







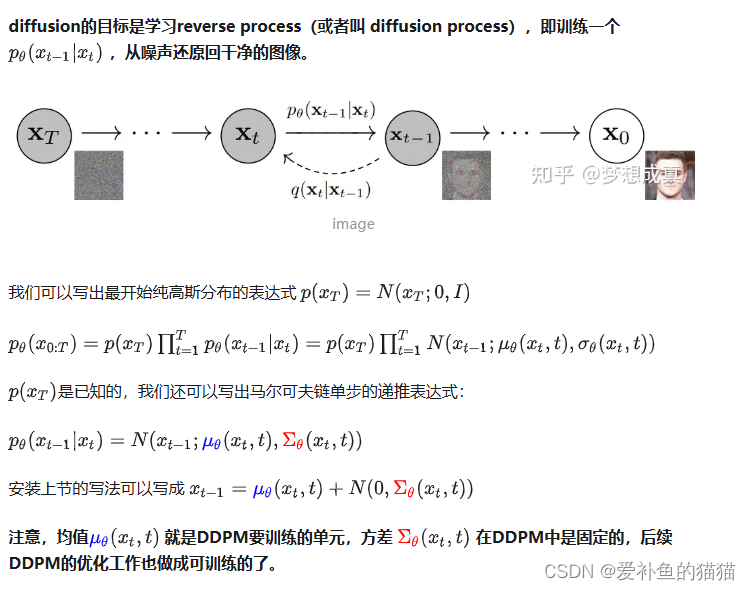
Diffusion相关原理
Diffusion Model 是一类生成模型, 和 VAE (Variational Autoencoder, 变分自动编码器), GAN (Generative Adversarial Network, 生成对抗网络) 等生成网络不同的是, Diffusion扩散模型在前向阶段对图像逐步施加噪声, 直至图像被破坏变成完全的高斯噪声, 然后在逆向阶段学习从高斯噪声还原为原始图像的过程。
1、数学:
https://blog.csdn.net/weixin_44986037/article/details/138481866?spm=1001.2014.3001.5502
- 贝叶斯公式:VAE本质上是一种基于贝叶斯框架的生成模型,其核心思想是通过联合分布p(x,z)来描述观测数据x和潜在变量z之间的关系,然后利用贝叶斯公式求解后验分布p(z∣x),从而揭示数据的潜在结构。
- KL散度:VAE在优化过程中,利用KL散度衡量潜变量分布与先验分布之间的差异,作为正则化项融入损失函数,以此推动模型学习到更接近先验分布的潜变量分布。
- 变分推断原理(变分下界):VAE的核心创新在于采用变分推断方法近似难以直接计算的后验分布p(z∣x)。通过引入一个可学习的参数化分布q(z∣x;ϕ)(即编码器),并最小化其与真实后验分布之间的KL散度,实现对后验分布的有效近似
- 重参数化:重参数化技巧,就是从一个分布 po(z)中进行采样,而该分布是带有参数 o的,如果直接进行采样(采样动作是离散的,其不可微),是没有梯度信息的,那么在BP反向传播的时候就不会对参数梯度进行更新。重参数化技巧可以保证我们从 p进行采样,同时又能保留梯度信息。
- 马尔可夫:状态空间中经过一个状态到另一个状态的转换的随机过程,该过程具备无记忆性(马尔科夫性质),即下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。

重参数化 (用于高斯拟合求导)
https://0809zheng.github.io/2022/04/24/repere.html
https://zhuanlan.zhihu.com/p/542478018
重参数化技巧,个技巧的目的是使模型可微分(differentiable),以便使用梯度下降等反向传播算法来训练模型,也就是将随机采样的过程转换为可导的运算,从而使得梯度下降算法可以正常工作。通常会有一个随机性的潜在变量,例如高斯分布中的均值和方差,用于生成样本。这会导致问题,因为采样操作是不可微的,无法通过反向传播来更新梯度,从而让模型学习这些分布参数。为了解决这个问题,“Reparameterization trick” 提出将随机采样操作从网络中移动到一个确定性函数中。这个确定性函数通常是一个线性变换,将从标准高斯分布(均值为0,方差为1)中采样的随机噪声与潜在变量的均值和标准差相结合。这个确定性函数是可微分的,因此梯度可以在这个过程中传播。
数学期望,亦简称期望),是试验中每次可能的结果乘以其结果概率的总和。



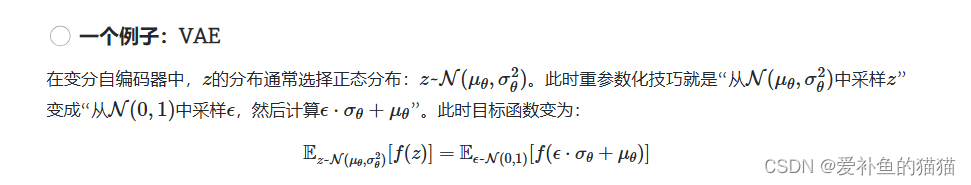
在模型训练时,采样的过程是不连续的(随机),从而会导致梯度无法反传,所以设计了一种重参数化技巧。引入可变化的噪声ε(随机,代替随机采样),保持均值和方差不变,这样就可以解决采样中断均值和方差梯度的问题。

变分推断原理 (用于损失)
https://zhuanlan.zhihu.com/p/118377754
https://zhuanlan.zhihu.com/p/88336614
变分推断的原理变分推断的目标是近似计算给定观测数据下的后验分布。它采用了一种变分参数化的方法来表示后验分布,并将推断问题转化为参数优化问题。基本的变分推断原理可以归结为最小化推断模型与真实后验分布之间的差异,以获得近似的后验分布。






例如VAE:
p(x)通过变分推断原理化为损失函数=重构损失+KL散度损失,重构损失通过重参数化将随机采样的过程转换为可导的运算,引入可变化的噪声ε(随机,代替随机采样),保持均值和方差不变,这样就可以解决采样中断均值和方差梯度的问题。

2、生成模型系列
生成模型AE、VAE、GAN、PixelCNN、VQVAE、DDPM、DDIM
https://zhuanlan.zhihu.com/p/664502140
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c190866?viewType=HTML
1、AE自动编码器(AutoEncoder)
https://zhuanlan.zhihu.com/p/664502140
它可以将图片先通过编码器获得中间隐变量,然后将隐变量通过解码器获得最终图片。
训练时使用的损失函数就是输入图片和输出图片的重构损失,Decoder就是它的生成器。此时,我们单独拿出Decoder,随机输入一些隐变量,会发现最终输出的图片是噪声。自动编码器训练时学习的是一对一映射 ,而我们随机输入的隐变量不在一对一映射中,所以不能用来生成图片。就像图中给的残月和满月的例子,我们将隐变量改成5,它能输出介于残月和满月的月亮吗?答案是否定的。因此自动编码器常常用来做图像压缩,因为图像压缩是一种一对一映射关系。

