







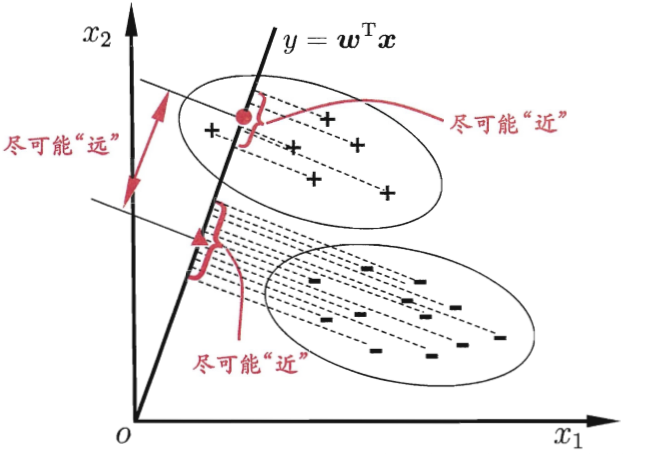
线性判别分析
\qquad 线性判别分析在降维中的运用:用过将高维的样本投影到最佳的矢量空间,投影后的样本在新的子空间有最大类间距离以及最小类内距离。也就是使投影后的数据内间散度矩阵大,类内散度矩阵小,等价于相同类别数据紧凑,不用类别离得远。
PCA与LDA之间的区别?
| PCA | LDA |
|---|---|
| 无监督的数据降维方法 | 有监督的数据降维方法 |
| 不使用数据标签 | 使用用数据标签 |
| 投影到方差最大的相互正交的方向上(保留更多的信息) | 尽可能多的保留样本信息;寻找使样本尽可能好分的方向;同类近,不同尽可能远 |
| 最多降到类别数N-1维 | |
| 可用于分类 |
LDA推导
二分类
数据集:D={(
x
1
x_1
x1,
y
1
y_1
y1),(
x
2
x_2
x2,
y
2
y_2
y2)…(
x
m
x_m
xm,
y
m
y_m
ym)}
\qquad
y
i
y_i
yi∈{0,1}
\qquad
x
i
x_i
xi∈
R
n
×
1
R^{n×1}
Rn×1
n:特征数
m:样本数量
m
i
m_i
mi:第i类样本数量
待求:投影方向
w
w
w
\qquad
w
w
w∈
R
n
×
1
R^{n×1}
Rn×1
μ
i
μ_i
μi:第i类数据集的样本均值
∑
i
\sum_i
∑i:第类数据集变换前的散度矩阵
\qquad
\qquad
∑
i
\sum_i
∑i=
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi(
x
x
x-
μ
i
μ_i
μi)(
x
x
x-
μ
i
μ_i
μi
)
T
)^T
)T
X
i
X_i
Xi:第i类拥有的数据集
w
T
w^T
wT
μ
i
μ_i
μi:第i类中心在
w
w
w上的投影
\qquad
w
T
w^T
wT
μ
i
μ_i
μi∈
R
1
×
1
R^{1×1}
R1×1
w
T
w^T
wT
x
i
x_i
xi:第i个样本在
w
w
w上的投影
\qquad
w
T
w^T
wT
x
i
x_i
xi∈
R
1
×
1
R^{1×1}
R1×1
w
T
w^T
wT
∑
i
\sum_i
∑i
w
w
w:投影后的方差
\qquad
w
T
w^T
wT
∑
i
\sum_i
∑i
w
w
w∈
R
1
×
1
R^{1×1}
R1×1
\qquad
\qquad
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi(
w
T
w^T
wT
x
x
x-
w
T
w^T
wT
μ
i
μ_i
μi)(
w
T
w^T
wT
x
x
x-
w
T
w^T
wT
μ
i
μ_i
μi
)
T
)^T
)T
\qquad
\qquad
=
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi
w
T
w^T
wT(
x
x
x-
μ
i
μ_i
μi)(
x
x
x-
μ
i
μ_i
μi
)
T
)^T
)T
w
w
w
\qquad
\qquad
=
w
T
w^T
wT
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi(
x
x
x-
μ
i
μ_i
μi)(
x
x
x-
μ
i
μ_i
μi
)
T
)^T
)T
w
w
w
\qquad
\qquad
=
w
T
w^T
wT
∑
i
\sum_i
∑i
w
w
w
类内方差小,类间距离大
目标函数:
\qquad
\qquad
\qquad
max J(
w
w
w)=
∣
∣
w
T
μ
0
−
w
T
μ
1
∣
∣
2
w
T
∑
0
w
+
w
T
∑
1
w
||w^Tμ_0-w^Tμ_1||^2\over w^T\sum_0w+w^T\sum_1w
wT∑0w+wT∑1w∣∣wTμ0−wTμ1∣∣2
\qquad
\qquad
\qquad
\qquad
