







先看一下文章的来源
[GPU memory expansion] Buddy Compression: Enabling Larger Memory for Deep Learning and HPC Workloads on GPUs. Esha Choukse, Michael B. Sullivan, Mike O’Connor, Mattan Erez, Jeff Pool, David Nellans, Stephen W. Keckler. ISCA’20
'Buddy Compression’是一种新的架构,通过压缩技术使用更大的主机内存或分散内存,有效地增加了GPU的内存容量。它将每个压缩的128B内存条目分割到高带宽GPU内存和较慢但更大的buddy内存中,可压缩的内存条目完全从GPU内存中读取,而不可压缩的条目部分数据来自于off-GPU内存。使用Buddy Compression,压缩性的变化不会导致昂贵的页面移动或重新分配。
Buddy Compression,我觉得中文翻译成伙伴压缩非常的合适。
"伙伴压缩"的工作方式是,它将每个压缩的128B内存条目分割到高带宽的GPU内存和一个较慢但更大的伙伴内存(可以是主机的内存或者是分散的内存)之间。这样,可以被压缩的内存条目完全从GPU内存中获取,而无法压缩的条目则从离GPU较远的内存中获取部分数据。
下面我们来看一个图,来理解伙伴压缩的工作方式。

压缩后的大小在128B以下的,可以直接从GPU内存中读取。压缩后,大小在128B以上的,128B的部分在GPU内存中读取,而超过的部分在伙伴内存中读取。

一个高带宽的互连,如NVLink、OpenCAPI或CXL,可以实现这种设计,因为它确保了对伙伴内存的低开销访问,只要大部分数据都压缩到适合在GPU设备内存中。只要够快就可以了。
在这篇文章中提出的,最近的工作问题:
- 他们可以为了容量而将应用程序扩展到许多GPU上(这样效率不高)
- 明确地在CPU和GPU之间调度数据移动以保持在设备内存限制内(这增加了算法的复杂性)
- 依赖于离GPU的内存访问或统一内存来自动超越设备内存(这限制了性能)
本文探讨了内存压缩作为一种性能和通用的GPU内存扩展替代方案。
虽然CPU的主内存压缩已经被研究过,但GPU架构提出了非常不同的权衡。CPU压缩技术假设压缩的页面大小不同,并且当压缩性改变时重新分配页面。**这种实时页面重新分配在GPU中会因其巨大的内存带宽而变得过于昂贵。**此外,虽然已经提出了针对大页面GPU工作负载的领域特定压缩,但是通用压缩的容量仍未被探索。
这种设计在保持良好的压缩比和高性能的同时,避免了在GPU上使用CPU内存压缩方法的复杂性和性能问题。
让我们来讲一个故事来理解本文的设计。
想象一下,你和你的好朋友(让我们称他为Buddy)正在搬家。你的新家很小,只有一间小房间,但是你的东西非常多,无法全部放进去。而你的好朋友Buddy,他的房子就大很多,他愿意借你一些空间存放你的东西。
然而,这个新房子的优势是,你可以非常快速地获取里面的任何东西。而要从Buddy的房子里取东西,虽然也很快,但总比在自己的房子里慢一些。为了最大化效率,你需要一个策略来决定哪些东西应该放在你的房子里,哪些可以放在Buddy的房子里。
