








前言
因为图论里算法比较复杂和乱,所以整理了一下,将其放在同一个程序里,比较执行。也是新的整理和理解。
white主调
- topsort(拓扑) 出入度,degree的操作,同时要记录路径通常用queue q 系列存度,减完了就弹出
- prim(最小生成树)通过点的外加dist[i] 与 g[i][j]的比较外加最小的点,邻接矩阵列表图
- krustra算法(最小生成树)通过无向图中的引入的定理,找最短路径加入进去确定是不是连通图,用到寻根问祖里的find并查集,前提是自带比较的数据存储,所以添加了结构体里的operator 《运算符重载或者是struct cmp外加都可以。
本文模拟板子用的两种数据格式
struct E {
int a, b, w;
bool operator<(const E& temp) {
return this->w < temp.w;//重点是有序的
}
}edge[N*2];
int find(int a) {
if (p[a] != a)p[a] = find(p[a]);
return p[a];
}
void add(int a, int b, int c) {
e[idx] = b,w[idx]=c;
ne[idx] = h[a];
h[a] = idx++;
}
- Dijkstra-朴素O(n^2)
初始化距离数组, dist[1] = 0, dist[i] = inf;
for n次循环 每次循环确定一个min加入S集合中,n次之后就得出所有的最短距离
将不在S中dist_min的点->t
t->S加入最短路集合
用t更新到其他点的距离 dist[j]=min(dist[j],dist[u]+w[i]);
新路径dist j 里是由之前的 dist u 加上新的连接上i 点的线构成 - Dijkstra-堆优化O(mlogm)
利用邻接表,优先队列
在priority_queue[HTML_REMOVED], greater[HTML_REMOVED] > heap;中将返回堆顶
利用堆顶来更新其他点,并加入堆中类似宽搜 queue q, q[++tt],都可以 - Bellman_fordO(nm)
注意连锁想象需要备份, struct Edge{inta,b,c} Edge[M];,也可以用hnewe四数组模拟
初始化dist, 松弛dist[x.b] = min(dist[x.b], backup[x.a]+x.w);
松弛k次,每次访问m条边
*Floyd O(n^3)
初始化d
k, i, j 去更新d 松弛的祖师爷,它松弛程度比backup备份的bellman—ford更大,同时也很费时间,要是水题,可以用一下,共同点是 floyd和bell都用min放缩 - Spfa O(n)~O(nm)
这个算法很全面,既可以审闭环,也可以走负权值,比较全面。
queue q 的队列存数据,先让所有能到达的点入队,然后遍历st变为true;每一次的使用就是弹出,然后算外延点的dist[j]=dist[u]+w[i],还是u集合外加上 i 点边后的 dist[j]距离,同时把标记一下探索点,如果不在当前队列探索队里就加入,也许会出现之前加入过但是在遍历前被弹出,那也重新加入,这也就是解决闭环 负环 重换的情况优势。
if (dist[j] > dist[t] + w[i]) {
dist[j] = dist[t] + w[i]; //更新距离
cpa[j] = cpa[t] + 1;
//如果大于等于n,则出现自己到自己的负环情况,则终止循环,表示存在负环
if (cpa[j] >= n) return true;
if (!st[j]) { //如果不在队列中
q.push(j);
st[j] = true;
}
}
- 匈牙利算法
理解为指派任务算法,在约束任务的前提下,获取最高的执行效率。以二分图为分支的图论
匹配边所连接的点被称为匹配点。同样可以定义非匹配边和非匹配点。
如果二分图里的某一个匹配包含的边的数量,在该二分图的所有匹配中最大,那么这个匹配称为最大匹配(Maximum Matching)有机会连接,没机会创造机会也要连接。
————————————————
代码集成实现
#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10;
int dist[N], st[N], degree[N];
int h[N], ne[N], e[N], w[N],idx;
int n, m;//默认记点从0开始
int g[N][N],res;
void add(int a, int b, int c) {
e[idx] = b,w[idx]=c;
ne[idx] = h[a];
h[a] = idx++;
}
void addtopsort(int a, int b) {
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
//在topsort函数里
int q[N];
int hh = 0, tt = -1;
//模仿q和queue,存放好度数数据为0的就是已经遍历结束后入队列
void topsort() {
for (int i = 0; i < n; i++) {
