









 本文提出NeRF-SR,一种利用超采样策略和细化网络的解决方案,能在低分辨率输入下生成高质量的高分辨率新视图。方法基于神经辐射场,通过多视图约束和HR参考图像细节补充,有效提升新视图合成效果。实验在合成数据集和真实世界场景中展示了卓越性能。
本文提出NeRF-SR,一种利用超采样策略和细化网络的解决方案,能在低分辨率输入下生成高质量的高分辨率新视图。方法基于神经辐射场,通过多视图约束和HR参考图像细节补充,有效提升新视图合成效果。实验在合成数据集和真实世界场景中展示了卓越性能。
使用超采样的高质量神经辐射场
目录
5.3. Effectiveness of super-sampling
Abstract
我们提出了NeRF-SR,一种高分辨率(HR)新视图合成的解决方案,主要采用低分辨率(LR)输入。我们的方法是建立在神经辐射场(NeRF)[33]的基础上的,该[33]通过多层感知器预测每一个点的密度和颜色。在生成任意尺度的图像时,NeRF正在努力处理超出观测图像的分辨率。我们的关键见解是,NeRF有一个局部先验,这意味着一个三维点的预测可以在附近的区域传播,并保持准确。我们首先利用一种超采样策略,在每个图像像素上拍摄多条光线,从而在亚像素水平上施加多视图约束。然后,我们证明了NeRF-SR可以通过细化网络进一步提高超采样的性能,该网络利用手头的估计深度从HR参考图像上的相关补丁补充细节( leverages the estimated depth at hand to hallucinate使产生幻觉details from related patches on an HR reference image)。实验结果表明,NeRF-SR在合成数据集和真实数据集上都产生了高质量的新视图合成结果。
1. Introduction
从一个新的角度合成逼真的观点,给定一组姿势图像,称为新视角合成,一直是计算机视觉社区长期存在的问题,也是虚拟现实和增强现实应用的重要技术。最近,神经渲染通过利用可学习的三维几何上下文组件来重建输入图像,在新的视图合成方面取得了重大进展。神经辐射场(NeRF)[33]作为目前最先进的方法,已经成为一个很有前途的场景表示方向,即使是在复杂的真实场景的稀疏图像集上。NeRF使用多层感知器(MLPs)的权重来编码一个场景的辐射场和体积密度。最重要的是,隐式神经表示是连续的,这使得NeRF可以在推理时将体积中的任何位置作为输入,并呈现任意分辨率的图像。
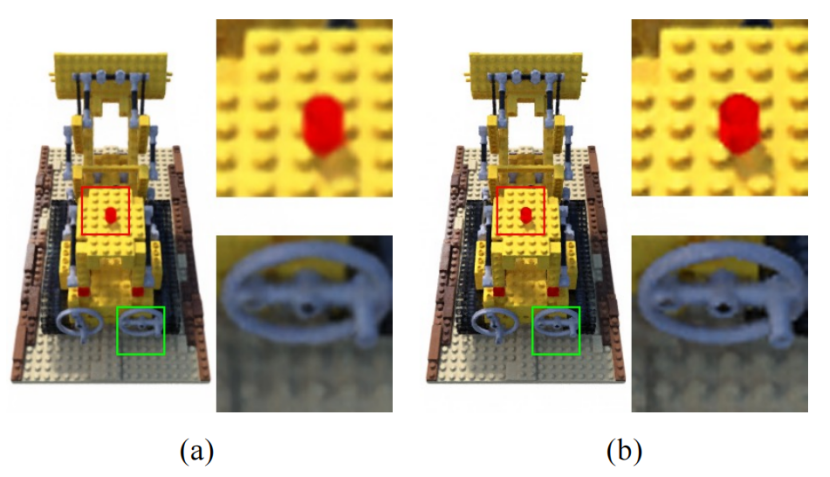
图1。NeRF可以在训练图像的分辨率下合成关于地面真实的逼真的输出,但难以合成更高的分辨率,如(a)所示,而NeRF-SR即使在低分辨率输入下也能产生高质量的新视图(b)。
高分辨率的3D场景对于许多场景都是必不可少的,例如,在VR中提供沉浸式虚拟环境的先决条件。然而,在低分辨率(LR)图像上训练的NeRF通常会产生更高分辨率的模糊视图(见图1)。为了解决这个问题,我们提出了NeRF-SR技术,这是一种扩展NeRF,并创建高分辨率(HR)新视图的技术。首先,我们观察到在超分辨输入图像的训练和测试阶段之间存在一个采样差距。为此,我们提出了一种超采样策略,以更好地加强嵌入在NeRF中的多视图一致性,并将单个像素的结果传播到亚像素sub-pixels,从而能够同时生成SR图像SR images和SR深度图SR depth maps。其次,当HR图像有限且无法预测摄像机参数时,我们对最后一阶段的输出进行改进,采用只有一个HR参考的补丁扭曲细化策略patch-wise warp-and-refifine strategy,受益于估计深度,并从参考中提取具有细节的补丁。据我们所知,我们是第一个在低分辨率图像下为新的视图合成产生视觉愉悦的结果的人。我们的方法只需要目标场景的图像,从中我们可以深入挖掘内部统计数据,而不依赖于任何外部先验。
我们的贡献总结如下:
- NeRF的一种扩展,主要通过LR输入图像产生良好的超分辨率结果
- 在NeRF中桥梁训练和测试阶段之间的采样差距的超级采样策略
- 一个细化网络,通过寻找具有可用深度地图的相关补丁relevant patches with available depth maps ,混合HR参考的细节
2、Related Work
Novel View Synthesis.
