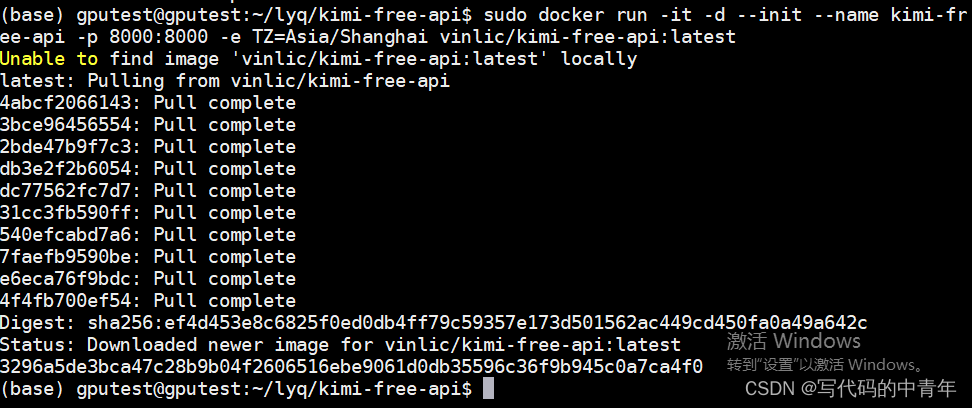
在本地部署kimi-free-api项目
https://github.com/LLM-Red-Team/kimi-free-api
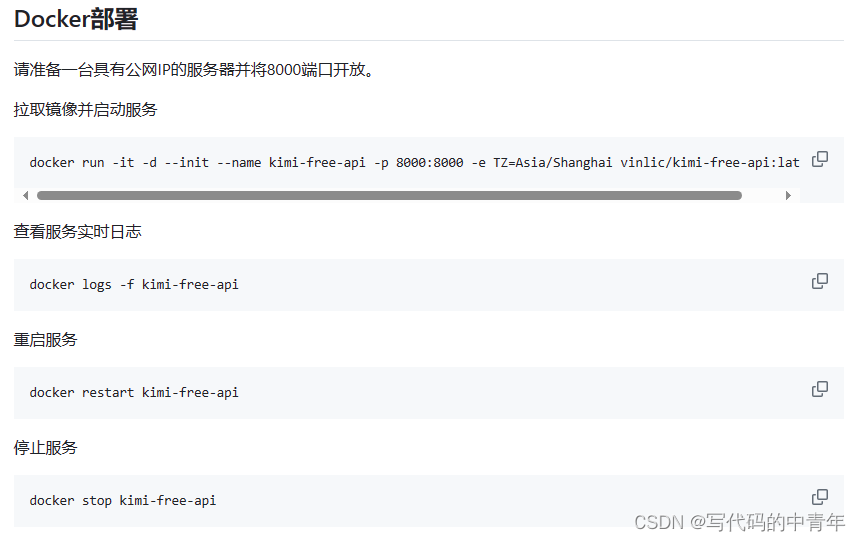
按指令docker部署环境
在dify的OpenAI界面下配置相关参数
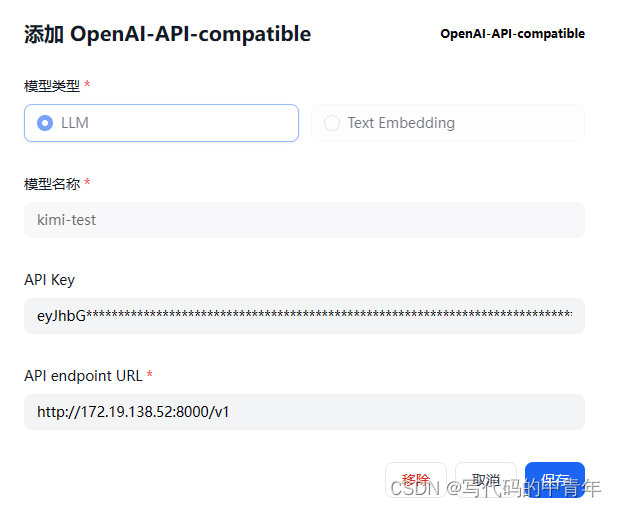
其中API KEY为kimi-free-api项目所提及的refresh_token,依据教程在kimi-chat页面F12开发者模式下即可获取。
注意,模型可用性检测
下述代码:
import requests
import json
# 定义发送请求的函数
def send_request(question):
url = 'http://172.19.138.52:8000/v1/chat/completions'
data = {
"model": "kimi-test",
"messages": [
{
"role": "user",
"content": question
}
],
"conversation_id": "cnndivilnl96vah411dg",
"use_search": 'true',
"stream": 'false'
}
json_data = json.dumps(data)
response = requests.post(url,
data=json_data,
headers={
"Content-Type": "application/json",
'Authorization': f'Bearer eyJhbGciOi'
}
)
response_text = response.text
return response_text
# test
result = send_request('你好,请介绍一下大数据局?')
