







文章来源: https://arxiv.org/pdf/1703.10025.pdf
Introduction
FGFA 是Deep Feature Flow的拓展工作。其主要思路是通过光流融合相邻帧的特征图来增强本征的特征。DFF为了提升速度而牺牲精度,而FGFA为了精度而牺牲速度。
Network Architecture

图中左右间隔K=10,聚合长度为2K+1=21. 当前帧(第t帧)由于运动模糊等原因导致特征图原本有目标的部分没有响应,但相邻帧(第t+10帧)有响应的特征图弥补了这个失误。
接下来是比较重要的三个模块。
Flow-guided warping
这部分计算帧i和帧j(i为当前帧,j为i相邻某帧)之间的流场(用FlowNet),然后将帧j的特征图根据流场映射到i去,记为f j->i;
Feature aggregation
融合各帧的特征图,用的是带权平均。
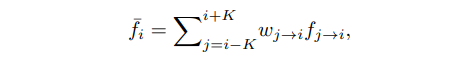
这里w j->i 是2D的,也就是特征图每个channel的权重是相同的。
融合后就可以将结果送入最终的任务网络了
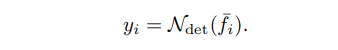
Adaptive weight
剩下的就是确定每帧的权重了。基本思想是与当前帧越相似的,对应的权重系数应该越大。但是,文章并没有直接衡量特征图的相似度(这样会导致当前帧的“提议”仍然占优,抑制了差异帧的“提议”),而是再用一个嵌入子网络对特征图处理(可以理解成一种平滑操作),得到的输出(这里暂且称为嵌入特征图)再用余弦相似度比较。
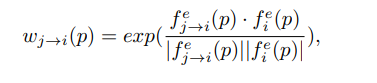
其中p表示嵌入特征图的位置(x,y)。
嵌入子网络的构造:三层卷积层,卷积核参数分别为(1x1x512),(3x3x512), (1x1x2048).















 1280
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









