







系列文章目录
论文名称:CycleISP: Real Image Restoration via Improved Data Synthesis
论文地址:https://arxiv.org/abs/2003.07761
代码地址:https://github.com/swz30/CycleISP
发表时间:2020
应用领域:图像去噪
主要模块:RGB2RAW、RAW2RGB、Color Correction、Noise Injection
注:本文出自:Whn丶nnnnn,此文仅做搬运
文章目录
摘要
本文中提出的方法是利用神经网络模拟Camera ISP的正向和逆向过程以此来获得更为真实的synthetic noisy data并训练去噪网络。
用于低级视觉问题(超分辨、去噪、去模糊)的数据集是难以收集的,一个典型的方法是对同一场景拍摄大量的带有噪声的图片(不同相机的处理会略有差异,所以噪声会略有不同,而图像的主体内容是基本一致的),再对大量同场景的噪声图片在像素级上进行平均,这样就获得了较为干净的ground truth(但是弊端是这样获取的图像会偏光滑,因为不同相机捕捉到的细节也会有差异,而细节在图像中占的比重是很小的,取平均去噪的过程同样会把细节破坏)。
相机拍摄的图片最初是RAW-RGB图(每个像素点只有R、G、B其中之一),RAW图通过相机的ISP(Image Signal Processing:降噪、白平衡、gamma变换、tone mapping等)转换成sRGB图(standard-RGB,3通道)。本文中使用两个网络实现了这一过程的正向和反向模拟,即从sRGB转为RAW图、从RAW图转为sRGB图,所以命名为CycleISP。
网络架构
整体架构
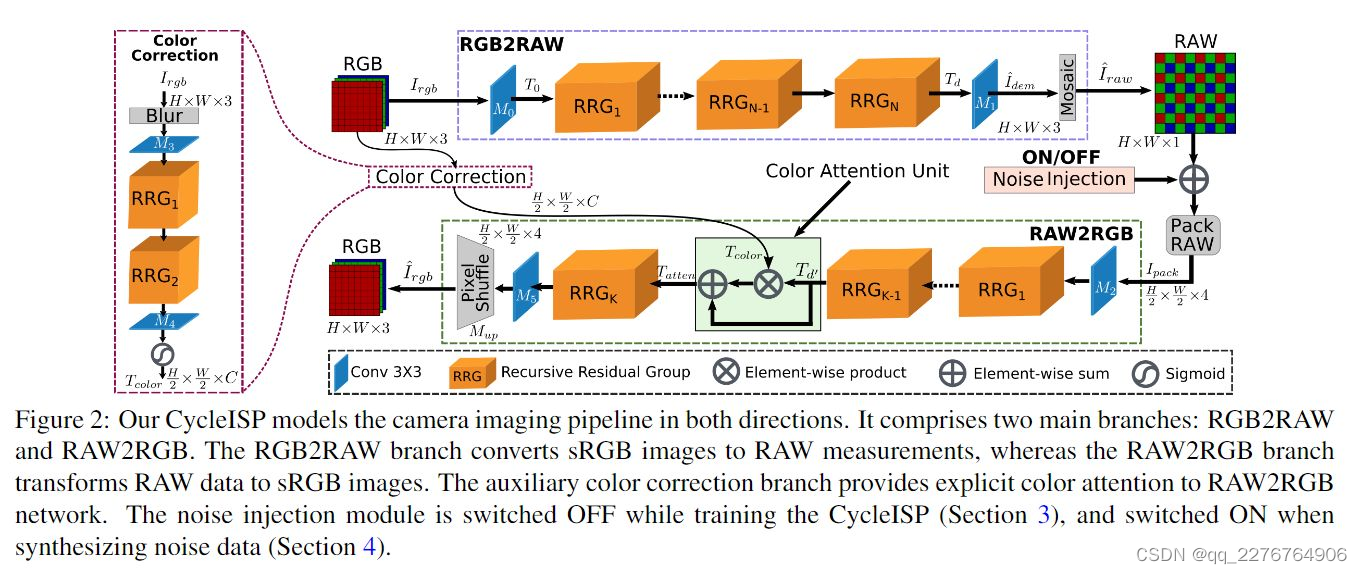
整个CycleISP框架包括四个部分:
(1)RGB2RAW:将sRGB图转为RAW图;
(2)RAW2RGB:将RAW图转为sRGB图;
(3)Color Correction:用于辅助的颜色恢复网络,提供准确的颜色注意机制(explicit color attention)用于RAW2RGB正确地恢复RGB图;
(4)Noise Injection:在训练CycleISP时设置为OFF,在需要生成噪声数据时设置为ON。
CycleISP的训练分为两步:
(1)分别单独训练RGB2RAW和RAW2RGB;
(2)将RGB2RAW和RAW2RGB一起进行joint finetune。
RGB2RAW Network branch
RGB2RAW分支的目的在于要“反转/逆向”相机的ISP效果,而且优点在于这一网络不需要任何的相机参数。
给定一张RGB输入
I
r
g
b
∈
R
H
×
W
×
3
I_{r g b} \in R^{H \times W \times 3}
Irgb∈RH×W×3。1.先用卷积层
M
0
M_{0}
M0提取low-level特征得到多个feature map:
T
0
∈
R
H
×
W
×
C
T_0 \in R^{H \times W \times C}
T0∈RH×W×C,即
T
0
=
M
0
(
I
r
g
b
)
T_0=M_0\left(I_{r g b}\right)
T0=M0(Irgb)。2.接下来再利用多个Recursive Residual Group(RRGs) 3.进一步从
T
0
T_0
T0 中提取深层特征
T
d
=
R
R
G
N
(
…
(
R
R
G
1
(
T
0
)
)
)
