







 4K-NeRF提出了一种新的方法,通过视点一致性编码器和解码器来增强基于NeRF的模型对高频细节的恢复能力。方法利用视点一致性编码器捕获几何信息,并通过视点一致性解码器进行高保真细节重建。采用基于补丁的射线采样策略训练,结合对抗损失和感知损失以提升图像质量。实验在LLFF数据集上进行,展示了在高分辨率图像合成方面的优势。
4K-NeRF提出了一种新的方法,通过视点一致性编码器和解码器来增强基于NeRF的模型对高频细节的恢复能力。方法利用视点一致性编码器捕获几何信息,并通过视点一致性解码器进行高保真细节重建。采用基于补丁的射线采样策略训练,结合对抗损失和感知损失以提升图像质量。实验在LLFF数据集上进行,展示了在高分辨率图像合成方面的优势。
简介
官网:https://github.com/frozoul/4K-NeRF
基于nerf方法的渲染过程通常依赖于一种像素方式,在这种方式中,射线(或像素)在训练和推断阶段都是独立处理的,这限制了其描述微妙细节的表示能力,特别是当提升到极高分辨率时。为了更好地探索射线相关性来解决这个问题,以增强受益于几何感知局部上下文的高频细节。使用view-consistent编码器在低分辨率空间中有效地建模几何信息,并通过view-consistent解码器恢复精细细节,条件是编码器估计的射线特征和深度。
基于补丁抽样的联合训练将基于感知的正则化监督纳入到像素损失之外

方法
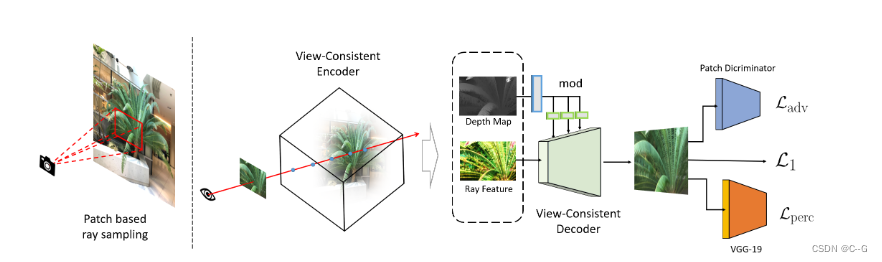
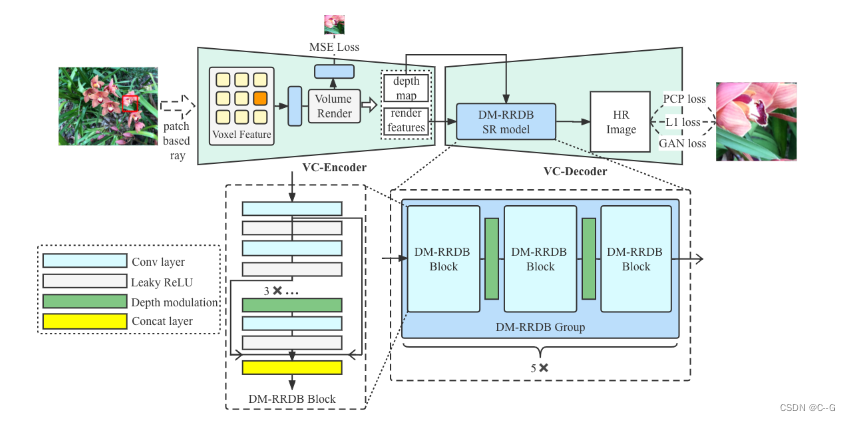
该方法旨在通过融合观察中学习到的3d感知局部特征来增强基于nerf的模型对高频细节恢复的表征能力。
View Consistent Encoder
编码器基于DVGO实现(使用体素网格搭建显示隐式结合的NeRF,其包括一个密度体素网格、一个特征体素网格),如下图。