answer = result
print(answer)
上述代码配合linux上的docker api后台即可检测模型服务是否有用,如有用,则显示如下:
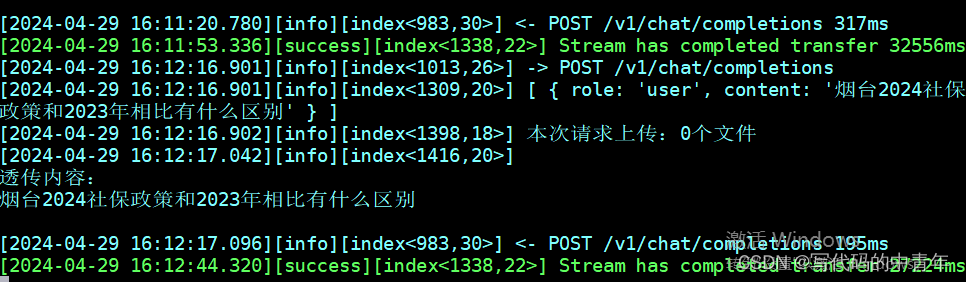
流程开发
本次设计总体流程如下:
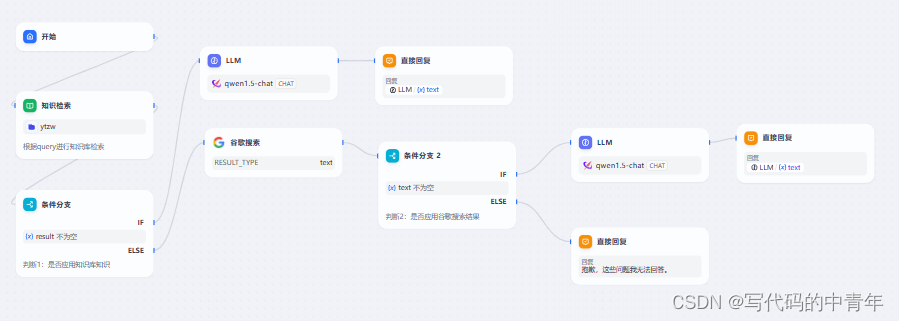
易知道,本次设计主要是一个RAG结合在线信息检索的项目。具体地,大模型依据输入后知识库检索结果进行判断,检索到信息后输入给大模型进行总结,是一条典型RAG路径;若未检索到符合阈值要求的知识库信息,则传入谷歌搜索界面进行信息检索,将检索信息及初始query传入LLM进行总结,这是一条AI信息检索路径;最后若检索结果不合要求,服务则输出指定内容。
知识检索节点
