







文章题目:Learning Enriched Features for Real Image Restoration and Enhancement
文章地址:
代码地址:https://github.com/swz30/MIRNet
应用领域:图像去噪、图像超分、图像增强
发表时间:2020
作者:Syed Waqas Zamir
摘要
现有的基于CNN的方法通常作用在全分辨率或渐进式低分辨率上。在前一种情况下,实现了空间精确但上下文不太稳健的结果,而在后一种情况下,生成语义可靠但空间不太准确的输出。在本文中,作者提出了一种新的架构,其目标是在整个网络中保持空间精确的高分辨率表示,并从低分辨率表示中接收强上下文信息。该方法的核心是一个包含几个关键元素的多尺度残差块:
- 用于提取多尺度特征的并行多分辨率卷积流
- 跨多分辨率流的信息交换
- 用于捕获上下文信息的空间和通道注意机制
- 基于注意力的多尺度特征聚合
简而言之,我们的方法学习了一组丰富的特征,结合了来自多个尺度的上下文信息,同时保留了高分辨率的空间细节。该方法 在各种图像处理任务(包括图像去噪、超分辨率和图像增强)上取得了最先进的结果。
动机(解决了什么问题)
传统方法(高分辨率单尺度的方法和编码器-解码器结构)不能兼顾图像细节和语义信息的保留
创新点(如何解决的)
- 种新的特征提取模型,在多个空间尺度上获得一组互补的特征,同时保持原始的高分辨率特征以保持精确的空间细节。(MRB)
- 一种用于信息交换的规则重复机制,其中跨多分辨率分支的特征逐渐融合在一起,以改进表示学习(DAU)
- 一种使用选择性核网络融合多尺度特征的新方法,该网络动态组合可变感受野,并在每个空间分辨率忠实地保留原始特征信息。(SKFF)
- 一个递归残差设计,逐步分解输入信号以简化整体学习过程,并允许构建非常深的网络。(Residual resizing modules,上下采样)
网络结构
整体网络架构
所提出的网络MIRNet的框架,学习用于图像恢复和增强的丰富特征表示。MIRNet基于递归残差设计。MIRNet的核心是多尺度残差块(MRB),其主要分支专门用于通过整个网络保持空间精确的高分辨率表示,而并行分支的互补集提供了更好的上下文化特征。它还允许通过选择性核特征融合(SKFF)在并行流之间进行信息交换,以便在低分辨率特征的帮助下巩固高分辨率特征,反之亦然。
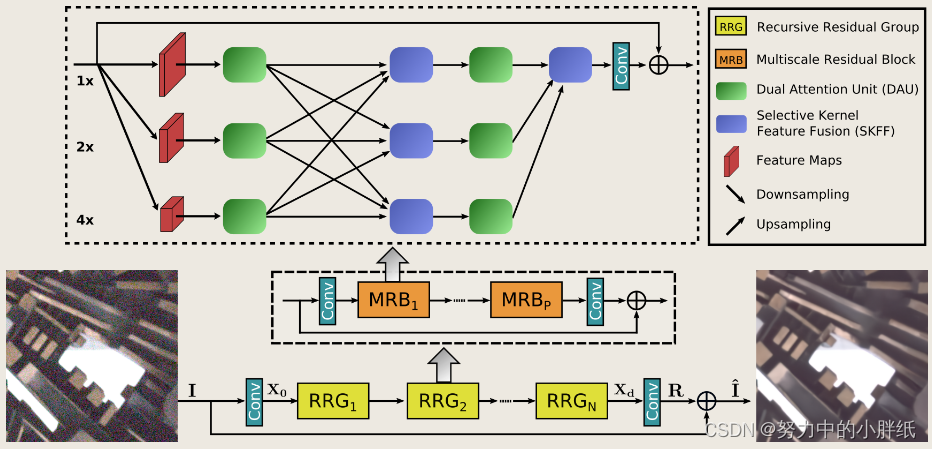
如上图所示,作者提供了多尺度残差块的细节,包含以下几个关键元素:
a)用于提取(从细到粗)语义更丰富和(从粗到细)空间精确特征表示的并行多分辨率卷积流
b)跨多分辨率流的信息交换
c)基于注意力的多流特征聚合
d)在空间和渠道维度上捕捉上下文信息的双注意力单元
e)残差大小调整模块,用于执行下采样和上采样操作
给定一个图像
I
∈
R
H
×
W
×
3
\mathbf{I}\in\mathbb{R}^{H\times W\times3}