基本表达公式如下:
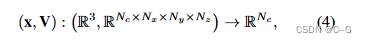
N
c
N_c
Nc为通道数(密度网格中
N
c
N_c
Nc =1),对于每个采样点,密度由配备softplus激活的三线性插值估计,公式为:σ = δ (interp (x, Vd))
颜色由特征网格的输出经过一个小MLP后得到
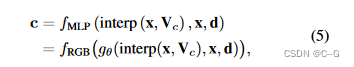
g
θ
(
⋅
)
g_θ(·)
gθ(⋅)提取颜色信息的体特征,
f
R
G
B
f_{RGB}
fRGB表示从特征到RGB图像的映射(具有一个或多个层)
论文中使用了DVGO的g(θ; x, d)部分作为VC-Encoder输出g = g(θ; x, d),其编码了视角方向为d的3D点X的体特征,然后,累加沿着射线r的采样点的特征来得到每条射线(或像素)的描述子
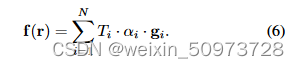
假设空间维度为H ’ ×W ',形成的特征图
F
e
n
∈
R
C
′
×
H
′
×
W
′
F_{en}∈R^{C ' ×H ' ×W '}
Fen∈RC′×H′×W′输入VC-Decoder进行精细细节的高保真重构。
View Consistent Decoder
为了更好使用vc -编码器中嵌入的几何属性,引入了深度图
M
∈
R
H
′
×
W
′
M \in R^{H' \times W'}
M∈RH′×W′
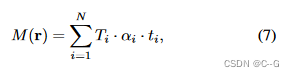
t
i
t_i
ti表示采样点 i 到相机中心的距离,估计的深度图为理解场景的3D结构提供了有力的指导
VC-Decoder使用特征图 F e n ∈ R C ′ × H ′ × W ′ F_{en} \in R^{C' \times H' \times W'} Fen∈RC′×H′×W′和深度图 M ∈ R H ′ × W ′ M \in R^{H' \times W'} M∈RH′×W′,经过特制卷积上采样网络 ψ : ( F e n , M ) → P \psi:(F_{en},M) \to P ψ:(Fen,M)→P( P ∈ R 3 × H × W , H = s H ′ , W = s W ′ P \in R^{3 \times H \times W},H=sH',W=sW' P∈R3×H×W,H=sH′,W=sW′是s表示上采样尺度)得到更高空间维度输出
VC-Decoder堆叠几个卷积块(既没有非参数归一化,也没有下采样操作)与上采样操作交错构建的,不是简单地连接特征 F e n F_{en} Fen和深度图M,而是分别考虑深度信号,并通过学习的变换将其注入到每个块中,以调制块激活。
F
k
F_k
Fk表示信道维度为
C
k
C_k
Ck的中间块的激活,深度图M经过变换(如1 × 1卷积),得到具有相同信道维数
C
k
C_k
Ck的预测标度和偏置值,用于根据以下条件调制
F
k
F_k
Fk:
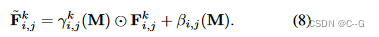
⋅
◯
\textcircled{\cdot}
⋅◯ 表示元素乘积,i j 为空间位置
Discussion
在单幅图像超分辨率重建中,融合相邻像素的局部信息是恢复高频细节的有效方法。VC-Encoder需要追求视点一致的高质量超分辨率
Training
Patch-based Ray Sampling
使用基于块的射线采样训练策略,以促进捕捉射线特征之间的空间依赖关系。
首先将图片以每块大小
N
p
×
N
p
N_p \times N_p
Np×Np划分为p块,如果图片不能刚好划分为p块,则在边缘停止划分。
Loss Functions
仅使用distortion oriented损失(如MSE、L1和Huber loss)作为目标,往往会在细节上产生模糊或过度平滑的视觉效果。为此,加入了对抗损失(adversarial loss)和感知损失(perceptual loss)来正则化精细细节合成。
对抗损失(adversarial loss):通过可学习的判别器对训练图像块计算对抗损失,旨在区分训练数据和预测数据的分布
感知损失(perceptual loss):预训练的19层VGG网络φ估计预测块
p
^
\hat{p}
p^和特征空间中的真实块p之间的相似性
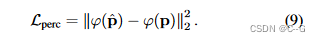
使用
L
1
L_1
L1损失代替MSE来监督高频细节的重建
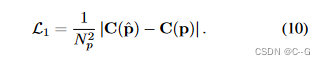
添加一个辅助的MSE损失,以促进VC-Encoder的训练,使用训练视图的降比例图像
VC-Encoder产生的光线特征被馈送到一个额外的全连接层,以回归低分辨率图像中的RGB值
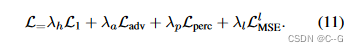
λ
h
\lambda_h
λh = 1.0
λ
a
\lambda_a
λa = 0.5,
λ
p
\lambda_p
λp = 0.02,
λ
l
\lambda_l
λl = 1.0
联合训练还可以通过深度图和射线特征的路径来辅助编码器中的3D几何建模,实现在平滑变化的视点上的高质量视图一致合成。
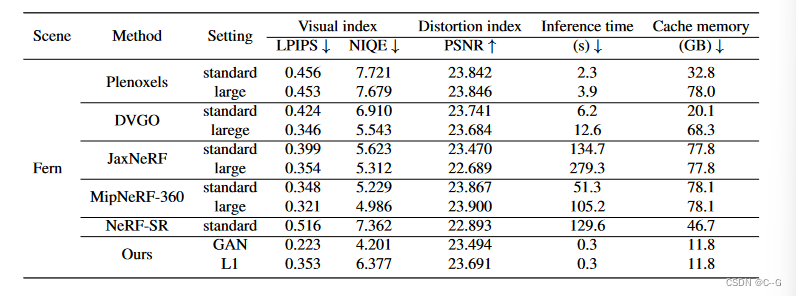
评估指标
NeRF方法将PSNR作为失真评价的默认指标,而该指标对过度平滑或模糊细节等伪影不敏感,为此加入LPIPS和NIQE指标
Datasets
实验使用LLFF数据集,原始分辨率为4032 × 3024,而现有的基于nerf的方法使用4×缩小图像(1008 × 756)进行训练和推理。在实验中,使用原始4K图像作为groundtruth进行主要实验的训练和评估。
网络结构
效果


















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