在全流程中,设计对知识库相关配置,如下:
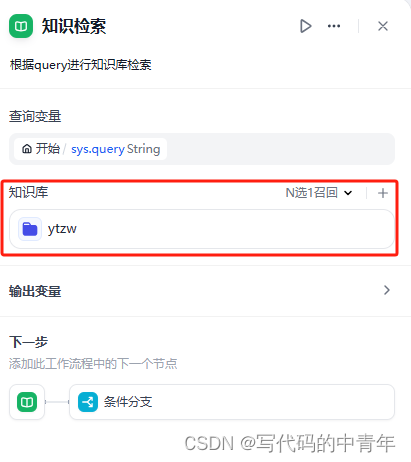
从上图所示区域即可设定输入query变量及所需查询知识库、查询知识库模型。
预设知识库流程如下:
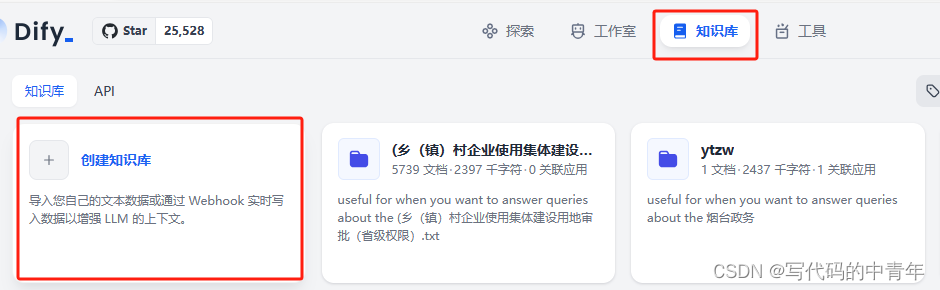
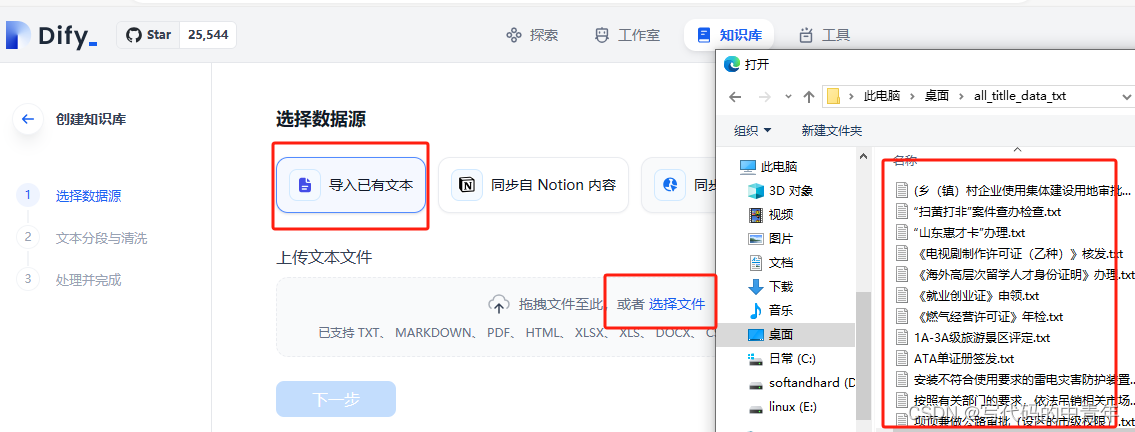
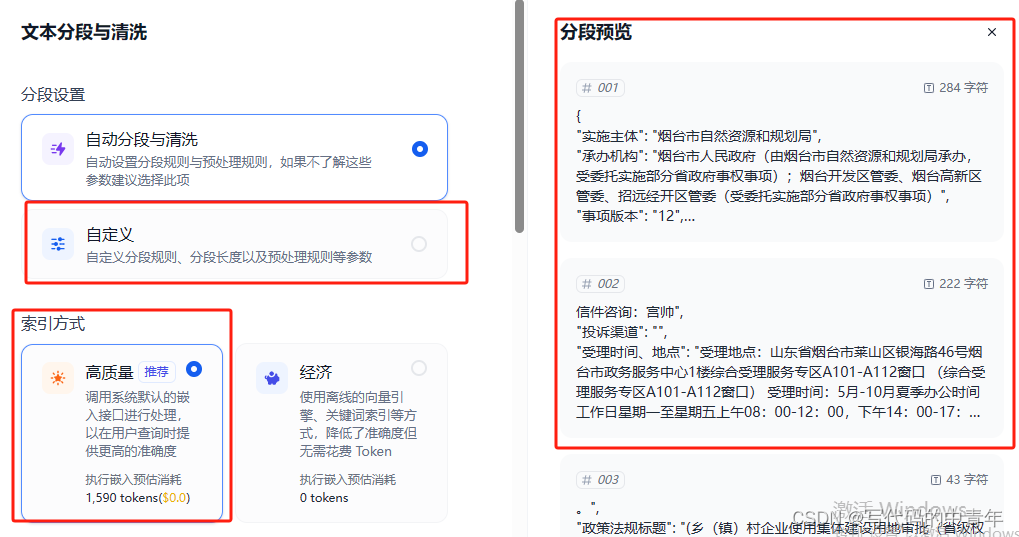
分割策略需对具体数据集做适配,我个人推荐自定义模式配合数据处理脚本进行,此处不做赘述。
还要再写一份技术方案意思是还需要写一个正在研发的,还没有完成的。
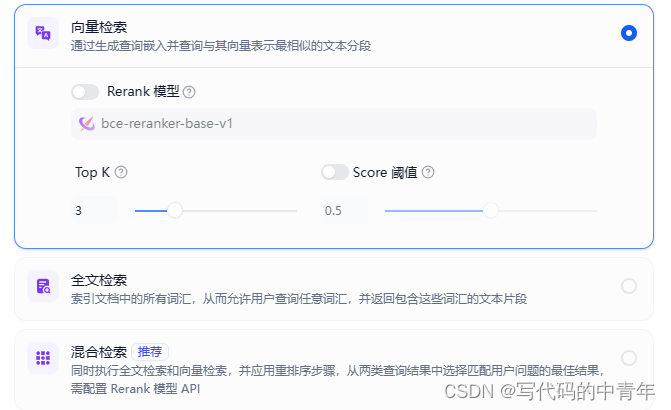
