







Diffusion 原理及attention代码详解
reference:
https://zhuanlan.zhihu.com/p/642354007
https://zhuanlan.zhihu.com/p/677234407
https://zhuanlan.zhihu.com/p/632809634
https://proceedings.neurips.cc/paper/2020/hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
0. 原理部分(DDPM )为例
0.1 扩散过程(加噪过程)
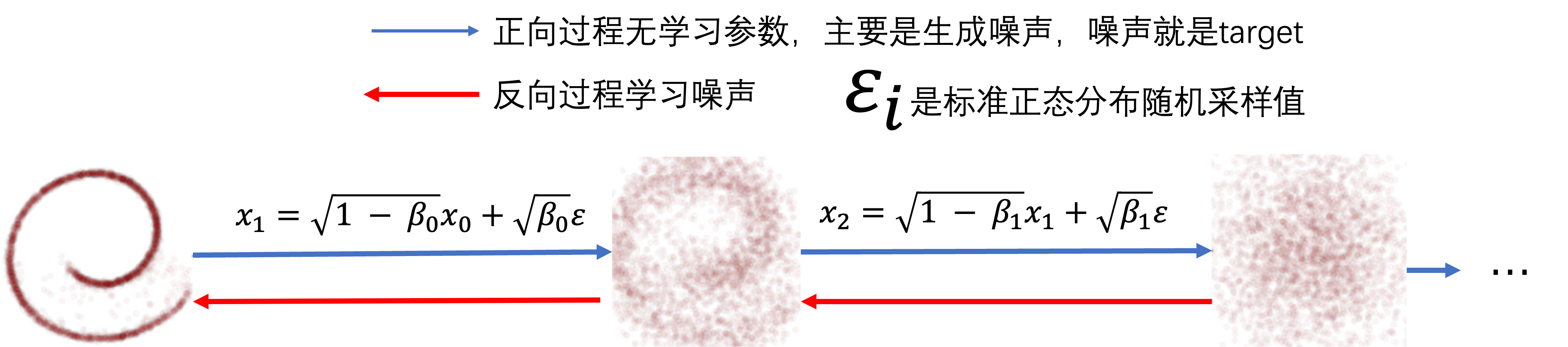
- 前向过程的每一步采样可以看作当前图像和高斯噪声的加权组合。加到最后完全变为高斯噪声。
- T = 1000,扩散1000次,采样1000次。
- β \beta β 取值 [ 1 0 − 4 , 0.02 ] [10^{-4},0.02] [10−4,0.02]。也就是说随着时间步的增大,高斯权重的噪声越来越大。
0.2 训练过程
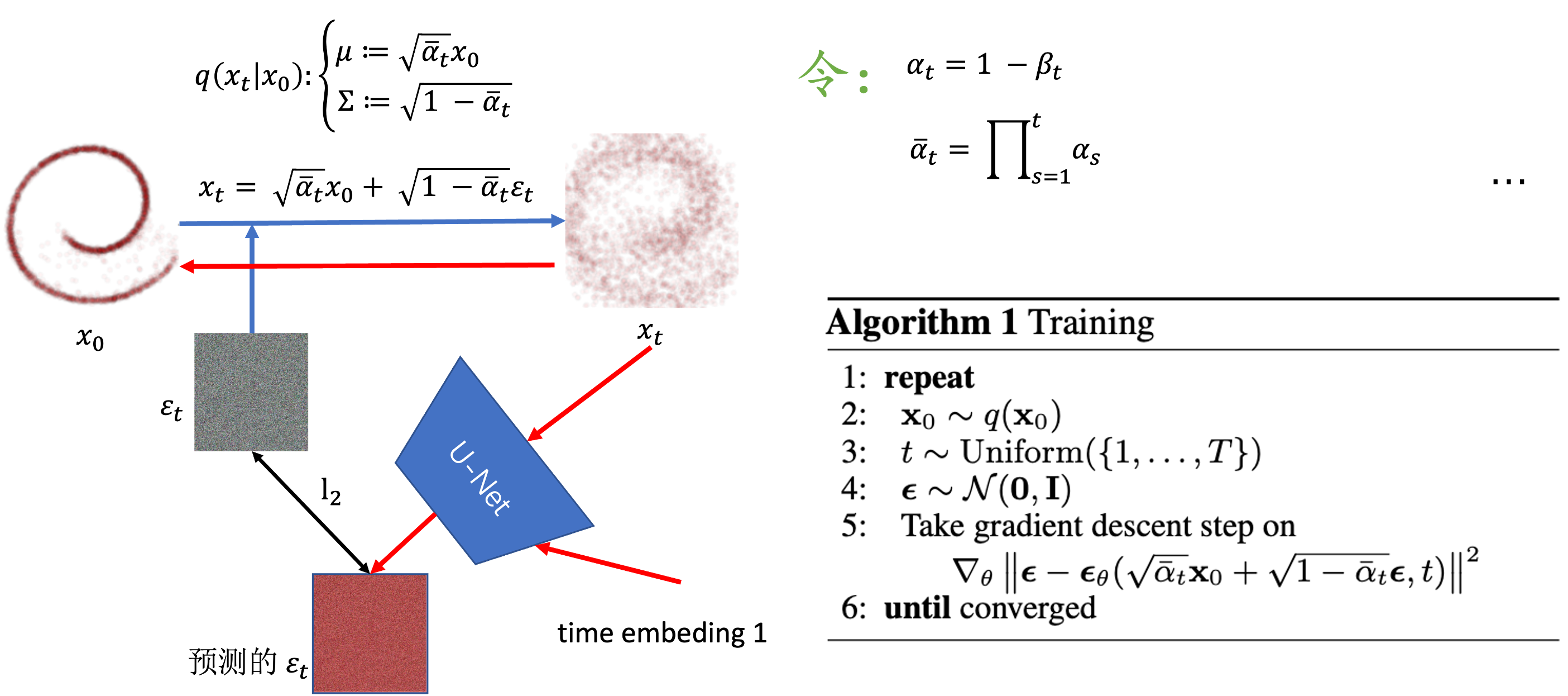
根据
x
t
=
α
t
x
t
−
1
+
1
−
α
t
ϵ
