









VGG
AlexNet在LeNet的基础上增加了3个卷积层
更大更深的AlexNet(重复的VGG块)
使用可重复使用的卷积块来构建深度卷积神经网络
不同的卷积块个数和超参数可以得到不同复杂度的变种
连续使用数个相同的填充为1、窗口形状为3×33×3的卷积层
后接上一个步幅为2、窗口形状为2×22×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。
对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核优于采用大的卷积核,因为可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。例如,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量和输入输出通道数。
VGG块
import time
import torch
from torch import nn, optim
import sys
sys.path.append("..")
import dl_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
VGG网络
VGG网络由卷积层模块后接全连接层模块构成。卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输入输出通道数。全连接模块则跟AlexNet中的一样。
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
这是5个卷积块,前2块使用单卷积层,而后3块使用双卷积层。第一块的输入输出通道分别是1(下面使用的Fashion-MNIST数据的通道数为1)和64,之后每次对输出通道数翻倍,直到变为512。因为这个网络使用了8个卷积层和3个全连接层,所以经常被称为VGG-11。
实现VGG-11:
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
构造一个高和宽均为224的单通道数据样本来观察每一层的输出形状。
net = vgg(conv_arch, fc_features, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)

每次将输入的高和宽减半,直到最终高和宽变成7后传入全连接层。与此同时,输出通道数每次翻倍,直到变成512。因为每个卷积层的窗口大小一样,所以每层的模型参数尺寸和计算复杂度与输入高、输入宽、输入通道数和输出通道数的乘积成正比。VGG这种高和宽减半以及通道翻倍的设计使得多数卷积层都有相同的模型参数尺寸和计算复杂度。
获取数据和训练模型
因为VGG-11计算上比AlexNet更加复杂,出于测试的目的构造一个通道数更小,或者说更窄的网络在Fashion-MNIST数据集上进行训练。
ratio = 8
small_conv_arch = [(1, 1, 64//ratio), (1, 64//ratio, 128//ratio), (2, 128//ratio, 256//ratio),
(2, 256//ratio, 512//ratio), (2, 512//ratio, 512//ratio)]
net = vgg(small_conv_arch, fc_features // ratio, fc_hidden_units // ratio)
print(net)

模型训练:
batch_size = 64
# 如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
池化层
直接计算池化窗口内元素的最大值或者平均值。该运算也分别叫做最大池化或平均池化。在二维最大池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。当池化窗口滑动到某一位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。
例:最大池化层: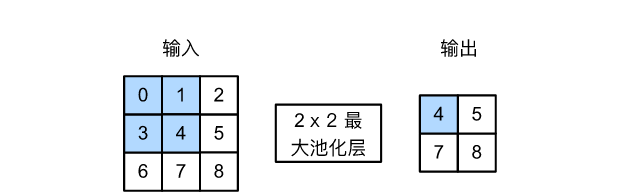
注:
(1)池化层一般位与卷积层之后,会缓解卷积层位置的敏感性,与卷积层一样有窗口大小,填充和步幅作为超参数。
(2)没有输出通道数的超参数。
(3)在多输入通道时,在每一个输入通道应用池化层以获得相应的输出通道
(4)输出通道数=输出通道数
(5)没有可学习的参数
代码实现:
import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):
X = X.float()
p_h, p_w = pool_size
Y = torch.zeros(X.shape[0] - p_h + 1, X.shape[1] - p_w + 1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
关注公众号:Time木
一起学习交流
















 4230
4230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