if (degree[i] == 0) q[++tt] = i;
}
while (hh <= tt) {
int a = q[hh++];
for (int i = h[a]; i != -1; i = ne[i]) {
int b = e[i];
degree[b]--;
if (degree[b] == 0)q[++tt] = b;
}
}//顺便记住了拓扑序列
if (tt == n - 1)for (int i = 0; i < n; i++)cout << q[i] << " ";
else cout << -1;//不是这一个线路里的
}
//如果变成了大量访问,那么就相当于是add构建一个基本图,然后query依次减,看看能不能依靠入度走完全程
/*for(int i=0;i<k;i++){
for(int j=1;j<=n;j++){
cin>>query[j];
d[j]=degree[j];
}
if(topsort())demon[i]=1;
else demon[i]=0;
}
for(int i=0;i<k;i++)
if(!demon[i])
cout<<i<<' ';
*/
//最短路径
void dijkstra(int u) {//朴素
memset(dist, 0x3f, sizeof(dist));
dist[u] = 0;
for (int i = 0; i < n; i++) {
int t = -1;
for (int j = 1; j <=n; j++) {
if (!st[t] && (t == -1 || dist[j] < dist[t]))t = j;
}
st[t] = true;
for (int i = h[u]; i!= -1; i = ne[i]) {
int j = e[i];
dist[j] = min(dist[j], dist[t] + w[i]);
}
}
}
typedef pair<int, int> PII;
int heapdijkstra() {//堆优化之后迪杰特斯拉算法
memset(dist, 0x3f, sizeof(dist));
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>>heap;//大跟堆first是值,second是序号
//while(heap.size())都可以,反正还是要加入的
heap.push({ 0,1 });
while (!heap.empty()) {
auto t = heap.top();
heap.pop();
int u = t.second, distance = t.first;
if (st[u])continue;
st[u] = true;
for (int i = h[u]; i != -1; i = ne[i]) {
int j = e[i];
if (dist[j] > dist[u] + w[i]) {
dist[j] = dist[u] + w[i];
heap.push({ dist[j],j });
/*不论是dijkstra里的什么
理解是第 i的dist 是从1到u的距离加上外面的点i的距离变成新的dist i;
最小值,可以使用min化
dist[j]=min(dist[j],dist[u]+w[i])
或者如果堆优化就要加入队列里新的dist路径,dist[j],j
结合pII的数据结构设定,左侧距离,右侧点
*/
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
void prim()//考察的是点,同时在数据操作中也有变换,常面临的是邻接矩阵
{
memset(dist, 0x3f3f, sizeof(dist));
dist[0] = 0;
for (int i = 0; i < n; i++) {
int t = -1;
for (int j = 0; j < n; j++) {
if (!st[j] && (t == -1 || dist[j] < dist[t]))t = j;
}
st[t] = 1;
res += dist[t];
for (int i = 0; i < n; i++) {
if (dist[i] > g[t][i] && !st[i])dist[i] = g[t][i];
}
}
cout << res;
}
//krustra利用结构体
int p[N];
//并查集寻根问祖,也从侧面说明了针对的是边排序后加入最小判断=是否闭环
struct E {
int a, b, w;
bool operator<(const E& temp) {
return this->w < temp.w;//重点是有序的
}
}edge[N*2];
int find(int a) {
if (p[a] != a)p[a] = find(p[a]);
return p[a];
}
int cnt = 0;
void krustra() {
for (int i = 0; i <= m; i++) {
int pa = find(edge[i].a);
int pb = find(edge[i].b);