x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{1 - \alpha_t}\epsilon
xt=αtxt−1+1−αtϵ
可以推出
x
t
x_t
xt 根据
x
0
x_0
x0 的高斯采样分布为:
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
‾
t
x
0
,
1
−
α
‾
t
I
)
q(x_t|x_0) = \mathcal{N}(x_t;{\overline{\alpha}_t}x_0 ,1 - \overline{\alpha}_t I)
q(xt∣x0)=N(xt;αtx0,1−αtI)
重采样形式为:
x
t
=
α
‾
t
x
0
+
1
−
α
‾
t
ϵ
t
x_t = \sqrt{\overline{\alpha}_t}x_0 + \sqrt{1 - \overline{\alpha}_t }\epsilon_t
xt=αtx0+1−αtϵt
因此在训练过程中可以得到任意一个
x
t
x_t
xt 来计算l2误差损失。
0.3 采样过程

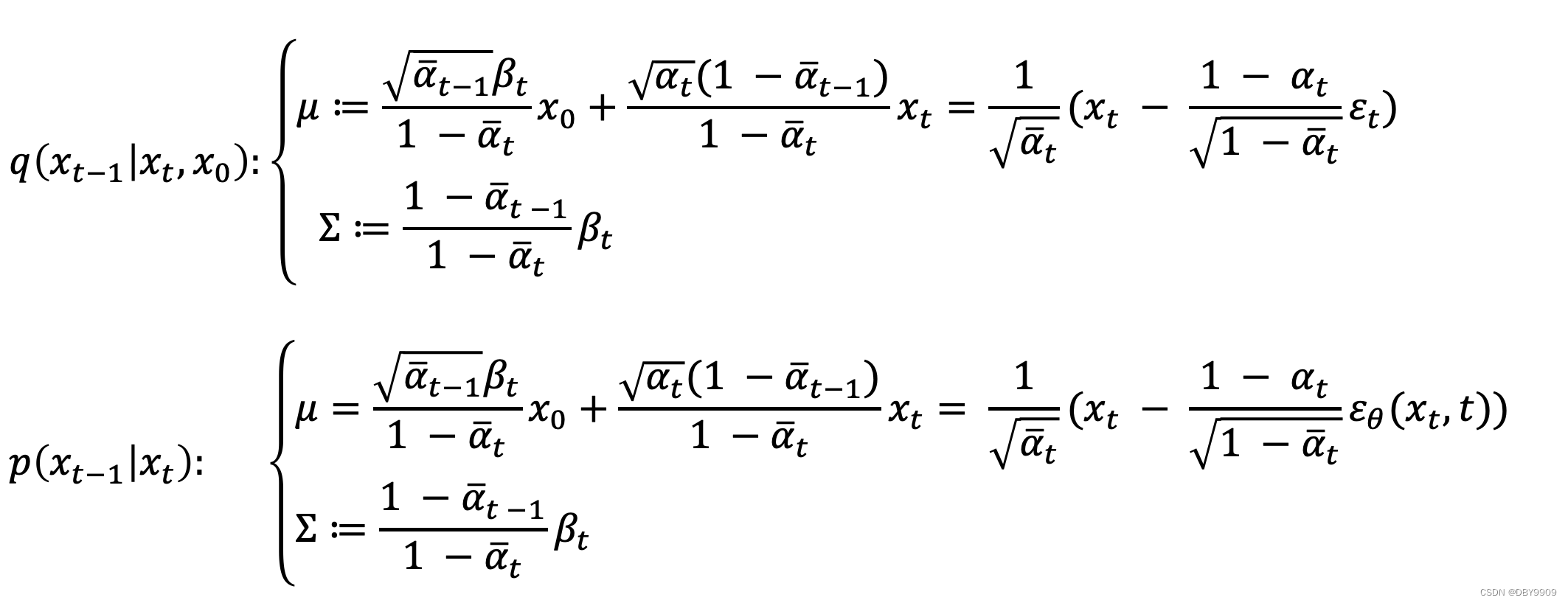
- 在扩散过程中, q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)可以根据高斯分布推到出来,也就是知道 x 0 x_0 x0 和 x t x_t xt 就可以推导出来 x t − 1 x_{t-1} xt−1 的分布。