这就是内存压缩的概念。你的房子就像是GPU的设备内存,它的空间有限,但访问速度很快。Buddy的房子代表了更大但访问速度较慢的伙伴内存。你需要在这两个位置之间进行平衡,以保持高效的操作。
你的策略是,尽可能地将东西压缩,让它们占用更少的空间。如果一个物品可以被压缩到足够小,那么你就把它放在你的房子里。如果一个物品即使压缩了也还是太大,那么你就把它放在你和Buddy的房子里。
这种策略不需要在物品的大小变化时重新分配存储空间,因为无论物品的大小如何,你都可以在你和Buddy的房子之间找到一个地方放置它。
看一下本文的贡献,也就是他的独特之处。
- 首次引入使用通用压缩技术增加GPU内存容量的设计: 这是首次提出使用通用压缩技术来扩展GPU内存容量的设计。这种设计被称为"Buddy Compression",它能有效地增加GPU的内存容量,同时保持高性能。(这个首次没有求证,论文中写的,通用压缩技术)
- Buddy Compression的独特性: Buddy Compression的一个独特之处在于,当数据的可压缩性发生变化时,它不需要进行任何额外的数据移动。(因为只需要去找就可以了,是一个通信而不是移动)
- 别的就不说了,不太关注
看看本文的实现方法:
- 内存分配和压缩目标:
使用 “Buddy Compression”,程序员或深度学习框架可以注释内存分配,使设备内存的使用量少于分配大小。例如,如果用户有24GB的数据,而GPU的内存容量只有12GB,数据可以被分配一个2×压缩的目标,这样在GPU设备内存上只需分配数据全尺寸的一半。 - 精细的压缩:
作者使用精细的压缩以适应这个减少的设备内存分配。如果一个内存项无法足够压缩,那么会使用一个通过NVLink2连接的、更大但更慢的buddy-memory 作为溢出存储。 - 数据对齐和分配:
作者使用了32B的扇区来对数据进行分段,这与GDDR5、GDDR5X、GDDR6和基于HBM2的GPU的内存访问粒度相匹配。如果一个分配目标压缩比为2×,那么每128B内存项的前两个扇区会映射到设备内存,最后两个扇区会映射到 buddy-memory。因此,如果一个内存项被压缩2×或更多,它就会完全适应设备内存。 - 压缩算法:
一个好的硬件内存压缩算法应该快速、能耗少,但又能达到高压缩率。论文中比较了几种低成本的压缩算法,其中Bit-Plane Compression (BPC)对于Buddy Compression来说最具吸引力,因为它在高性能计算和深度学习工作负载中都能达到稳健的压缩比。 - 压缩粒度和大小:
大多数CPU主内存压缩策略在缓存块粒度上运行以避免读-修改-写(RMW)开销。Buddy Compression也采用了这种设计决策,并使用128B的压缩粒度来匹配GPU缓存块大小。 - Buddy-Memory的剥离区域:
在启动时,驱动程序为每个GPU划出一个连续的固定buddy-memory区域。这些区域从未被主机CPU直接访问,从而消除了任何一致性问题,并使得buddy-memory的地址转换简单且快速。
我们理解一下这个压缩比,这个压缩比是需要手工设计的。

