







Analysing Diffusion Segmentation for Medical Images
去噪扩散概率模型由于能够提供概率模型并产生不同的输出结果而越来越受欢迎。这种多功能性激发了它们在图像分割中的应用,在图像分割中,模型的多重预测可以产生分割结果,不仅实现高质量,还能捕捉模型固有的不确定性。在此,本文提出了功能强大的架构来提高扩散分割性能。然而,对于扩散分割与图像生成之间的差异,显然缺乏分析和讨论,也缺乏全面的评估,以区分这些架构对一般分割的改进和对扩散分割的具体益处。在这项工作中,批判性地分析和讨论了医学图像的扩散分割与扩散图像生成的不同之处,尤其关注训练行为。此外,还评估了所提出的扩散分割架构在直接进行分割训练时的表现。最后,还探讨了不同的医学分割任务如何影响扩散分割行为,以及如何对扩散过程进行相应调整。通过这些分析,旨在深入了解扩散分割的行为,以便在未来更好地设计和评估扩散分割方法。
Introduction
扩散模型已成为各种计算机视觉任务的强大工具,包括图像生成、物体检测和分割。它们捕捉复杂分布和生成不同输出的能力已使它们对需要概率建模的应用特别有吸引力。近年来,在利用扩散模型对不确定性进行建模的动机推动下,利用扩散模型进行分割任务的趋势明显加快。这一点在医疗领域尤为重要,因为在该领域,标签噪声很常见,因此需要对不确定性进行测量。
然而,尽管扩散模型前景广阔,但将其应用于分割任务却面临着独特的挑战。与自然图像不同,分割缺乏细粒度的细节,并表现出不同的特性,而这些特性可能无法通过为图像生成而设计的扩散时间表来充分解决。改进基于扩散的分割的努力包括完善像素损失函数和开发专用架构。
虽然专门的架构声称可以提高分割性能,但它们在扩散方面的具体优势尚未得到全面评估。此外,据作者所知,之前没有任何作品分析过扩散图像生成和扩散分割之间的差异。这包括不同数据集的行为。
在这项工作中,探讨了三个主题。首先,比较了扩散分割与前馈分割设置中的三种扩散分割架构,并直观地展示了不同网络和训练中存在的模型不确定性。其次,讨论了扩散图像生成和扩散分割的不同之处,以及训练行为可能有何不同。第三,分析了三个数据集的前向过程,并提出了如何使扩散分割方法适应不同数据集的建议。
Background on Diffusion Models
扩散模型是一种生成模型,在图像生成方面取得了巨大成功。它包括一个数据逐渐退化的正向过程和一个退化程度降低的逆向过程。前向过程被描述为一个具有 T 个步骤的马尔可夫链,其中一个噪声估计模型 εθ 被训练用来估计添加到输入图像 x0 中的噪声 ε。通过在每个时间步长 t 对噪声 ε 或 x0 进行估计,目标函数有两种描述方式,一种是
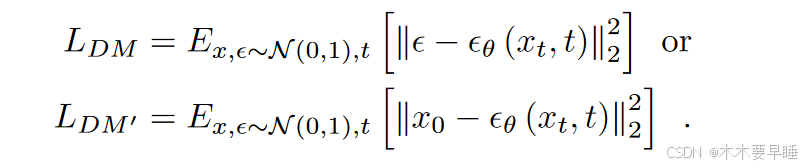