I∈RH×W×3,网络首先应用卷积层来提取低级特征
X
0
∈
R
H
×
W
×
C
\mathbf{X_0}\in\mathbb{R}^{H\times W\times C}
X0∈RH×W×C。接下来,特征图 X0 通过 N 个递归残差组 (RRG),产生深度特征
X
d
∈
R
H
×
W
×
C
\mathbf{X_d}\in\mathbb{R}^{H\times W\times C}
Xd∈RH×W×C。我们注意到每个RRG包含多个多尺度残差块(MRB)。接下来,作者将卷积层应用于深度特征
X
d
\mathbf{X_d}
Xd,得到残差图像
R
∈
R
H
×
W
×
3
\mathbf{R}\in\mathbb{R}^{H\times W\times3}
R∈RH×W×3。最后,将恢复后的图像得到为
I
^
=
I
+
R
\mathbf{\hat{I}}=\mathbf{I}+\mathbf{R}
I^=I+R。我们使用Charbonnier损失[优化所提出的网络:
L
(
I
^
,
I
∗
)
=
∥
I
^
−
I
∗
∥
2
+
ε
2
\mathcal{L}(\mathbf{\hat{I}},\mathbf{I}^*)=\sqrt{\left\|\mathbf{\hat{I}}-\mathbf{I}^*\right\|^2+\varepsilon^2}
L(I^,I∗)=
I^−I∗
2+ε2其中
I
∗
\mathrm{I}^{*}
I∗表示干净图像,ε是一个常数,作者在所有实验中根据经验设置为10−3。
Multi-scale Residual Block(MRB)
为了对上下文进行编码,现有的CNN通常采用以下架构设计 a) 神经元的感受野在每一层/每一阶段都是固定的、b) 特征图的空间大小逐渐减小,以生成语义强的低分辨率表示、c) 从低分辨率表示逐渐恢复高分辨率表示。然而,在视觉科学中,人们很清楚,在灵长类动物的视觉皮层中,同一区域神经元的局部感受野大小不同。因此,需要将这种在同一层中收集多尺度空间信息的机制纳入细胞神经网络。在本文中,我们提出了多尺度残差块(MRB),如图1所示,它能够通过保持高分辨率表示生成空间精确的输出,同时从低分辨率接收丰富的上下文信息。MRB由并行连接的多个(本文中为三个)完全卷积流组成。它允许在并行流之间进行信息交换,以便在低分辨率特征的帮助下整合高分辨率特征,反之亦然。接下来,我们将描述MRB的各个组件。
Selective kernel feature fusion (SKFF)
视觉皮层中存在的神经元的一个基本特性是能够根据刺激改变它们的感受野,这种自适应调整感受野的机制可以通过使用多尺度特征生成(在同一层中)和特征聚合和选择合并到 CNN 中。最常用的特征聚合方法包括简单的连接或求和。然而,这些选择为网络提供了有限的表达能力。在 MRB 中,我们介绍了一种非线性过程,用于使用自注意力机制融合来自多个分辨率的特征。我们称之为选择性核特征融合(SKFF)。
