







 SwinIR是一种基于SwinTransformer的图像恢复模型,通过深度特征提取和跨窗口交互,解决了传统CNN在长程依赖和内容相关性处理上的局限。实验结果表明,SwinIR在多项任务上超越了CNN和Transformer模型,表现出更好的性能和效率。
SwinIR是一种基于SwinTransformer的图像恢复模型,通过深度特征提取和跨窗口交互,解决了传统CNN在长程依赖和内容相关性处理上的局限。实验结果表明,SwinIR在多项任务上超越了CNN和Transformer模型,表现出更好的性能和效率。
文章题目:SwinIR: Image Restoration Using Swin Transformer
文章地址:https://arxiv.org/pdf/2108.10257.pdf
代码地址:https://github.com/JingyunLiang/SwinIR
应用领域:图像超分(经典、轻量级和真实世界图像超分)、图像去噪(灰度和彩色图像去噪)、JPEG压缩伪影减少
发表时间:2021
作者:Jingyun Liang 作者github主页
摘要
提出了一种基于Swin Transformer的强基线模型SwinIR,用于图像恢复。SwinIR由三部分组成:浅层特征提取、深层特征提取和高质量图像重建。特别是,深度特征提取模块由多个残差Swin Transformer块(RSTB)组成,每个块都有多个Swin Transformer层和一个残差连接。
动机(解决了什么问题)
卷积网络存在的问题:
- 图像和卷积核之间的交互是内容无关的,使用相同的卷积核来恢复不同图像区域可能不是最好的选择。
- 其次,在局部处理的原则下,卷积对于长程依赖建模并不有效
transformer:
设计了一种自注意力机制来捕获上下文之间的全局交互。然而,用于图像恢复的视觉Transformer通常将输入图像划分为固定大小(例如48*48)的块,并独立处理每个块。这种策略不可避免地会带来两个缺点:
- 便捷像素不能利用块之外的相邻像素来进行图像恢复。
- 其次,恢复的图像可能会在每个补丁周围引入边界伪影。虽然这个问题可以通过补丁重叠来缓解,但它会带来额外的计算负担。
Swin Transformer:
集成了CNN和Transformer的优点。一方面,由于局部注意力机制,它具有CNN处理大尺寸图像的优势。另一方面,它具有Transformer的优势,可以通过移位窗口方案对远程依赖关系进行建模。
创新点(如何解决的)
由此本文提出一种基于 Swin Transformer 的图像恢复模型,即 SwinIR。
更具体地说,SwinIR由三个模块组成:浅层特征提取、深层特征提取和高质量图像重建模块。
- 浅层特征提取模块使用卷积层提取浅层特征,直接传输到重建模块以保留低频信息。
- 深度特征提取模块主要由残差 Swin Transformer 块(RSTB)组成,每个块利用多个 Swin Transformer 层进行局部注意力和跨窗口交互。此外,我们在块的末尾添加了一个卷积层来进行特征增强,并使用残差连接来为特征聚合提供捷径。
- 最后,在重建模块中融合浅层和深层特征,以实现高质量的图像重建。
与流行的基于 CNN 的图像恢复模型相比,基于 Transformer 的 SwinIR 有几个好处:
- 图像内容和注意力权重之间基于内容的交互,可以解释为空间变化的卷积。