此处我推荐向量检索形式,topk以及阈值自行根据问答效果进行适配。
分支节点
此处分支节点,即条件判断、代码执行以及问题分类器三个节点。
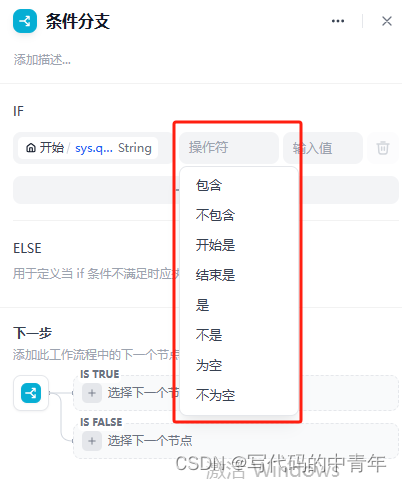
条件分支功能较为有限
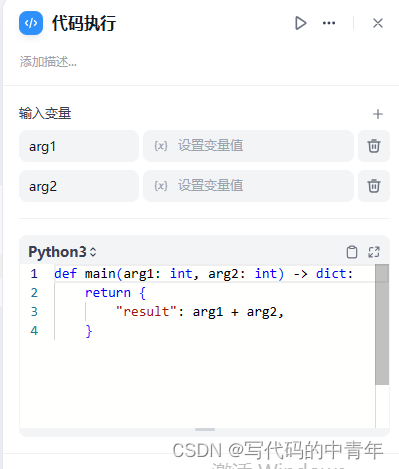
代码执行完全可以利用python语言设计复杂的功能和逻辑判断
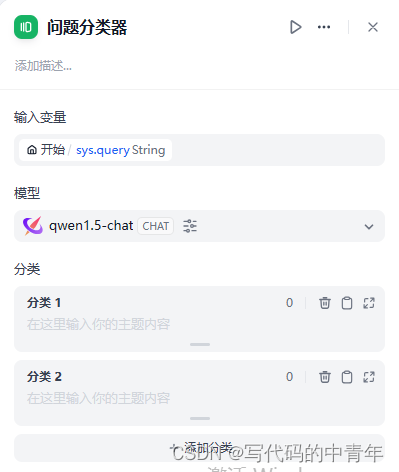
问题分类器则是依据大模型能力对问题进行分析选择不同地后续路径,其本质是Agent组的思想。需配置输入、分类以及所用模型。
模型节点
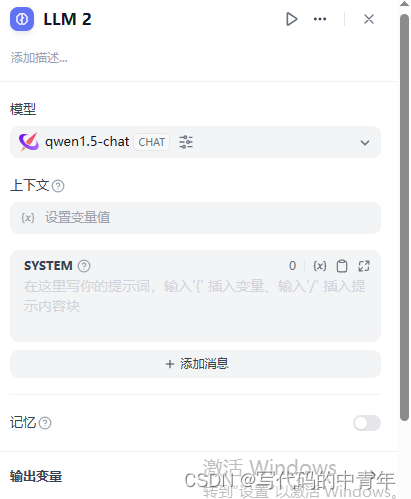