除了学习数据分布 p(x),扩散模型还能通过在训练目标中加入条件 y 来模拟条件分布 p(x|y),如下所示:
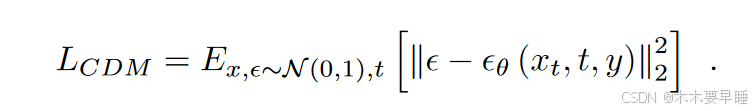
就扩散分割而言,输入 x 是分割掩膜,条件 y 是待分割的条件图像。
Datasets and Experiments
Datasets
利用两个公开的医疗数据集 ISIC16、MoNuSeg(这两个数据集已在相关工作中用于扩散分割)以及一个内部数据集 HER2 来进行这项工作。
SIC16 任务 3B 数据集:该数据集由皮肤镜图像组成,其任务是病变分割,以前曾在 [13] 中使用过。数据集中的每张图像都包含一个病灶,通常位于图像的中心。
MoNuSeg 数据集:该数据集由 H&E 染色图像组成,带有用于多器官细胞核分割的标签,曾在文献[1]中使用。数据集中的每张图像都包含多个细胞核及其分割。
HER2 数据集:这是一个由 HER2 染色的乳腺癌组织活检图像组成的私人数据集。该数据集的任务是肿瘤分割,由大小不一的细胞簇组成。肿瘤组织在某些图像中可能不存在,而在另一些图像中则覆盖了图像的大部分。
Experiments
E1) 前馈式分割,即以图像为输入,采用经典的Dice和交叉熵损失方法进行训练。虽然最近的研究报告了他们所提出的架构的扩散分割性能,但还缺少相同架构的前馈分割结果。这种比较对于了解架构的扩散特定优势非常重要。在本实验中,还将 SegFormerB3和 nnUnet作为额外的参考架构。
E2) 扩散分割,根据上述公式对三种扩散分割架构进行训练,预测 ε。
E3) 掩膜预测。对于自然图像,这种退化通常与信息损失相对应,因为细节会逐渐丢失。在以分割掩膜为目标 x 的扩散分割中,由于分割掩膜不包含在较低噪声水平下丢失的细粒度细节,因此信息丢失并不是连续的。旨在了解这一特性如何影响扩散行为。因此,本实验包括训练根据公式 (2),三个扩散分割网络的目标是从独立于图像输入的噪声掩膜 xt 中恢复分割掩膜 x0。
E4) 图像生成,根据表示经典的无条件图像生成,图像为 x。
扩散分割架构的设置和训练方案采用了他们发表的作品。EnsemDiff 只提供了一套设置,对于 SegDiff,采用了 MoNuSeg 实验报告中的设置,而对于 MedSegDiff,采用了 ISIC16 数据集的设置。没有任何一部扩散分割著作描述了训练-验证分割或其他模型选择方法。为了使用相同数量的训练数据,并避免根据测试指标选择指标来优化测试集,对架构进行了报告步骤数量的训练。分段结果是通过预测集合获得的。对于私有数据集,对 MoNuSeg 进行了 25 次组合预测,对 ISIC16 进行了 10 次组合预测,对 HER2 进行了 5 次组合预测。