- 但是在采样过程中,由于不知道 x 0 x_0 x0 因此 p ( x t − 1 ∣ x t ) p(x_{t-1}|x_t) p(xt−1∣xt)是未知的。需要预测噪声进而预测出一个 x 0 x_0 x0带入分布。
0.4 为什么优化目标是误差最小?
一开始优化的目标是负log似然:
−
l
o
g
P
θ
(
x
0
)
-logP_\theta(x_0)
−logPθ(x0)
然而又因为
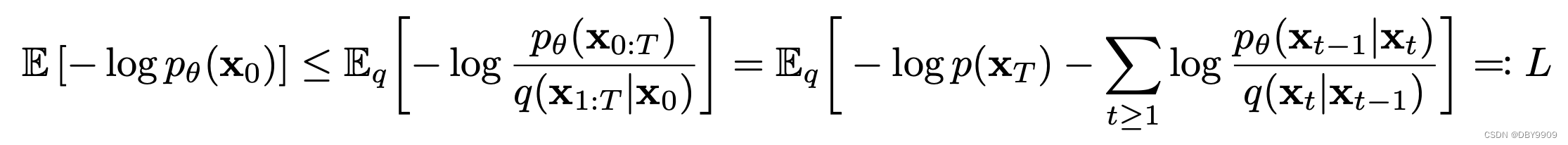
推理过程:

因此只需要优化
L
t
−
1
L_{t-1}
Lt−1就好,
L
T
L_T
LT 和
L
0
L_0
L0是定值。
让两个高斯分布的KL散度最小,就是让他们的均值和方差最小。而方差
σ
t
\sigma_t
σt 在DDPM中假设为定值
β
t
\beta_t
βt所以不优化。
均值部分为
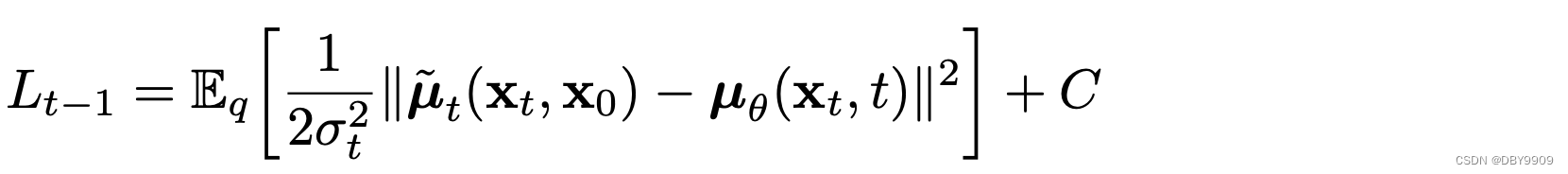
推导可以有:
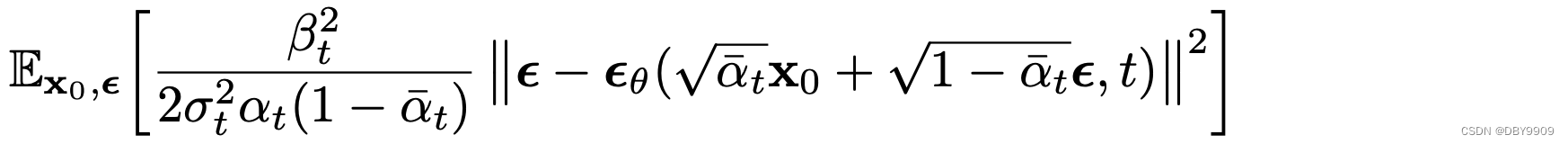
1. 核心算法
1.1 采样部分
def ldm_text_to_image(image_shape, text, ddim_steps = 20, eta = 0):