if (pa != pb) {
res += edge[i].w;
p[pa] = pb;
cnt++;
}
}
}
bool isperfectpic(int cnt) {
if (cnt < n - 1) {//如果保留的边小于点数-1,则不能连通
cout << "impossible";
}
}
int backup[N];//为了数组的稳定性
void bellman_ford() {
memset(dist, 0x3f, sizeof(dist));
dist[1] = 0;
for (int i = 0; i < n; i++) {
memcpy(backup, dist, sizeof dist);
int flag = 0;
for (int j = 0; j < m; j++) {
int a = e[j], b = ne[a];//eg :边从a-b
dist[b] = min(dist[b], backup[a] + w[a]);
}
/*Bellman - ford 算法是求含负权图的单源最短路径的一种算法,效率较低,代码难度较小。
其原理为连续进行松弛,在每次松弛时把每条边都更新一下,若在 n - 1 次松弛后还能更新,
则说明图中有负环,因此无法得出结果,否则就完成。找每一步的最短距离*/
}
}
//松弛的祖师爷,矩阵列表g来确定dist.可以理解成dp
void floyd() {
for (int k = 1; k <= n; k++) {
for (int i = 1; i < n; i++) {
for (int j = 1; j <= n; j++) {
g[i][j] = min(g[i][j], g[i][k] + g[k][j]);
}
}
}
}
//可以用q数组存队列,也可以直接queue<int> q;
void spfa() {
q[++tt] = 1;
dist[1] = 0;
st[1] = 1;//找起点,或者默认1也行
while (hh <= tt) {
int a = q[hh++];
st[a] = false;
for (int i = h[a]; i != -1; i = ne[i]) {
int j = e[i];
if (dist[j] > dist[a] + w[i]) {
dist[j] = dist[a] + w[i];
if (!st[j]) {
q[++tt] = j;
st[j] = 1;//spfa反复入队
}
}
}
}
}
int cpa[N];//计算环
int spfaque() {
queue<int> q;
for (int i = 1; i <= n; i++) {
st[i] = true;
q.push(i);
}
while (q.size()) {
int t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i]) {
int j = e[i];
if (dist[j] > dist[t] + w[i]) {
dist[j] = dist[t] + w[i]; //更新距离
cpa[j] = cpa[t] + 1;
//如果大于等于n,则出现自己到自己的负环情况,则终止循环,表示存在负环
if (cpa[j] >= n) return true;
if (!st[j]) { //如果不在队列中
q.push(j);
st[j] = true;
}
}
}
}
}
int main(){
scanf("%d %d", &n, &m);
memset(st, 0, sizeof(st));
memset(h, -1, sizeof(h));
memset(g, 0x3f, sizeof(g));
for (int i = 0; i < m; i++) {
int a, b, c;
scanf("%d %d %d", &a, &b, &c);
add(a, b, c);
addtopsort(a, b);
g[a][b] = c;
degree[b]++;
edge[i] = { a,b,c };//结构的加入
}
sort(edge + 1, edge + m + 1);
krustra(); isperfectpic(cnt);//同样可以运用于topsort和最小生成单支树,也可以求res
topsort();//是否是完整图
prim();//求最小生成树,res,返回前序结点,周游的路径
int u;//以某点为起点的遍历,更有应用实践性
dijkstra(u);
heapdijkstra();//多快好省
bellman_ford();
floyd();
spfa();//spfaque同理,可以用queue看着更舒服
//解决负权值的问题,性价比比较高,价值等同于堆优化的dij
//可以理解成松弛的用min,其他的都比较一下好用于数据的其他操作
}
下面讲一道融合上面所以算法思路和代码的应用题,也许有点烧脑,但也是将知识点融合的好题
判断有无向图,有无正负权值,连通图,find并查集 dijkstra
航路与道路
农夫约翰正在一个新的销售区域对他的牛奶销售方案进行调查。他想把牛奶送到 T 个城镇,编号为 1∼T。
