







一. 策略迭代
(1)为V(s),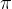 (s),设初值。
(s),设初值。
(2)策略评估,改变V(s)。
利用贝尔曼期望方程。
利用上式,依次遍历价值表,直至收敛。
(3)策略改进,改变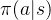
在(2)中收敛之后,利用动作价值函数的定义式:
在每一个s处选使得最大的
构成
若原与新
不一致,则利用新
重新返回(2)中进行策略评估
二. 价值迭代(极端情况下的策略迭代,即策略评估只进行一次)
(1)给V(s),(s),设初值。
(2)利用
通过贝尔曼最优性方程
















 4956
4956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