ddim_scheduler = DDIMScheduler()
vae = VAE()
unet = UNet()
zt = randn(image_shape)
T = 1000
timesteps = ddim_scheduler.get_timesteps(T, ddim_steps) # [1000, 950, 900, ...]
text_encoder = CLIP()
c = text_encoder.encode(text)
for t = timesteps:
eps = unet(zt, t, c)
std = ddim_scheduler.get_std(t, eta)
zt = ddim_scheduler.get_xt_prev(zt, t, eps, std)
xt = vae.decoder.decode(zt)
return xt
- ddim_scheduler: 包含了 α , β \alpha,\beta α,β的参数,时间步 t e m p s t e p tempstep tempstep,方差 s t d std std等信息。
- VAE 是stable diffusion 是将图像转化为隐空间的编码器。
- unet 负责根据时间步骤 t t t 以及第 t t t时刻的图像状态以及文本约束 c c c 来预测噪声。
1.2 Unet 结构
1.2.1 总体结构示意图:
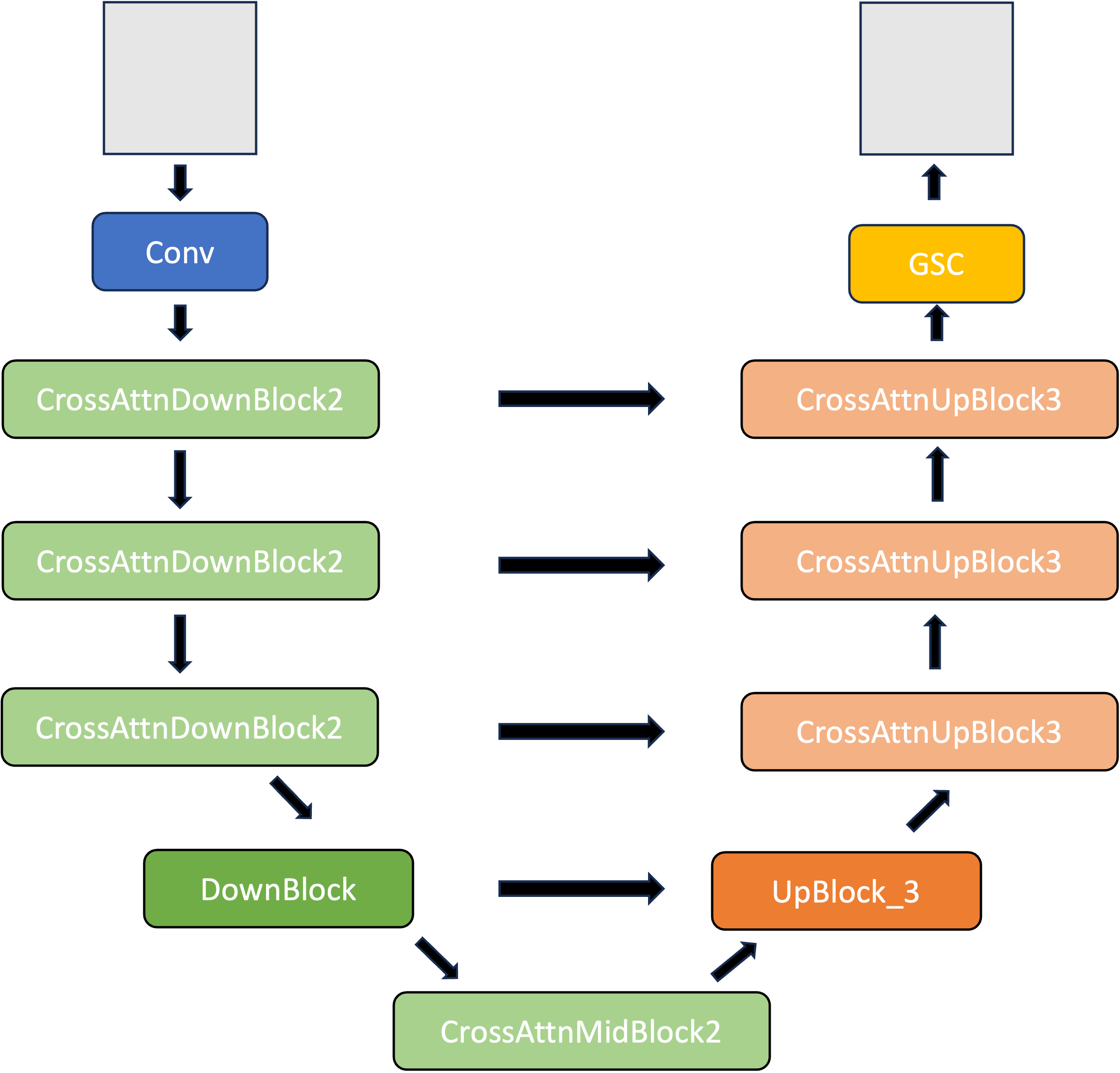
1.2.2 模块细节
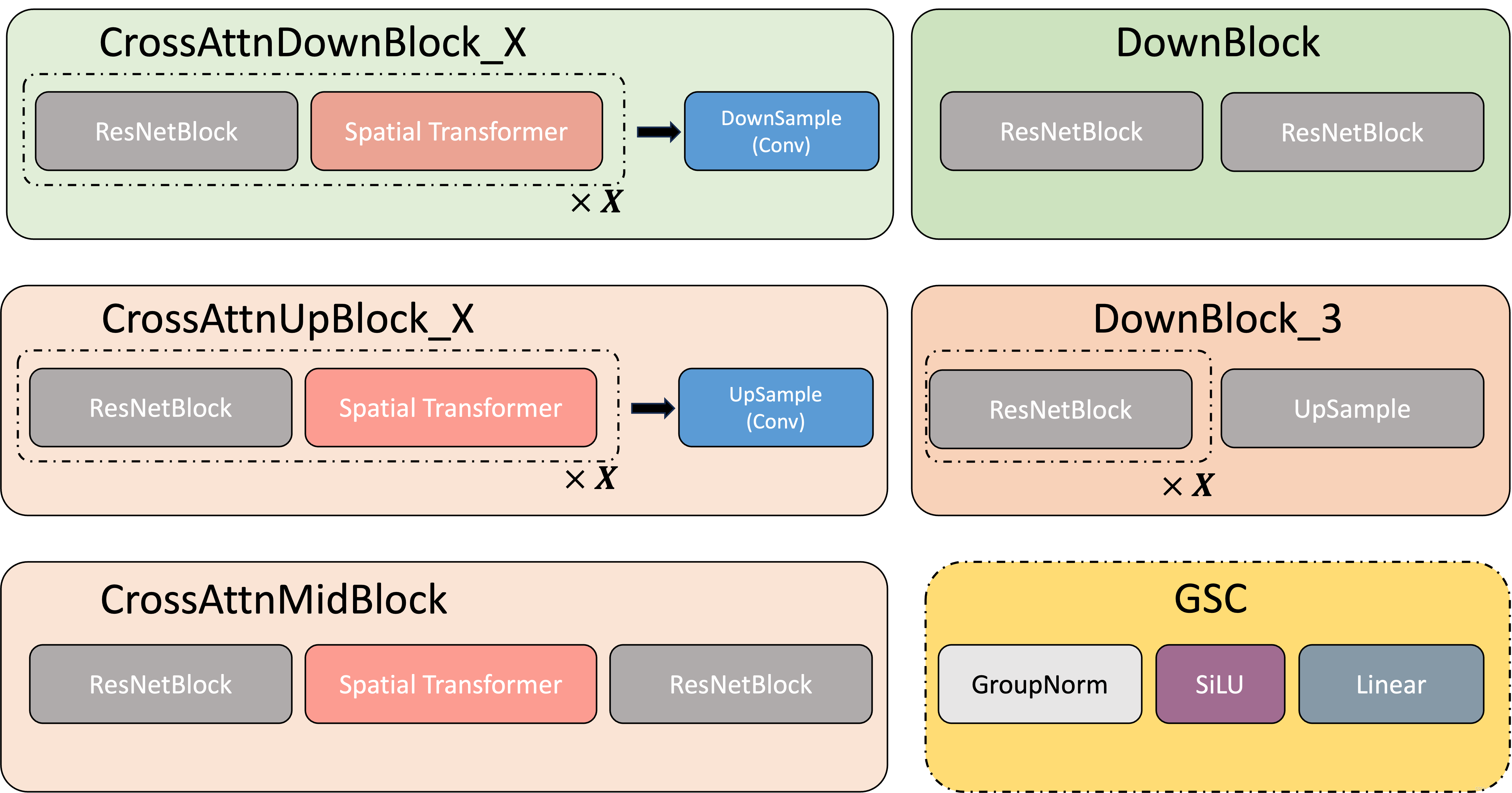
1.2.3 改进的核心模块
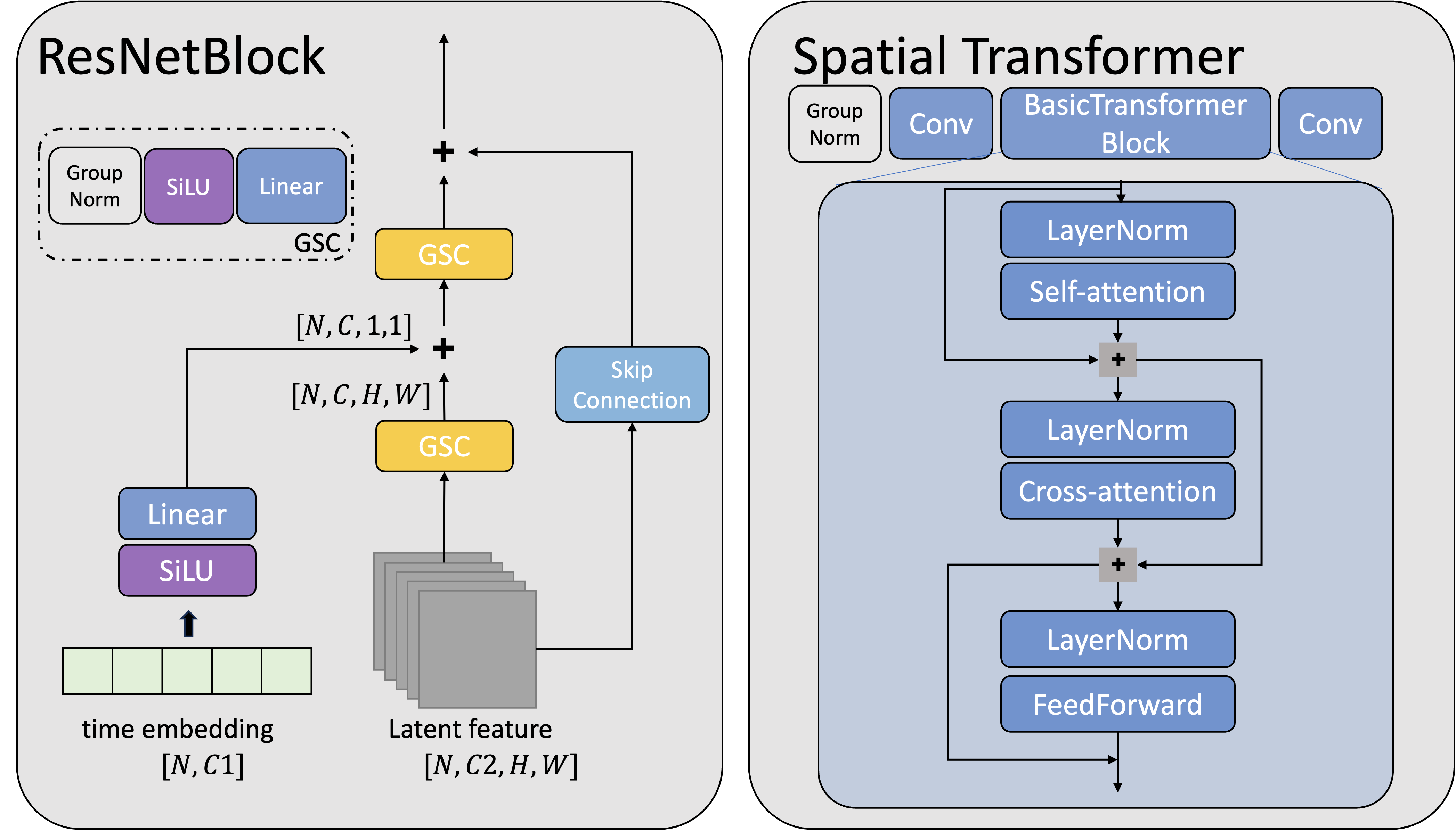
- time embedding 从ResNetBlock 中加入。相加时在H,W维度上进行了广播。
- context 文本约束从Spatial Transformer 中加入。
2. Attention 部分的修改
2.1 attn_processors字典的修改。
在Unet 中,每一个attention模块都对应一个AttentionProcessor类和实例,通过 Unset 中的 attn_processors 字典维护。
它的key 是attention 的位置或者说是网络模块的名字,在修改时需要修改attn_processors中我们想要修改部分的AttentionProcessor
例如,
attn_procs = {}
unet_sd = unet.state_dict()
for name in unet.attn_processors.keys():