- 通过移位窗口机制实现远程依赖建模。
- 用更少的参数获得更好的性能。 例如,如图1所示,与现有的图像SR方法相比,SwinIR以更少的参数实现了更好的PSNR。
网络结构
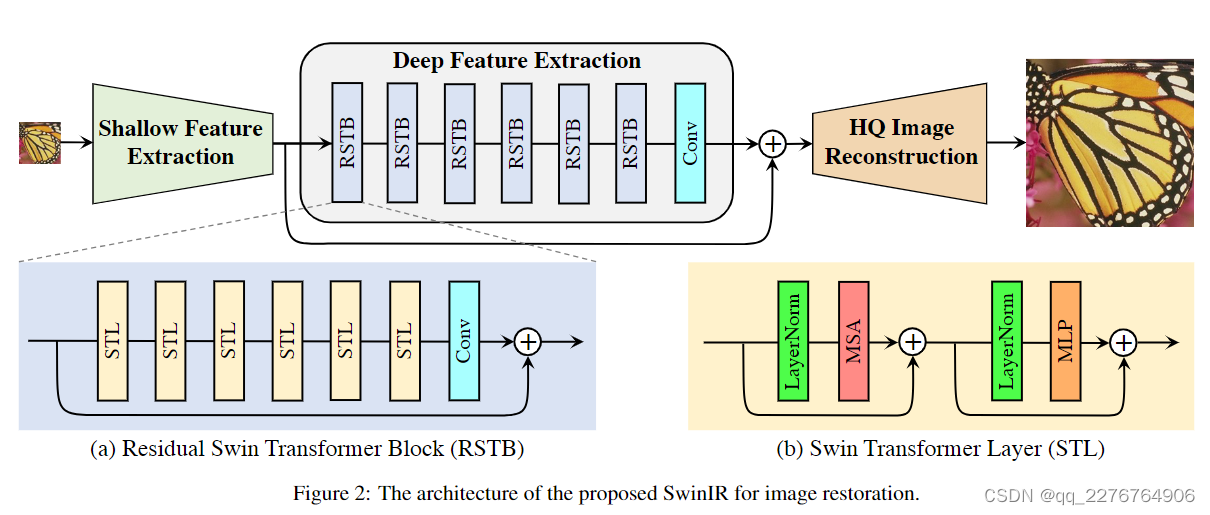
Shallow and deep Feature Extraction
使用 3 × 3 卷积层 H S F ( ⋅ ) H_{SF}(\cdot) HSF(⋅) 来提取浅层特征: F 0 = H S F ( I L Q ) F_{0}=H_{SF}(I_{LQ}) F0=HSF(ILQ),其中 C 是特征通道数。 卷积层擅长早期视觉处理,导致更稳定的优化和更好的结果。 它还提供了一种将输入图像空间映射到更高维特征空间的简单方法。从F0中提取深度深度特征: F D F = H D F ( F 0 ) F_{DF}=H_{DF}(F_0) FDF=HDF(F0)
image reconstruction
通过聚合浅层和深层特征来重建高质量图像IRH:
I
R
H
Q
=
H
R
E
C
(
F
0
+
F
D
F
)
I_{RHQ}=H_{REC}(F_0+F_{DF})
IRHQ=HREC(F0+FDF)。
其中HREC(·)是重建模块的函数。 浅层特征主要包含低频,而深层特征侧重于恢复丢失的高频。 通过长跳跃连接,SwinIR可以将低频信息直接传输到重建模块,这可以帮助深度特征提取模块专注于高频信息并稳定训练。 为了实现重建模块,图像超分任务时使用亚像素卷积层对特征进行上采样,图像去噪和JPEG压缩伪影减少使用单个卷积层进行重建。
此外,使用 残差学习 来 重建LQ和HQ之间的残差,而不是HQ图像,这被表述为:I_{RHQ}=H_{SwinIR}(I_{LQ})+I_{LQ},其中HSwinIR(·)表示SwinIR的函数。
Loss function
对于真实世界的图像SR,结合使用像素损失、GAN损失和感知损失来提高视觉质量。对于图像去噪和JPEG压缩伪影减少,使用Charbonnier损失。
实验
实验设置
对于经典图像SR、真实世界图像SR、图像去噪和JPEG压缩伪影减少,RSTB数、STL数、窗口大小、通道数和注意力头数一般分别设置为6、6、8、180和6。 一个例外是窗口大小设置为 7 以减少 JPEG 压缩伪影,因为我们观察到使用 8 时性能显着下降,这可能是因为 JPEG 编码使用 8 × 8 图像大小。对于轻量级图像 SR,我们将 RSTB 数量和通道数量分别减少到 4 和 60。 遵循[95, 63],当使用自集成策略[51]进行测试时,我们用符号“+”标记模型,例如SwinIR+。 由于页数限制,训练和验证详细信息在补充材料中提供。
消融实验讨论
对于消融研究,我们在 DIV2K上针对经典图像 SR (×2) 训练 SwinIR,并在 Manga109上进行测试

通道数、RSTB数和STL数的影响:
我们在图 2 和 3 中展示了 RSTB 中的通道数、RSTB 数和 STL 数对模型性能的影响。 分别如图3(a)、3(b)和3©所示。 可以看出,PSNR 与这三个超参数呈正相关。 对于通道数来说,虽然性能不断提高,但参数总数呈二次方增长。 为了平衡性能和模型大小,我们在其余实验中选择180作为通道数。 对于RSTB数量和层数,性能增益逐渐饱和。 我们为它们都选择 6,以获得相对较小的模型。
