







文章题目:Multi-Scale Adaptive Network for Single Image Denoising
文章地址:http://pengxi.me/wp-content/uploads/2022/11/MSANet.pdf
代码地址:https://github.com/XLearning-SCU/2022-NeurIPS-MSANet
应用领域:图像去噪
发表时间:2022
作者:yuanbiao Gou(四川大学)
摘要
由于吸引人的跨尺度互补性,多尺度架构在各种任务中都显示出有效性。然而,现有的架构平等地对待不同的尺度特征,而不考虑尺度特定的特征,即在架构设计中忽略了尺度内特征。在本文中,我们揭示了这种用于多尺度架构设计的缺失部分,并相应地提出了一种新的多尺度自适应网络(MSANet)用于单幅图像去噪。具体来说,MSANet由于三个新的神经块,即自适应特征块(AFeB)、自适应多尺度块(AMB)和自适应融合块(AFuB),同时包含了尺度内特征和跨尺度互补性。简而言之,AFeB具有自适应保留图像细节和滤除噪声的功能,这对于混合细节和噪声的特征具有很高的期望。AMB可以扩大感知野,聚合多尺度信息,满足上下文信息特征的需要。AFuB致力于自适应采样并将特征从一个尺度转移到另一个尺度,融合了从粗到细不同特征的多尺度特征。在3个真实和6个合成噪声图像数据集上进行的大量实验表明,与12种方法相比,MSANet具有优势。
动机(解决了什么问题)
当下多尺度架构平等地对待不同的尺度特征,而不考虑尺度特定的特征,即在架构设计中忽略了尺度内特征。在本文中,我们揭示了这种用于多尺度架构设计的缺失部分,并相应地提出了一种新的多尺度自适应网络(MSANet)用于单幅图像去噪。
理论分析
在网络设计范式中,由于多尺度特征,多尺度架构在性能提升中发挥着重要作用。然而,现有研究仅考虑跨尺度互补性而忽略尺度内特征来设计他们的网络架构(见下图)。准确地说,缺乏上下文信息意识的浅层和高分辨率特征对输入很敏感,并且包含大量噪声。然而,它们包含丰富的图像几何信息,如边缘和纹理。因此,它们对细粒度图像细节的恢复至关重要,其网络结构应具有优势并弥补缺点。深度和低分辨率特征在噪声鲁棒性和上下文信息方面具有竞争力,这对于恢复粗粒度图像上下文至关重要,但过低分辨率会破坏图像结构。因此,他们的网络结构也应该充分考虑他们在架构设计过程中的特征。总而言之,由于不同的尺度特征表现出不同的特征,值得通过尺度特定的结构来处理它们,以完全适应它们的特征。
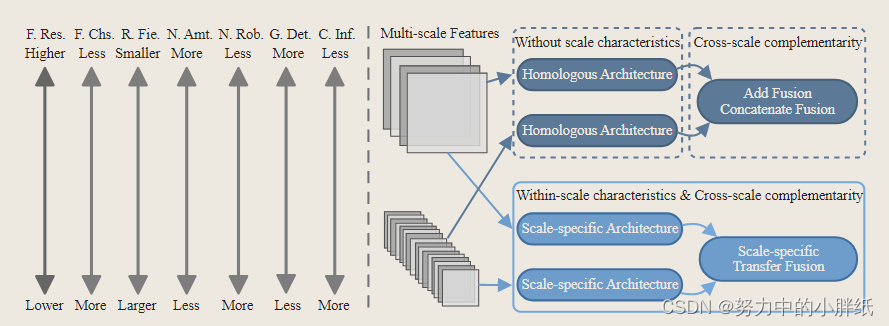
MSANet的动机。左:不同分辨率的特征表现出不同的特征。在图中,“F.Res.”和“F.Chs.”分别表示特征分辨率和通道; “R.Fie.”表示感受野; “N.Amt.”和“N.Rob.”分别表示噪声量和鲁棒性; “G.Det.”和“C.Inf.”分别表示几何细节和上下文信息。右图:MSANet与现有的多尺度架构的主要区别在于,不同的尺度特征表现出不同的特征,应该由尺度特定的结构而不是同源架构处理。
创新点(如何解决的)