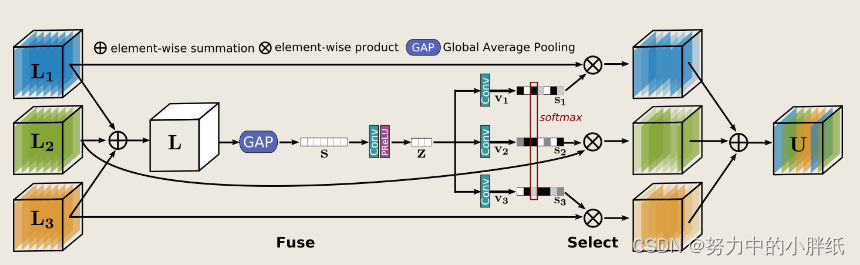
SKFF模块通过两个操作(Fuse和Select)对接收域进行动态调整,如上图所示。fuse算子通过结合多分辨率流的信息来生成全局特征描述符,select操作符使用这些描述符来重新校准(不同流的)特征图,然后进行聚合。接下来,我们为三个流的情况提供了两个运算符的详细信息,但可以很容易地将其扩展到更多的流。
Fuse:
SKFF接收来自三个具有不同信息尺度的并行卷积流的输入。我们首先使用逐元素求和来组合这些多尺度特征:L = L1 + L2 + L3。然后,我们在
L
∈
R
H
×
W
×
C
\mathbf{L}\in\mathbb{R}^{H\times W\times C}
L∈RH×W×C的空间维度上应用全局平均池化 (GAP) 来计算通道统计
s
∈
R
H
×
W
×
C
\mathbf{s}\in\mathbb{R}^{H\times W\times C}
s∈RH×W×C。接下来,我们应用通道缩放卷积层来生成一个紧凑的特征表示
z
∈
R
1
×
1
×
r
\mathbf{z}\in\mathbb{R}^{1\times 1\times r}
z∈R1×1×r ,其中所有实验的
r
=
C
8
\begin{aligned}r&=\frac{C}{8}\end{aligned}
r=8C。最后,特征向量 z 通过三个并行通道放大卷积层(每个分辨率流一个),为我们提供了三个特征描述符 v1、v2 和 v3,每个特征描述符维度为 1 × 1 × C。
Select:
该算子将 softmax 函数应用于 v1、v2 和 v3,产生注意力激活 s1、s2 和 s3,分别用于自适应地重新校准多尺度特征图 L1、L2 和 L3。特征重新校准和聚合的整体过程定义为:U = s1·L1 + s2·L2 + s3·L3。注意,SKFF使用的参数比连接聚合少约6倍,但产生更有利的结果(实验部分提供了消融研究)。
Dual attention unit (DAU)
虽然SKFF块融合了多分辨率分支的信息,但我们还需要一种机制来在特征张量内共享信息,包括沿空间和通道维度。受最近基于注意机制的低级视觉方法的进展的启发,我们提出了双注意单元(DAU)来提取卷积流中的特征。DAU示意图如下图所示。
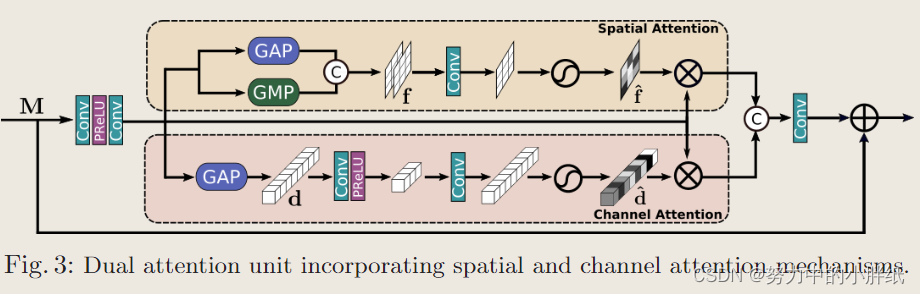
DAU抑制了不太有用的特征,只允许更多的信息特征进一步传递。该特征重新校准是通过使用通道注意和空间注意]机制实现的。
1)通道注意力(CA)分支通过应用挤压和激励(squeeze-and-excitation)操作来利用卷积特征映射的通道间关系。给定一个特征图
M
∈
R
H
×
W
×
C
\mathscr{M}\in\mathbb{R}^{H\times W\times C}
M∈RH×W×C,挤压(squeeze)操作在空间维度上应用全局平均池化来编码全局上下文,从而产生特征描述符