再讲VAE之前,有必要先简单介绍一下自动编码器AE,自动编码器是一种无监督学习方法,它的原理很简单:先将高维的原始数据映射到一个低维特征空间,然后从低维特征学习重建原始的数据。(函数映射)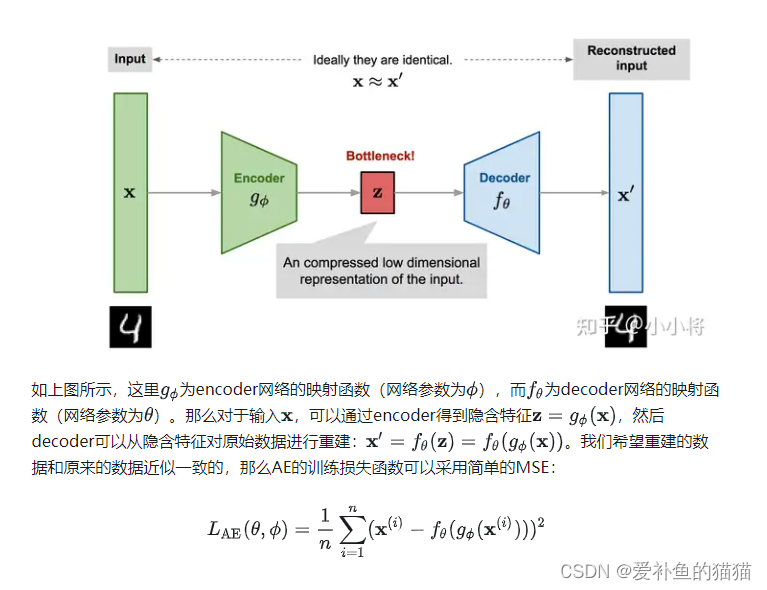
2.VAE的模型架构
https://zhuanlan.zhihu.com/p/664502140
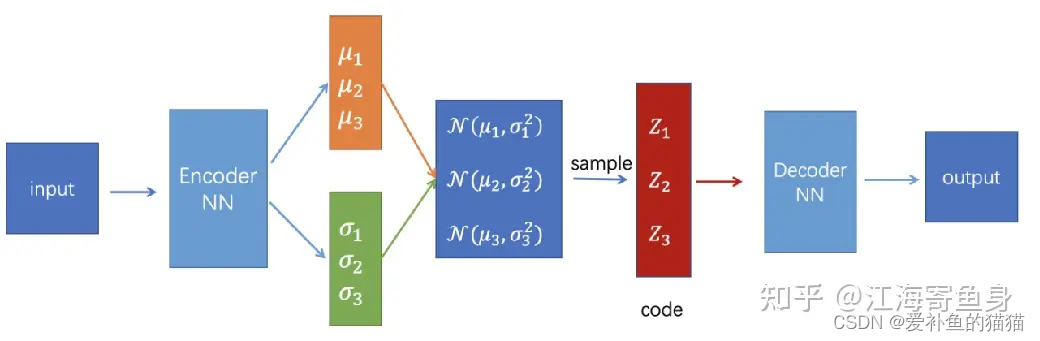
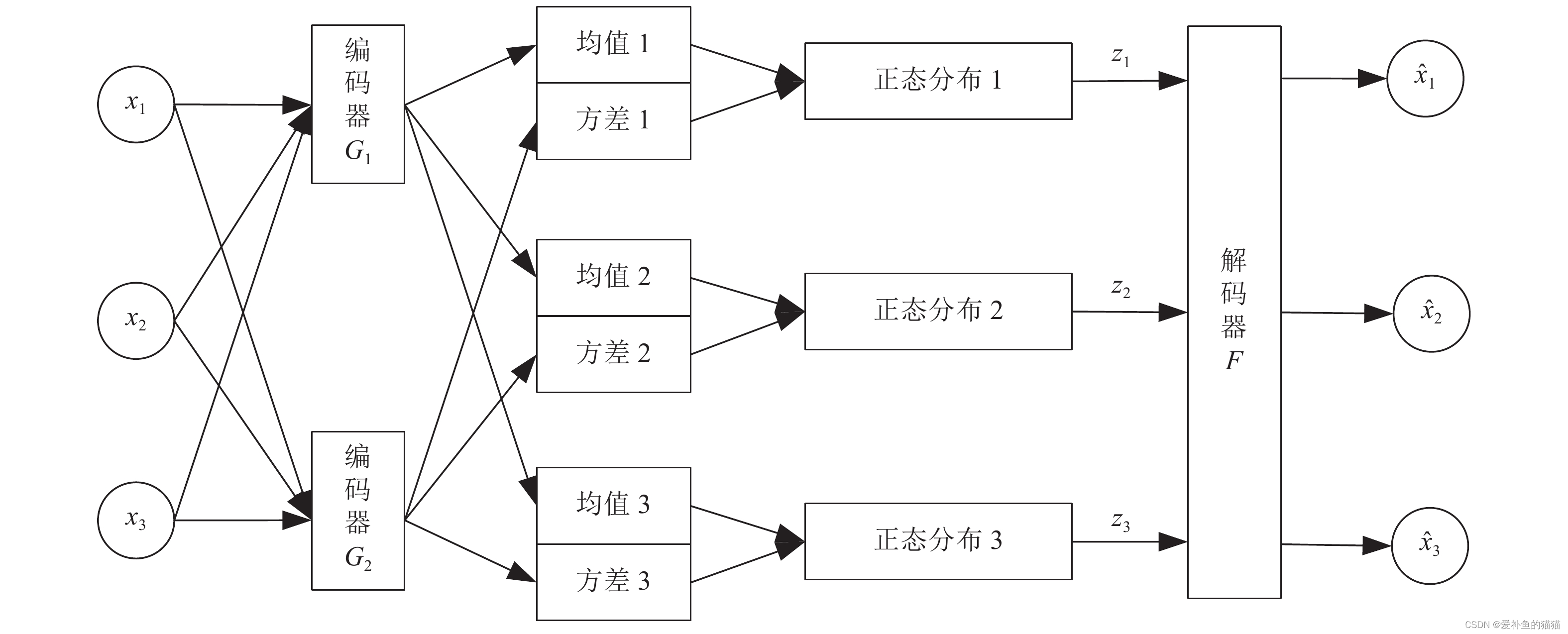
1、Encoder输出的是一系列的正态分布的均值和方差(特征提取,产生多组均值和方差提取特征,然后再对提取的特征进行采样筛选,相当于视觉中的卷积核提取特征),然后在这一系列的正态分布中采样得到隐变量,采样后的隐变量再输入到Decoder生成图片。
2、VAE的理论基础就是高斯混合模型。任何一个数据的分布,都可以看作是若干高斯分布的叠加(傅里叶变换)。所以Encoder能输出一系列的正态分布的叠加(提取多个特征)。
3、latent variable,隐变量或潜在变量,也称为latent code。隐变量是指通过模型从观测数据中推断出来的变量。比如,我们将一个输入对象送入一个神经网络的编码层(Nerual Network Encoder, NN-Encoder),得到的由隐含层输出的向量就可以称作 latent variable。
vae网络结构组成:可以大致分成Encoder和Decoder两部分(如下图)。对于输入图片,Encoder将提取得到编码:(正态分布)一个mean vector(均值)和一个deviation vector(方差),然后将这个编码(两个vector)作为Decoder的输入,最终输出一张和原图相近的图片。
声音是连续的波,理论上是由无限多个点组成,我们通过采样就可以将一个连续的波转换成离散的点。
模型原理
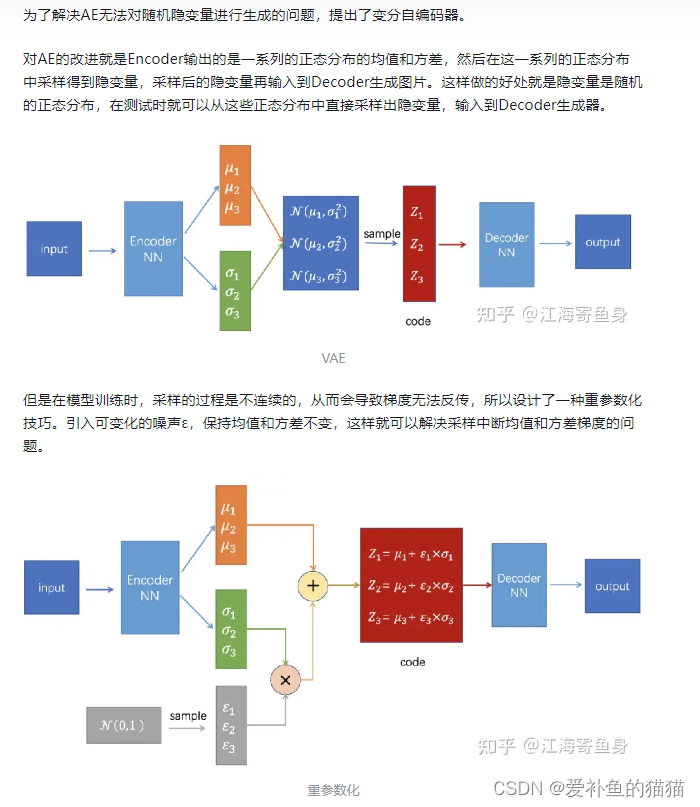
为了解决AE无法对随机隐变量进行生成的问题,提出了变分自编码器。
对AE的改进就是Encoder输出的是一系列的正态分布的均值和方差,然后在这一系列的正态分布中采样得到隐变量,采样后的隐变量再输入到Decoder生成图片。这样做的好处就是隐变量是随机的正态分布,在测试时就可以从这些正态分布中直接采样出隐变量,输入到Decoder生成器。
在模型训练时,采样的过程是不连续的(随机),从而会导致梯度无法反传,所以设计了一种重参数化技巧。引入可变化的噪声ε(随机,代替随机采样),保持均值和方差不变,这样就可以解决采样中断均值和方差梯度的问题。
Encoder输出的是一系列的正态分布的均值和方差(特征提取,产生多组均值和方差提取特征,然后再对提取的特征进行随机采样筛选特征,相当于视觉中的卷积核提取特征),然后在这一系列的正态分布中采样得到隐变量,采样后的隐变量再输入到Decoder生成图片。
算法原理
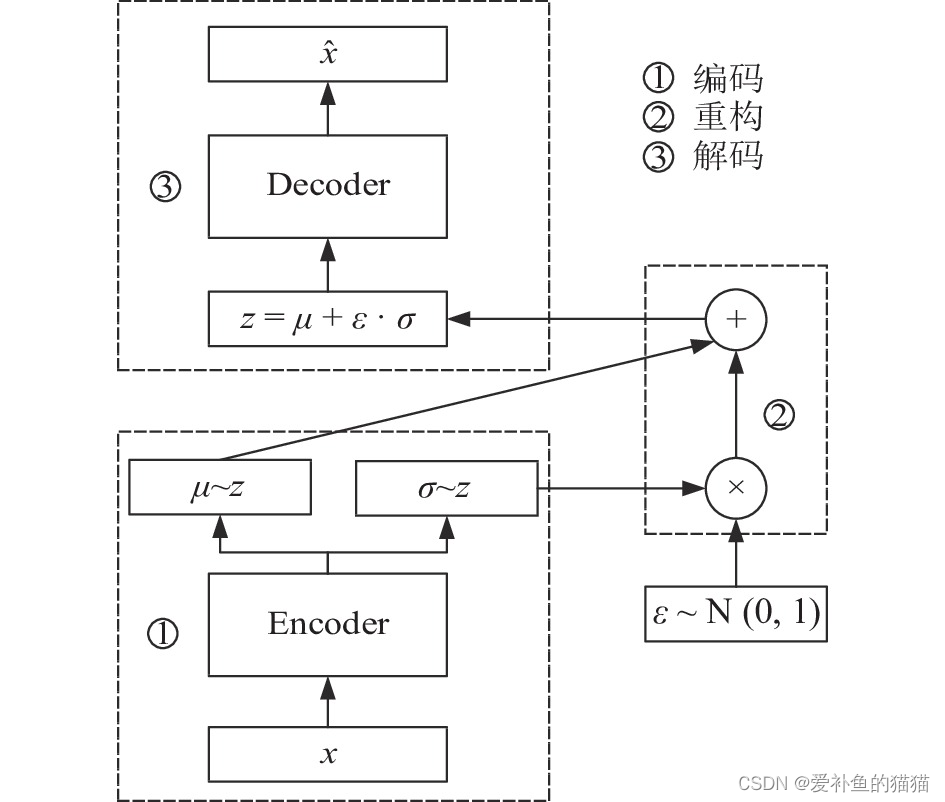
VAE由两部分构成:编码器(Encoder)和解码器(Decoder)。其工作流程如下:
- 编码阶段:给定观测数据x,编码器网络(通常是神经网络)计算出其对应潜变量z的概率分布q(z∣x;ϕ),其中ϕ是编码器网络的参数。通常假设该分布为多元正态分布,由均值向量μ和协方差矩阵Σ(或其对角线形式的方差σ²)刻画。
- 采样阶段:从上述分布中抽取一个样本,通常采用重参数化技巧(Reparameterization Trick)保证梯度可以通过采样过程反向传播。
- 解码阶段:将采样的潜变量输入解码器网络,生成重构数据。解码器的目标是学习数据生成过程,即条件概率分布p(x∣z;θ),其中θ是解码器网络的参数。
损失函数:VAE的损失函数由两部分构成:重构损失(Reconstruction Loss)和KL散度损失(KL Divergence Loss)。重构损失通常采用均方误差(MSE)或交叉熵(CE)衡量原始数据x与重构数据的差异。KL散度损失则用来约束潜变量分布接近于预设的先验分布(通常为标准正态分布)。 链接:https://blog.csdn.net/qq_51320133/article/details/137631531
数学原理
https://blog.csdn.net/a312863063/article/details/87953517
通过decode的分布,推出encode的分布,kl使他们相近。
对于生成模型而言,主流的理论模型可以分为隐马尔可夫模型HMM、朴素贝叶斯模型NB和高斯混合模型GMM,而VAE的理论基础就是高斯混合模型。这个现象从宏观上来看也是很有意思,调节P(x|z)就是在调节Decoder,调节q(z|x)就是在调节Encoder。于是,VAE的训练逻辑就变成了,Decoder每前进一步,Encoder就调节成与其一致的样子,并且站在那拿“枪”顶住Decoder,这样Decoder在下次训练的时候就只能前进,不能退步了。
定理
一般情况下,VAE的理论基础主要源于概率论、统计推断和变分推断。特别地,VAE的设计深受贝叶斯公式、KL散度以及变分推断原理的影响。补充定理,可以下几点:
- 贝叶斯公式:VAE本质上是一种基于贝叶斯框架的生成模型,其核心思想是通过联合分布p(x,z)来描述观测数据x和潜在变量z之间的关系,然后利用贝叶斯公式求解后验分布p(z∣x),从而揭示数据的潜在结构。
- KL散度:VAE在优化过程中,利用KL散度衡量潜变量分布与先验分布之间的差异,作为正则化项融入损失函数,以此推动模型学习到更接近先验分布的潜变量分布。
- 变分推断原理(变分下界):VAE的核心创新在于采用变分推断方法近似难以直接计算的后验分布p(z∣x)。通过引入一个可学习的参数化分布q(z∣x;ϕ)(即编码器),并最小化其与真实后验分布之间的KL散度,实现对后验分布的有效近似。
p(x)通过变分推断原理化为损失函数=重构损失+KL散度损失,重构损失通过重参数化将随机采样的过程转换为可导的运算,引入可变化的噪声ε(随机,代替随机采样),保持均值和方差不变,这样就可以解决采样中断均值和方差梯度的问题。
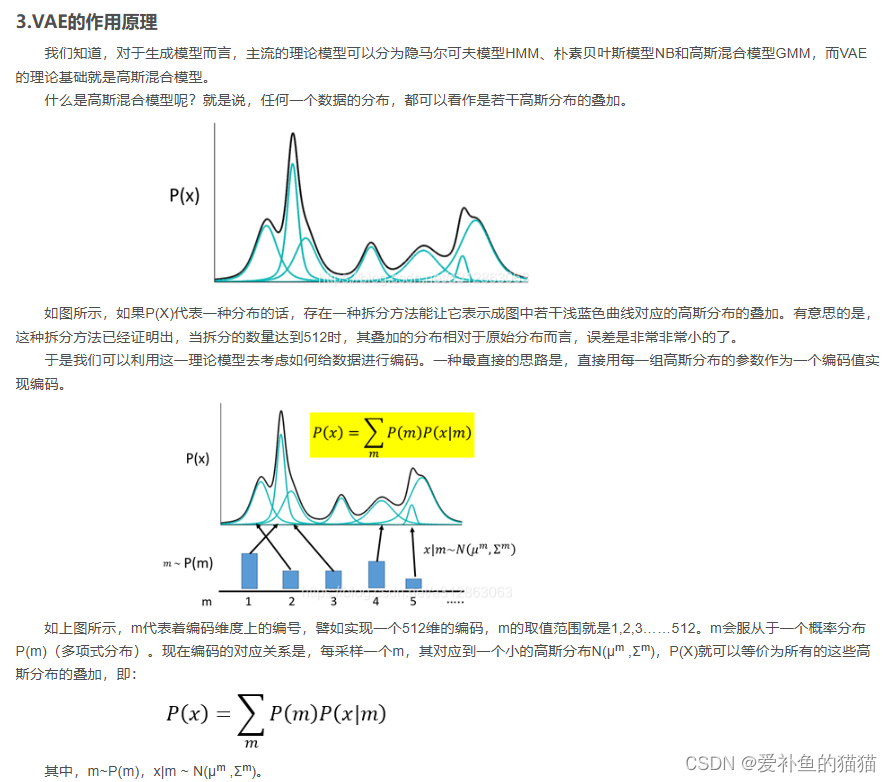