新的视图合成可以分为基于图像的方法、基于学习的方法和基于几何的方法。基于图像的方法在观测帧中扭曲和混合相关斑块,基于质量[12,22]的测量生成新的视图。基于学习的方法通过神经网络和/或其他手工制作的启发式[6,13,43,58]来预测混合权重和视图依赖的效应。深度学习也促进了从单一图像中预测新视图的方法,但它们通常需要大量的数据来训练[36,45,51,60,66]。与基于图像和基于学习的方法不同,基于几何的方法首先重建一个三维模型[48],并从目标姿态渲染图像。例如,Aliev等人[1]将多分辨率特征分配给点云,然后进行神经渲染,Thies等人[57]将神经纹理存储在三维网格上,然后用传统的图形管道渲染新的视图。其他几何表示包括多平面图像[10,23,24,32,55,76]、体素网格[14,18,41]、深度[10,43,44,66]和分层深度[51,61]。这些方法,虽然产生了相对高质量的结果,但离散表示需要丰富的数据和内存,而渲染的分辨率也受到重建几何图形的精度的限制。
神经辐射场
隐式神经表示已经证明了它在表示形状和场景方面的有效性,这通常利用多层感知器(MLPs)来编码有符号的距离场 signed distance fields [9,37]、占用occupancy [5,31,40]或体积密度 volume density [33,35]。与可微渲染[19,27]一起,这些方法可以重建对象和场景[26,35,46,52,53]的几何形状和外观。其中,神经辐射场(NeRF)[33]在合成给定一组姿态输入图像的静态场景的新视图方面取得了显著的效果。NeRF的关键思想是利用mlp构造一个连续的辐射场,并通过可微体积渲染来获得图像,因此,优化过程可以通过最小化光度损失photometric loss来实现。出现了越来越多的NeRF扩展,例如,没有输入摄像机姿态[25,64]的重建,建模非刚性场景non-rigid scenes [29,38,39,42],无界场景unbounded scenes[72]和对象类别object categories [16,59,70]。NeRF也被研究为能够重新激活[3,54],generation[34,49],editing[28,68],3D重建[4,65,71]。
与我们的工作相关,Mip-NeRF[2]也考虑了NeRF的解决问题。他们表明,在不同分辨率下呈现的nerf将引入混叠伪影,并通过提出一个集成的位置编码,使锥形而不是单点来解决它。然而,Mip-NeRF只考虑具有低采样分辨率的渲染。据我们所知,目前还没有任何工作来研究如何提高NeRF的分辨率。
Image Super-Resolution
我们的工作也与图像的超分辨率有关。经典的单图像超分辨率(SISR)方法利用先验,如图像统计[20,77]或[56]梯度。基于CNN的方法旨在通过最小化SR图像和地面真相[7,8,62]之间的均方误差来学习CNN中HR和LR图像之间的关系。生成对抗网络(GANs)[11]在超分辨率中也很流行,它通过对抗学习[21,30,47]产生高分辨率的细节。这些方法大多从大规模的数据集或现有的高分辨率和低分辨率的训练对中获得知识。此外,这些基于二维图像的方法,特别是基于gan的方法没有考虑到视图的一致性,对于新的视图合成是次优的。