前馈式分割实验采用了 Dice 和交叉熵损失的等效组合、1e-5 的学习率和 Adam 优化器。扩散分割架构所需的输入 xt 用所需形状的随机噪声代替。为了使用与扩散分割相同数量的训练数据,我们首先以 80-20 的训练验证比例进行训练,以确定训练历元数,然后在不进行验证的情况下使用完整数据集进行重新训练。作为度量指标,使用了 "交集大于联合"(Intersection over Union,IoU)和 "预期校准误差"(Expected Calibration Error,ECE),共有十个分段。
Evaluation
Feed-forward Segmentation Performance vs. Diffusion Segmentation
在本节中,将比较实验 E1) 和 E2) 在分割性能和不确定性量化方面的结果,以研究架构的影响以及扩散模型在提供更好的模型校准方面的潜力。
在表 1 中,报告了这项工作中使用的所有架构和数据集的分割结果。对于 EnsemDiff、SegDiff 和 MedSegDiff,比较了它们没有扩散过程的前馈分割性能和它们的扩散分割性能。在大多数实验中,扩散分割训练的性能都优于前馈分割训练,尤其是在研究 ECE 时。不过,在每个数据集中,nnUNet 或 SegFormer 的表现都最好。
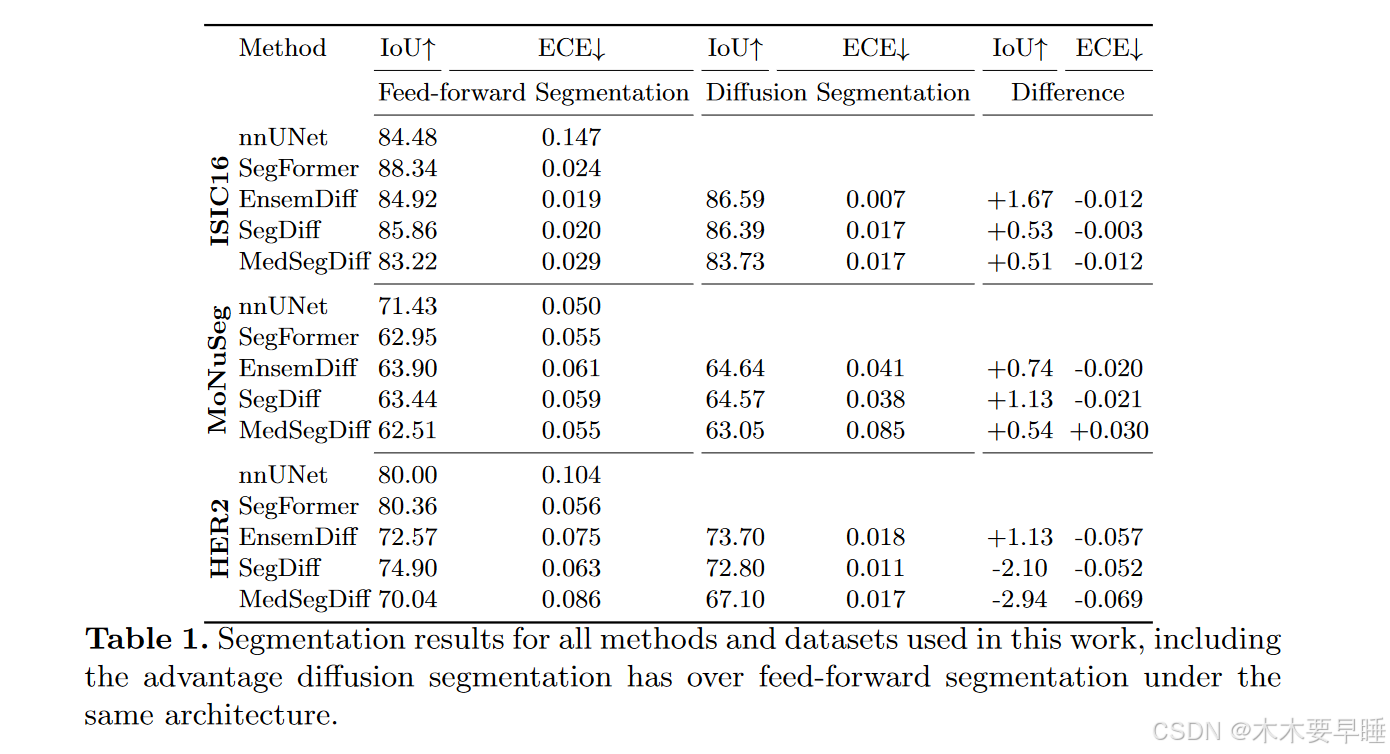
结果与相关工作中报告的数值大致相同。对于 HER2 数据集,怀疑扩散方法的拟合度较差,这是因为这些方法缺乏验证方案。不过,就设置而言,在大多数情况下,看到扩散分割训练相对于前馈分割训练有了相对改善。这一点在 ECE 中表现得尤为明显,除一种情况外,扩散分割训练在其他所有情况下都表现得更好。

在图 1 中,展示了 SegDiff(针对 ISIC16)和 MedSegDiff(针对 MoNuSeg)的定性分割示例,说明了多次预测的平均值和标准偏差。虽然前馈分段模型突出显示了与扩散模型类似的不确定区域,但整体而言,模型的不确定性较低。值得注意的是,前馈分割模型的不确定性完全是由于在训练/推理过程中提供的随机噪声(而不是 xt)造成的,它稍微改变了激活。认为这是一种 "弱 "增强/重组形式,因为网络很容易学会忽略这种输入。
这些结果表明,在扩散分割设置中训练相同的网络具有优势;但是,在实验中,它们与 SOTA 前馈网络相比并不完全具有竞争力。此外,更强大的不确定性/集合方法(包括测试时间增强[10])可能会进一步缩小或消除这一差距。
Error and Loss Behaviour of Diffusion Segmentation over Different Timesteps
在本节中,将研究扩散分割模型在扩散过程的不同时间步骤中的表现。为此,首先将 E2 中的正常扩散分割行为与 E3 中的 "无条件 "扩散分割(无图像)进行比较,后者可理解为掩膜完成或形状生成。随后,研究了扩散分割与图像生成在损失函数方面的差异。