基于动机,作者提出了一种新的多尺度自适应网络(MSANet)用于单幅图像去噪,通过克服以下三个困难,将尺度内特征和跨尺度互补性同时纳入架构设计,即 i)如何自适应地采样图像细节和滤波噪声;ii)如何在不改变特征分辨率的情况下自适应地提取上下文信息特征;iii)如何自适应地融合具有不同特征的多尺度特征。因此,提出了自适应特征块(AFeB)、自适应多尺度块(AMB)和自适应融合块(AFuB)三个神经块。简而言之,AFeB通过自适应采样和加权处理细节和噪声混合的特征,从而在滤波噪声时保留图像细节。AMB 通过扩张卷积和自适应聚合提取上下文信息,从而在保持分辨率不变的情况下获得上下文信息特征。AFuB 自适应地对特征进行采样并将特征从一个尺度转移到另一个尺度,将具有不同特征的多尺度特征从粗到细融合。
主要贡献
总而言之,贡献如下:
- 我们提出了一种新的神经网络用于单幅图像去噪,称为MSANet。与现有方法的主要区别在于 MSANet 同时考虑并结合了尺度内特征和跨尺度互补性到多尺度架构设计中,这是迄今为止第一个揭示前后的缺失部分。
- 为了利用尺度内特征并实现跨尺度互补性,我们设计了三个神经块,即 AFeB、AMB 和 AFuB,它们用于实现我们的想法,通过考虑不同尺度特征来构建与不同尺度特征相对应的尺度特定子网络。
- 在三个真实和六个合成噪声图像数据集上进行了广泛的实验,以显示MSANet的有效性,以及尺度内特征的重要性。
相关工作
此处介绍了现有的单幅图像去噪方法和多尺度架构,并讨论MSANet与它们之间的主要区别。这部分写得非常好,建议仔细阅读。
网络结构
整体网络结构

![(https://img-blog.csdnimg.cn/direct/733dbc6e049f4a5c9f6b2446c78408b9.png)
MSANet的框架。它采用具有多个子网络的非对称编码器-解码器架构来捕获和融合特定于尺度的特征。此外,设计了三个神经块来利用尺度内特征并实现多尺度特征的跨尺度互补性。请注意,我们将四个尺度的特征作为展示和实验评估,在实践中允许更多的尺度。 如上图所示,MSANet采用了非对称编码器-子网络-解码器架构。具体来说,编码器采用四个残差块 [15] 来提取四个尺度的特征。第一个残差块旨在在不改变分辨率的情况下提取初始特征。其他残差块将分辨率分别降低到一半,同时将通道增加到两倍。通过编码器提取的多尺度特征,子网络旨在通过 AFeB 和 AMB 块利用它们的尺度内特征。由于多尺度特征的特征逐渐从高分辨率到低分辨率变化, 将上图中的两个底部和两个顶部子网络分别作为高分辨率分支和低分辨率分支。
两个底部子网络需要处理高分辨率特征,这些特征通常由细节和噪声的混合来表征。在不丢失细粒度图像细节的情况下,非常期望去除噪声,因此AFeB旨在自适应地保留不可缺少的细节和过滤不愉快的噪声。同时,高分辨率特征的另一个特点是上下文信息有限。相应的子网络还应该丰富上下文信息,同时保持特征分辨率不变,以免丢失细节。因此,AMB 旨在自适应地提取上下文信息特征。由于 AFeB 和 AMB 可以相互相互促进,即来自 AFeB 的低噪声特征允许 AMB 更好地捕捉图像上下文,而来自 AMB 的上下文信息特征有助于 AFeB 更好地区分噪声和细节,我们交替堆叠 AFeB 和 AMB 来构建子网络。此外,由于更高分辨率的特征通常具有更少的通道(即更少的参数),因此允许更深的子网络进一步缓解它们的缺点,例如大量噪声和有限的上下文。
与底部子网络不同,两个顶部子网络旨在利用低分辨率特征的尺度内特征,这些特征的特点是噪声更少,上下文信息更多。由于过低分辨率会破坏图像结构,因此在图像恢复过程中无法保证结构一致性。因此,我们使用 AMB 来捕获更多的图像上下文来丰富上下文信息,而不会降低特征分辨率。另外,由于低分辨率特征对噪声具有更强的鲁棒性,通道较多,顶部子网络主要由AMB组成,深度较浅,以提高效率。同时,除了分辨率最低外,顶部子网络中的第一个块和最后一个块是AFeB,用于自适应控制输入和输出特征。