图上显示的内存占用了64B,伙伴内存占用了64B。这是由目标压缩比2x计算出来的。每一个sector是一个32B大小的扇区,对于每一个数据块,我们首先对他进行一个压缩。根据压缩比来确定要压缩多少,选择对应的压缩算法去压缩就可以了。
- 当4x压缩的时候,压缩完就可以剩下32B了,可以直接在内存中读取
- 当2x压缩的时候,压缩完就剩下64B了,可以直接在内存中读取
- 当1.33x压缩的时候,压缩完由32B需要从伙伴内存中读取
- 当不压缩也就是1x的时候,64B从内存中读取,64B从伙伴内存中读取
为什么是128?
选择128B作为内存项的大小是基于GPU内存架构和访问模式的考虑。在很多GPU内存架构中,128B是一个常见的内存访问的粒度。这意味着,当GPU访问内存时,它通常一次会读取或写入128B的数据。因此,将内存项的大小设置为128B可以有效地匹配GPU的内存访问模式,进而优化内存访问的性能。
此外,选择128B作为内存项的大小还有一个好处是,它可以很好地配合2×的压缩比率。如果一个128B的内存项可以被压缩到2×的比率,那么它的压缩后的大小正好是64B,这也是很多GPU内存架构的一个常见的内存访问粒度。
虽然128B是一个常见的选择,但实际的内存项大小可以根据具体的GPU内存架构和应用需求进行调整。例如,如果GPU的内存访问粒度是64B,那么可以考虑将内存项的大小设置为64B;
为什么要压缩?
压缩会损失性能,但是很小,压缩可以显著节省内存占用。overhead是解压缩,论文中实验是2%,可以换来1.5x以上的内存扩展,作者认为是值得的。
这也是一种用计算换空间的思想。
如何找到压缩后的数据?
-
地址转换: 访问压缩数据需要额外的地址转换和元数据,这些信息包括压缩比目标、特定内存项是否被压缩到目标比率、以及未能压缩到目标比率的内存项在 buddy-memory 中的访问地址。全局 buddy-memory 划分区域的基础物理地址被存储在一个全局 Buddy Base-address 寄存器(GBBR)中。GPU 的页表和 TLB 被增强以存储页面是否被压缩(1 bit)、目标压缩比(3 bits)以及 buddy-page 从全局基地址的偏移量的信息。
-
元数据处理: Buddy Compression 适用于 GPU 固定内存。支持 CPU 共享(UM 或 ATS)内存需要额外的地址转换机制和系统级模拟,这部分被留给未来的研究(也就是不支持)。Buddy Compression 将地址转换元数据存储在 GPU 页表中,非 GPU 对等体无法访问这些转换元数据,因此他们无法请求到 Buddy-Compressed GPU 内存。
-
内存条目大小元数据: 每个 128B 内存项的压缩大小使用 4 bits 的元数据。这些元数据被存储在一个专用的驱动程序分配的设备内存区域,占用 0.4% 的存储开销。尽管我们选择的压缩大小严格地只需要每个压缩缓存线有 5 个状态(3 bits),但论文保留 4 bits 的元数据以对齐到 2 的幂,并为其他用途或未来的压缩变化预留状态。
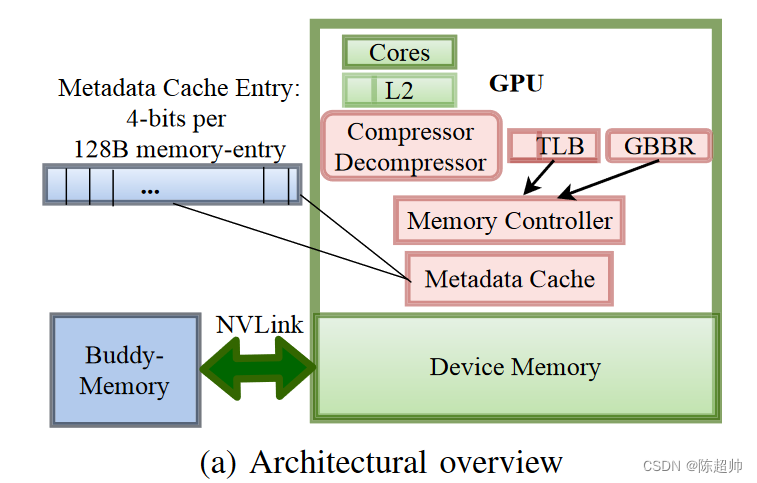
- 伙伴内存和主存通过NVlink连接,因为这个比较快,当然也可以换成别的
- 元数据单独用4bit去存储
- GPU页表被增强了以放置这些额外的信息。
- 伙伴内存的基地址用一个单独的寄存器放,图上的GBBR(Global Buddy base-Address Register)
至于这里用到的压缩算法,Bit-Plane Compression (BPC),读者可以按需要搜索,这个倒不是文本的亮点。
Bit-Plane Compression (BPC)
是一种被广泛使用的压缩方法,尤其在高性能计算和深度学习工作负载中,它能达到稳健的压缩比。这种压缩方法的基本思想是将数据分解成一系列的"bit-planes",然后独立地压缩每一个 “bit-plane”。具体来说,首先,BPC 将每个数据项分解成一系列的二进制位(即 “bit-planes”)。例如,一个32位的浮点数可以被分解成32个"bit-plane"。然后,BPC 对每个 “bit-plane” 进行压缩。通常,高位的"bit-plane"(表示更大的值)包含的信息更少,因此可以被更大程度地压缩。
BPC 的一个主要优点是,它可以按需解压缩数据。也就是说,如果一个计算只需要数据的一部分信息(例如,只需要高位的"bit-plane"),那么只需要解压缩相应的 “bit-plane” 就可以了。这可以进一步提高计算效率。















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