Reference-based image super-resolution (Ref-SR) upscales输入图像与额外的参考高分辨率(HR)图像。现有的方法将补丁匹配patch-match [74,75]、特征提取[67,69]或注意力[69]的HR引用和LR输入之间的对应关系进行匹配。受他们作品的启发,我们还致力于从给定的参考图像中学习HR细节。然而,这些方法大多基于参考只超解析 super-resolve一个SR输入,而我们的方法可以通过一个参考图像从所有新视图中细化细节。
3、Background(Nerf介绍)

神经辐射场(NeRF)[33]将三维场景编码为连续函数,以3D位置x=(x,y,z)和观察的视角方向d=(θ,φ)作为输入,并预测辐射c(x,d)=(r,g,b)和体积密度σ(x)。颜色取决于查看方向d和x来捕获与视图相关的效果,而密度仅依赖于x来保持视图的一致性。NeRF通常由一个多层感知器(MLP)f:(x,d)→(c,σ)参数化
NeRF是一种仅发射emission-only的模型(像素的颜色仅取决于沿光线的亮度,没有其他照明因素)。因此,根据体积渲染[17],通过沿着从相机中心o方向d拍摄的相机光线r(t)=o+td的颜色积分,可以从虚拟相机在任意位置渲染图像:
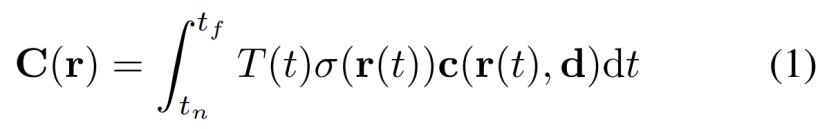
其中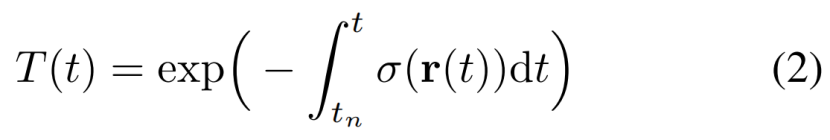
是表示一条射线从tn传播到t而不撞击任何粒子的概率的累积透射率accumulated transmittance。
NeRF被训练成最小化一个射线r的渲染和相应的地面真实颜色之间的均方误差(MSE):
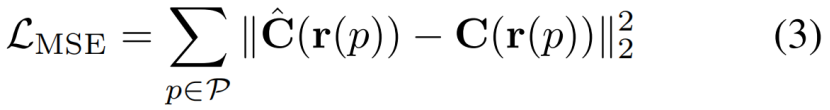
其中P表示训练集图像的所有像素,r(p)表示从摄像机中心到角落(或某些变体[2]中的中心)的射线拍摄。ˆC(r(p))和C(r(p))表示地面真实值和预测的颜色。
在实际应用中,方程(1)中的积分近似为数值求积,它将有限数量的点与光线一起采样,并根据估计的每点透射率计算辐射之和。NeRF中的采样采用两个mlp的粗到细机制,即在等间隔的样本上查询粗网络,利用输出对另一组点进行采样以获得更准确的估计,然后对两组样本查询精细网络。
4、Approach
在本节中,我们将介绍NeRF-SR的细节。总体结构如图2所示。超采样策略The supersampling strategy和补丁细化网络 patch refinement network将在第4.1节和第4.2节中进行介绍。
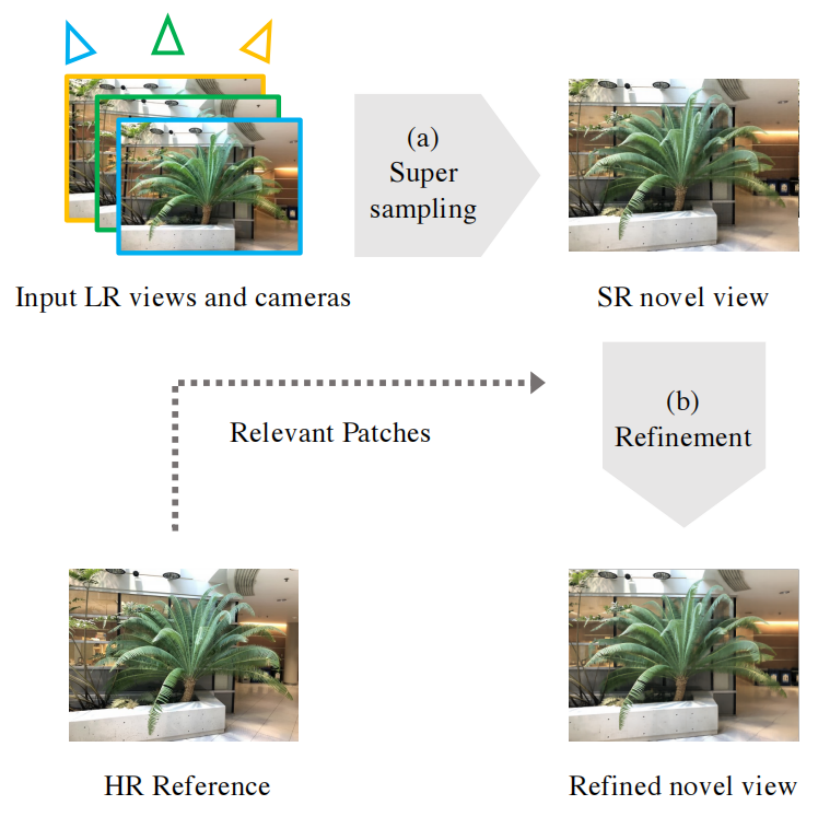
图2。概述了所提出的NeRF-SR,其中包括两个组件。(a),我们采用超采样策略,只从低分辨率的输入中产生超分辨率的新视图。(b)给定一个在任何视点上的高分辨率参考,从中我们利用手头的深度图来提取相关的补丁,NeRF-SR为合成图像生成更多的细节。
4.1. Super Sampling