\;\;\;\;\;\;
=
∣
∣
w
T
μ
0
−
w
T
μ
1
∣
∣
2
w
T
∑
0
w
+
w
T
∑
1
w
||w^Tμ_0-w^Tμ_1||^2\over w^T\sum_0w+w^T\sum_1w
wT∑0w+wT∑1w∣∣wTμ0−wTμ1∣∣2
\qquad
\qquad
\qquad
\qquad
\;\;\;\;\;\;
=
∣
∣
w
T
(
μ
0
−
μ
1
)
∣
∣
2
w
T
(
∑
0
+
∑
1
)
w
||w^T(μ_0-μ_1)||^2\over w^T(\sum_0+\sum_1)w
wT(∑0+∑1)w∣∣wT(μ0−μ1)∣∣2
\qquad
\qquad
\qquad
\qquad
\;\;\;\;\;\;
=
w
T
(
μ
0
−
μ
1
)
(
μ
0
−
μ
1
)
T
w
w
T
(
∑
0
+
∑
1
)
w
w^T(μ_0-μ_1)(μ_0-μ_1)^Tw\over w^T(\sum_0+\sum_1)w
wT(∑0+∑1)wwT(μ0−μ1)(μ0−μ1)Tw
类内散度矩阵(半正定矩阵,对称阵):
S
w
S_w
Sw=
∑
0
\sum_0
∑0+
∑
1
\sum_1
∑1
类间散度矩阵(对称阵):
S
b
S_b
Sb=(
μ
0
μ_0
μ0-
μ
1
μ_1
μ1)(
μ
0
μ_0
μ0-
μ
1
μ_1
μ1
)
T
)^T
)T
目标函数转化为:
\qquad
\qquad
\qquad
max J(
w
w
w)=
w
T
S
b
w
w
T
S
w
w
w^TS_bw\over w^TS_ww
wTSwwwTSbw
由广义瑞丽商得:J(
w
w
w)的最大值为
S
w
−
1
S_w^{-1}
Sw−1
S
b
S_b
Sb的最大特征值
求投影方向
w
w
w:最重要的是确定
w
w
w的方向
此时目标函数优化为:max
w
T
w^T
wT
S
b
S_b
Sb
w
w
w
\;\;\;\;\;\;
s.t.
w
T
w^T
wT
S
w
S_w
Sww$=1
拉格朗日:
\qquad
\qquad
\qquad
L(
w
w
w,λ)=
w
T
w^T
wT
S
b
S_b
Sb
w
w
w-λ(
w
T
w^T
wT
S
w
S_w
Sww
−
1
)
L
对
-1) L对
−1)L对w$求导,并且让其等于0
\qquad
\qquad
\qquad
(
S
b
S_b
Sb+
S
b
T
S_b^{T}
SbT)
w
w
w-λ(
S
w
S_w
Sw+
S
w
T
S_w^{T}
SwT)
w
w
w=0
\qquad
\qquad
\qquad
\qquad
\qquad
S
b
S_b
Sb
w
w
w=λ
S
w
S_w
Sw
w
w
w
\qquad
\qquad
\qquad
(1)
又
\qquad
S
b
S_b
Sb
w
w
w=(
μ
0
μ_0
μ0-
μ
1
μ_1
μ1)(
μ
0
μ_0
μ0-
μ
1
μ_1
μ1
)
T
)^T
)T
w
w
w
且 S b S_b Sb w w w的方向恒为 μ 0 μ_0 μ0- μ 1 μ_1 μ1
假设 \qquad S b S_b Sb w w w=λ( μ 0 μ_0 μ0- μ 1 μ_1 μ1) \qquad \qquad \qquad (2)
即让 \qquad λ=( μ 0 μ_0 μ0- μ 1 μ_1 μ1 ) T )^T )T w w w
(2)带入(1)得:
\qquad
\qquad
\qquad
w
w
w=
S
w
−
1
S_w^{-1}
Sw−1(
μ
0
μ_0
μ0-
μ
1
μ_1
μ1)
多分类
数据集:D={(
x
1
x_1
x1,
y
1
y_1
y1),(
x
2
x_2
x2,
y
2
y_2
y2)…(
x
m
x_m
xm,
y
m
y_m
ym)}
\qquad
y
i
y_i
yi∈{1,2…N}
\qquad
x
i
x_i
xi∈
R
n
×
1
R^{n×1}
Rn×1
N:类数
n:特征数
m:样本数量
m
i
m_i
mi:第i类样本数量