Z 所在的潜在空间通常是高维且包含复杂相互作用的,直接去积分来计算 p(X) 几乎是不可能的,于是乎,我们就需要将这个问题简化、近似化。于是,变分下界(Evidence Lower BOund,ELBO)的概念呼之欲出。
变分下界

AE和VAE对比
AE为什么不能用于图像重构?
VAE(Variational Autoencoder)是一种基于生成模型的无监督学习方法,常用于图像生成和特征提取。然而,VAE并不擅长图像重构,即从编码空间中的隐变量中重构出原图像。这是因为VAE在训练过程中使用了KL散度来约束隐变量的分布,导致编码空间变得过于平滑,难以准确重构原图像。 解决VAE不能用于图像重构的方法是使用更适合图像重构的模型,如GAN(Generative Adversarial Network)或AE(Autoencoder),或对VAE进行一些修改,例如引入更合适的损失函数和正则化项。以下是一个修改后的VAE代码示例,引入了像素差损失(Pixelwise Difference Loss)和L1正则化项(L1 regularization)。
VAE 与 AE 进行比较
我们上文已经介绍了 AE ,它和 VAE 很像,VAE 和 AE 是两种常见的无监督学习模型,用于数据压缩、特征学习和生成模型等任务。下面比较相似之处和不同之处。
-
相似之处:
基本结构:VAE 和 AE 都由 Encoder 和 Decoder 组成。Encoder 将输入数据映射到潜在空间中的编码表示,Decoder 则将潜在空间中的编码恢复为重构的输出数据。
无监督学习:VAE 和 AE 都是无监督学习模型,不需要标注的训练数据,只使用输入数据本身进行训练。 -
不同之处:
潜在空间的表示:AE 的潜在空间是确定性的,即编码后的表示是确定的固定向量。而 VAE 的潜在空间是概率性的,即编码后的表示是均值和方差的分布,使得潜在空间具有连续性和采样性质。
模型训练目标:AE 通过最小化重构误差来学习数据*的低维表示,即尽量恢复输入数据本身。而 VAE 不仅要最小化重构误差,还要最大化潜在空间的先验分布与编码后的分布之间的相似性,通过最小化重构损失和正则化损失来训练模型。
生成能力:由于 VAE 的潜在空间具有连续性和采样性质,可以从潜在空间中采样生成新的样本,具有一定的创造性和多样性。而 AE 没有显式的生成过程,只能通过编码和解码的过程来重构输入数据。
3、DDMP
https://zhuanlan.zhihu.com/p/563661713
https://blog.csdn.net/qq_45752541/article/details/127956235
https://blog.csdn.net/Stetman/article/details/131396154
在2020年提出的Denoising Diffusion Probabilistic Models 让用扩散模型进行图像生成开始变成主流。大家通常说的扩散模型也就是这个DDPM。由于在从噪声恢复到目标图像的过程中,特征维度是一致的,在DDPM中采用的是U-Net的结构,在T步的反向过程中,U-Net模型是参数共享的,为了能告知U-Net模型现在是反向传播的第几步,在每一步反向传播时会增加一个time embedding,其实现和transformer中的position embedding相似。
图像高斯加噪
概述:所谓高斯噪声是指它的概率密度函数服从高斯分布(即正态分布)的一类噪声。其噪声位置是一定的,即每一点都有噪声,但噪声的幅值是随机的。
前向过程
重参数化和反重参数化过程,其中每一步εt就是重参数。通过高斯噪声采样得到 xt 的过程在 diffusion 中都对应Et重参数。每一步Xt都用到一个高斯分布的噪声,不同t之间所用的噪声是不同的高斯噪音分布。N高斯分布是每一步的噪声,不是图像的高斯分布。时间T是一个马尔可夫过程。

重复如下步骤,直到收敛:
- 根据 loss 函数,开始梯度下降更新模型参数
- 对图片添加噪音
- 从高斯分布的噪音等级中选取某个等级的噪音 ε (ε为重采样参数,q(Xt,Xt-1)=N(…),这里的N()正态分布是噪音的密度分布)
- 在有限时间序列从 1 - T 的某个时刻 t
- 从训练集的数据分布中抽取一个样本(图片)X0