在图 3(左)中,以 HER2 数据集为例说明了掩码预测误差的行为。在最初的 400 个时间步中,看到有条件扩散分段和无条件扩散分段之间几乎没有差异。
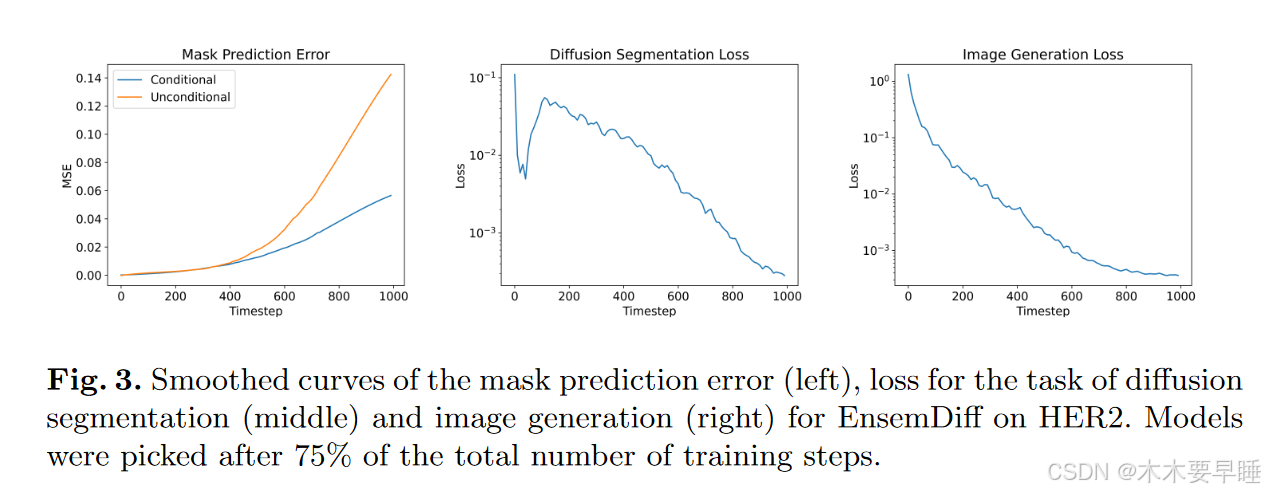
这意味着该模型在预测这些时间步的掩码时,没有从实际待分割图像中获益(可能也没有关注)。一般来说,这种行为表明,通过简单的、与内容无关的掩码去噪,可以恢复掩码 x0,而不会出现从 xt 到此时为止的较大误差。图 2 展示了图像(上行)和分割掩码(下行)上噪声水平增加的影响以及图像去噪的潜在差异。随着时间步长的增加,图像中不同程度的细节会不断丢失,但直到时间步长增加,分割掩码仍能(在视觉上)识别,而不会丢失信息。

在分析了扩散过程对分割掩码的影响之后,现在来看看扩散训练过程的影响。图 3 中部和右部分别说明了扩散分割训练 (E2) 和图像生成训练 (E4) 的训练损失。这两条损失曲线都是使用 EnsemDiff 架构和 HER2 数据绘制的,都是在训练步骤完成 75% 之后绘制的,希望模型在合理拟合的同时不会出现过拟合。不出所料,ε 和ε 的时间步数损失分别为 0.5%和 0.5%。随着信息的不断丢失,图像生成量单调减少,但噪声 ε 更容易识别。在较高的噪声水平下,网络几乎可以在噪声预测 ε 不变的情况下转发 xt,并获得较低的损失值,因为底层图像 x0 的影响越来越小。对于扩散分割,看到了一种非常有趣的非单调行为,在前 50 个时间步内急剧下降,在后 100 个时间步内急剧上升。在早期的时间步中,网络可能很容易预测噪声,因为在掩码输入中存在大量恒定区域,学习一个简单的高频滤波器就足以做出正确的预测。一旦噪声水平阻止了这种简单的估计,误差就会急剧增加,回到几乎线性的状态。
基于这些观察结果,认为用于生成图像的扩散损失结构可能不适合扩散分割任务。图 3 显示,在该数据集中,掩码 x0 可以从其噪声版本 xt 中恢复,在时间步 400 之前不会出现较大误差。然而,损失结构表明,大部分注意力都放在了时间步的下半部分,而不是时间步的上半部分,因为在这部分,来自噪声掩膜 xt 的信息开始衰减,预计概率建模也会在这部分发生。虽然这并不妨碍扩散分割法学习分割图像,但这可能会导致训练时间超过所需的时间,以及概率建模效果不理想。针对这种情况,可能的改进方法是通过噪声或权重调度,在噪声掩膜 xt 的信息开始衰减时,更加重视噪声水平。
Dataset Fingerprints
每种分割掩码的信息可能不尽相同。图 4 显示了所有三个数据集和所有三种架构的平滑掩码预测误差(虚线),以及架构的平均值(实线)。可以观察到每个数据集的不同行为.