NeRF通过增强多视图的颜色一致性来优化辐射场,并基于训练集中的相机姿态和像素位置来采样射线。与空间中无限可能的入射射线方向相比,在有限的输入图像观测条件下,采样相当稀疏。然而,NeRF仍然可以创建合理的新视图,因为输出分辨率与输入分辨率相同,而且它依赖于神经网络的插值特性。当我们以比训练图像更高的分辨率渲染图像时,这就成为了一个问题,具体来说,在训练阶段和测试阶段之间存在着一个差距。假设一个NeRF在分辨率为H×W的图像上进行训练,这是在尺度因子s上重建训练图像最直接的方法,即分辨率为sH×sW的图像在原始像素中采样s2射线网格。显然,不仅在训练过程中从未见过采样的射线方向,而且查询的像素对应于一个更小的区域。针对这个问题,我们提出了一个超采样策略来解决为NeRF渲染SR图像的问题。超级采样的直觉解释如下,并如图3所示。
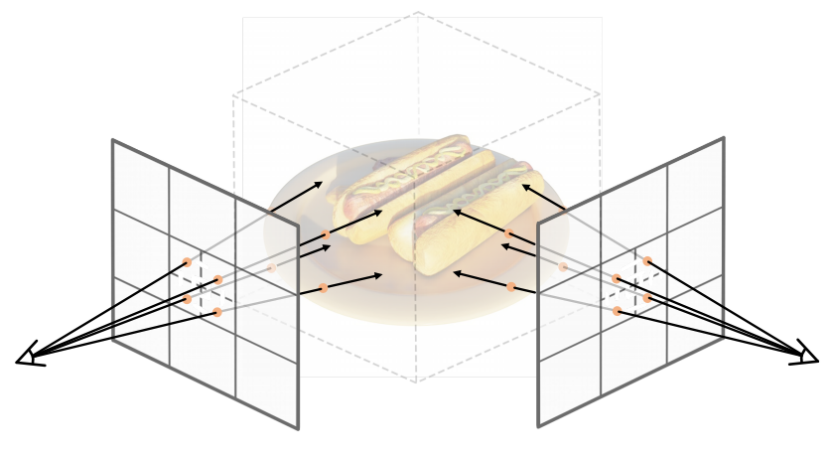
图3。超采样策略将一个像素(实线)分割为多个子像素(虚线),并为每个子像素绘制一条射线。因此,与普通的NeRF相比,场景中更多的3D点可以被对应和约束。
我们从图像形成的过程开始。设R(p)表示训练图像中像素p的所有可能的射线方向的集合,p的颜色可以表示为:
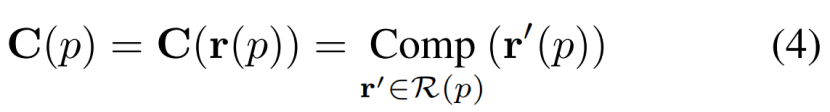
其中Comp是R(p)中包含的所有入射光线的辐射的组成和栅格化过程rasterization process。虽然理想情况下,训练射线方向应该从R(p)中采样,但网络拟合这一庞大的数据是一个挑战。在实际应用中,为了在s的尺度上对图像进行超分辨,将一个像素均匀地分割成一个s×s grid sub-pixels S(p),像素p的射线方向将从![]() 中采样进行训练。因此,通过渲染子像素,可以直接获得一个sH × sW图像,消除训练和测试阶段之间的采样间隙。
中采样进行训练。因此,通过渲染子像素,可以直接获得一个sH × sW图像,消除训练和测试阶段之间的采样间隙。
另一个问题是如何在H×W维度上仅对地面真实图像进行监督。与blind-SR问题类似,从H×W维的降解过程是未知的,可能受到许多因素的影响。为了中止对降采样操作的任何假设,并使其适用于所有情况,我们averaged the radiances rendered from R’(p),以执行监督supervision(“average” kernel):
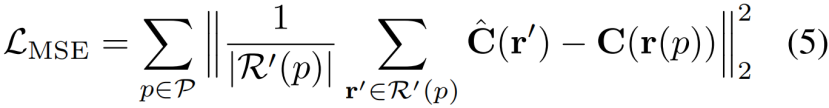
超采样充分利用了NeRF引入的交叉视图一致性 cross-view consistency到亚像素级 sub-pixel level,即一个位置可以通过多个视点进行对应。虽然NeRF对每个像素只拍摄一条射线,并优化了该射线上的点,但超采样限制了三维空间中更多的位置,更好地利用了输入图像中的多视图信息。换句话说,超级采样直接在训练时优化了一个更密集的辐射场。
4.2. Patch-Based Refinement
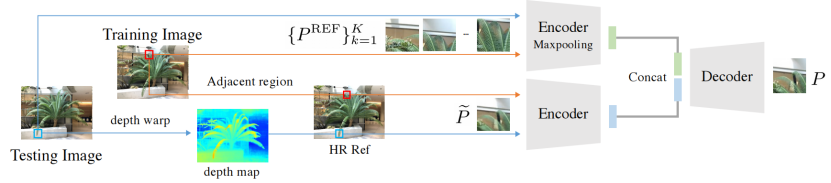 图4。我们的细化模块从IREF的超采样和参考补丁{PREF}Kk=1产生的图像中编码合成的补丁P~。IREF的编码特征被最大值池化maxpooled,并与P~的编码特征连接,然后将P~解码生成细化的补丁。在训练阶段,在IREF的相机姿态下从合成的SR图像中采样P~,并在相邻区域采样{PREF}Kk=1。在测试时,通过深度扭曲 depth warping得到{PREF}Kk=1。(为了更好的说明,输入和输出补丁被放大,放大以看到细化后的叶子的细节)