逆向过程
通过计算后验分布,可以用前向过程来计算该过程的噪声分布的均值和方差。
https://zhuanlan.zhihu.com/p/563661713






目标函数
变分推断,拟合损失函数。


模型设计
噪音和原始数据是同维度,用unet预测噪声,计算预测噪声与真实噪声的误差(loss)。
前面我们介绍了扩散模型的原理以及优化目标,那么扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以我们可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。如下所示:
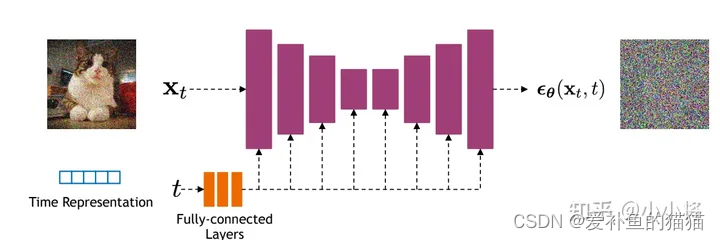
U-Net属于encoder-decoder架构,其中encoder分成不同的stages,每个stage都包含下采样模块来降低特征的空间大小(H和W),然后decoder和encoder相反,是将encoder压缩的特征逐渐恢复。U-Net在decoder模块中还引入了skip connection,即concat了encoder中间得到的同维度特征,这有利于网络优化。DDPM所采用的U-Net每个stage包含2个residual block,而且部分stage还加入了self-attention模块增加网络的全局建模能力。 另外,扩散模型其实需要的是
个噪音预测模型,实际处理时,我们可以增加一个time embedding(类似transformer中的position embedding)来将timestep编码到网络中,从而只需要训练一个共享的U-Net模型。具体地,DDPM在各个residual block都引入了time embedding,如上图所示。
4、DDIM(ddmp加速)
https://zhuanlan.zhihu.com/p/666552214


5、Diffusion Model发展史(文生图)
https://zhuanlan.zhihu.com/p/672700039
https://arthurchiao.art/blog/rise-of-diffusion-based-models-zh/
最近两年文生图模型越来越火,迭代速度越来越快,生成图片的效果也越来越好。像OpenAI的DALLE系列、Google的Imagen系列以及StableDiffusion等。每一次迭代都解决了之前图像生成的经典问题,像之前生成人物的图像中很难生成正确的手指数量,现在以及可以正确生成并且人物生成的效果也越来越逼真。这些目前最火的文生图方法大部分都是基于扩散模型改进而来的,今天给大家介绍扩散模型的发展历史以便可以更加全面的理解Diffusion Model。
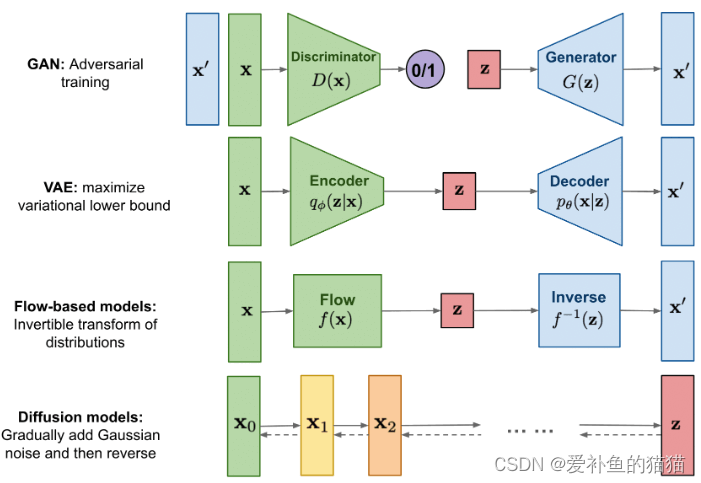
几种图像生成模型:GAN/VAE/Flow-based/Diffusion
扩散模型最早由文章Deep unsupervised learning using nonequilibrium thermodynamics
在2015年提出,其目的是消除对训练图像连续应用的高斯噪声,可以将其视为一系列去噪自编码器。该文章基于马尔可夫链将一个分布变成另外一个分布,从而可以从一个已知的分布(高斯分布,基于此分布可以得到噪声的图片)得到一个目标分布(基于此分布可以得到目标图像)。
在2020年提出的Denoising Diffusion Probabilistic Models 让用扩散模型进行图像生成开始变成主流。大家通常说的扩散模型也就是这个DDPM。由于在从噪声恢复到目标图像的过程中,特征维度是一致的,在DDPM中采用的是U-Net的结构,在T步的反向过程中,U-Net模型是参数共享的,为了能告知U-Net模型现在是反向传播的第几步,在每一步反向传播时会增加一个time embedding,其实现和transformer中的position embedding相似。
2021年提出的Diffusion models beat GAN on image Synthesis 首次提出了classifier guidance diffusion,额外训练一个分类器来指导扩散模型生成图像。在扩散模型的生成过程中的中间的latend code会通过分类器计算得到一个梯度,该梯度会指导扩散模型的迭代过程。分类器能更好的告诉U-Net的模型在反向过程生成新图片的时候,当前图片有多像需要生成的物体。此外本文从GAN的实验中得到启发,对扩散模型进行了大量的消融实验,找到了更好的架构更深更宽的模型。2022年提出了Classifier-Free Diffusion Guidance 提出无需训练分类器,也可以用生成模型自己做引导,所以起名叫“Classifier-Free Diffusion Guidance”。
引导扩散(guiding the diffusion):
如果在训练过程中向神经网络提供额外的信息,就可以引导图像的生成。
引入指导的一种方式是训练一个单独的模型,该模型作为噪声图像的分类器(classifier of noisy images)。在每个去噪步骤中,分类器检查图像是否以正确的方向去噪,并将自己的损失函数梯度计入扩散模型的整体损失中。
Openai 2021年提出了GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models 在前面扩散模型的一系列进展之后,尤其是当guidance技术之后证明扩散模型也能生成高质量的图像后。Openai开始探索文本条件下的图像生成,并在这篇论文里对比了两种不同的guidance策略,分别是通过CLIP引导和classifier-free的引导。验证了classifier-free的方式生成的图片更真实,与提示的文本有更好的相关性。并且使用classifier-free的引导的GLIDE模型在35亿参数的情况下优于120亿参数的DALL-E模型。GLIDE最大的贡献是开始用文本作为条件引导图像的生成。
GLIDE:文本引导,定向扩散,2022.04
如何使用文本信息(textual information)来引导扩散模型?
如何确保模型的质量足够好?
三个主要组件:
一个基于 UNet 的模型:负责扩散的视觉部分(visual part of the diffusion learning),
一个基于 Transformer 的模型:负责将文本片段转换成文本嵌入(creating a text embedding from a snippet of text),
一个 upsampling 扩散模型:增大输出图像的分辨率。
前两个组件生成一个文本引导的图像,最后一个组件用于扩大图像并保持质量。
GLIDE 融合了近年的几项技术精华,为文本引导图像生成带来了新的启示。 考虑到 DALL·E 模型是基于不同结构(非扩散)构建的,因此,可以说 GLIDE 开启了扩散式文生图时代。
Openai 2022年提出了dalle2 如果说前面所提到的方法将扩散模型优化到比同期gan模型指标还要好,让研究人员看到了扩散模型在生成领域的前景,那么Dalle2则将扩散模型引入了公众视野。在GLIDE取得成功之后,Openai又进一步在GLIDE上加了一些track,成为了Dalle2。
OpenAI 团队马不停蹄,在 2022 年 4 月份以 DALL·E 2 [7] 再次震撼了整个互联网。 它组合了前面介绍的 CLIP 模型和 GLIDE 架构的精华。
5 Google Imagen:删繁就简,扩散三连,2022.05
DALL·E 2 发布不到两个月, Google Brain 团队也展示了自己的最新成果 - Imagen
5.1 架构:T5-XXL + Diffusion + Diffusion + Diffusion
dalle2提出之后,图片生成工作迎来了大爆发,google提出了Imagen以及Imagen2,stability AI提出了stable diffusion以及前段时间火爆全网的Midjourney。
最近基于扩散模型的工作已经开始向3D以及视频生成,发展速度相当快。
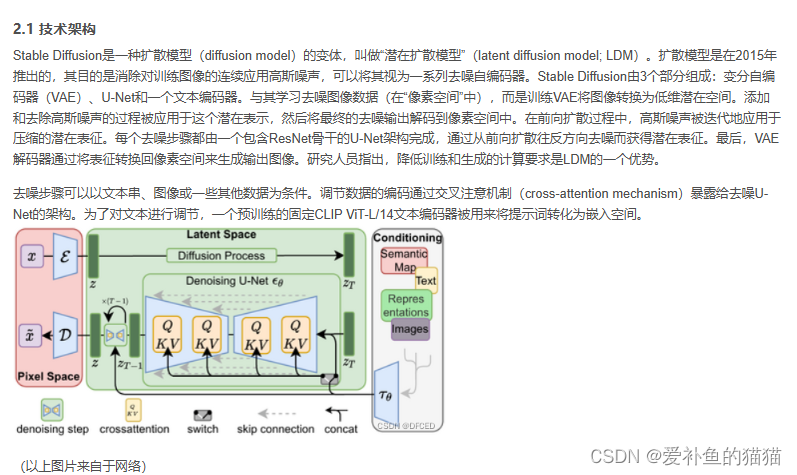
6、Stable Diffusion
https://zhuanlan.zhihu.com/p/632809634
Stable Diffusion是Diffusion的改进版。
Diffusion的缺点是在反向扩散过程中需要把完整尺寸的图片输入到U-Net,这使得当图片尺寸以及time step t足够大时,Diffusion会非常的慢。Stable Diffusion就是为了解决这一问题而提出的。后面有时间再介绍下Stable Diffusion是如何改进的。