为了实现跨尺度互补性,解码器由四个 AFuB 块组成,然后是一个卷积层来输出恢复的图像。更具体地说,前三个 AFuB 块将分辨率加倍并将通道减少到一半,同时自适应地采样并将细粒度细节特征转移到粗粒度上下文特征。最后的AFuB块保持分辨率和通道不变,直接从噪声输入中采样和传输图像细节,这是全局跳过连接的有效替代方案,可以避免从噪声输入中引入噪声。
对于给定的噪声输入 x,MSANet 使用编码器来提取不同尺度的特征,然后将特征馈送到不同的子网络以学习特定于尺度的特征。之后,解码器将多尺度特征与从粗到细的不同特征进行融合,得到恢复的图像
y
^
=
f
(
x
)
\hat{y}=f(x)
y^=f(x),其中f(·)表示MSANet。为了优化MSANet,我们采用了以下目标函数:
L
=
∥
y
−
y
^
∥
p
p
(
1
)
\mathcal{L}=\|y-\hat{y}\|_p^p\quad\quad\quad\quad\quad\quad\quad(1)
L=∥y−y^∥pp(1)
其中 y 是 x 的真值,p = {1, 2}。
Adaptive Neural Blocks(自适应神经块)
在本节中,将详细介绍所提出的三个神经块,这些神经块旨在学习更好的多尺度特征以进行单幅图像去噪。
Adaptive Feature Block (AFeB)
为了保持不可或缺的细节和过滤不愉快的噪声,该模块希望根据自身自适应地采样和加权输入特征
f
i
f_{i}
fi,即
{
Δ
x
,
Δ
y
,
Δ
w
}
(
x
,
y
)
=
F
(
f
i
)
,
(
2
)
\{\Delta x,\Delta y,\Delta w\}_{(x,y)}=F(f_i),\quad\quad\quad\quad\quad\quad(2)
{Δx,Δy,Δw}(x,y)=F(fi),(2)
其中F(·)用于计算相对于位置(x, y)的偏移量(∆x,∆y),以及相应的权重∆w。然后,输出特征
f
i
+
1
f_{i+1}
fi+1可以由
f
i
+
1
(
x
,
y
)
=
∑
k
w
j
∗
f
i
(
x
+
Δ
x
j
,
y
+
Δ
y
j
)
∗
Δ
w
j
,
(
3
)
\begin{aligned}f_{i+1}(x,y)=\sum^kw_j*f_i(x+\Delta x_j,y+\Delta y_j)*\Delta w_j,\quad\quad\quad\quad(3)\end{aligned}
fi+1(x,y)=∑kwj∗fi(x+Δxj,y+Δyj)∗Δwj,(3)
聚合,其中k是样本数,w表示可学习权重。通过这种方式,AFeB可以学习采样位置来指示哪些位置对恢复很重要,同时分配不同的权重来显示这些位置的重要程度。因此,AFeB保留了必不可少的细节,并过滤了令人不快的噪音,以更好地恢复。然而,禁止遍历所有位置以对输入特征中的每个位置进行采样和加权。因此,为了方便实现,AFeB采用调制可变形卷积实现式(3)中的聚合操作。具体来说,AFeB 将样本数设置为内核大小,将可学习权重设置为卷积权重。尽管此设置会降低样本数量和权重的灵活性,但它在高分辨率特征的计算中是有效的,并且可以通过堆叠 AFeB 块来缓解限制。综上所述,AFeB由卷积层F(·)、调制可变形卷积、LeakyReLU层、卷积层和跳过连接组成,即
f
o
u
t
=
f
i
+
F
c
o
n
v
(
F
