







在线自适应动态规划之持续激励条件
在在线自适应动态规划算法中,需要通过满足持续激励条件(Persistent Excitation Condition)保证critic网络权值的收敛性,一般的做法都是在算法初期在输入端引入探测噪声(Probing Noises)来保证数据的丰富性,但是由于在输入端引入噪声会给系统带来一些不好的影响,甚至可能破坏系统的稳定性。
自适应动态规划这个方向涵盖得十分广,不同的团队研究的内容差异比较大。
在一些关于ADP的论文,算法明明是在线迭代的,但是并没有去讨论PE条件,不知道是不是我在哪些方面理解错了。
因此,出现了一些其他的方法来避免引入探测噪声,主要有两种:
- Concurrent Learning(CL)
- Experience Replay (ER)
下面大致谈一下这两种方法,Concurrent Learning来源于自适应控制中自适应律的设计,其实自适应动态规划的思想主要也是一种自适应控制,首先构建理想的具有未知权值的Critic,Actor网络,然后通过自适应律来计算出真实的权值。Sutton在《Reinforcement 》也指出强化学习是一种直接的自适应控制。
首先介绍一下自适应控制中的CL
1、Concurrent Learning1 2
主要思想: 除了通过当前时刻轨迹下的误差,还预先选取一些特征点,来加入到自适应律的迭代中。
不足:因为要预先记录一些特征点,所以需要模型已知,故不能扩展到无模型的自适应动态规划中。
主要思想: 记录当前时刻和过去一段时间内的贝尔曼误差用于权值更新。
首先,考虑一个如下简单的参数估计问题。

其中,
Φ
(
x
(
t
)
)
\Phi(x(t))
Φ(x(t)) 是已知的系统结构,
y
(
t
)
y(t)
y(t) 表示观测值,
W
∗
T
W^{*T}
W∗T 表示理想的权值,但是未知的,因此需要通过自适应算法估计出真实值。
另
W
(
t
)
W(t)
W(t)表示实时的估计值。则估计模型为:
v
(
t
)
=
W
T
(
t
)
Φ
(
x
(
t
)
)
v(t) = W^T(t) \Phi(x(t))
v(t)=WT(t)Φ(x(t))
则实时的估计误差为:
ϵ
(
t
)
=
v
(
t
)
−
y
(
t
)
=
W
~
T
(
t
)
Φ
(
x
(
t
)
)
=
(
W
T
(
t
)
−
W
∗
T
(
t
)
)
Φ
(
x
(
t
)
)
\epsilon(t) = v(t) - y(t) = \tilde{W}^T(t)\Phi(x(t)) = (W^T(t)-W^{*T}(t))\Phi(x(t))
ϵ(t)=v(t)−y(t)=W~T(t)Φ(x(t))=(WT(t)−W∗T(t))Φ(x(t))
其中
W
~
T
(
t
)
=
W
T
(
t
)
−
W
∗
T
(
t
)
\tilde{W}^T(t) = W^T(t)-W^{*T}(t)
W~T(t)=WT(t)−W∗T(t)
因此,我们可以构建误差的平方
V
=
0.5
ϵ
(
t
)
T
ϵ
(
t
)
V=0.5 \epsilon(t)^T \epsilon(t)
V=0.5ϵ(t)Tϵ(t),通过设计自适应律来减小V即可使得
W
~
→
0
\tilde{W} \rightarrow 0
W~→0, as
ϵ
(
t
)
→
0
\epsilon(t) \rightarrow 0
ϵ(t)→0。
一般的自适应律如下所示:
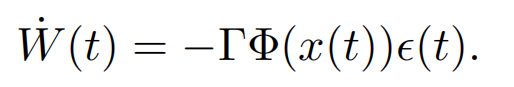
可以看到,要想
W
W
W收敛,必须保证在
W
W
W在收敛的过程中
Φ
(
x
(
t
)
)
\Phi(x(t))
Φ(x(t))持续非零。这也成为持续激励条件(PE)。详细的持续激励条件定义可以参考自适应控制的教材,这里不展开讨论。
为了满足持续激励,提出了CL的自适应律
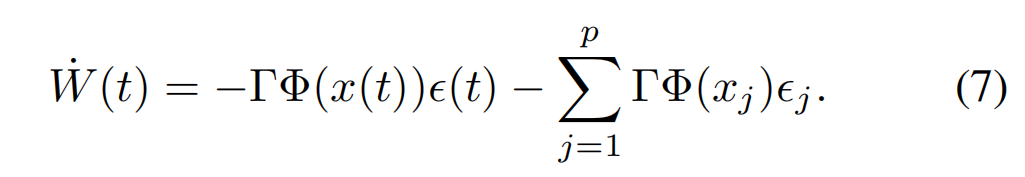
可以看到,与一般自适应律不同的是增加了后面一项。
其中,
x
j
x_j
xj表示在
x
j
x_j
xj这个位置的状态,
ϵ
j
\epsilon_j
ϵj表示在当前估计模型下
x
j
x_j
xj这个点的误差。
p
p
p表示我们选取了p个这样的特征点和误差。
直观来看,在自适应律的迭代中,除了应用到当前时刻当前轨迹的误差,还用到其他轨迹的误差来更新自适应律,相当于应用了更多了信息来更新自适应律,这样会更加有利于自适应律的收敛。
因此,CL的思想其实很简单,同时也十分容易应用到自适应动态规划的在线计算中。但是需要注意的是,CL是预先选取一些特征轨迹点,这样就需要模型是已知的,不然无法得到通过模型计算的"观测值"。这个模型可以是数学模型,也可以是数据模型,如神经网络模型。
CL在自适应动态规划中的应用
2、Experience Replay 3 4 5
【参考文献】
Chowdhary, Girish, and Eric Johnson. “Concurrent learning for convergence in adaptive control without persistency of excitation.” 49th IEEE Conference on Decision and Control (CDC). IEEE, 2010. ↩︎
Kamalapurkar, Rushikesh, Patrick Walters, and Warren E. Dixon. “Model-based reinforcement learning for approximate optimal regulation.” Control of Complex Systems. Butterworth-Heinemann, 2016. 247-273. ↩︎
Modares, Hamidreza, Frank L. Lewis, and Mohammad-Bagher Naghibi-Sistani. “Integral reinforcement learning and experience replay for adaptive optimal control of partially-unknown constrained-input continuous-time systems.” Automatica 50.1 (2014): 193-202. ↩︎
Yang, Yongliang, et al. “Online barrier-actor-critic learning for H∞ control with full-state constraints and input saturation.” Journal of the Franklin Institute 357.6 (2020): 3316-3344. ↩︎
Malla, Naresh, and Zhen Ni. “A new history experience replay design for model-free adaptive dynamic programming.” Neurocomputing 266 (2017): 141-149. ↩︎















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