模型节点需配置所用模型、prompt、输入变量、是否多轮等参数,cot、few-shot等等技巧可在此进行应用。
HTTP节点

该节点可通过http请求实现附加功能。也可以通过对url post的方式实现对大模型的另一种功能引入。
最后
我们所开发的服务可以通过API或独立页面形式使用。
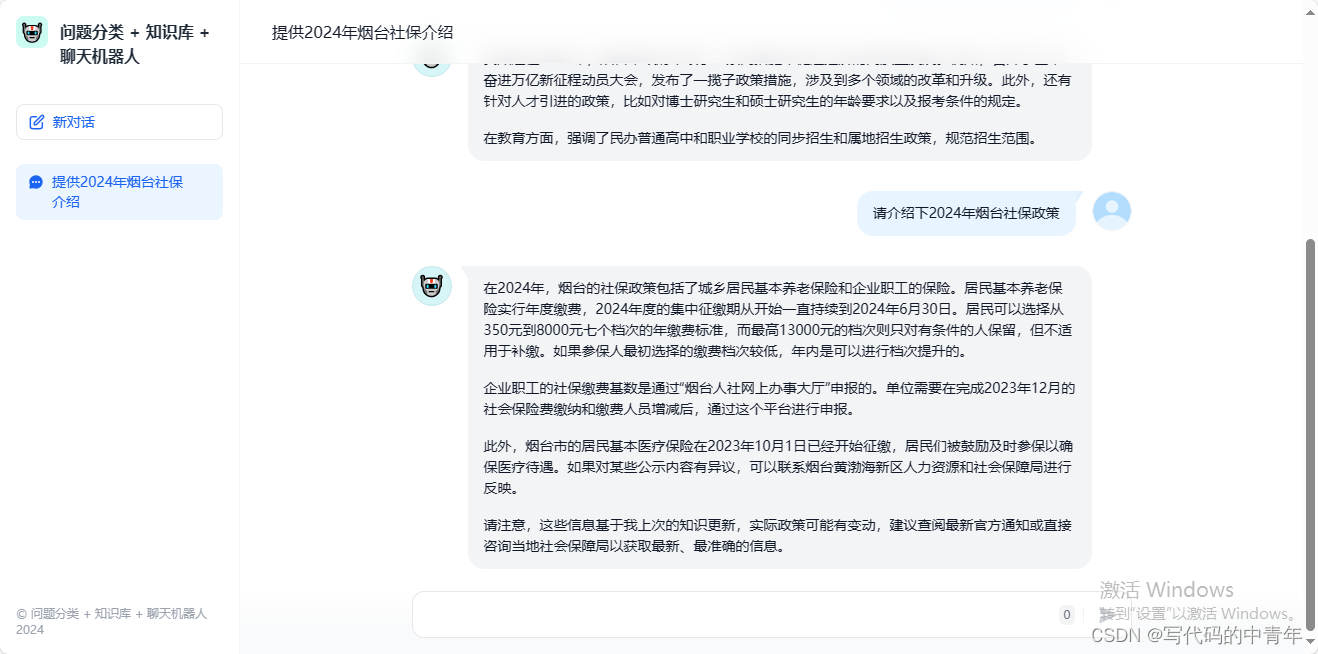
当然,回馈机制、复杂多角色工作流、agent组、可视化、多模态分析以及更丰度的大模型应用开发,Dify均可进行便捷实现,此处不一一列举。本文抛砖引玉,希望诸位能在大模型开发上做出更多有用的设计和尝试,谢谢!


















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