补丁大小和训练图像数量的影响;模型收敛性比较。
将所提出的 SwinIR 与代表性的基于 CNN 的模型 RCAN 进行比较,以比较基于 Transformer 的模型和基于 CNN 的模型的差异。 从图3(d)可以看出,SwinIR在不同的patch尺寸上比RCAN表现更好,并且当patch尺寸更大时PSNR增益变得更大。 图 3(e) 显示了训练图像数量的影响。 当百分比大于 100%(800 张图像)时,将使用来自 Flickr2K 的额外图像进行训练。 有两个观察结果。 首先,正如预期的那样,SwinIR 的性能随着训练图像数量的增加而提高。 其次,与 IPT 中基于 Transformer 的模型严重依赖大量训练数据的观察不同,SwinIR 使用相同的训练数据比基于 CNN 的模型取得了更好的结果,即使数据集很小(即 25%, 200 张图片)。 我们还在图 3(f)中绘制了 SwinIR 和 RCAN 训练期间的 PSNR。 很明显,SwinIR 比 RCAN 收敛得更快更好,这与之前的观察结果相矛盾,即基于 Transformer 的模型经常会出现模型收敛缓慢的问题。
RSTB中残差连接和卷积层的影响
表1显示了RSTB中的四种残差连接变体:无残差连接,使用1×1卷积层,使用3×3卷积层和使用三个3×3卷积层(中间层的信道号设置为网络信道号的四分之一)。从表中,我们可以得出以下观察结果。首先,RSTB中的残差连接很重要,因为它将PSNR提高了0.16dB。其次,使用1×1卷积带来的改进很小,可能是因为它不能像 3 × 3 卷积一样提取局部邻近信息。 第三,虽然使用三个3×3卷积层可以减少参数数量,但性能略有下降。

对比实验
经典图像SR。 表 2 显示了 SwinIR(中型)和最先进方法之间的定量比较:DBPN [31]、RCAN [95]、RRDB [81]、SAN [15]、IGNN [100]、HAN [63 ]、NLSA [61] 和 IPT [9]。 正如我们所看到的,在 DIV2K 上进行训练时,SwinIR 在几乎所有五个基准数据集上针对所有比例因子都实现了最佳性能。 对于比例因子 4,最大 PSNR 增益在 Manga109 上达到 0.26dB。注意,RCAN 和 HAN 引入了通道和空间注意力,IGNN 提出了自适应补丁特征聚合,NLSA 基于非局部注意力机制。 然而,所有这些基于 CNN 的注意力机制的表现都比所提出的基于 Transformer 的 SwinIR 差,这表明了所提出模型的有效性。 当我们在更大的数据集(DIV2K+Flickr2K)上训练 SwinIR 时,性能进一步大幅提高(高达 0.47dB),比相同的基于 Transformer 的模型 IPT 实现了更好的精度,即使 IPT 使用 ImageNet(超过 1.3 M 张图像)在训练中并且具有大量参数(115.5M)。 相比之下,即使与最先进的基于 CNN 的模型(15.4∼44.3M)相比,SwinIR 的参数数量也很少(11.8M)。 至于运行时间,基于 CNN 的代表性模型 RCAN、IPT 和 SwinIR 在 1、024 × 1、024 图像上进行测试分别需要大约 0.2、4.5 秒和 1.1 秒。 视觉比较如图4所示。SwinIR可以恢复高频细节并减轻模糊伪影,产生清晰自然的边缘。 相比之下,大多数基于 CNN 的方法会生成模糊的图像甚至不正确的纹理。 与基于 CNN 的方法相比,IPT 可以生成更好的图像,但它会出现图像失真和边界伪影的问题。