r
e
l
u
(
f
i
+
1
)
)
f_{out}=f_i+F_{conv}(F_{relu}(f_{i+1}))
fout=fi+Fconv(Frelu(fi+1))
Adaptive Multi-scale Block (AMB)
高分辨率和低分辨率分支都高度期望具有上下文信息特性。对于高分辨率特征,降低分辨率会导致图像细节的丢失。对于低分辨率特征,过低分辨率会破坏恢复图像的结构一致性。因此,为了在不改变分辨率的情况下捕获更多的上下文信息,我们通过使用几个具有不同膨胀率的卷积来提出 AMB。膨胀率较大的卷积可以提供较大的接收域,不同膨胀率的多个卷积可以平滑地捕获多尺度信息。为了减少多个卷积带来的成本,AMB压缩每个卷积的通道,使所有卷积的拼接通道等于输出通道,即
f
i
+
1
=
C
o
n
c
a
t
(
{
F
k
d
(
f
i
)
∣
d
,
k
∈
N
+
}
)
,
(
5
)
\begin{aligned}f_{i+1}=Concat(\{F_{k}^{d}(f_{i})|d,k\in\mathbb{N}^{+}\}),\quad\quad\quad\quad(5)\end{aligned}
fi+1=Concat({Fkd(fi)∣d,k∈N+}),(5)
其中
f
i
f_{i}
fi和
f
i
+
1
f_{i+1}
fi+1是输入和输出特征,
F
k
d
F_k^d
Fkd是第 k 个膨胀率为 d 的卷积。由于concatenation将不同尺度的特征分配到不同的通道中,因此没有考虑多尺度特征的独特重要性。为了解决这个问题,AMB 自适应地缩放不同的通道和特征,即
c
h
=
2
∗
F
s
i
g
(
F
f
c
(
a
v
g
_
p
o
o
l
(
f
i
+
1
)
)
)
,
f
i
+
2
=
c
h
∗
f
i
+
1
,
s
p
=
2
∗
F
s
i
g
(
F
c
o
n
v
(
m
e
a
n
(
f
i
+
2
)
)
)
,
f
i
+
3
=
s
p
∗
f
i
+
2
,
,
(
6
)
\begin{aligned}\begin{aligned} &ch=2*F_{sig}(F_{fc}(avg\_pool(f_{i+1}))), \\ &\begin{aligned}f_{i+2}=ch*f_{i+1},\end{aligned} \\ &sp=2*F_{sig}(F_{conv}(mean(f_{i+2}))), \\ &\begin{aligned}f_{i+3}=sp*f_{i+2},\end{aligned} \end{aligned},\quad\quad\quad\quad(6)\end{aligned}
ch=2∗Fsig(Ffc(avg_pool(fi+1))),fi+2=ch∗fi+1,sp=2∗Fsig(Fconv(mean(fi+2))),fi+3=sp∗fi+2,,(6)
其中avg_pool是空间域上的自适应平均池化,mean表示沿通道的平均操作,
F
f
c
F_{fc}
Ffc是线性层,
F
c
o
n
v
F_{conv}
Fconv是卷积层,
F
s
i
g
F_{sig}
Fsig是sigmoid层,2 *用于控制放大(> 1)或抑制(< 1)。对于
f
i
+
3
f_{i+3}
fi+3AMB将其通过LeakyReLU层、卷积层和跳过连接,即:
f
o
u
t
=
f
i
+
F
c
o
n
v
(
F
r
e
l
u
(
f
i
+
3
)
)
.
