







偏差、方差

SVM



优化目标
我们先从Logistic回归说起,我们知道在Logistic回归中,Sigmoid函数的作用 z = θ T x z=\theta^Tx z=θTx,如果我们需要让y = 1,那我们就想要 h ( x ) ≈ 1 h(x)\approx1 h(x)≈1。下面我们为远大于和远小于划定一定的界限,首先我们还是以代价函数的例子来说明,我们之前定义了:
![[公式]](https://img-blog.csdnimg.cn/77f63daf1f6b4f08bea98e5e1a383465.png)
我们分别画出当y=0,1时的函数图像:

我们可以很明显地看出当y = 1,z>1时,代价z就差不多变成0了,反之则是z<-1。这里注意一下,关于1和-1,基本是我们约定俗成的,请大家不用过分在意。于是我们得到了新的代价,在机器学习,我们把它成为支持向量:
![[公式]](https://img-blog.csdnimg.cn/6cb75a4380d949c698cc20de23d41738.png)
下面我们重写SVM的整体代价函数,我们加入了正则项,并与logistic作对比:
![[公式]](https://img-blog.csdnimg.cn/6a5b5a2d394a4b47b86c45e87bf32b51.png)
我们可以看出SVM中有一个常数C,没有关系,你可以把他当做和正则化参数一样的东西,用于调整权重的比例,防止过拟合的问题。这就是SVM的优化目标,即代价函数。
大间隔学习
支持向量机还有一个名称,就是大间隔学习,下面我会用可视化的方式来告诉你为何它是大间隔学习,以及为何它的效果要优于我们的Logistic回归。假设我们有一个二分类的样本,如下图所示:

在这里分类问题中,L1和L2是我们Logsitic回归可能得到的决策界限,可以看出的是,虽然这两条直线,确实分开了两个样本,但是分类效果并不太好。而支持向量机划分的决策界限,则是S1,其中S2和S3为初始划定界限,最终选择S1作为决策界限,而S1与S2、S3的距离被称为Margin。
核函数
其实核函数核方法这些东西在所有的模型算法中都能应用到,但是其在SVM中的效果明显,所以核函数常常后来和SVM一起出现。我们在解决非线性问题的时候,常常会为假设函数的选择而困扰,选择单变量一次项 x 1 x_1 x1,还是单变量高次项 x 1 n x_1^n x1n,还是选择多变量的积 x 1 x 2 x 3 x_1x_2x_3 x1x2x3,这常常会给我们的分类问题的解决造成障碍,于是我们可以得到一个较为统一的式子:
![[公式]](https://img-blog.csdnimg.cn/3b9741ccd321405dafd2f474bb261ad4.png)
下面我们就来谈谈如何选择这项通用式子中的 f 1 , f 2 , f 3 f1,f2,f3 f1,f2,f3。对于给定的特征向量x,我们定义三个坐标点 l 1 , l 2 , l 3 l^1,l^2,l^3 l1,l2,l3。我们以此来决定通向式中的三个权重:
![[公式]](https://img-blog.csdnimg.cn/dca7e929d36c432fa89b1abf1cfd3689.png)
其中similarity函数就是我们所经常使用高斯核函数(Gaussion Kernels),如果特征值离我们的定义坐标点越近,则 f ≈ 1 f\approx1 f≈1,反之则是 f ≈ 0 f\approx0 f≈0。
简单说说,我们如何选择坐标点[公式],我通常的选择方法笔记比较简单(当然还有很多复杂的选择方法),比如我们有m个特征向量样本即[公式]。
那我们便选择m个坐标点,[公式]。一般而言,我会这么选择。然而核函数还有很多种,我这里列举一些:
String kernel
chi-square kernel
histogram intersection kernel
不过最常用且较为容易的还是高斯核函数。
与Logistic如何选择
我们假设
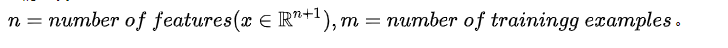
如果n相对于m来说非常大:我们选用Logistic回归,或者不用核函数的SVM(不用核函数就相当于线性核函数Linear Kernel)。
如果n比较小,m中等:我们选用高斯核函数的SVM。
如果n小,m大:那我们需要增加特征向量的种类,然后同理第一种情















 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