Stable diffusion由三部分组成,UNet,VAE和CLIP。那么它为什么要使用这些模块?
2.1 UNet:找出输入的图片中有多少噪声。之后会用于去噪,Xt—>Xt-1—>X0。
2.2 VAE:512x512的图像太大了,在计算过程中对资源的占用很大。所以使用VAE将数据降维,传入UNet的特征是经过VAE的encoder和取样之后的。
2.3 CLIP:在生成图像的过程中输入的是纯噪声,如果不加干涉,模型的输出结果是不可控的。CLIP可以用来对降噪过程施加约束,从而生成符合要求的图片。
SD加噪与去噪
扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以我们可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。噪音和原始数据是同维度,用unet预测噪声,计算预测噪声与真实噪声的误差(loss)。
U-Net:预测噪声残差,结合调度算法(PNDM,DDIM,K-LMS等)进行噪声重构,逐步将随机高斯噪声转化成图片的隐特征。U-Net整体结构一般由ResNet模块构成,并在ResNet模块之间添加CrossAttention模块用于接收文本信息。
“图像优化模块”作为SD模型中最为重要的模块,“图像优化模块”是由一个U-Net网络和一个Schedule算法共同组成,U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息。而schedule算法对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度。在SD中,U-Net的迭代优化步数(Timesteps)大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)。U-Net网络和Schedule算法的工作完成以后,SD模型会将优化迭代后的Latent Feature输入到图像解码器(VAE Decoder)中,将Latent Feature重建成像素级图像。
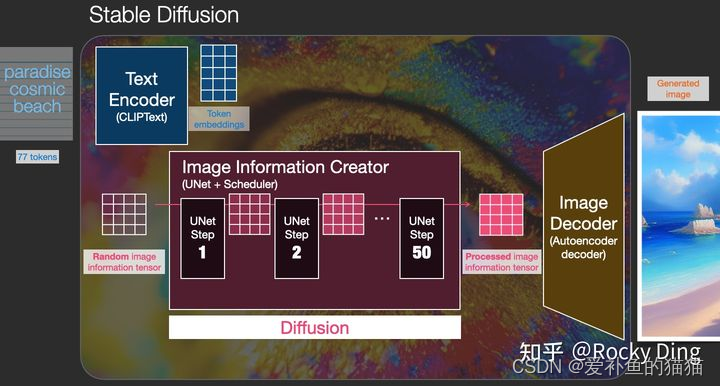
扩散模型的前向扩散过程和反向扩散过程,他们的目的都是服务于扩散模型的训练,训练目标也非常简单:将扩散模型每次预测出的噪声和每次实际加入的噪声做回归,让扩散模型能够准确的预测出每次实际加入的真实噪声。
SD训练的具体过程就是对每个加噪和去噪过程进行梯度计算,从而优化SD模型参数,如下图所示分为四个步骤:
1.从训练集中选取一张加噪过的图片和噪声强度(timestep),然后将其输入到U-Net中。
2.让U-Net预测噪声(下图中的U-Net Prediction)。
3.接着再计算预测噪声与真实噪声的误差(loss)。
4.最后通过反向传播更新U-Net的权重参数。
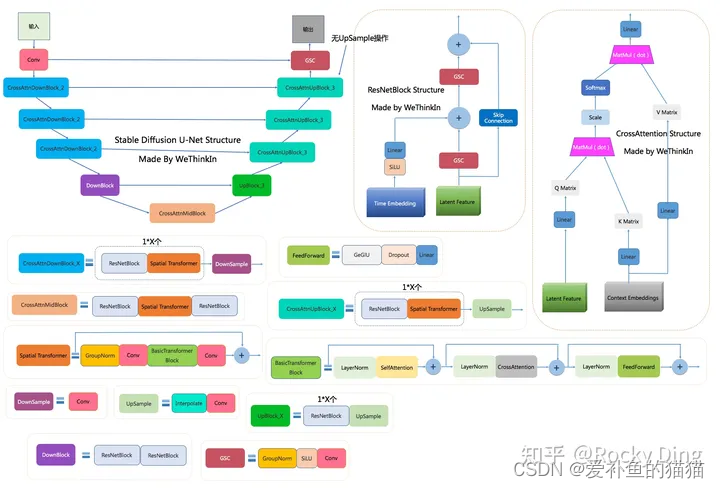
Stable Diffusion核心网络结构解析
SD模型整体架构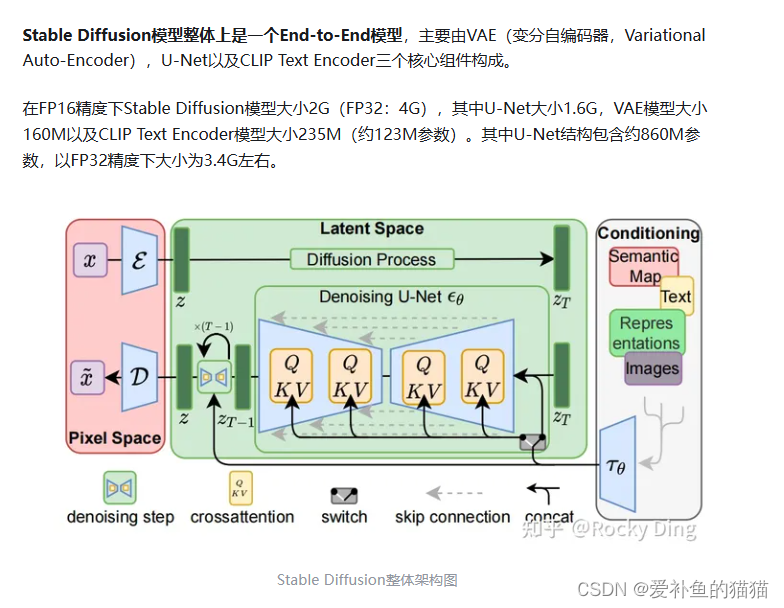
SD VAE模型
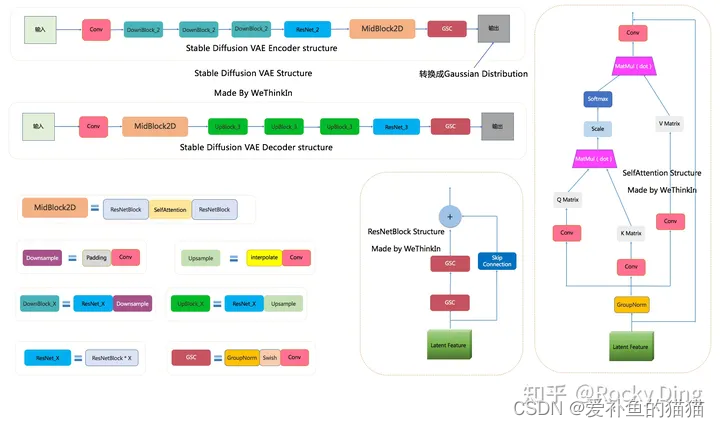
SD U-Net模型
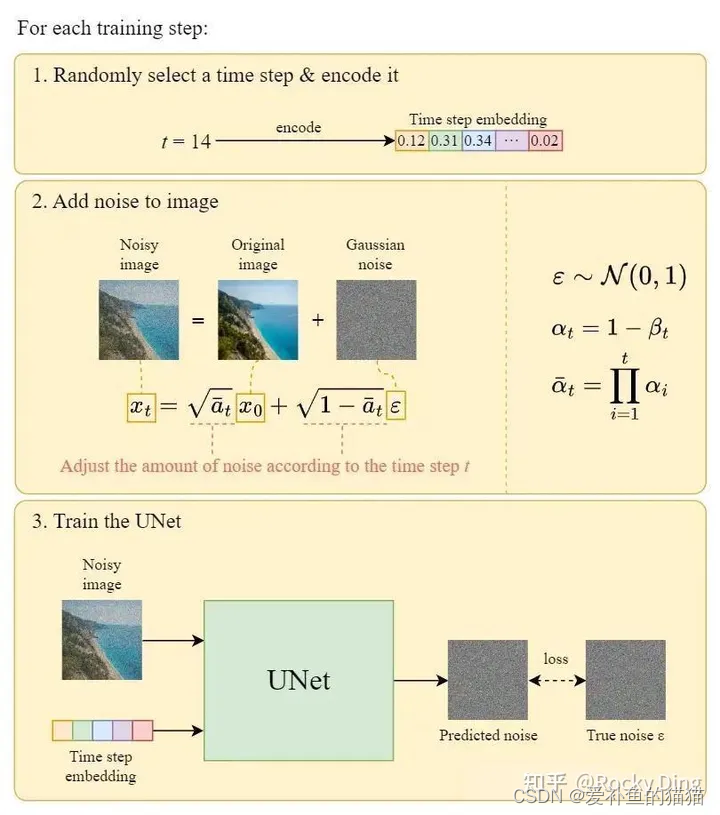
stable Diffusion训练全过程
【1】SD训练集加入噪声
SD模型训练时,我们需要把加噪的数据集输入模型中,每一次迭代我们用random函数生成从强到弱各个强度的噪声,通常来说会生成0-1000一共1001种不同的噪声强度,通过Time Embedding嵌入到SD的训练过程中。
Time Embedding由Timesteps(时间步长)编码而来,引入Timesteps能够模拟一个随时间逐渐向图像加入噪声扰动的过程。每个Timestep代表一个噪声强度(较小的Timestep代表较弱的噪声扰动,而较大的Timestep代表较强的噪声扰动),通过多次增加噪声来逐渐改变干净图像的特征分布。
【2】SD训练中加噪与去噪
Stable Diffusion的整个训练过程在最高维度上可以看成是如何加噪声和如何去噪声的过程,并在针对噪声的“对抗与攻防”中学习到生成图片的能力。Stable Diffusion整体的训练逻辑也非常清晰:
1.从数据集中随机选择一个训练样本
2.从K个噪声量级随机抽样一个timestep t
3.将timestep t对应的高斯噪声添加到图片中
4.将加噪图片输入U-Net中预测噪声
5.计算真实噪声和预测噪声的L2损失
6.计算梯度并更新SD模型参数
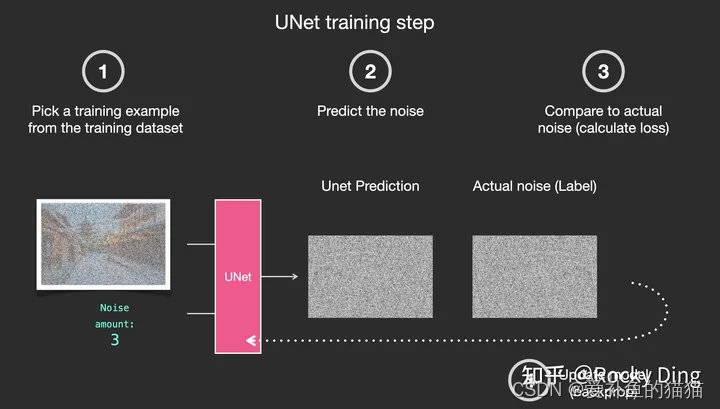
我们了解了训练中的加噪和去噪过程,SD训练的具体过程就是对每个加噪和去噪过程进行梯度计算,从而优化SD模型参数,如下图所示分为四个步骤:
1.从训练集中选取一张加噪过的图片和噪声强度(timestep),然后将其输入到U-Net中。
2.让U-Net预测噪声(下图中的U-Net Prediction)。
3.接着再计算预测噪声与真实噪声的误差(loss)。
4.最后通过反向传播更新U-Net的权重参数。
【3】文本信息对图片生成的控制
SD模型在生成图片时,需要输入prompt提示词,那么这些文本信息是如何影响图片的生成呢?
答案非常简单:通过注意力机制。在SD模型的训练中,每个训练样本都会对应一个文本描述的标签,我们将对应标签通过CLIP Text Encoder输出Text Embeddings,并将Text Embeddings以Cross Attention的形式与U-Net结构耦合并注入,使得每次输入的图片信息与文本信息进行融合训练.
【4】SD模型训练时的输入
有了上面的介绍,我们在这里可以小结一下SD模型训练时的输入,一共有三个部分组成:图片、文本以及噪声强度。其中图片和文本是固定的,而噪声强度在每一次训练参数更新时都会随机选择一个进行叠加。
SD AI绘画框架
目前能够加载Stable Diffusion模型并进行图像生成的主流AI绘画框架有四种:
diffusers框架
Stable Diffusion WebUI框架
ComfyUI框架
SD.Next框架
Stable Diffusion系列模型的性能优化
8.1 从精度角度优化Stable Diffusion系列模型的性能
8.2 从整体Pipeline角度优化Stable Diffusion系列模型的性能
8.3 从加速插件角度优化Stable
xFormers 20%
tomesd 5.4倍左右的提速
torch.compile 前向推理速度可以提升20%-30%左右
TensorRT SD系列模型的推理过程可以加速约57.14%
OneDiff 推理时加速约44.68%
Stable Fast 比起TensorRT那样需要几分钟来进行SD模型的编译,Stable Fast库只需要10-20秒左右即可以完成。
accelerate库能让PyTorch的训练和推理变得更加高效简洁
SD Turbo模型
SD Turbo模型是在Stable Diffusion V2.1的基础上,通过蒸馏训练得到的精简版本,其本质上还是一个Stable Diffusion V2.1模型,其网络架构不变。
与SDXL Turbo相比,SD Turbo模型更小、速度更快,但是生成图像的质量和Prompt对齐方面不如前者。但是在AI视频领域,SD Turbo模型有很大的想象空间,因为Stable Video Diffusion的基础模型是Stable Diffusion 2.1,所以未来SD Turbo模型在AI视频领域很可能成为AI视频加速生产的有力工具之一。
为了测试SD Turbo的性能,StabilityAI使用相同的文本提示,将SD Turbo与LCM-LoRA 1.5和LCM-LoRA XL等不同版本的文生图模型进行了比较。测试结果显示,在图像质量和Prompt对齐方面,SD Turbo只用1个step,就击败了LCM-LoRA 1.5和LCM-LoRA XL生成的图像。
3、Control Net
https://blog.csdn.net/jarodyv/article/details/132739842
https://zhuanlan.zhihu.com/p/660924126
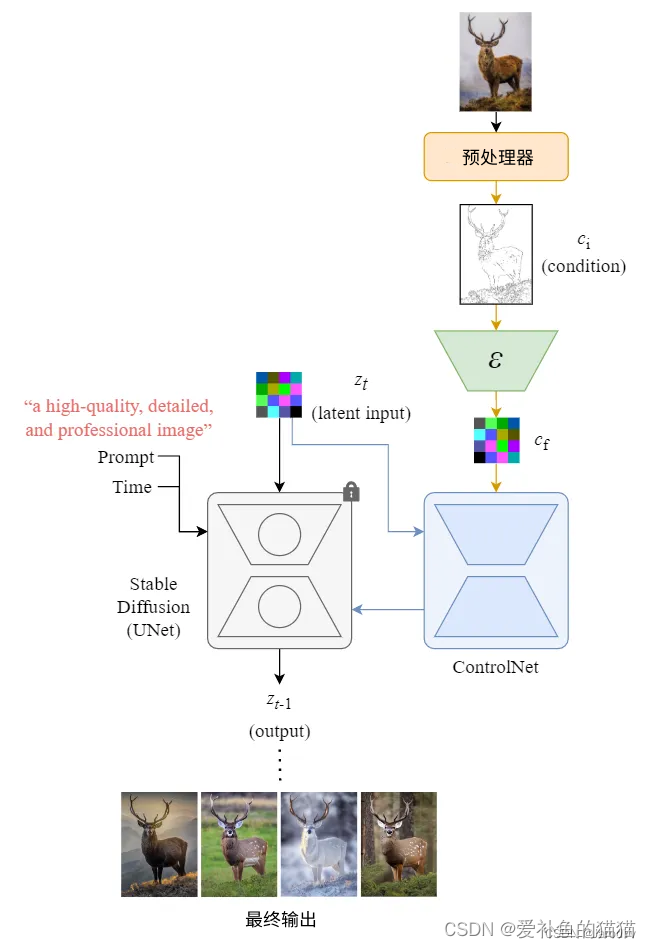
Stable Diffusion (UNet) 中的所有参数都被锁定并克隆到 ControlNet 端的可训练副本中。然后使用外部条件向量训练该副本。下图从整体上说明了 ControlNet 和 Stable Diffusion 如何在反向扩散过程(采样)中协同工作。(推理过程,训练过程没用到)
整体结构:
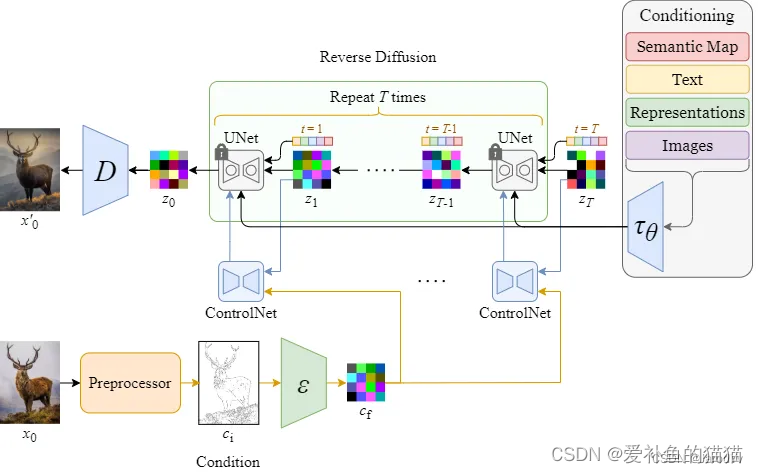
我们使用Zt和Zt-1作为锁定网络块的输入和输出,以匹配 Stable Diffusion 上下文中的符号。
下图展示了 Stable Diffusion 中 ControlNet 和 UNet 在一个去噪步骤中的输入和输出。
内部结构:
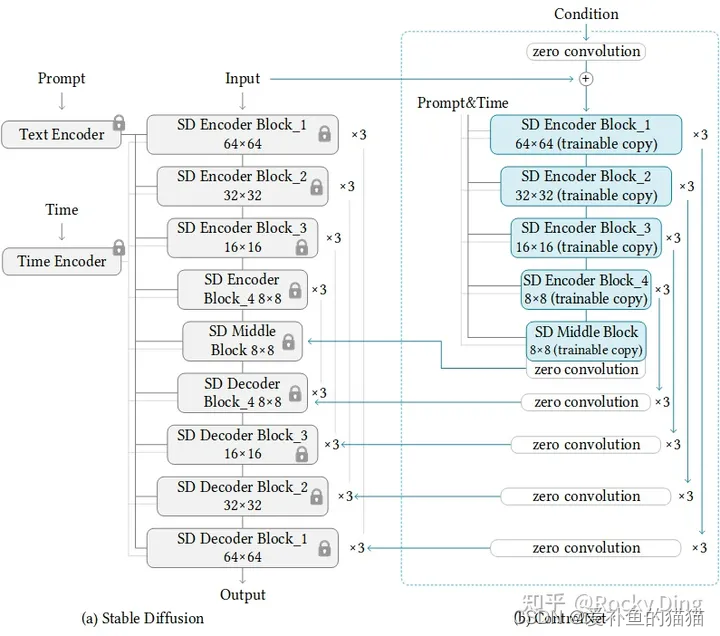
我们从ControlNet整体的模型结构上可以看出,其主要在Stable Diffusion的U-Net中起作用,ControlNet主要将Stable Diffusion U-Net的Encoder部分和Middle部分进行复制训练,在Stable Diffusion U-Net的Decoder模块中通过skip connection加入了zero convolution模块处理后的特征,以实现对最终模型与训练数据的一致性。
由于ControlNet训练与使用方法是与原始的Stable Diffusion U-Net模型进行连接,并且Stable Diffusion U-Net模型权重是固定的不需要进行梯度计算。这种设计思想减少了ControlNet在训练中一半的计算量,在计算上非常高效,能够加速训练过程并减少GPU显存的使用。在单个Nvidia A100 PCIE 40G的环境下,实际应用到Stable Diffusion模型的训练中,ControlNet仅使得每次迭代所需的GPU显存增加大约23%,时间增加34%左右。
ControlNet一开始的输入Condition怎么与SD模型的隐空间特征结合呢?在这里ControlNet主要是训练过程中添加了四层卷积层,将图像空间Condition转化为隐空间Condition。这些卷积层的卷积核为4×4,步长为2,通道分别为16,32,64,128,初始化为高斯权重,并与整个ControlNet模型进行联合训练。
梯度求导:
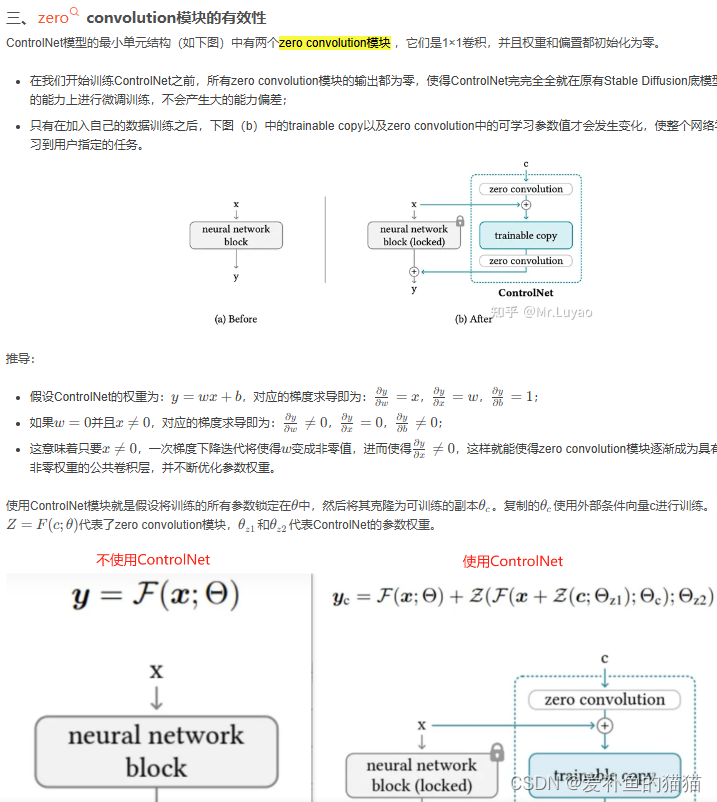
1.零卷积
零卷积成为一种独特的连接层,以学习的方式从零逐渐增长到优化参数。零卷积是一种特殊的参数初始化。在我们开始训练ControlNet之前,所有zero convolution模块的输出都为零,使得ControlNet完完全全就在原有Stable Diffusion底模型的能力上进行微调训练,不会产生大的能力偏差;
ControlNet基本结构中的零卷积层是一些权重和偏置都被初始化为0的1×1卷积层。训练刚开始的时候,无论新添加的控制条件是什么,这些零卷积层都只输出0,因此ControlNet不会对扩散模型的生成结果造成任何影响。但随着训练过程的深入,ControlNet将学会逐渐调整扩散模型原先的生成过程,使得生成的图像逐渐向新添加的控制条件靠近。
2.1×1卷积
1×1卷积的作用是通过控制卷积核的数量来进行降维和升维,增加网络的深度和非线性能力,以及跨通道聚合信息。
ControlNet模型的最小单元结构中有两个zero convolution模块,它们是1×1卷积,并且权重和偏置都初始化为零。这样一来,在我们开始训练ControlNet之前,所有zero convolution模块的输出都为零,使得ControlNet完完全全就在原有Stable Diffusion底模型的能力上进行微调训练,不会产生大的能力偏差。
这时很多人可能就会有一个疑问,如果zero convolution模块的初始权重为零,那么梯度也为零,ControlNet模型将不会学到任何东西。那么为什么“zero convolution模块”有效呢?(AIGC算法面试必考点)