图4。我们的细化模块从IREF的超采样和参考补丁{PREF}Kk=1产生的图像中编码合成的补丁P~。IREF的编码特征被最大值池化maxpooled,并与P~的编码特征连接,然后将P~解码生成细化的补丁。在训练阶段,在IREF的相机姿态下从合成的SR图像中采样P~,并在相邻区域采样{PREF}Kk=1。在测试时,通过深度扭曲 depth warping得到{PREF}Kk=1。(为了更好的说明,输入和输出补丁被放大,放大以看到细化后的叶子的细节)
通过超采样,合成的图像比普通的NeRF获得了更好的视觉质量。然而,当一个场景的图像没有足够的亚像素对应时,超采样的结果无法找到足够的细节来进行高分辨率的合成。另一方面,通常有限的高分辨率图像,例如HR全光学图像HR panoptic image或设备的照片 shots from devices,其中HR内容可用于进一步改进结果。
因此,我们提出了一个基于补丁的细化网络patch-based refinement network,来恢复由HR参考输入HR reference input引入的高频细节,如图4所示。核心设计考虑的重点是如何将参考图像IREF上的细节“混合”到已经捕获了整体结构的NeRF合成的SR图像中。我们采用了逐个补丁patch-by-patch的细化策略,将SR补丁P~转化为细化补丁P。除了P~之外,输入还应该包括来自IREF的HR补丁,揭示P~中的对象或纹理是如何以高分辨率呈现的。然而,由于遮挡和深度估计的不准确,需要多个HR补丁片覆盖P~区域,我们使用K 个补丁 {PREF}Kk=1作为参考。此外,{PREF}Kk=1中的补丁比P~覆盖更大的区域,包含的相关信息较少。

我们使用了一个基于U-Net的卷积架构作为细化网络refinement network,这已经在现有的几种新的视图合成方法[6,43,44]中证明了其有效性。在早期的尝试中,我们将细化过程建模为一个图像到图像的转换[15],并发现通道级堆栈 channel-wise stack P~和{PREF}Kk=1不能完美地拟合训练集。因此,受[6,43]的启发,我们分别用一个由七个卷积层组成的编码器对每个补丁进行编码。该网络的解码器将具有相同空间分辨率的已编码特征P~和 maxpooled features of {PREF}Kk=1的前一层的最近邻上采样特征作为输入。所有的卷积层之后都有一个ReLU激活。

Training
细化网络的训练需要SR和HR patch pairs,这只在IREF的相机姿态上可用。因此,从SR图像中随机抽取P~,P是IREF上同一位置的patch。我们对P~和P进行透视变换,因为在测试过程中,输入的补丁大多来自不同的相机姿态。此外,为了解释在测试时参考补丁的不准确性,我们在一个固定窗口内P 采样{PREF}Kk=1。为了保持P~的空间结构,同时提高其质量,我们的目标函数结合重建损失Lrec和感知损失Lper,
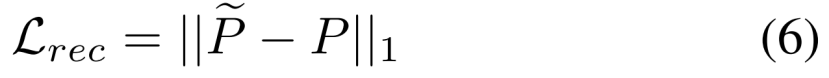
请注意,我们采用了l1-范数而不是MSE,因为它在超采样中已经被最小化了,而l1-范数将使结果更加锐化。
Testing
在推理时,给定合成图像In上的一个补丁P~,我们可以在P~上的每个像素的参考图像IREF上找到一个高分辨率的参考补丁:
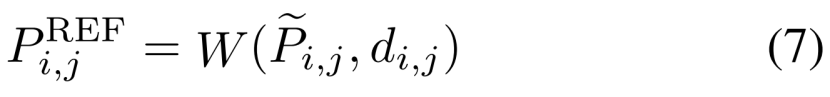