T_d=R R G_N\left(\ldots\left(R R G_1\left(T_0\right)\right)\right)
Td=RRGN(…(RRG1(T0)))
4.然后将
T
d
T_d
Td通过卷积层
M
1
M_1
M1 得到去马赛克的图像
I
^
d
e
m
∈
R
H
×
W
×
3
\hat{I}_{d e m} \in R^{H \times W \times 3}
I^dem∈RH×W×3(这里故意将
M
1
M_1
M1的输出通道设置为3而不是1,是为了更好地保持初始图像的结构信息,进一步发现这样可以提高网络的训练速度和准确性),这时网络已经可以实现相机ISP的逆向。5.最后为了生成Mosaicked RAW的结果
I
^
raw
∈
R
H
×
W
×
1
\hat{I}_{\text {raw }} \in R^{H \times W \times 1}
I^raw ∈RH×W×1 ,我们使用Bayer sampling function
f
Bayer
f_{\text {Bayer }}
fBayer 在每个像素点省略两个颜色通道:
I
^
raw
=
f
Bayer
(
M
1
(
T
d
)
)
\hat{I}_{\text {raw }}=f_{\text {Bayer }}\left(M_1\left(T_d\right)\right)
I^raw =fBayer (M1(Td))
RGB2RAW网络使用线性域和对数域的
L
1
L_1
L1 loss作为损失函数:
L
s
→
r
(
I
^
raw
,
I
raw
)
=
∥
I
^
raw
−
I
raw
∥
1
+
∥
log
(
max
(
I
^
raw
,
ϵ
)
)
−
log
(
max
(
I
raw
,
ϵ
)
)
∥
1
L_{s \rightarrow r}\left(\hat{I}_{\text {raw }}, I_{\text {raw }}\right)=\left\|\hat{I}_{\text {raw }}-I_{\text {raw }}\right\|_1+\left\|\log \left(\max \left(\hat{I}_{\text {raw }}, \epsilon\right)\right)-\log \left(\max \left(I_{\text {raw }}, \epsilon\right)\right)\right\|_1
Ls→r(I^raw ,Iraw )=
I^raw −Iraw
1+
log(max(I^raw ,ϵ))−log(max(Iraw ,ϵ))
1 ,
I
raw
I_{\text{raw}}
Iraw是RAW格式的ground truth图,
ϵ
\epsilon
ϵ用于防止出现log(0),添加对数域的loss以对所有图像进行近似相等的处理,防止网络过于关注图像中过亮的区域。
RAW2RGB Network Branch
该分支的最终目的是用于生成带有噪声的sRGB图用于去噪网络的训练,首先阐述在加噪模块处于OFF状态下,将clean的RAW图映射为clean的sRGB图。
首先为了减少计算代价,将输入转为4通道(RGGB)格式(这里用到了Bayer pattern unification technique)得到 I p a c k ∈ . R H 2 × W ˙ 2 × 4 I_{p a c k}\stackrel{.