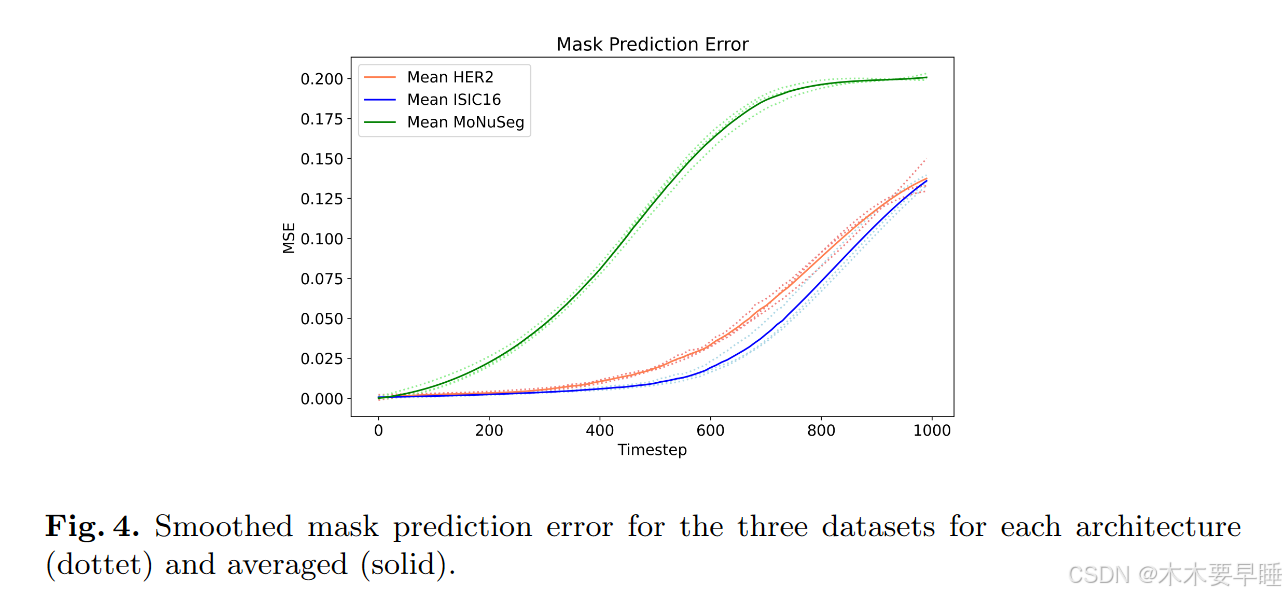
本文认为这种行为是由分割任务的特性造成的。MoNuSeg 的核分割包括小物体,随着噪声水平的增加,小物体的识别速度也会加快。相比之下,ISIC16 数据集每幅图像包含一个大的分割掩膜,通常位于图像的中心位置,即使在噪声水平较高的情况下,也能更容易地进行识别,而且迭代去噪的效果也不明显。
本文得出的结论是,分割指纹可能会对扩散行为产生影响,因此在设计扩散分割方法时应加以考虑,尤其是在医学图像中,因为医学图像包含多种分割类型。首先,HER2 和 ISIC16 在 1000 个时间步时,并非所有信息都会丢失,因为没有观察到 MSE 的收敛,这表明这些数据集可能需要更高的最终噪声水平。其次,所有数据集都有一些时间步区域,在这些区域中,可以从噪声掩膜中恢复全部或全部信息。建议减少对这些区域的重视,因为不应该在这些区域学习概率建模。一种可能的改进方法是用掩码预测误差的第一个偏差来加权,这样可以加快训练收敛速度,并更好地模拟不确定性。



















 2707
2707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