式中,i,j表示补丁P~上的一个位置,d为估计深度,W为翘曲操作。W首先基于di,j计算i,j的三维坐标,投影到IREF上,根据相机的本质和外部提取参考补丁。因此,为了得到P,我们首先从{Pi,jREF}中抽取K个补丁,构造{PREF}Kk=1,然后将它们与P~一起输入网络。

5. Experiments
在本节中,我们提供了定量和定性的比较,以证明所提出的NeRF-SR的优势。我们首先展示超采样的结果和分析,然后演示细化网络如何为其添加更多的细节。我们只有超采样的结果记为Ours-SS,基于补丁的细化后的结果记为Ours-Refine
5.1. Dataset and Metrics
为了评估我们的方法,我们在两个数据集上训练和测试了我们的模型。我们使用峰值信噪比(PSNR)和结构相似性指数度量(SSIM)[63]和LPIPS[73]三个指标来评估来自同一姿态的地面真实的视图合成质量。
Blender Dataset
【32】的真实的合成360◦(称为Blender 数据集)包含8个详细的合成物体,其中100张图像来自于排列在一个半球向内的虚拟相机。与NeRF[33]一样,对于每个场景,我们输入100个视图进行训练,并保留200张图像进行测试。
LLFF Dataset
LLFF数据集[32,33]由8个真实世界的场景组成,主要包含正向的图像。我们对所有的图像进行训练,并报告整个集合上的平均指标。
5.2. Training Details
我们使用PyTorch在NeRF[33]之上实现了所有的实验。当我们独立地对不同的图像分辨率进行训练时,为了公平比较,我们分别将blender数据集和llff数据集训练为20个epoch和30个epoch,其中每个epoch包含整个训练集的迭代。我们选择Adam作为优化器(超参数β1=0.9,β2=0.999),batch size设置为2048(2048个射线一batch为所有实验规模)和学习率从5x10^−4呈指数下降到5x10^−6。在NeRF之后,NeRF-SR还使用了具有“粗”和“细”MLP的分层采样。粗样本和细样本均设为64。
5.3. Effectiveness of super-sampling
对于blender数据集,我们在两种分辨率上进行了超级采样:100×100和200×200,以及test scales×2和×4。对于LLFF数据集,输入分辨率为504×378,我们也升级upscale by×2和×4。数据集中的图像从原始分辨率到训练分辨率的降缩放是通过Pillow包中默认的lanczos方法完成的。
图10显示了在blender场景子集上的所有方法的定性结果。从双边缘bicubic的渲染显示出正确的全局形状,但缺乏高频细节。如果场景已经在输入分辨率下很好地重建,Vanilla NeRF产生的渲染比双边缘有更多的细节。但是,它仍然受到输入图像中的信息的限制。NeRF-SR通过超采样找到亚像素级的对应关系,这意味着在三维空间中邻近区域的其他视图中也可以发现输入中缺失的细节。
blender数据集的定量结果汇总见表1。在输入图像上直接训练NeRF并渲染高分辨率输出会导致相当差的结果,无法与双边插值 bicubic interpolation竞争。NeRF-SR除了200×200输入的SSIM外,NeRF-SR在所有情况下都优于NeRF和双边缘。我们敦促读者检查视觉结果,看看双边缘是如何被严重平滑的。