待求:投影矩阵
W
W
W={
w
1
w_1
w1,
w
2
w_2
w2…
w
d
w_d
wd}
\qquad
w
w
w∈
R
n
×
d
R^{n×d}
Rn×d
μ
i
μ_i
μi:第i类数据集的样本均值
μ
μ
μ:整个数据集的样本均值
全局散度矩阵:
S
t
S_t
St=
S
b
S_b
Sb+
S
w
S_w
Sw
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi(
x
x
x-
μ
μ
μ)(
x
x
x-
μ
μ
μ
)
T
)^T
)T
类内散度矩阵: S w S_w Sw= ∑ i = 1 N \sum_{i=1}^{N} ∑i=1N ∑ x ∈ X i \sum_{x∈X_i} ∑x∈Xi( x x x- μ i μ_i μi)( x x x- μ i μ_i μi ) T )^T )T
类间散度矩阵:
S
b
S_b
Sb=
S
t
S_t
St-
S
w
S_w
Sw
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi[(
x
x
x-
μ
μ
μ)(
x
x
x-
μ
μ
μ
)
T
)^T
)T-(
x
x
x-
μ
i
μ_i
μi)(
x
x
x-
μ
i
μ_i
μi
)
T
)^T
)T]
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi[
x
x
x
x
T
x^T
xT-
x
x
x
μ
T
μ^T
μT-
μ
μ
μ
x
T
x^T
xT+
μ
μ
μ
μ
T
μ^T
μT-
x
x
x
x
T
x^T
xT+
x
x
x
μ
i
T
μ_i^T
μiT+
μ
i
μ_i
μi
x
T
x^T
xT-
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT]
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N
∑
x
∈
X
i
\sum_{x∈X_i}
∑x∈Xi[-
x
x
x
μ
T
μ^T
μT-
μ
μ
μ
x
T
x^T
xT+
μ
μ
μ
μ
T
μ^T
μT+
x
x
x
μ
i
T
μ_i^T
μiT+
μ
i
μ_i
μi
x
T
x^T
xT-
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT]
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N[-
m
i
m_i
mi
μ
i
μ_i
μi
μ
T
μ^T
μT-
m
i
m_i
mi
μ
μ
μ
μ
i
T
μ_i^T
μiT+
m
i
m_i
mi
μ
μ
μ
μ
T
μ^T
μT+
m
i
m_i
mi
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT+
m
i
m_i
mi
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT-
m
i
m_i
mi
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT]
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N[-
m
i
m_i
mi
μ
i
μ_i
μi
μ
T
μ^T
μT-
m
i
m_i
mi
μ
μ
μ
μ
i
T
μ_i^T
μiT+
m
i
m_i
mi
μ
μ
μ
μ
T
μ^T
μT+
m
i
m_i
mi
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT]
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N
m
i
m_i
mi[-
μ
i
μ_i
μi
μ
T
μ^T
μT-
μ
μ
μ
μ
i
T
μ_i^T
μiT+
μ
μ
μ
