









 本文深入解析YOLOv1目标检测算法,详细阐述其网络结构、输入输出设计、训练过程及损失函数,同时介绍了预测阶段的非极大值抑制(NMS)算法。
本文深入解析YOLOv1目标检测算法,详细阐述其网络结构、输入输出设计、训练过程及损失函数,同时介绍了预测阶段的非极大值抑制(NMS)算法。
前言
网上有许多YOLOv1的文章,但绝大部分文章将训练样本标签与训练输出混为一谈,对初学者的理解造成了很大的困难。本文总结了几篇优秀的博客,改正了一些用图与表述错误,加上了自己的一些理解和一些实例以助理解
YOLO
YOLO意思是You Only Look Once,创造性的将候选区和对象识别这两个阶段合二为一,看一眼图片就能知道有哪些对象以及它们的位置。
实际上,YOLO并没有真正去掉候选区,而是采用了预定义的候选区(准确点说应该是预测区,因为并不是Faster RCNN所采用的Anchor)。也就是将图片划分为 7×7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 492=98 个bounding box。可以理解为98个候选区,它们很粗略的覆盖了图片的整个区域。
RCNN虽然会找到一些候选区,但毕竟只是候选,等真正识别出其中的对象以后,还要对候选区进行微调,使之更接近真实的bounding box。这个过程就是边框回归:将候选区bounding box调整到更接近真实的bounding box。
既然反正最后都是要调整的,干嘛还要先费劲去寻找候选区呢,大致有个区域范围就行了,所以YOLO就这么干了。
下图为YOLO运行过程简图:

(1)把图像缩放到448X448,(2)在图上运行卷积网络,(3)根据模型的置信度对检测结果进行阈值处理
网络结构

单看网络结构的话,和普通的CNN对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。
其他层都是使用的激活函数都是leaky rectified activation:

理解YOLO的过程中,最重要的是理解输入输出的映射关系,下面将详细介绍
输入输出的结构与映射关系

输入
输入就是原始图像,唯一的要求是缩放到448×448的大小。主要是因为YOLO的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以倒推回去也就要求原始图像有固定的尺寸。那么YOLO设计的尺寸就是448×448
输出
简单来说输出就是一个7×7×30的张量。
为何是这个尺寸,又包含哪些信息呢?
首先需要知道YOLO的一些规定:
YOLO将图像分成S×S(S=7)的网格grid cell,并且每个网格单元负责预测B(B=2)个边界框box。加上每个边界框box的置信度confidence,每个网格的C个条件类别概率
7*7的网格设计
根据YOLO的设计,输入图像被划分为7×7的网格(grid cell),输出张量中的7×7就对应着输入图像的7×7网格或者说输出就是7×7=49个30维张量,正如上图所示,两个橙色的gridcell各自对应着输出中对应位置的两个30维向量
要注意的是,并不是说仅仅网格内的信息被映射到一个30维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个30维向量中。
30维向量

(1)20个对象的概率
因为YOLO支持识别20种不同的对象,(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率。可以记为

是条件概率,意思是如果网格存在一个对象Object,那么它是Ci的概率是P(Ci|Object)
(2)两个bounding box的位置
每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),2个bounding box共需要8个数值来表示其位置。
需要强调的是,这里的x,y,w,h都是归一化的坐标,并且x,y是相对于该bounding box所在的grid cell的左上角的偏移量。
对与w,h的归一化比较简单:w=框的宽度/图片总宽度,h=框的高度/图片总高度
因为x,y只是bounding box中心点的相对于所在grid cell左上角的偏移,具体而言如下图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HFGyTQNW-1588516991656)(assets/image-20200503195221736.png)]](https://i-blog.csdnimg.cn/blog_migrate/9049639e5b36d35bd087651b8b4f577d.png)
如图,绿色框框的那个grid cell有一个bouding box,这个boundingbox的中心是红点,这个红点的坐标计算公式如下:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gvRNNxmF-1588516991659)(assets/image-20200503195918681.png)]](https://i-blog.csdnimg.cn/blog_migrate/8d2fb8f553850205000700d3a38eacdf.png)
这个x,y是绿色grid cell 左上角的偏移量,因为是归一化后的结果,所以x,y的值在(0,1)范围
例如这个坐标为(0.4,0.7),如果是在这个网格坐标系(即横纵轴范围0~7),那么红点在网格坐标系实际的坐标为(1.4,4.7),同样也可以将xywh放缩到image实际的大小,也就可以在image中画出这个红框了。
(3)两个bounding box的置信度
这里很容易产生混淆,需要区分 预测(或称测试inference)时图片进入网络的输出 中的bounding box的置信度和训练集产生的标签里的置信度
此处只需简单知道置信度的概念:一个bounding box的置信度Confidence意味着它 是否包含对象且位置准确的程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象 或者 即便有对象也存在较大的位置偏差。
至此我们明确了输出其实就是 S * S * ( B * 5 + C) }的Tensor(张量)。
训练样本的标签
有了神经网络,自然要用训练集去训练参数,以得到我们想要的模型。
如我们可以用labelImg软件标注,下面我们用一张用于训练的图片举例,在这张图片中框出所有我们想要识别对象(Object),并且分别设定类别(class)。这样我们就完成了一张图片的标注。
训练的过程简单来说,就是这张图片输入网络得到一个预测的7×7×30 的输出,那我们根据这张图片的标注,也应该生成一个7×7×30的样本标签与预测的输出计算Loss,再前向传播调整参数 这么一个过程
以这张图为例:图中蓝色,黄色,粉色的框框就是我们标注时候的框框,对应的类别分别为 dog,bicycle,car