表1。在blender数据集上的新视图合成的质量指标。我们报告了两种输入分辨率(100×100和200×200)上的比例因子×2和×4的PSNR/SSIM/LPIPS。虽然Bicubic在分辨率200×200方面实现了略好的SSIM,但我们建议读者看看我们的方法产生更好结构和细节的效果图。
LLFF数据集的定性和定量结果分别见图11和表2。NeRF-SR即使在复杂的场景中也要填写细节,并显著优于其他基线。
在第4.1节中,我们提到,由于退化过程的未知性质,监督是通过比较子像素的平均颜色来执行的。我们进一步的实验条件表明,对于分辨率为100×100的blender数据,从高分辨率到输入图像的退化也是平均的。结果显示,这种对称的降尺度和高档操作比非对称的操作提供了更好的效果图(见图7)。PSNR、SSIM、LPIPs均提高到scale ×2的30.94dB、0.956、0.023,scale ×4分别为28.28dB、0.925和0.061。其对降解过程的灵敏度与单图像超分辨率相似。

图7。当降尺度方法 downscale method和监督信号supervision signal都是“平均”(输入分辨率为100×100, upscaled by 4)时的视觉结果。与非对称操作相比,对称平均低尺度和上尺度产生更详细的超分辨率新视图合成。
5.4. Refifinement network
LLFF数据集包含了真实世界的图片,其结构比blender数据集要复杂得多,而超采样还不足以进行逼真的渲染。我们通过在第4.2节中引入的细化网络来进一步提高其输出。我们使用固定数量的参考补丁(K=8),补丁的尺寸设置为64×64。在推断时,输入的图像被分成不重叠的斑块non-overlapping patches,经过细化后缝合在一起。在不损失慷慨generosity的情况下,我们将所有场景的参考图像设置为数据集中的第一个图像,这在计算度量时省略。
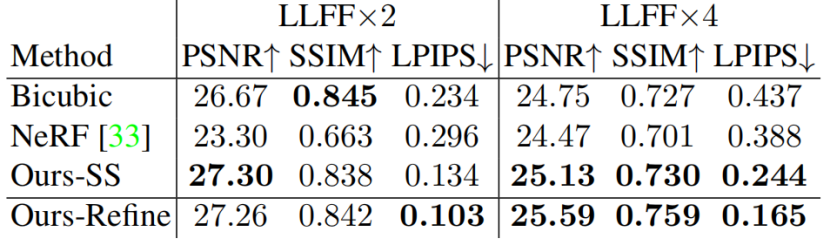
表2。在LLFF数据集上进行视图合成的质量指标。我们报告了比例因子×2和×4在输入分辨率(504×378)上的PSNR/SSIM/LPIPS。
细化的定量结果见表2。经过细化后,指标在×4的规模上得到了显著的改进。对于×2的尺度,PSNR略有下降,一个可能的原因是,超采样已经学习了一个不错的高分辨率神经辐射场的小上采样,改进只改善了细微的细节,即如图8所示的噪声点,这对PSNR产生了负面影响,但LPIPS仍然得到了提升。然而,对于像4这样的更大的放大倍数,这个问题不会出现,因为超采样从低分辨率的输入中获得更少的细节。
我们还在图11中定性地演示了在细化之前和之后的渲染图。很明显,细化网络极大地提高了超采样的输出。
6. Limitation
虽然NeRF-SR在构建高分辨率神经辐射场方面表现出了其优越的性能,但它只能在预先确定的尺度下实现这一点,而不是在任意尺度上,这限制了它的实际应用。超采样为更好的视图对应带来了优势,但却以计算效率为代价。细化网络也有不足之处,因为它只能提供参考图像中已经捕获的区域的细节,尽管提供强大的先验通常需要大量的外部数据。

图8。一个花放大2的细化比较的例子。虽然PSNR在细化后从22.50dB下降到22.22dB,但看看它是如何减轻噪声点和提高视觉质量的
7、Conclusion
