









 本文介绍了一种结合控制屏障函数(CBF)的离策略强化学习方法,用于确保安全关键系统的安全运行同时优化性能。通过在成本函数中加入CBF,平衡了安全性和最优性。提出的算法提供前瞻性的安全规划,避免了仅在约束被违反时才介入的被动策略。通过RL算法,可以在不完全了解系统动力学的情况下寻找安全的最优策略,证明了该方法在车道保持问题上的有效性。
本文介绍了一种结合控制屏障函数(CBF)的离策略强化学习方法,用于确保安全关键系统的安全运行同时优化性能。通过在成本函数中加入CBF,平衡了安全性和最优性。提出的算法提供前瞻性的安全规划,避免了仅在约束被违反时才介入的被动策略。通过RL算法,可以在不完全了解系统动力学的情况下寻找安全的最优策略,证明了该方法在车道保持问题上的有效性。
【论文复现】Safe reinforcement learning: A control barrier function optimization approach
作者:Zahra Marvi Bahare Kiumarsi
期刊:Int J Robust Nonlinear Control
时间:2020
摘要
本文提出了一种基于学习的屏障认证方法来学习安全的最优控制器,该控制器保证安全关键系统在其安全区域内运行,同时提供最佳性能。编码设计者目标的成本函数增加了控制屏障函数 (CBF),以确保安全性和最优性。 CBF 中包含一个阻尼系数,它指定了安全性和最优性之间的权衡。**提议的公式提供了前瞻性和主动的安全规划,并导致可行集中状态的平稳过渡。**也就是说,不是应用最优控制器并仅在违反安全约束时才对其进行干预,而是将安全性与性能一起规划和优化,以最大限度地减少对最优控制器的干预。结果表明,将 CBF 添加到成本函数中不会影响设计控制器在安全区域内的稳定性和最优性。该公式使我们能够迭代地找到最佳安全解决方案。**然后采用离策略强化学习 (RL) 算法来寻找安全的最优策略,而无需了解系统动力学的完整知识,同时满足安全约束。**所提出的安全 RL 控制设计方法的有效性在作为汽车控制问题的车道保持上得到了证明。
主要贡献:
将control barrier function 和Off policy reinforcement learning结合到一起,解决了强化学习控制中的安全状态约束问题。之前的文章中对于状态约束的解决办法主要可以分为:
采用基于Barrier Function的状态空间转换,将原来在一个有限约束集合的状态映射到一个新的无约束的状态中,这样可以将原有的状态受限问题转换为无状态约束的问题。这样的方法具有一个缺陷,当状态超出约束后,新状态会趋向无限大,导致系统的控制输入可能会趋向一个很大的值,这样无法保证其安全性。
本文的采用的Control barrier function就是解决这一问题
算法构建
初始过程,针对非线性系统的reinforcement learning 问题,构建Critic网络和Actor网络。分别用多项式函数来构建Actor NN,Critic NN。
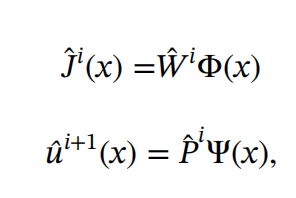
接下来,算法的核心以非线性的off policy reinforcement learning 为基础,主要的区别在构造reward时需要考虑状态约束。
算法的框架包括两个部分:
- 数据收集过程:这一个过程需要引入探测噪声来保证系统数据的丰富性,以保证后续策略迭代过程中的计算收敛。
从我阅读的文献来看,探测噪声的选取没有什么准则,和自适应控制里面提到的一样,只要输入时持续激励(Persistent Existence)就能够保证未知参数收敛到真实值,但是也没有什么特定的选取要点,一般是选取不同频率的 sin \sin sin信号,可以参考jiang[^1]
- 策略迭代过程:根据收集的数据矩阵,通过策略迭代算法迭代计算Critic网络和Actor网络的权值,直到收敛到稳定值。
策略迭代算法(Policy Iteration)是ADP中比较常用的算法,其每次迭代过程中需要计算一次Lyapunov方程,因此只需要较少的迭代次数即可收敛到近似最优解。
附上Matlab代码:
提示:代码还没有调试完,可能是探测噪声的选取或者收集数据哪里有问题,导致数据矩阵出现零特征值
clear all;clc;
global A B flag un i1;
global Q R Actor Critic;
clc;
%%
x_save=[];
t_save=[];
flag=1; % 1: learning is on. 0: learning is off.