}{\in}R^{\frac{H}{2}\times\frac{\dot{W}}{2}\times4} Ipack∈.R2H×2W˙×4,接下来通过k-1个RRG模块和一个卷积层 M 2 M_2 M2将 I p a c k I_{pack} Ipack转换成深层特征 T d ⃗ = R R G K − 1 ( … ( R R G 1 ( M 2 ( P a c k ( I r a w ) ) ) ) T_{\vec{d}}=R R G_{K-1}(\ldots(R R G_{1}(M_{2}(P a c k(I_{r a w})))) Td=RRGK−1(…(RRG1(M2(Pack(Iraw))))。这里的 I r a w I_{raw} Iraw是原始的RAW图,而不是RGB2RAW网络的输出结果,因为此时我们的目标是独立地训练这两个分支。
color attention unit(核心:color correction branch)
训练CycleISP使用了MIT-Adobe 5K数据集,该数据集中包含了多种不同相机拍摄的图像,所以CNN很难确地学习一种RAW到sRGB的映射(因为这种映射是复杂多样的),所以本文中采用的方法是提出一个color attention unit,嵌入到RAW2RGB网络中,通过color correction branch来获得颜色的attention。
该分支首先将高斯核与输入的sRGB图
I
r
g
b
I_{rgb}
Irgb,进行卷积,再依次通过卷积层
M
3
M_3
M3、2个RRG模块和卷积层
M
4
M_4
M4,使用
σ
\sigma
σ激活函数,转化为颜色编码的深度特
T
c
o
l
o
r
=
σ
(
M
4
(
R
R
G
2
(
R
R
G
1
(
M
3
(
K
∗
I
r
g
b
)
)
)
)
)
)
)
T_{color}=\sigma(M_4(RRG_2(RRG_1(M_3(K*I_{rgb})))))))
Tcolor=σ(M4(RRG2(RRG1(M3(K∗Irgb)))))))。高斯模糊的作用是只让颜色信息流入color attention unit,而图像的结构和纹理特征会通过RAW2RGB网络获得,那么整个color attention unit过程就变为了
T
a
t
t
e
n
=
T
d
′
+
(
T
d
′
⊗
T
c
o
l
o
r
)
T_{atten}=T_{d'}+(T_{d'}\otimes T_{color})
Tatten=Td′+(Td′⊗Tcolor),其中**
⊗
\mathbf{\otimes}
⊗是Hadamard product**。
为了获得最终的sRGB输出
I
^
r
g
b
\hat{I}_{r g b}
I^rgb,还需要将1个RRG模块和卷积层
M
5
M_5
M5和upscaling layer
M
u
p
M_{up}
Mup,即
I
^
r
g
b
=
M
u
p
(
M
5
(
R
R
G
K
(
T
a
t
t
e
n
)
)
)
\hat{I}_{r g b}=M_{u p}(M_{5}(R R G_{K}(T_{a t t e n})))
I^rgb=Mup(M5(RRGK(Tatten)))。
对于RAW2RGB网络,也是用 L 1 L_1 L1 loss: L r → s ( I ^ r g b , I r g b ) = ∣ ∣ I ^ r g b − I r g b ∣ ∣ 1 L_{r\rightarrow s}(\hat{I}_{r g b},I_{r g b})=||\hat{I}_{r g b}-I_{r g b}||_{1} Lr→s(I^rgb,Irgb)=∣∣I^rgb−Irgb∣∣1
RRG:Recursive Residual Group
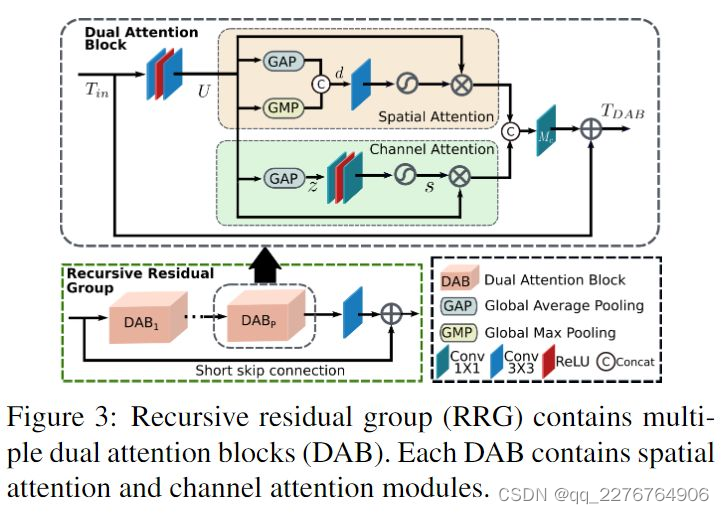