4、多模态
https://zhuanlan.zhihu.com/p/642315162
多模态学习(Multimodal Learning)是一种利用来自多种不同感官或交互方式的数据进行学习的方法。在这个语境中,“模态”指的是不同类型的数据输入,如文本、图像、声音、视频等。多模态学习的关键在于整合和分析这些不同来源的数据,以获得比单一数据源更全面和深入的洞察。
人类通过视觉、语言等多种表征媒介(模态)与世界互动,每种模态都可能在某个方面的表达和交流上有它自己的优势,融合在一起帮助我们更系统、更完整地理解这个世界。随着技术的发展,大预言模型基本实现独立自然的表达,视觉编码表征能力也逐渐增强,自然而然,我们就会想要把两方面的能力结合在一起,用一个大一统的模型完成语言+视觉的综合理解&表达,这也更靠近大家所理解的AGI-通用人工智能。
多模态大模型都是Transformer based架构,NLP对文本进行embedding,CV对图像patch进行Embedding,从图像、视频、文本、语音数据中提取特征,转换为tokens,进行不同模态特征的对齐,送入Transformer进行运算。Transformer 是一种基于自注意力机制(self-attention)的序列到序列(sequence-to-sequence)模型。它使用了多头注意力机制,能够并行地关注不同位置的信息。ViT(Vision Transformer)是一种将 Transformer 模型应用于图像分类任务的方法。它将图像分割为一系列的小块patch,并将每个小块作为序列输入 Transformer 模型。通过自注意力机制,ViT 能够在图像中捕捉全局和局部的视觉信息,实现图像分类。
语言模型怎么理解视觉编码,并作出相应的语言描述?视觉模型怎么理解语言模型的指令,并生成相应的图片?我们可以通过BLIP2,CLIP了解第一个问题,并通过LLaVA,MiniGPT4,mPLUG-Owl了解第二个问题。
vlm (Vision-Language Models)视觉语言大模型
掩码语言建模 (MLM)
MLLM(Multimodal Large Language Model)多模态大语言模型
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。