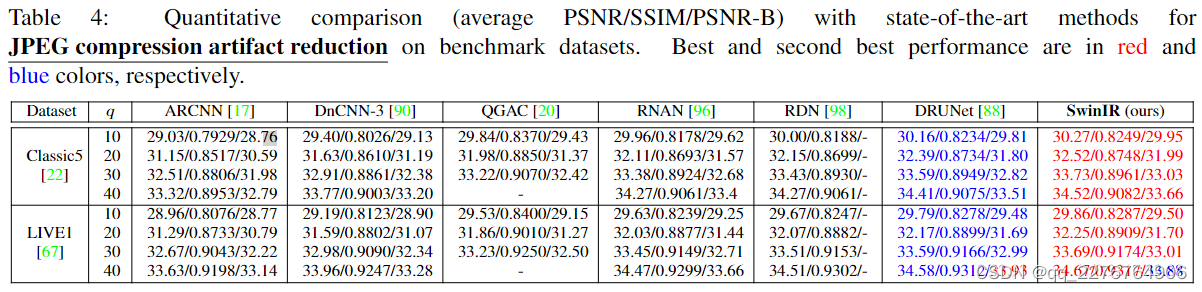
Results on JPEG Compression Artifact Reduction
表 4 显示了 SwinIR 与最先进的 JPEG 压缩伪影减少方法的比较:ARCNN [17]、DnCNN-3 [90]、QGAC [20]、RNAN [96]、RDN [98] 和 DRUNet [88] 。 所有比较的方法都是基于 CNN 的模型。 遵循[98, 88],我们在两个基准数据集(Classic5 [22] 和 LIVE1 [67])上针对 JPEG 质量因子 10、20、30 和 40 测试不同的方法。正如我们所看到的,所提出的 SwinIR 具有平均 PSNR 增益 在不同品质因数的两个测试数据集上至少为 0.11dB 和 0.07dB。 此外,与之前最好的模型DRUNet相比,SwinIR只有11.5M参数,而DRUNet是一个大型模型,有32.7M参数。
Results on Image Denoising
我们分别在表 5 和表 6 中显示了灰度和彩色图像去噪结果。 比较的方法包括传统模型BM3D [14]和WNNM [29],基于CNN的模型DnCNN [90],IRCNN [91],FFDNet [92],N3Net [65],NLRN [52],FOCNet [38],RNAN [96]、MWCNN [54] 和 DRUNet [88]。 根据[90, 88],比较的噪声水平包括15、25和50。可以看出,我们的模型比所有比较方法都取得了更好的性能。 特别是,它在拥有 100 张高分辨率测试图像的大型 Urban100 数据集上超过了最先进的模型 DRUNet 高达 0.3dB。 值得指出的是,SwinIR 只有 12.0M 个参数,而 DRUNet 有 32.7M 个参数。 这表明 SwinIR 架构在学习用于恢复的特征表示方面非常高效。 不同方法的灰度和彩色图像去噪的直观比较如图 6 所示。 6 和 7。正如我们所看到的,我们的方法可以消除严重的噪声损坏并保留高频图像细节,从而产生更清晰的边缘和更自然的纹理。 相比之下,其他方法要么过于平滑,要么过于锐利,并且无法恢复丰富的纹理。




结论
在本文中,我们提出了一种基于 Swin Transformer 的图像恢复模型 SwinIR。 该模型由三部分组成:浅层特征提取、深层特征提取和HR重建模块。 特别是,我们使用一堆残差 Swin Transformer 块(RSTB)进行深度特征提取,每个 RSTB 由 Swin Transformer 层、卷积层和残差连接组成。 大量实验表明,SwinIR 在三种代表性图像恢复任务和六种不同设置上实现了最先进的性能:经典图像 SR、轻量级图像 SR、真实世界图像 SR、灰度图像去噪、彩色图像去噪和 JPEG 压缩伪影减少,这证明了所提出的 SwinIR 的有效性和普遍性。 未来,我们会将模型扩展到其他恢复任务,例如图像去模糊和去雨。















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