RRG模块包括p个dual attention blocks(DAB),每个DAB的目标是抑制作用更小的feature而只允许传播信息更丰富的feature,DAB通过两种attention mechanisms(注意机制)来实现feature的校准:(1)channel attention(CA) 和(2)spatial attention(SA)。整个过程如下:
T
D
A
B
=
T
i
n
+
M
c
(
[
C
A
(
U
)
,
S
A
(
U
)
]
)
T_{DAB}=T_{in}+M_{c}([CA(U),SA(U)])
TDAB=Tin+Mc([CA(U),SA(U)]) ,其中
U
∈
R
H
×
W
×
C
U\in R^{H\times W\times C}
U∈RH×W×C是DAB的输入张量
T
i
n
∈
R
H
×
W
×
C
T_{in}\in R^{H\times W\times C}
Tin∈RH×W×C通过两次卷积得到的feature maps,而
M
c
M_c
Mc是最后的1*1卷积层。
channel attention主要是为了利用卷积特征通道间的相关性(dependencies),spatial attention则利用特征的空间关系,计算出一个spatial attention map用于重新缩放输入的特征U。详细可以参照作者引用的文章,这里不再赘述。
Joint Fine-tune of CycleISP
因为第一阶段RGB2RAW和RAW2RGB两个网络是独立训练的,所以可能无法得到最理想的效果,那么接下来就要将两个网络连接起来进行finetune,作者将RGB2RAW网络的输出作为RAW2RGB网络的输入。
联合优化的损失函数如下:
L
j
o
i
n
t
=
β
L
s
→
r
(
I
^
r
a
w
,
I
r
a
w
)
+
(
1
−
β
)
L
r
→
s
(
I
^
r
g
b
,
I
r
g
b
)
L_{joint}=\beta L_{s\rightarrow r}(\hat{I}_{raw},I_{raw})+(1-\beta)L_{r\rightarrow s}(\hat{I}_{rgb},I_{rgb})
Ljoint=βLs→r(I^raw,Iraw)+(1−β)Lr→s(I^rgb,Irgb),其中
β
\boldsymbol{\beta}
β是一个正常数
Synthetic Realistic Noise Data Generation
分析完CycleISP的架构之后,接下来就是生成数据来训练去噪网络了
Data for RAW denoising
RGB2RAW网络将输入的clean sRGB图像转换成clean的RAW图像,将加噪模块noise injection module设置为ON,加噪模块像RGB2RAW网络的输出结果添加不同程度的shot and read noise,这样对于仍以一张输入的RGB图像,我们就获得了其对应的RAW图像对{ R A W c l e a n , R A W n o i s y RAW_{clean},RAW_{noisy} RAWclean,RAWnoisy} 用于训练RAW denoising网络。
Data for sRGB denoising
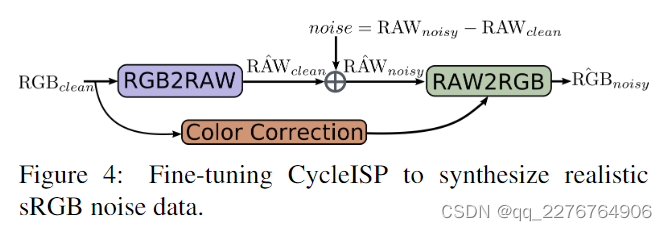