d
∈
R
1
×
1
×
C
\mathscr{d}\in\mathbb{R}^{1\times 1\times C}
d∈R1×1×C 。激励(excitation)操作 将d 经过两个卷积层,然后是sigmoid gate门控,产生激励
d
^
∈
R
1
×
1
×
C
\hat{\mathrm{d}}\in\mathbb{R}^{1\times1\times C}
d^∈R1×1×C。最后,用激励值
d
^
\hat{d}
d^重新缩放M,得到CA支路的输出。
2)空间注意力(SA)分支旨在利用卷积特征的空间间依赖关系。SA的目标是生成一个空间注意图,并用它来重新校准输入的特征M。为了生成空间注意图,SA分支首先沿着通道维度对特征M独立地应用全局平均池化和最大池化操作,并将输出连接起来形成一个特征图
f
∈
R
H
×
W
×
2
\mathrm{f}\in\mathbb{R}^{H\times W\times2}
f∈RH×W×2。通过卷积和 sigmoid 激活传递的映射 f 以获得空间注意力图
f
^
∈
R
H
×
W
×
1
\mathbf{\hat{f}}\in\mathbb{R}^{H\times W\times1}
f^∈RH×W×1,然后用它来重新缩放 M。
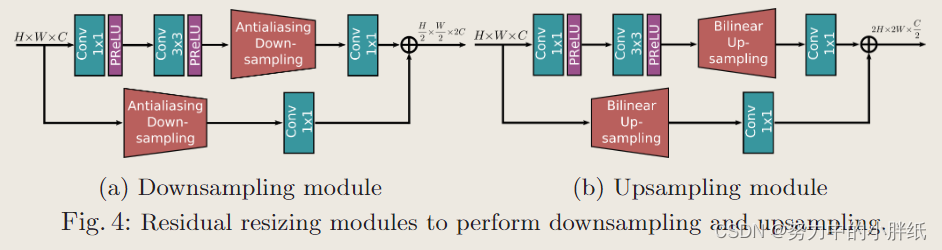
Residual resizing modules
所提出的框架采用递归残差设计(具有跳跃连接)来简化学习过程中信息流。为了保持我们体系结构的残差性质,我们引入了残差调整大小模块来执行下采样(图4a)和上采样(图4b)操作。在 MRB 中,特征图的大小沿卷积流保持不变。另一方面,跨流,特征图大小根据输入分辨率索引 i 和输出分辨率索引 j 而变化。如果i<j,则对输入特征张量进行下采样,如果i>j,则将对特征图进行上采样。为了执行2×下采样(将空间维度减半并将通道维度加倍),我们仅应用图4a中的模块一次。对于4×下采样,模块被连续应用两次。类似地,可以通过分别应用图 4b 中的模块一次和两次来执行 2× 和 4× 上采样。请注意,在图4a中,我们集成了抗混叠下采样(antialiasing downsampling),以提高我们网络的偏移等方差。
实验
实验细节
所提出的架构是端到端可训练的,不需要子模块的预训练。作者为三个不同的恢复任务训练了三个不同的网络。所有实验共有的训练参数如下:使用 3 个 RRG,每个 RRG 进一步包含 2 个 MRB。MRB 由 3 个并行流组成,通道维度为 64、128、256,分辨率分别为 1、1/2、1/4。每个流有 2 个 DAU。采用Adam优化器(β1 = 0.9, β2 = 0.999)对模型进行 7 × 1 0 5 7\times10^{5} 7×105次迭代训练.初始学习率设置为 2 × 1 0 − 4 2\times10^{-4} 2×10−4,在训练过程中,采用余玄退火策略将学习率逐渐降低到 1 0 − 6 10^{-6} 10−6。我们从训练图像中提取大小为 128 × 128 的补丁。批量大小设置为 16,对于数据增强,我们执行水平和垂直翻转。