(
7
)
f_{out}=f_{i}+F_{conv}(F_{relu}(f_{i+3})).\quad\quad\quad\quad\quad\quad\quad(7)
fout=fi+Fconv(Frelu(fi+3)).(7)
Adaptive Fusion Block (AFuB)
高分辨率特征包含大量无序的细粒度图像细节,而低分辨率特征包含大量粗粒度图像上下文信息,因此需要将细粒度图像细节转移到粗粒度图像上下文中。为此,AFuB首先将粗粒度特征上采样到细粒度特征的分辨率
f
c
o
a
r
s
e
=
F
T
C
o
n
v
(
f
c
o
a
r
s
e
l
o
w
)
,
(
8
)
f_{coarse}=F_{TConv}(f_{coarse}^{low}),\quad\quad\quad\quad\quad\quad\quad(8)
fcoarse=FTConv(fcoarselow),(8)
其中
F
T
C
o
n
v
F_{TConv}
FTConv是一个转置卷积。然后,为了解决细节无序的问题,AFuB采用粗粒度特征提供上下文信息,细粒度特征提供细节信息的方法,自适应地对细粒度特征进行采样和加权,即:
{
Δ
x
,
Δ
y
,
Δ
w
}
(
x
,
y
)
=
F
(
f
c
o
a
r
s
e
,
f
f
i
n
e
)
,
(
9
)
\{\Delta x,\Delta y,\Delta w\}_{(x,y)}=F(f_{coarse},f_{fine}),\quad\quad\quad\quad\quad\quad\quad(9)
{Δx,Δy,Δw}(x,y)=F(fcoarse,ffine),(9)
其中F(·,·)用于计算位置(x, y)相对于位置(x, y)的偏移量(∆x,∆y),以及对应的权重∆w。之后,AFuB通过将细粒度的细节传输到粗粒度上下文:
f
c
o
a
r
s
e
f
i
n
e
=
f
c
o
a
r
s
e
+
∑
j
=
1
k
w
j
∗
f
f
i
n
e
(
x
+
Δ
x
j
,
y
+
Δ
y
j
)
∗
Δ
w
j
,
(
10
)
f_{coarse}^{fine}=f_{coarse}+\sum_{j=1}^{k}w_{j}*f_{fine}(x+\Delta x_{j},y+\Delta y_{j})*\Delta w_{j},\quad(10)
fcoarsefine=fcoarse+∑j=1kwj∗ffine(x+Δxj,y+Δyj)∗Δwj,(10)
其中k是细粒度细节特征的个数,w是可学习的权重。与AFeB类似,AFuB使用卷积层作为函数F,并使用调制的可变形卷积来实现式(10)中的聚合。最后,AFuB使用一个卷积层、一个LeakyReLU层、一个卷积层和一个跳过连接来进一步细化特征,即:
f
o
u
t
=
f
c
o
a
r
s
e
f
i
n
e
+
F
c
o
n
v
(
F
r
e
l
u
(
F
c
o
n
v
(
f
c
o
a
r
s
e
f
i
n
e
)
)
)
.