μ
T
μ^T
μT+
μ
i
μ_i
μi
μ
i
T
μ_i^T
μiT]
\qquad
\qquad
\qquad
\;\;\;
=
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N
m
i
m_i
mi(
μ
i
μ_i
μi-
μ
μ
μ)(
μ
i
μ_i
μi-
μ
μ
μ
)
T
)^T
)T
目标函数:
\qquad
\qquad
argmax J(
w
i
w_i
wi)=
∑
i
=
1
d
w
i
T
S
b
w
i
∑
i
=
1
d
w
i
T
S
w
w
i
\sum_{i=1}^{d}w_i^TS_bw_i\over \sum_{i=1}^{d}w_i^TS_ww_i
∑i=1dwiTSwwi∑i=1dwiTSbwi
\qquad
\qquad
\qquad
\qquad
\;\;\;\;
=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d
w
i
T
S
b
w
i
w
i
T
S
w
w
i
w_i^TS_bw_i\over w_i^TS_ww_i
wiTSwwiwiTSbwi
由广义瑞丽熵得:J(
w
i
w_i
wi)的最大值为
S
w
−
1
S_w^{-1}
Sw−1
S
b
S_b
Sb的最大d个特征值之和
求
w
i
w_i
wi:
\qquad
\qquad
argmax J(
w
i
w_i
wi)=
∑
i
=
1
d
\sum_{i=1}^{d}
∑i=1d
w
i
T
S
b
w
i
w
i
T
S
w
w
i
w_i^TS_bw_i\over w_i^TS_ww_i
wiTSwwiwiTSbwi
\qquad
\qquad
\qquad
\qquad
\;\;\;\;
=
t
r
(
W
T
S
b
W
)
t
r
(
W
T
S
w
W
)
tr(W^TS_bW)\over tr(W^TS_wW)
tr(WTSwW)tr(WTSbW)
等价于:
\qquad
\qquad
argmax tr(
W
T
W^T
WT
S
b
S_b
Sb
W
W
W)
\qquad
\qquad
s.t. tr(
W
T
W^T
WT
S
w
S_w
Sw
W
W
W)=1
拉格朗日:
\qquad
L(W,∧)=-tr(
W
T
W^T
WT
S
b
S_b
Sb
W
W
W)+tr(∧(
W
T
{W^T}
WT
S
w
S_w
Sw
W
W
W-I))
∧=diag(
λ
1
λ_1
λ1,
λ
2
λ_2
λ2…
λ
d
λ_d
λd)
L对W求导,并让其为0:
\qquad
\qquad
\qquad
(
S
b
S_b
Sb+
S
b
T
S_b^{T}
SbT)
W
W
W-∧(
S
w
S_w
Sw+
S
w
T
S_w^{T}
SwT)
W
W
W=0
\qquad
\qquad
\qquad
\qquad
\qquad
S
b
S_b
Sb
W
W
W=∧
S
w
S_w
Sw
W
W
W
对任意
λ
i
λ_i
λi都有:
\qquad
\qquad
\qquad
\qquad
\qquad
S
b
S_b
Sb
W
W
W=
λ
i
λ_i
λi
S
w
S_w
Sw
W
W
W
=>
\qquad
\qquad
\qquad
\qquad
\;\;\;\;
S
w
−
1
S_w^{-1}
Sw−1
S
b
S_b
Sb
W
W
W=
λ
i
λ_i
λi
W
W
W
w i w_i wi为 S w − 1 S_w^{-1} Sw−1 S b S_b Sb的d个最大特征值对应的特征向量
iris实例
LDA降维步骤
- 计算每类的均值向量
- 计算整个样本的均值向量
- 计算类内散度矩阵 S w S_w Sw以及类间散度矩阵 S b S_b Sb
- 计算 S w − 1 S_w^{-1} Sw−1 S b S_b Sb的特征值以及特征向量,选取前d个最大特征值对应的特征向量,组成矩阵W
- 对原始数据降维。降维数据Y= W T W^T WTX
单步