对比实验
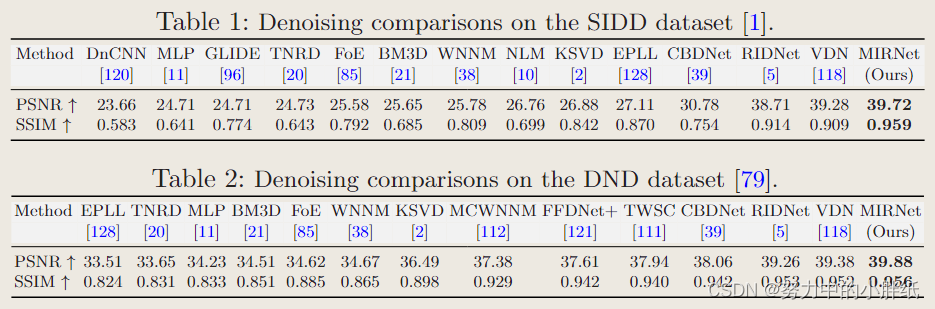
作者只在SIDD的训练集上训练网络,并在SIDD和DND数据集的测试图像上直接对其进行评估。SIDD 和 DND 的 PSNR 和 SSIM 指标方面的定量比较总结在表 1 和表 2 中。这两个表都表明,我们的 MIRNet 优于数据驱动的去噪算法,以及传统的去噪算法。具体来说,与最近的最佳方法VDN相比,我们的算法在SIDD上的性能增益为0.44 dB,在DND上的性能增益为0.50 dB。此外,值得注意的是CBDNet和RIDNet使用额外的训练数据,但我们的方法提供了明显更好的结果。例如,我们的方法在SIDD数据集上比CBDNet[39]提高了8.94 dB,在DND上实现了1.82 dB的改进。
作者暂时了展示了我们的结果与其他竞争算法的视觉比较。可以看出,我们的MIRNet在去除真实噪声并产生感知愉悦和清晰的图像方面是有效的。它能够在不引入伪影的情况下保持均匀区域的空间平滑度。相比之下,大多数其他方法要么产生过度平滑的图像,从而牺牲结构内容和精细的纹理细节,要么产生带有色度伪影和斑点纹理的图像。
DND 和 SIDD 数据集是通过具有不同噪声特征的不同相机集获得的。由于 DND 基准不提供训练数据,使用我们的 SIDD 训练网络在 DND 数据集上取得了最好的效果,表明了我们方法的良好泛化能力。
消融实验
消融实验写得很好,因消融实验是基于超分任务进行的,此处仅作简单说明。
分别讨论1)了MRB中各模块的影响,说明skip-connection可以加速收敛、大幅提升性能,同时简单说明了其他模块的作用;2)说所提SKFF与简单的sum和concat操作相比参数更少、效果更好;3)对MRB不同布局(并行解析流数和DAU数)做了讨论,分别增加流数以及增加DAU列数效果都会有相应的提升,说明多尺度特征处理的重要性和并行流之间的信息交换对于特征整合的重要性。
结语
传统的图像恢复和增强管道要么沿着网络层次结构坚持全分辨率特征,要么使用编码器-解码器架构。第一种方法有助于保留精确的空间细节,而后者提供了更好的上下文表示。然而,这些方法只能满足上述两个要求之一,尽管现实世界的图像恢复任务需要以给定的输入样本为条件的组合。在这项工作中,我们提出了一种新颖的架构,其主要分支专用于全分辨率处理,互补并行分支集提供了更好的上下文特征。我们提出了新的机制来学习每个分支内特征之间的关系以及跨多尺度分支。我们的特征融合策略确保可以在不牺牲原始特征细节的情况下动态适应感受野。在三个图像恢复任务和增强任务的五个数据集上,都取得了最好的结果,证实了我们方法的有效性。















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