向RAW2RGB网络输入一张synthetic R A W n o i s y RAW_{noisy} RAWnoisy图像,网络输出带有噪声的sRGB图像,那么我们就得到了对应的sRGB图像对{ R A W c l e a n , R A W n o i s y R A W_{clean},R A W_{nois y} RAWclean,RAWnoisy}用于训练RGB denoising网络。而作者想进一步提高训练数据的质量,所以使用SIDD数据集(包含同一场景的RAW和sRGB的干净和噪声图像对)按照Figure 4 中的流程对网络进行finetune,当finetune完成后,就可以通过向CycleISP模型输入clean sRGB图像,并输出noisy sRGB图像了。
Denoising Architecture
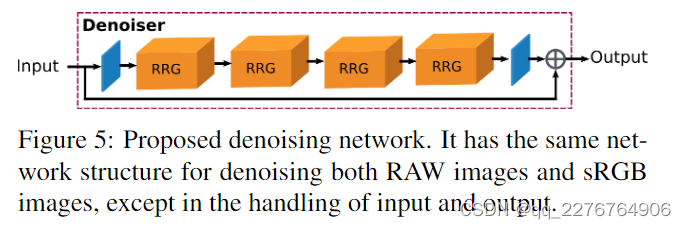
如Figure5所示,去噪网络是有多个RRG模块组成的,对于RAW denoising 和 sRGB denoising都采用了相同的网络结构,唯一的区别就在于对于输入和输出的处理上,sRGB去噪网络的输入输出均为3通道;RAW去噪网络的输入输出均为4通道(???不解)。
experiments
Real Image Datasets
DND
包含50对noisy和(nearly)noise-free图像(应该是通过4个相机的结果进行平均得到的),因为干净的ground truth无法获得,所以整个数据集都作为测试集,使用时由于图片太大还进行了crop。
SIDD
使用5台智能手机收集的数据集,对每个场景都包括RAW格式和sRGB格式的clean、noisy图片,320个图片对用于训练,1280个图片对用于验证。
Implementation Details
所有优化过程都是用Adam optimizer(
β
1
=
0.9
,
β
2
=
0.999
\beta_{1}=0.9,\beta_{2}=0.999
β1=0.9,β2=0.999);
CycleISP的训练使用了MIT-Adobe 5K数据集(包括5000张RAW格式图像),使用LibRaw对RAW图像进行处理并生成sRGB图像;
Finetune实际上进行了两次,分别参照Section 3.4和Section 4;
对于去噪网络,都使用了4个RRGs模块和8个DABs模块,训练去噪网络使用的数据集是MIR flickr中的100万张图像,所有的图像都先通过高斯核处理来减小噪声的影响,再利用作者提出的CycleISP生成clean/noisy图像对用于训练。
Results for RAW Denoising
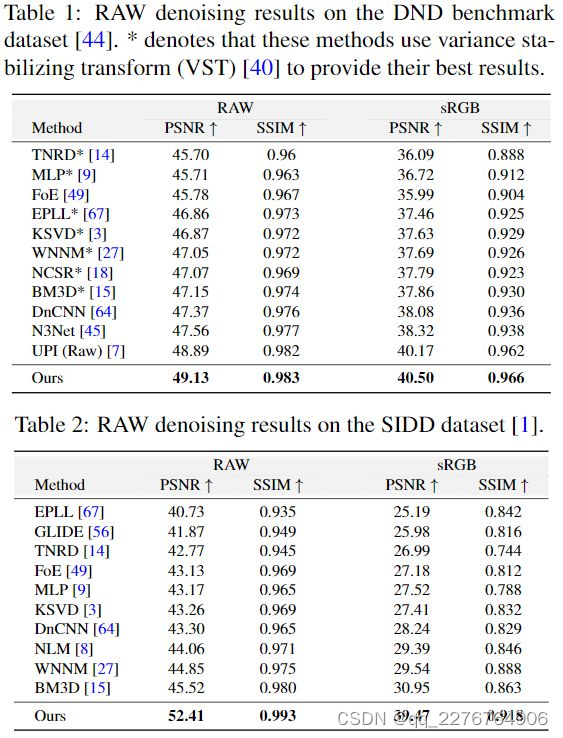
Results for sRGB Denoising


Conclusion
从文章中的结果可以看出,CycleISP的确在DND和SIDD数据集上表现突出,我自己也使用作者的代码在一些real-world images上进行了测试,并与BM3D和CBD-Net的去噪结果进行了对比,CycleISP的开源代码中包含了4个训练好的去噪模型(dnd_raw、dnd_rgb、sidd_raw、sidd_rgb),因为我使用的测试图片均为sRGB格式,所以只对dnd_rgb和sidd_rgb两个模型进行了测试,CycleISP_dnd_rgb要比BM3D和CBD-Net的去噪效果更好,去除掉另外两种算法难以去掉的噪声的同时也很好的保留了图片的细节,而CycleISP_sidd_rgb的去噪效果和另外两种算法相近。篇幅原因这里不多展示结果图了,总的来说CycleISP的去噪效果很不错,值得尝试。















 6623
6623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