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris=datasets.load_iris()
#一共三类数据
x=iris.data
y=iris.target
x1=iris.data[:50,:4]
x2=iris.data[50:100,:4]
x3=iris.data[100:150,:4]
#print(x1)
#print(x2)
#print(x3)
print(iris)

#求每内样本的均值向量
x1_mean=x1.mean(axis=0)
x2_mean=x2.mean(axis=0)
x3_mean=x3.mean(axis=0)
print(x1_mean)
print(x2_mean)
print(x3_mean)

#求整个数据集的均值向量
x_mean=x.mean(axis=0)
print(x_mean)
print((x1_mean+x2_mean+x3_mean)/3)

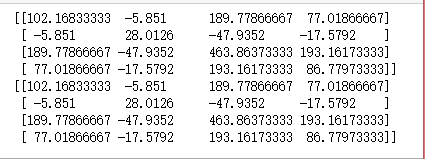
#计算全局散度矩阵
x=x-x.mean(axis=0)
st=np.zeros((4,4))
print(x)
print(st)

for i in range(len(x)):
st+=np.dot(x[i,np.newaxis].T,x[i,np.newaxis])
print(st)
#print(st/150)
print(np.dot(x.T,x))
#计算类内散度矩阵
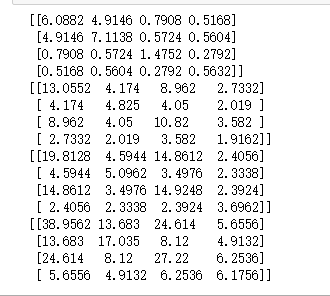
x1=x1-x1_mean
sw1=np.zeros((4,4))
for i in range(len(x1)):
sw1+=np.dot(x1[i,np.newaxis].T,x1[i,np.newaxis])
x2=x2-x2_mean
sw2=np.zeros((4,4))
for i in range(len(x2)):
sw2+=np.dot(x2[i,np.newaxis].T,x2[i,np.newaxis])
x3=x3-x3_mean
sw3=np.zeros((4,4))
for i in range(len(x3)):
sw3+=np.dot(x3[i,np.newaxis].T,x3[i,np.newaxis])
print(sw1)
print(sw2)
print(sw3)
sw=sw1+sw2+sw3
print(sw)
#计算内间散度矩阵
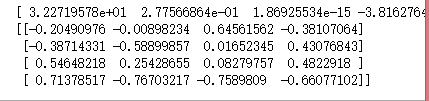
sb=st-sw
print(sb)

#svd求sw的逆矩阵
U,A,V=np.linalg.svd(sw)
#求A的逆矩阵
SA=np.linalg.inv(np.diag(A))
print(SA)
#计算sw的逆
VSAU=np.dot(np.dot(V.T,SA),U.T)
print(VSAU)
#计算sw-1*sb
Swb=np.dot(VSAU,sb)
print(Swb)

#特征值分解
val,vector=np.linalg.eig(Swb)
#只保留实数部分
val=np.real(val)
vector=np.real(vector)
print(val)
print(vector)
#排序
index=np.argsort(-val)
print(index)
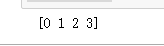
#假设降到二维
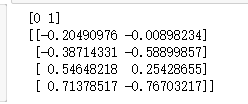
print(index[:2])
Z=vector[:,index[:2]]
print(Z)
#降维后矩阵
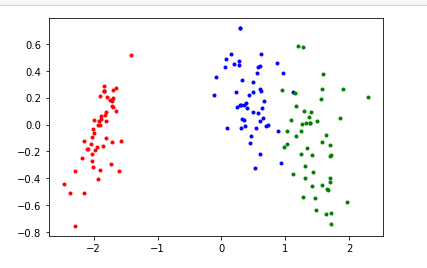
Y=np.dot(x,Z)
print(Y)

#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],Y[i][1],c='g',marker='.')