下面就介绍标注完这张图片后,对应的7×7×30的样本标签如何生成
(1)20个对象分类概率
对此,论文中有个关键词“responsible”,给出了仅由中心点所在的网格对预测该对象负责的这样一个规定。
意思是说,每个对象(Object)都有一个框框,计算框框的中心点,中心点所在的网格(grid cell)对这个对象负责。例如,狗被标注了一个蓝色的框框,蓝色的框框中心是那个蓝色的圆点,圆点所在的网格(图中蓝色阴影的grid cell)对狗这个Object负责。
每个Object找到负责的grid cell后 这个grid cell对应的30维张量中那20个对象分类概率中就把这个Object的类别设为1,其他类别为0。继续上面的例子:蓝色阴影的grid cell对应的30维张量中的20个分类概率中,dog设为1,其他19个类设为0。同样的黄色阴影grid cell类别概率中bicycle设为1,其余19个位0,粉色grid cell类别概率中car设为1,其余19个位0。
这样49个30维张量中,3个30维张量的对象分类概率得到了确定,那剩下45个呢?注意"仅由中心点所在的网格对预测该对象负责"这句话中的仅由二字,也就是说及时一个对象横跨了众多grid cell,我们也只关系这个对象中心点所在的grid cell,仅由这个grid cell负责。那剩下的45个30维张量的20个对象分类概率都为0!!
(2)bounding box的位置
依旧在仅由中心点所在的网格对预测该对象负责的前提下
每个对象的框框已经由我们标注获得,即知道了训练样本中对象的真实位置,自然要把真实的位置信息填入负责的grid cell对应的30维张量中。但因为B=2,即一个grid cell对应了两个bounding box信息,我们该填入哪一个呢?
需要明确的是这是在训练过程中在线计算出才填入样本标签的!这也牵扯到了置信度问题,故见下面第三点置信度
(3)bounding box的置信度
对于置信度由这样一个公式确定:

 是 bounding box 与 对象真实bounding box 的IOU(Intersection over Union,交并比)。在此已经可以发现 体现了预测的bounding box与真实bounding box的接近程度且这里不仅用到了我们通过标注就知道的真实bounding box,还牵扯到了预测的bounding box,既然要用到预测信息就不难理解为何要在训练时候在线生成。
是 bounding box 与 对象真实bounding box 的IOU(Intersection over Union,交并比)。在此已经可以发现 体现了预测的bounding box与真实bounding box的接近程度且这里不仅用到了我们通过标注就知道的真实bounding box,还牵扯到了预测的bounding box,既然要用到预测信息就不难理解为何要在训练时候在线生成。
简单介绍一下IOU的计算,IOU=交集部分面积/并集部分面积,2个box完全重合时IOU=1,不相交时IOU=0
训练时通过网络的输出,每个grid cell都有2个预测的bounding box。对于对 对象 负责的grid cell而言,将这两个预测的bounding box分别与真实的bounding box计算IOU,然后最重要的一步!比较两个IOU哪个大,由大的IOU对应的bounding box 负责预测这个对象 (这又是一个负责的重要规定),那么这个负责的bounding box的 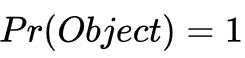 ,另一个不负责的bounding box(IOU小的这个)
,另一个不负责的bounding box(IOU小的这个)  。总的来说就是,与对象实际bounding box最接近的那个bounding box,即IOU大的这个
。总的来说就是,与对象实际bounding box最接近的那个bounding box,即IOU大的这个  ,不负责的bounding box,
,不负责的bounding box,