在本文中,我们提出了用于高分辨率的新视图合成的NeRF-SR。我们的程序的动机来自于我们对NeRF中的局部先验的观察,这包括两个方面。第一个是亚像素级的多视图一致性,它鼓励亚像素级的预测保持准确,为此,我们提出了一个超采样策略,通过亚像素级的多视图找到相应的点。其次,我们利用估计的局部深度从HR参考图像中找到相关的补丁,从中细化网络可以混合细节,产生更好的结果。NeRF-SR是第一个解决HR新视图合成问题,并在没有任何外部数据的情况下实现更逼真的渲染。
我们的工作也为未来的工作开辟了许多途径。首先,我们认为超采样策略可以扩展到区域敏感region sensitive策略,以加速训练。其次,将我们的方法扩展到一个广义版本generalized version也很有趣,它不需要额外的场景前训练additional pre-scene training来超级解析新的视图 super-resolves novel views。
我们鼓励读者观看视频,看多视图渲染。
A. Experimental Details

B、其他结果
Average Kernel
我们在图9中提供了在blender数据集上的“平均”内核之间的额外比较。很明显,对称的“平均”核比非对称的核产生更好的结果。
Additional Renderings
图10和图11显示了在blender和LLFF数据集上的其他静态结果。
C、Adversarial Training
细化过程的目标是学习参考图像的高频细节。因此,我们也考虑了使用对抗性训练[11],它已经被用于图像到图像的转换[15],图像超分辨率[50],因为它能够对齐一个分布到另一个分布。我们将NeRF视为一个生成器,并添加一个额外的补丁判别器,从生成器和参考图像中作为输入补丁,期望NeRF生成与HR参考难以区分的图像。然而,输入补丁的大小受到内存限制的限制,GAN在引入不可忽视的工件时难以提供有意义的指导。当使用NeRF进行训练时,训练一个单独的鉴别器和冻结权重的尝试也没有成功。
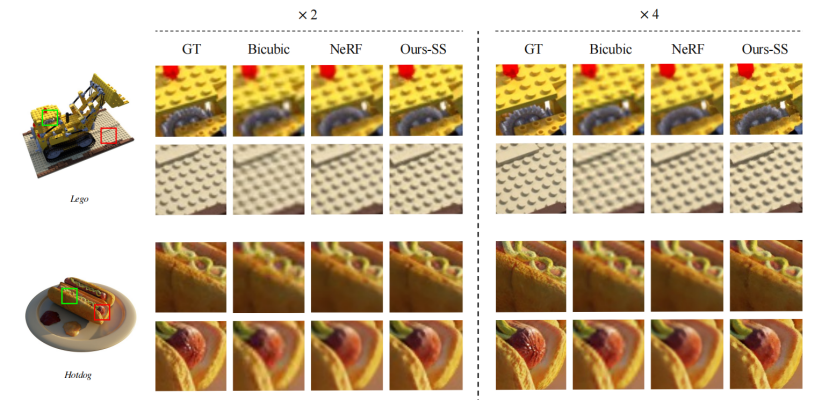

图5。当输入图像为200×200,高档比例为2和4时,对blender数据集进行定性比较。请注意NeRF-SR如何通过超级采样恢复正确的细节,即使在输入低分辨率的图像,如乐高的齿轮,热狗的香肠和酱汁,麦克风的磁铁和闪亮的支架。注意:NeRF-SR能够在不同的观点上一致地合成,这里我们提供了两个热狗,视频可以在补充材料中找到。请放大以获得更好地检查结果。



图6。双边缘、NeRF、Ours-SS和 Ours-Refine的LLFF数据集的定性比较。NeRF-SR在叶片和花的叶片和T-rex的耳朵和鼻子上的裂缝上呈现出正确和清晰的纹理,这可以利用细化网络进一步增强。请放大以获得更好地检查结果。

图9。当降尺度方法和监督信号都是“平均”(输入分辨率为100×100,upscaled by 4)时,额外的视觉结果。与非对称操作相比,对称平均降尺度和上尺度产生更详细的超分辨率新视图合成。
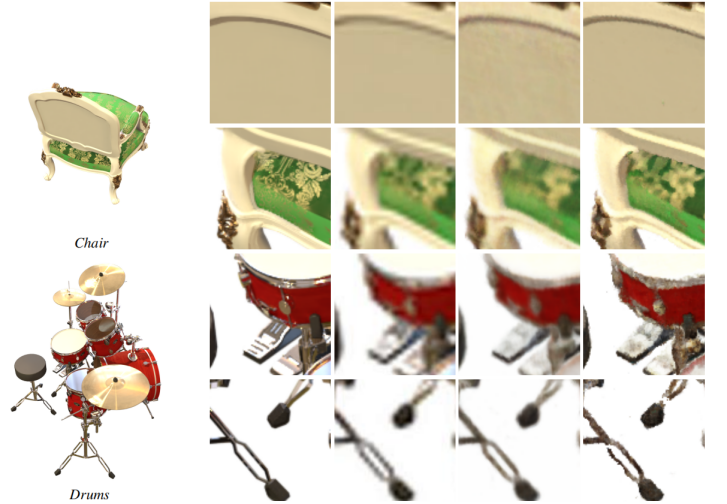



图11。LLFF数据集上的附加渲染放大4。

















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