plt.show()
函数
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import random
class LinearDiscriminantAnalysis():
def __init__(self,n_components):
#特征数
self.n_components=n_components
#类别数
self.classes=0
#整个数据集的均值向量
self.X_mean=0
#特征向量
self.eig_vectors=0
def fit_transform(self,X,y):
#计算样本数量以及特征数
self.n_samples,self.n_features=X.shape
#print(self.n_samples)
#计算类别数,y_index存放相对于classes的类别索引
self.classes,y_index=np.unique(y,return_inverse=True)
#计算整体样本的均值向量
self.X_mean=np.zeros((1,self.n_features))
self.X_mean=np.copy(X.mean(axis=0))
# print(self.X_mean)
#计算全集散度矩阵
st=np.zeros((self.n_features,self.n_features))
for i in range(self.n_samples):
temp=X[i]-self.X_mean
#st+=np.dot((X[i,np.newaxis]-self.X_mean[0,np.newaxis]).T,(X[i,np.newaxis]-self.X_mean[0,np.newaxis]))
st+=np.dot(temp[np.newaxis,:].T,temp[np.newaxis,:])
#print(st)
#计算每类样本的均值向量
means=np.zeros((len(self.classes),self.n_features))
#i代表第几个类别,从0起
for i in range(len(self.classes)):
#计算每类个数
count=0
for j in range(self.n_samples):
if y[j]==self.classes[i]:
means[i]+=X[j]
count+=1
means[i]=means[i]/count
#按类别去中心化,同时求类内散度矩阵
#print(means)
sw=np.zeros((self.n_features,self.n_features))
for i in range(self.n_samples):
temp=X[i]-means[y_index[i]]
#sw+=np.dot((X[i,np.newaxis]-means[y_index[i],np.newaxis]).T,(X[i,np.newaxis]-means[y_index[i],np.newaxis]))
sw+=np.dot(temp[np.newaxis,:].T,temp[np.newaxis,:])
# print(sw)
#计算类间散度矩阵
sb=st-sw
#SVD求sw的逆矩阵
U,A,V=np.linalg.svd(sw)
#计算对角矩阵的逆矩阵
SA=np.linalg.inv(np.diag(A))
#计算sw的逆
VSAU=np.dot(np.dot(V.T,SA),U.T)
#计算SW-1Sb
Swb=np.dot(VSAU,sb)
# print(Swb)
#特征值分解
eig_vals,eig_vectors=np.linalg.eig(Swb)
#特征值排序
index=np.argsort(-eig_vals)
#选取特征向量
if self.n_components==0:
self.n_components=len(self.classes)-1
self.vectors=eig_vectors[:,index[:self.n_components]]
#返回降维后的数据
return np.dot(X,self.vectors)
iris=datasets.load_iris()
#打乱数据
data_size=iris.data.shape[0]
#生成索引-列表
index=[i for i in range(data_size)]
#打乱
random.shuffle(index)
#通过打算的索引重新取值,相应的标签也要打乱
iris.data=iris.data[index]
iris.target=iris.target[index]
x=iris.data
y=iris.target
lda=LinearDiscriminantAnalysis(2)
Y=lda.fit_transform(X=x,y=y)
#画图
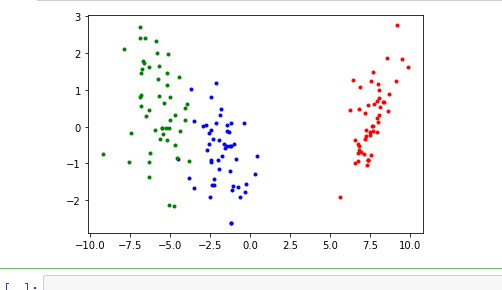
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],Y[i][1],c='g',marker='.')
plt.show()
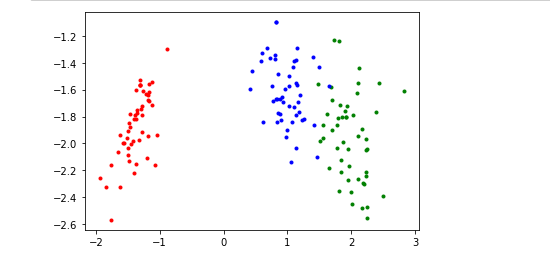
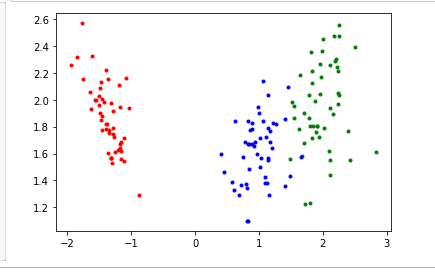
可能会有相反问题,这是特征向量方向的问题。
sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
iris=datasets.load_iris()
x=iris.data
y=iris.target
lda=LinearDiscriminantAnalysis(n_components=2)
Y=lda.fit(x,y).transform(x)
#画图
for i in range(len(y)):
if y[i]==0:
plt.scatter(Y[i][0],Y[i][1],c='r',marker='.')
elif y[i]==1:
plt.scatter(Y[i][0],Y[i][1],c='b',marker='.')
else:
plt.scatter(Y[i][0],Y[i][1],c='g',marker='.')
plt.show()
















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