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
if cross_attention_dim is None:
attn_procs[name] = AttnProcessor()
else:
layer_name = name.split(".processor")[0]
weights = {
"to_k_ip.weight": unet_sd[layer_name + ".to_k.weight"],
"to_v_ip.weight": unet_sd[layer_name + ".to_v.weight"],
}
attn_procs[name] = IPAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
attn_procs[name].load_state_dict(weights)
unet.set_attn_processor(attn_procs)
2.2 自定义的AttentionProcessor
下面是原始的AttentionProcessor,可以修改其中的逻辑,或者添加新的可以学习的变量。
例如IP-Adapter 中就加入了新的image 的cross-attention。
但是注意,_call_()中的变量不能更改。想要传入新的变量,可以cancate 到encoder_hidden_states 上。
class AttnProcessor(nn.Module):
r"""
Default processor for performing attention-related computations.
"""
def __init__(
self,
hidden_size=None,
cross_attention_dim=None,
):
super().__init__()
def __call__(
self,
attn,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
temb=None,
):
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
- attn:已经定义好的attention,不可以修改,可以用,也可不用。
- hidden_states:Transformer Block 的中间变量。
- encoder_hidden_states:文本编码器,一般是修改这个结构,例如IP-adapter 中在这里拼接了image_embedding。
- attention_mask 、temb:一般不用。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