(
11
)
f_{out}=f_{coarse}^{fine}+F_{conv}(F_{relu}(F_{conv}(f_{coarse}^{fine}))).\quad\quad\quad(11)
fout=fcoarsefine+Fconv(Frelu(Fconv(fcoarsefine))).(11)
实验
在本节中,我们首先介绍了实验设置,然后展示了在九个数据集上的定量和定性结果。最后,我们进行了分析实验,包括消融研究和基于特征的可视化。由于篇幅限制,我们在补充材料中给出了更多的实验细节和结果。
实验设置
在真实和合成噪声数据集上对MSANet进行了评估。对于真实噪声的评估,我们使用SIDD , RENOIR , Poly数据集进行训练,并使用SIDD Validation, Nam和DnD数据集进行测试。对于合成噪声,我们在DIV2K数据集上训练MSANet,该数据集包含800张2K分辨率的图像,通过添加噪声水平为30、50和70的加性高斯白噪声(AWGN)。我们使用彩色McMaster (CMcMaster)、彩色Kodak24 (CKodak24)、彩色BSD68 (CBSD68)进行彩色图像去噪测试,使用灰度McMaster (GMcMaster)、灰度Kodak24 (GKodak24)、灰度BSD68 (GBSD68)进行灰度图像去噪测试。
在Pytorch中实现了MSANet,并在Ubuntu 20.04上使用GeForce RTX 3090 gpu进行了所有实验。在我们的实现中,我们使用了四种尺度的特征,通道分别为32、64、128和256。此外,对于真实噪声,作者对MSANet采用L1损失函数进行了100轮实验,对于合成噪声,作者对MSANet采用L2损失函数进行了300轮实验。真实噪声训练和合成噪声训练的batch大小为16,patch大小为128。为了优化MSANet,使用Adam优化器,初始学习率设置为1e-4,并通过余弦退火策略衰减为零。在训练过程中,我们随机裁剪,翻转和旋转补丁进行数据增强。在测试中,我们使用PSNR和SSIM来评估性能。
对比实验
Comparisons on Real Noise Images
真实噪声图像的去噪是一项具有挑战性的工作,因为真实噪声通常是信号相关的,并且取决于相机内管道的空间变化。因此,我们对三个真实噪声图像数据集SIDD Validation、Nam和DnD进行去噪实验。简而言之,SIDD的验证数据集包含由智能手机捕获的1,280对256 × 256的去噪图像。Nam 包含 15 个带有 JPEG 压缩的大型图像对,我们通过遵循 CBDNet在选定的 25对512 × 512 补丁上评估 MSANet。DnD 包含 50 对由相机捕获的真实噪声干净图像,并提取 1,000对512 × 512 补丁进行测试。由于补丁的原图公开,我们通过在线提交系统获得PSNR和SSIM结果。此外,由于JPEG压缩使噪声更顽固于Nam,我们首先在SIDD和RENOIR的组合上训练模型,以评估SIDD验证和DND,然后在Poly上微调训练好的模型,对Nam进行评估。
我们将MSANet与10种模型复杂度相当的去噪方法,即CDnCNN-B、CBM3D[9]、FFDNet+、CBDNet、N3Net[31]、PD[54]、PR[46]、RIDNet[4]、SADNet和DeamNet进行了比较。在实验中,我们使用了他们的作者提供的相应的预训练模型,并参考了他们在在线投稿系统和论文中报告的结果。
表1显示了在SIDD验证数据集上的定量结果。简而言之,与其他方法相比,MSANet的PSNR和SSIM值最高,例如,与RIDNet、SADNet和DeamNet相比,PSNR增益分别为0.85dB、0.1dB和0.09dB, SSIM增益分别为0.0066、0.0015和0.0013。在图3的视觉对比中,CBDNet和PD会产生残余噪声和伪伪,RIDNet、SADNet和DeamNet会严重破坏纹理并获得过度平滑的结果。相比之下,我们的方法MSANet恢复纹理和结构更精细,恢复效果更清晰。一些区域通过彩色矩形突出显示,建议放大以获得更好的可视化效果。
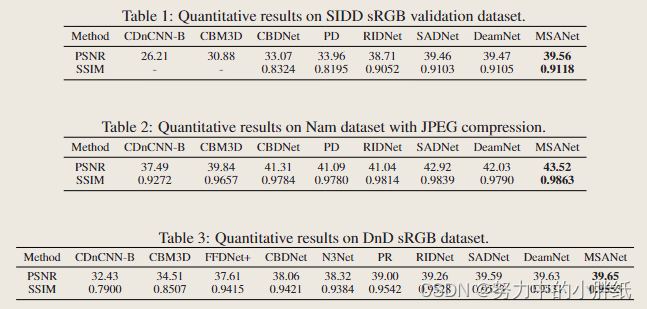