以样例图中的黄色grid cell 对应的30维输出为例,如上图,这里已经假设在线计算时候时候bounding box1的IOU更大。 至于这个坐标2因为不计入Loss的计算,所有显得没那么重要,当然为了方便在设计代码时候可以也设为自行车边框坐标,总之这个值不会产生影响
总结一下,标签中只有对对象负责的那个grid cell的 负责的那一个bounding box(计算出IOU最大的那个) 对应的置信度才是计算出的IOU的值,其余所有的置信度因为Pr(Object)=0所以都是0
还是拿那个样例图来说,7×7个grid cell,每个grid cell 有两个bounding box ,共计7×7×2=98个bounding box,每个bounding box 都有一个 置信度confidence信息,那么98个中只有3个是计算出的IOU值,其余95个都是0
至此,训练样本标签如何设定就介绍完了,而经过网络输出的7×7×30的张量内的值最初都是随意的,拿出一个30维张量为例,

就长这个样子,接下来就是计算Loss,再去回归的过程
损失函数
损失就是网络实际输出值与样本标签值之间的偏差
如:
YOLO给出的损失函数如下:



函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。简单的全部采用了sum-squared error loss来做这件事会有以下不足: a) 8维的localization error和20维的classification error同等重要显然是不合理的; b) 如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。 解决方案如下:
①更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 上面已经提到了引入了 ,作者在pascal VOC训练中取了5
,作者在pascal VOC训练中取了5
②对没有object的bbox的confidence loss,赋予小的loss weight,上面也已经提到了引入了 ,在pascal VOC训练中取0.5
,在pascal VOC训练中取0.5
③有object的bounding box的confidence loss (上图第三行) 和类别的loss (上图第五行)的loss weight正常取1
④对不同大小的bounding box预测中,相比于大bounding box预测偏一点,小bounding box预测偏一点更不能忍受。而sum-square error loss中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。

对于负责,再补充一些作者给出的说法
一个网格预测多个bounding box,在训练时我们希望每个object(ground true box)只有一个bounding box专门负责(一个object 一个bounding box)。具体做法是与ground true box(object)的IOU最大的bounding box 负责该ground true box(object)的预测。这种做法称作bounding box predictor的specialization(专职化)。每个预测器会对特定(sizes,aspect ratio or classed of object)的ground true box预测的越来越好
预测(inference)与NMS(非极大值抑制)
训练好的YOLO网络,输入一张图片,将输出一个 7730 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和置信度。注意在inference过程中就没有了训练时标注所知的对象真实位置,也就没有那些IOU的计算了。
NMS(非极大值抑制)
在inference时,引入一个score公式:score为 反映了每个bounding box 特定类别的置信度分数。
反映了每个bounding box 特定类别的置信度分数。
可前面提到在inference时候并没有IOU啊,公式只是为了反应其意义,对应到inference时候,就是每个bounding box的20个类别概率去乘bounding box 的置信度。

如上图,就反应了一个bounding box的置信度和类别概率相乘的过程,获得了一个20×1的张量
一共有98个bounding box 也就有98个20×1的张量,如下图

接下来以Dog类为例,Dog类对应位置如下

设置一个阈值小于阈值的score直接设为0,如下图:

之后降序排列(这只是dog类) 如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LrJP03tn-1588516991677)(assets/20200430111910248.png)]](https://i-blog.csdnimg.cn/blog_migrate/749612606b0fadb1b621a7bb9e06f23b.png)
降序排列后,由于一些大的物体可能会占用好几个grid cell,但是由于一个物体只能由一个grid cell中的一个预测边界框负责,所以需要选出score值最高的那个边界框来负责该物体,就像例图中的狗就占用了好多grid cell;此时就需要进行NMS处理(非极大值抑制): 抑制的过程是一个迭代-遍历-消除的过程:
1.将所有框的得分排序,选中最高分及其对应的框。
2.遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。
3.从未处理的框中继续选一个得分最高的,重复上述过程。