clip
https://blog.csdn.net/zzZ_CMing/article/details/133908101
https://blog.csdn.net/weixin_47228643/article/details/136690837
https://zhuanlan.zhihu.com/p/653902791
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。CLIP在预训练期间学习执行广泛的任务,包括OCR,地理定位,动作识别,并且在计算效率更高的同时优于公开可用的最佳ImageNet模型。
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
- Text Encoder:用于将文本转换为低维向量表示-Embeding。
- Image Encoder:用于将图像转换为类似的向量表示-Embedding。
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。
对比学习
自监督学习:要说到对比学习,首先要从自监督学习开始讲起。自监督学习属于无监督学习范式的一种,特点是不需要人工标注的类别标签信息,直接利用数据本身作为监督信息,来学习样本数据的特征表达,并用于下游任务。
对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。logits 和 ground truth 的labels 计算交叉熵损失,loss_i,loss_t分别是 Image 和 Text 的 loss,最后求平均就得到loss。通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。
普通有分类头的监督学习的模型,输入的是已知的图片,不用再输入标签,自行分类,其实标签是已经在了,这是全包围的。CLIP输入的可以是外来没有训练过的图片,输入这个图片对应的文字到文字库里面,然后也可以正确分类。分类任务是输入图像,根据提取的特征,输出分类结果。对比学习,还要通过对比正负样本后,sotfmax得出二分类结果。
如果任务改为给定一张图片去预测一个文本(或者给定一个文本去预测一张图片),那么训练效率将会非常低下(因为一个图片可能对应很多种说法,一个文本也对应着很多种场景);
与其做默写古诗词,不如做选择题!(只要判断哪一个文本与图片配对即可);
通过从预测任务改为只预测某个单词到只选出配对的答案,模型的训练效率一下提升了4倍;
为此,本文训练阶段使用对比学习,让模型学习文本-图像对的匹配关系,也就是下面模型原理图中,蓝色对角线为匹配的图文对。训练集用的他们自己采集的包含4亿个图文对的 WIT数据集。
链接:https://blog.csdn.net/weixin_38252409/article/details/133828294
训练/推理
https://blog.csdn.net/zzZ_CMing/article/details/133908101
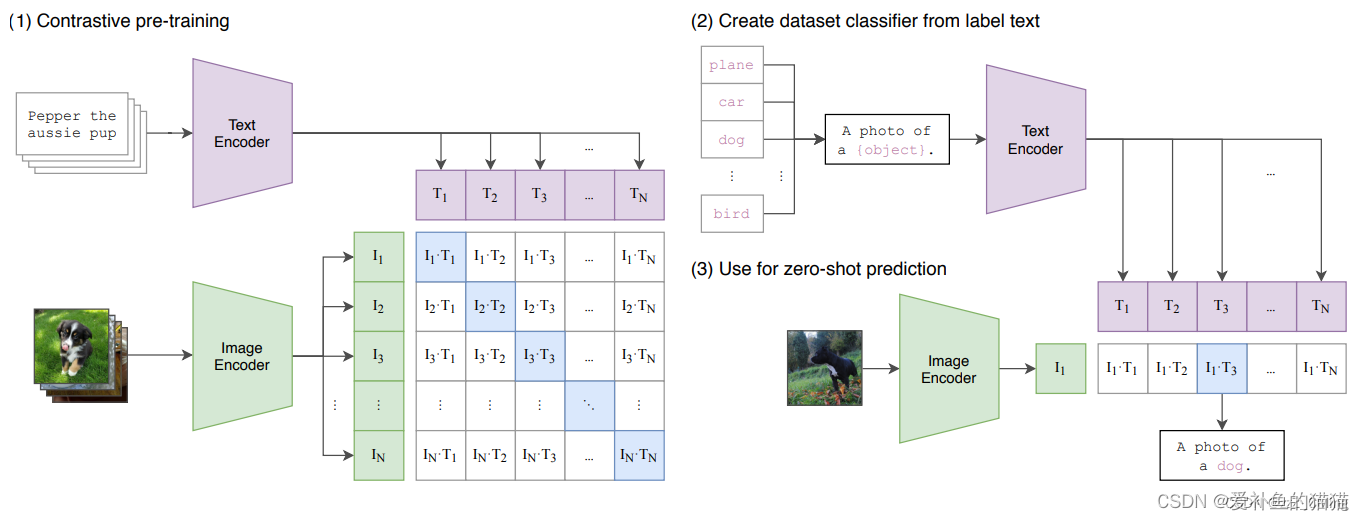
CLIP模型共有3个阶段:1阶段用作训练,2、3阶段用作推理。
1.Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
2.Create dataset classifier from label text:提取预测类别文本特征;
3.Use for zero-shot predictiion:进行 zero-shot 推理预测;
1、训练阶段
通过计算目标图像和对应文本描述的余弦相似度从而获取预测值。CLIP第一阶段主要包含以下两个子模型;
Image Encoder:用来提取图像的特征,可以采用常用CNN模型或者vision transformer模型;(视觉模型)
Text Encoder:用来提取文本的特征,可以采用NLP中常用的text transformer模型;(文本模型)
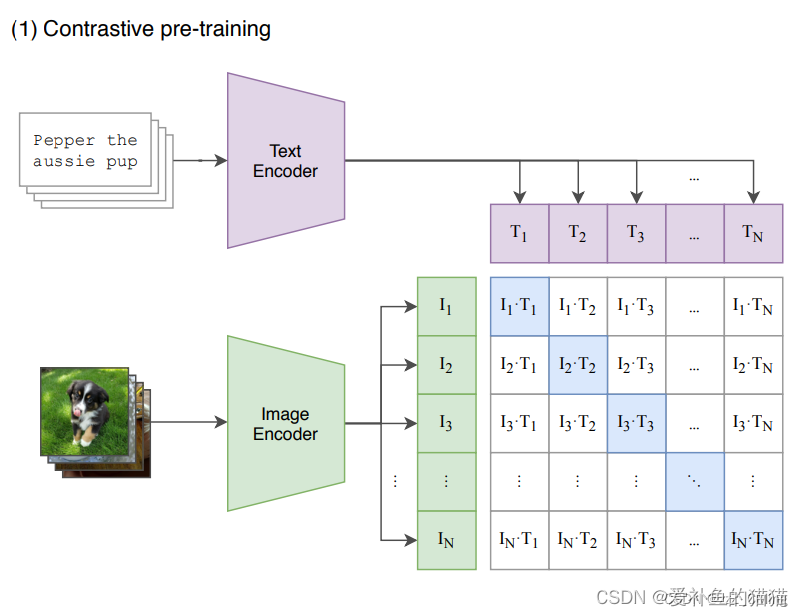
这里举例一个包含N个文本-图像对的训练batch,对提取的文本特征和图像特征进行训练的过程:
输入图片 —> 图像编码器 —> 图片特征向量;输入文字 —> 文字编码器 —> 文字特征向量;并进行线性投射,得到相同维度;
将N个文本特征和N个图像特征两两组合,形成一个具有N2个元素的矩阵;
CLIP模型会预测计算出这N2个文本-图像对的相似度(文本特征和图像特征的余弦相似性即为相似度);
对角线上的N个元素因为图像-标签对应正确被作为训练的正样本,剩下的N2-N个元素作为负样本;
CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N2-N个负样本的相似度;
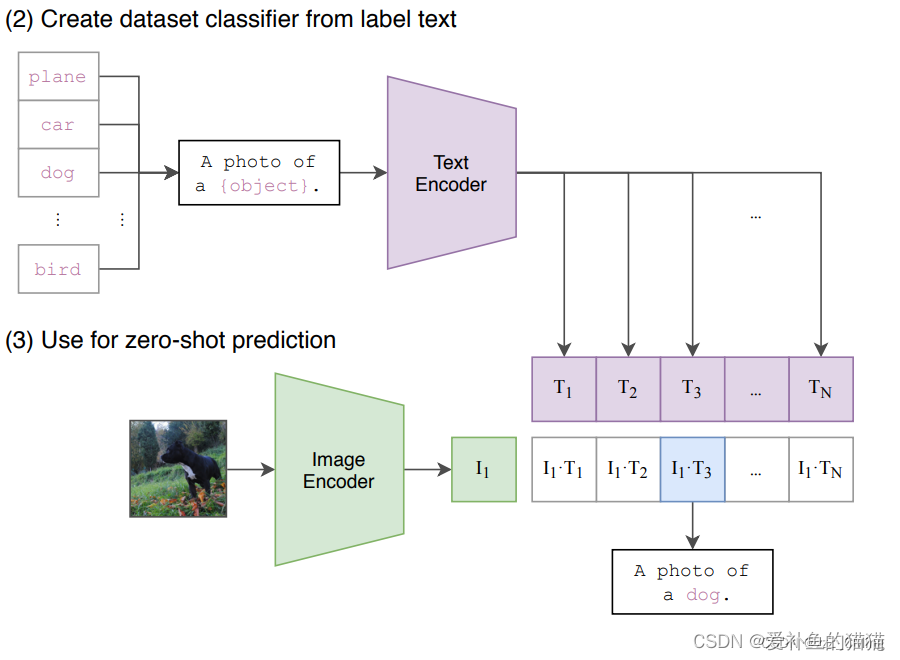
2、推理过程
CLIP的预测推理过程主要有以下两步:
1.提取预测类别的文本特征:由于CLIP 预训练文本端的输出输入都是句子,因此需要将任务的分类标签按照提示模板 (prompt template)构造成描述文本(由单词构造成句子):A photo of {object}.,然后再送入Text Encoder得到对应的文本特征。如果预测类别的数目为N,那么将得到N个文本特征。
2.进行 zero-shot 推理预测:将要预测的图像送入Image Encoder得到图像特征,然后与上述的N个文本特征计算余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果。进一步地,可以将这些相似度看成输入,送入softmax后可以得到每个类别的预测概率。
3、补充:zero-shot 零样本学习
zero-shot :零样本学习,域外泛化问题。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集,期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
在计算机视觉中,即便想迁移VGG、MobileNet这种预训练模型,也需要新数据经过预训练、微调等手段,才能学习新数据集所持有的数据特征,而CLIP可以直接实现zero-shot的图像分类,即:不需要训练任何新数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。
什么是零样本图像分类?
“零样本图像分类”(Zero-shot image classification)指的是使用一个模型对图像进行分类,而这个模型并没有在包含那些特定类别的标记样本的数据上进行过显式训练。
传统的图像分类方法需要在一组特定的带标签的图像上训练模型。这个模型通过学习,将图像的某些特征与标签相对应。当需要使用这种模型来处理引入了新标签集的分类任务时,通常需要进行模型的微调,以适应新的标签。
与此相反,零样本或开放词汇的图像分类模型通常是多模态模型,这些模型在包含大量图像及其相关描述的数据集上进行训练。这些模型学习了视觉和语言之间对齐的表示方法,可以应用于包括零样本图像分类在内的许多下游任务。
这是一种更为灵活的图像分类方法,它允许模型在不需要额外训练数据的情况下,泛化到新的和未见过的类别。同时,它也使用户能够用自由形式的文本描述来查询他们目标对象的图像。https://blog.csdn.net/weixin_43694096/article/details/135463444
等训练好了,然后进入前向预测阶段。首先需要对文本类别进行一些处理,拿 ImageNet 数据集的 1000 个类别来说,原始的类别都是单词,而 CLIP 预训练时候的文本端出入的是个句子,这样一来为了统一就需要把单词构造成句子,怎么做呢?可以使用 A photo of a {object}. 的提示模板 (prompt template) 进行构造,比如对于 dog,就构造成 A photo of a dog.,然后再送入 Text Encoder 进行特征提取,就 ImageNet 而言就会得到一个 1000 维的特征向量,整个过程如下:

最后就是推理见证效果的时候,怎么做的呢。这个时候无论你来了张什么样的图片,只要扔给 Image Encoder 进行特征提取,会生成一个一维的图片特征向量,然后拿这个图片特征和 1000 个文本特征做余弦相似度对比,最相似的即为我们想要的那个结果,比如这里应该会得到 A photo of a dog.,整个过程如下:
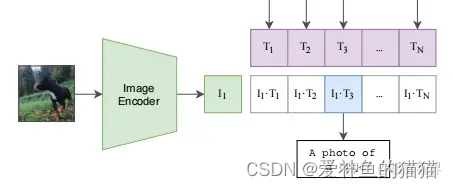
以上就是 CLIP 工作的总览,可以看到 CLIP 在一次预训练后,可以方便的迁移到其他视觉分类任务上进行 Zero-Shoot 的前向预测。
5、补充知识点
Diffusion,Latent Diffusion和Stable Diffusion
https://zhuanlan.zhihu.com/p/623539249
Stable Diffusion、DALL-E 2、MidJourney
https://www.zhihu.com/question/597471405
#自监督学习、MLM、vit、对比学习、clip、simclr
前言
在前面的两篇文章中,我们介绍了基于各类代理任务 (Pretext Task) 和基于对比学习 (Contrastive Learning) 的自监督学习算法。
随着 Vision Transformer (ViT) 在 2021 年霸榜各大数据集,如何基于 ViT 构建更加合适的自监督学习范式成为了该领域的一大问题。最初,DINO 和 MoCo v3 尝试将对比学习和 ViT 相结合,取得了不错的效果。不过长期以来,由于 CV 和 NLP 领域数据和基础模型之间的差异,NLP 的 Masked Language Modeling (MLM) 掩码模式机制没能成功应用于 CV 领域,但最近 ViT 的蓬勃发展,为掩码学习机制应用于视觉自监督打开了一扇大门。
本文将介绍四篇基于掩码学习的自监督学习
https://zhuanlan.zhihu.com/p/475952825
多模态:vit 、blip
turb lcm
control net
clip和blip
迁移和微调
风格迁移
ai绘画框架

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