&emsp在Nam数据集上的定量结果如表2所示,这表明我们的方法比其他方法取得了显著的改进。具体而言,MSANet在PSNR (SSIM)值上优于RIDNet为2.48dB (0.0049), SADNet为0.6dB (0.0024), DeamNet为1.49dB(0.0073)。在图4所示的视觉对比中,我们的方法在细节恢复和去噪方面的效果最好,比其他方法的结果更接近原图情况。

&emsp表3报告了DnD数据集的定量结果,该数据集来自DnD基准网站。从表中可以观察到,MSANet在PSNR和SSIM值方面优于所有方法。此外,我们进一步对DnD数据集进行了定性比较。如图5所示,其他方法得到的结果是模糊的,许多图像细节被噪声腐蚀,而我们的方法可以有效地去除噪声,获得更清晰的细节。

Comparisons on Synthetic Noise Images
此处省略…
消融实验
进行消融研究以证明利用尺度内特征 (WSC) 和跨尺度互补 (CSC) 的重要性。如表6所示,“ED”和“ResB”具有同源架构,分别使用统一的Identity Mapping和残差块处理不同的尺度特征。由于单独使用AFeB和AMB不能很好地利用WSC,“AFeB”/“AMB”和“AFeB+AFuB”/“AMB+AFuB”仅比“ResB”和“AFuB”分别略微提高了性能。当AFeB和AMB一起使用时,“AFeB+AMB”和MSANet(即“AFeB+AMB+AFuB”)比“ResB”和“AFuB”显著提高了性能,验证了我们关于AFeB+AMB在WSC中的作用。此外,由于CSC通过AFuB,“AFuB”和MSANet(即“AFeB+AMB+AFuB”)分别明显优于“ResB”和“AFeB+AMB”。总之,消融研究不仅证明了利用 WSC 和 CSC 的重要性,而且还显示了我们提出的解决方案的有效性。
表 6:噪声水平为 30 的 CMcMaster 的消融研究。 “ED”表示具有跳跃连接的编码器-解码器架构。“ResB”表示用剩余块替换MSANet中的块。“AFeB”、“AMB”、“AFuB”、“AFeB+AMB”、“AFeB+AFuB”和“AMB+AFuB”表示在“ResB”的基础上使用相应的块。

为了进一步证明尺度内特征的重要性,以及我们的解决方案在利用它方面的有效性,我们展示了在 MSANet 中的子网络之前(即没有)和之后(即,有)中间多尺度特征的定性比较。从图 6 可以看出,我们的子网络可以很好地利用尺度内特征,即在过滤高分辨率特征(即第 2 列和第 3 列)的不愉快噪声的同时保留不可或缺的细节,并为低分辨率特征(即第 4 列和第 5 列)捕获丰富的上下文信息。此外,不同尺度的特征表现出不同的特征和显着的跨尺度互补性,我们的 AFuB 将进一步利用。
图 6:MSANet 中中间多尺度特征的定性比较。左上角是噪声图像,左下角是对应的干净图像。从左到右,特征分辨率从高到低不等。顶行是(即没有)子网络之前的特征,底行是(即有)子网络之后的特征。

结论
在本文中,我们提出了具有三个神经块的 MSANet,即 AFeB、AMB 和 AFuB,用于单幅图像去噪。与现有的多尺度架构不同,MSANet不仅考虑了跨尺度互补性,还考虑了尺度内特征,从而提高了实验中验证的恢复性能。这项工作可以被视为发现多尺度结构设计中缺失的部分,我们将探索其他解决方案,以同时利用尺度内特征和跨尺度互补性,并研究它们在去模糊、分割等更广泛的任务中的有效性。
Broader Impact Statement
MSANet是一种专门设计的监督单幅图像去噪体系结构,需要大量的劳动来收集大量的噪声干净的图像对,因此有可能为就业提供更多机会.然而,MSANet 是一个通用的神经网络,可以用不确定的数据进行训练并用于不确定的目的,例如水印去除,这可能会损害他人的权利。此外,MSANet 涉及多尺度架构设计的新思想,可用于为不确定目的设计新的网络。此外,模型的训练和运行消耗大量电力,造成碳排放。















 2597
2597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