通过选出一个类中score值最高的框,添加到输出列表,然后使用同一类中未选择过的最高score值进行比较,若是两个框的IOU大于阈值则表明两个框重叠太多,属于共同负责一个物体,此时需要将框中该类的score置为0,依次将所有框都与其进行比较。如果剩下的(已经去除掉输出的)还有非0的,那再选出剩下(已经去除掉输出的)中最大的,重复上述过程。
最后所有的bounding box 要么输出,要么score为0。
其他的所有类也是如此,都需要进行NMS处理过程。
总结一下这样一个inference过程就是:
①Resize成448*448,图片分割得到7×7网格(grid cell)
②CNN提取特征和预测:卷积层负责提特征。全链接层负责预测:a) 7×7×2=98个bounding box的坐标和confidence置信度 b)7×7=49个grid cell中所属20个物体的概率
③NMS过滤,输出
如下图:

cfg配置文件参数简要解析
[net]
# Testing
#batch=1
#subdivisions=1
Training
batch=64 #一批训练样本的样本数量,每batch个样本更新一次参数
# subdivisions=8 #batch/subdivisions作为一次性送入训练器的样本数量,如果内存不够大,将batch分割为subdivisions个子batch
#上面这两个参数如果电脑内存小,则把batch改小一点,batch越大,训练效果越好subdivisions越大,可以减轻显卡压力
height=448
width=448
channels=3 # height,width,channels图像属性
momentum=0.9 #DeepLearning1中最优化方法中的动量参数,这个值影响着梯度下降到最优值得速度
decay=0.0005 #权重衰减正则项,防止过拟合
saturation=1.5 # 通过调整饱和度来生成更多训练样本
exposure=1.5 # 通过调整曝光量来生成更多训练样本
hue=.1 #通过调整色调来生成更多训练样本
learning_rate=0.0005 #学习率决定着权值更新的速度,设置得太大会使结果超过最优值,太小会使下降速度过慢。
#如果仅靠人为干预调整参数,需要不断修改学习率。刚开始训练时可以将学习率设置的高一点,
#而一定轮数之后,将其减小
#在训练过程中,一般根据训练轮数设置动态变化的学习率。
#刚开始训练时:学习率以 0.01 ~ 0.001 为宜。
#一定轮数过后:逐渐减缓。
#接近训练结束:学习速率的衰减应该在100倍以上。
policy=steps #这个是学习率调整的策略,有policy:constant, steps, exp, poly, step, sig, RANDOM,constant等方式
steps=200,400,600,20000,30000 #下面这两个参数steps和scale是设置学习率的变化,比如迭代到20000次时,学习率衰减十倍。
#30000次迭代时,学习率又会在前一个学习率的基础上衰减十倍
scales=2.5,2,2,.1,.1
max_batches = 40000
[convolutional] #卷积层
batch_normalize=1
filters=64 # 特征图数量
size=7 #卷积核大小
stride=2 # 步长
pad=1 #边缘拓展。输出尺寸通用公式:(输入尺寸-卷积核尺寸+2pad)/步长 )+1,理论认为卷积向下取整,池化向上取整,不同框架规则可能有差异
activation=leaky
[maxpool] #池化层
size=2
stride=2
[convolutional]
batch_normalize=1
filters=192
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
#######
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[local] #local层与convolution层很类似,只是convolution层共享卷积核参数,而local层每次滑动卷积窗口时,都会使用新的卷积核参数
size=3
stride=1
pad=1
filters=256
activation=leaky
[dropout]
probability=.5 #dropout层依一定概率将输入值重置为0并输出,然后作为下一层的输入,这个概率值为probability
[connected] #全连接层
output= 1715
activation=linear
#detection层得代码解析https://cloud.tencent.com/developer/article/1588094
[detection]
classes=20 #网络需要识别的物体种类数
coords=4 #每个box的4个坐标tx,ty,tw,th
rescore=1 #暂理解为一个开关,非0时通过重打分来调整l.delta(预测值与真实的差)
side=7 #gridcell尺寸
num=3 # gidcell预测几个box
softmax=0 #激活函数
sqrt=1 #yolo v1直接回归的sqrt(w), 所以与GT bbox 计算IOU前,需要pow一下
jitter=.2 #通过抖动增加噪声来抑制过拟合
object_scale=1 #以下为计算损失值的权重
noobject_scale=.5
class_scale=1
coord_scale=5
参考与引用资料:
yolov1深入理解
yolov1解读
中文论文
英文论文

















 2710
2710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