%% 定义状态数目,输入数目
[xn,un]=size(B);
%% 设置权值
Q=2*diag([1 1 1 1]);
R=eye(1);
%% 初始化critic权值,actor权值
Critic = 50*ones(1,12);
Actor = 0.00*zeros(1,4);
%% 初始化控制参数
N = 90; %每次迭代收集的数据维数;见(44):N>l_1+m*l_2
NN = 10; %最大策略迭代次数
T=0.01; %每次积分的时间
%% 初始状态
x0 = [0.2 27.7 0.1 0.1]';
i1=(rand(1,100)-.5)*1000;
%% 存储数据的矩阵
Y = [];Dxx=[];Dxu=[];DeltaXX=[];
Reward = 0;
X = [x0;0;zeros(16,1);zeros(16,1)]'; %4+1+16+16=37
% 运行仿真,以得到数据矩阵 H, Y
% dX = [dx;dY;Dxu;DeltaXX;Dxx]; %37*
% X(end,6:9)
for i = 1:N
[t,X] = ode45(@dynamicVehicle, [(i-1)*T,i*T],X(end,:));
%% 用于计算的数据
Dxu =[Dxu;X(end,6:9)];
Y = [Y;X(end,5)];
Dxx = [Dxx;X(end,22:37)];
DeltaXX = [DeltaXX;X(end,10:21)-X(1,10:21)];
%% 轨迹
x_save=[x_save;X];
t_save=[t_save;t];
end
%% 根据所得到的数据矩阵进行策略迭代计算最优策略
CriticOld = zeros(12,1); %
iteration = 0; %迭代次数
CriticSave = [];
ActorSave = [];
while norm(CriticOld-Critic)>1e-16 && iteration<10
iteration = iteration+1;
CriticOld = Critic;
Hsave1 = DeltaXX;
Hsave2 = (Dxu*(kron(eye(4),R))-Dxx*(kron(eye(4),(Actor*R))'));
H = [Hsave1 Hsave2];
YY = Y-Dxx*vec(Actor'*R*Actor);
Weight=(H'*H)\(H'*Y);
Critic = Weight(1:12);
Actor = Weight(13:16)';
ActorSave = [ActorSave, Actor];
CriticSave = [CriticSave,Critic];
end
%% 绘制轨迹
figure(1) %critic轨迹
plot([0])
function dX = dynamicVehicle(t,X)
global A B flag un i1;
global Q R Actor;
x = X(1:4);
%% Parameters
Cr = 133000;
Cf = 98800;
a = 1.11;
b=1.59;
M = 1650;
Iz = 2315.3;
v_l0=27.7;
Rr = 0.05;
gamma1 = 0.95;gamma2 = 2;
ymin = -0.45;ymax = 0.45;
%% state
% y = x(1);
% v = x(2);
% phi = x(3);
% Psi = x(4);
%% state space
A = [0 1 v_l0 0;
0 -(Cf+Cr)/(M*v_l0) 0 (b*Cr-a*Cf)/(M*v_l0)-v_l0;
0 0 0 1;
0 (b*Cr-a*Cf)/(Iz*v_l0) 0 0;];
B = [0 Cf/M 0 a*Cf/Iz]';
k = [0 0 -1 0]';
d = 0;
%% 激活函数
Phix = [x(1)^2 x(2)^2 x(3)^2 x(4)^2 x(1)*x(2) x(1)*x(3) x(1)*x(4)...
x(1)*x(4) x(1)*x(4) x(1)*x(4) (x(1)-ymin) x(1)^4]'; % Critic网络:12个激活函数单元
Psix = [x(1) x(2) x(3) x(4)]';
if t>=5 % See if learning is stopped
flag=0;
end
if flag==1
u=zeros(1,1);
for i=i1
u=u+01*sin(i*t)/length(i1); % constructing exploration noise
end
u=-0100*u;
disp(u);
else
u= Actor*Psix;
end
dx = A*x(1:4)+B*u+k*d;
%% 奖励函数
x1 = x(1);
% dY = (-x(1:4)'*Q*x(1:4) +log((gamma1*(x1-ymin))/(gamma1*(x1-ymin)+1))...
% +log((gamma2*(-x1+ymax))/(gamma2*(-x1+ymax)+1))); %1*1
dY = -x(1:4)'*Q*x(1:4);
DeltaXX = Phix; %12*1
Dxx = kron(Psix',Psix')';% 16*1
Dxu = kron(Psix',u)'; %4*1
dX = [dx;dY;Dxu;DeltaXX;Dxx]; %37*1
end

















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