这些城镇之间通过 R 条道路 (编号为 1 到 R) 和 P 条航线 (编号为 1 到 P) 连接。
每条道路 i 或者航线 i 连接城镇 Ai 到 Bi,花费为 Ci。
对于道路,0≤Ci≤10,000;然而航线的花费很神奇,花费 Ci 可能是负数(−10,000≤Ci≤10,000)。
道路是双向的,可以从 Ai 到 Bi,也可以从 Bi 到 Ai,花费都是 Ci。
然而航线与之不同,只可以从 Ai 到 Bi。
事实上,由于最近恐怖主义太嚣张,为了社会和谐,出台了一些政策:保证如果有一条航线可以从 Ai 到 Bi,那么保证不可能通过一些道路和航线从 Bi 回到 Ai。
由于约翰的奶牛世界公认十分给力,他需要运送奶牛到每一个城镇。
他想找到从发送中心城镇 S 把奶牛送到每个城镇的最便宜的方案。

下图重点解释,如何将道路和航路的两种复合图连通在一起,并进spfa()算法可以算的同时
也可以用通过topsort 并查集 dijkstra实现的方法,第二种方法更好理解,也是主流思想,不会拘束与数据问题
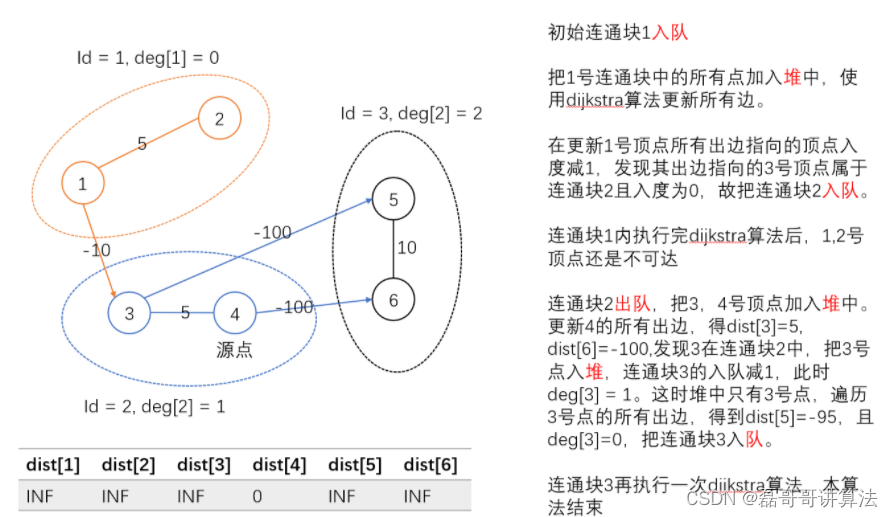
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+10;
int dist[N];
typedef pair<int,int> PII;
bool st[N];
int n,mr,mh,s,e[N],h[N],ne[N],idx,w[N];
int id[N],deg[N],bcnt;
int q[N],hh,tt=-1;
vector<int> block[N];
void add(int a,int b,int c){
e[idx]=b,w[idx]=c;
ne[idx]=h[a];
h[a]=idx++;
}
void dijkstra(int block_id){
priority_queue<PII,vector<PII>,greater<PII>>heap;
for(int u:block[block_id]){
heap.push({dist[u],u});
}
while(heap.size()){
PII t=heap.top();
heap.pop();
int u=t.second;
if(st[u])continue;
st[u]=true;
for(int i=h[u];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>dist[u]+w[i]){
dist[j]=dist[u]+w[i];
if(id[j]==block_id)heap.push({dist[j],j});
}
if(id[j]!=block_id&&--deg[id[j]]==0)q[++tt]=id[j];
}
}
}
void dfs(int u){
lock[bcnt].push_back(u);
id[u]=bcnt;
for(int i=h[u];i!=-1;i=ne[i]){
int j=e[i];
if(!id[j])dfs(j);
}//找链接
}
void topsort(){
memset(dist,0x3f,sizeof(dist));
dist[s]=0;
for(int i=1;i<=bcnt;i++){
if(!deg[i])q[++tt]=i;
}
while(hh<=tt){
int t=q[hh++];
dijkstra(t);
}
}
int main(){
memset(h,-1,sizeof(h));
scanf("%d %d %d %d",&n,&mr,&mh,&s);
for(int i=0;i<mr;i++){
int a,b,c;
scanf("%d %d %d",&a,&b,&c);
add(a,b,c),add(b,a,c);
}
for(int i=1;i<=n;i++){
if(!id[i]){
++bcnt;
dfs(i);
}
}
for(int i=0;i<mh;i++){
int a,b,c;
scanf("%d %d %d",&a,&b,&c);
add(a,b,c),deg[id[b]]++;
}
topsort();
for(int i = 1; i <= n; i++)
{
if(dist[i] > 0x3f3f3f3f / 2) puts("NO PATH");
else printf("%d\n", dist[i]);
}
return 0;
}
AOE图与AOV图
工序代号是弧线,事件是点集合
事件是v点
- 在一个有向图中,顶点表示事件,有向边表示活动,边上的权值表示活动的持续时间。
- 关键路径:活动的持续时间又称为路径长度,把源点到终点的具有最大长度的路径叫为关键路径。
- 关键路径又可以理解为同一个层次的事件,所占用的最大时间,那么关键路径必然经过这个事件。
- 活动的最晚开始时间和最晚开始时间相等,那么该活动就是关键活动,活动的路径就是关键路径
前提是拓扑排序是正序,逆序拓扑顺序是倒着来,执行是安排的倒着往前推。
etv:事件最早发生时间max正拓扑
ltv:事件最晚发生时间,etv和ltv 的时间安排是首尾一致min逆拓扑
ete:活动最早开始时间弧尾max
lte:活动最晚开始时间,时间-线权
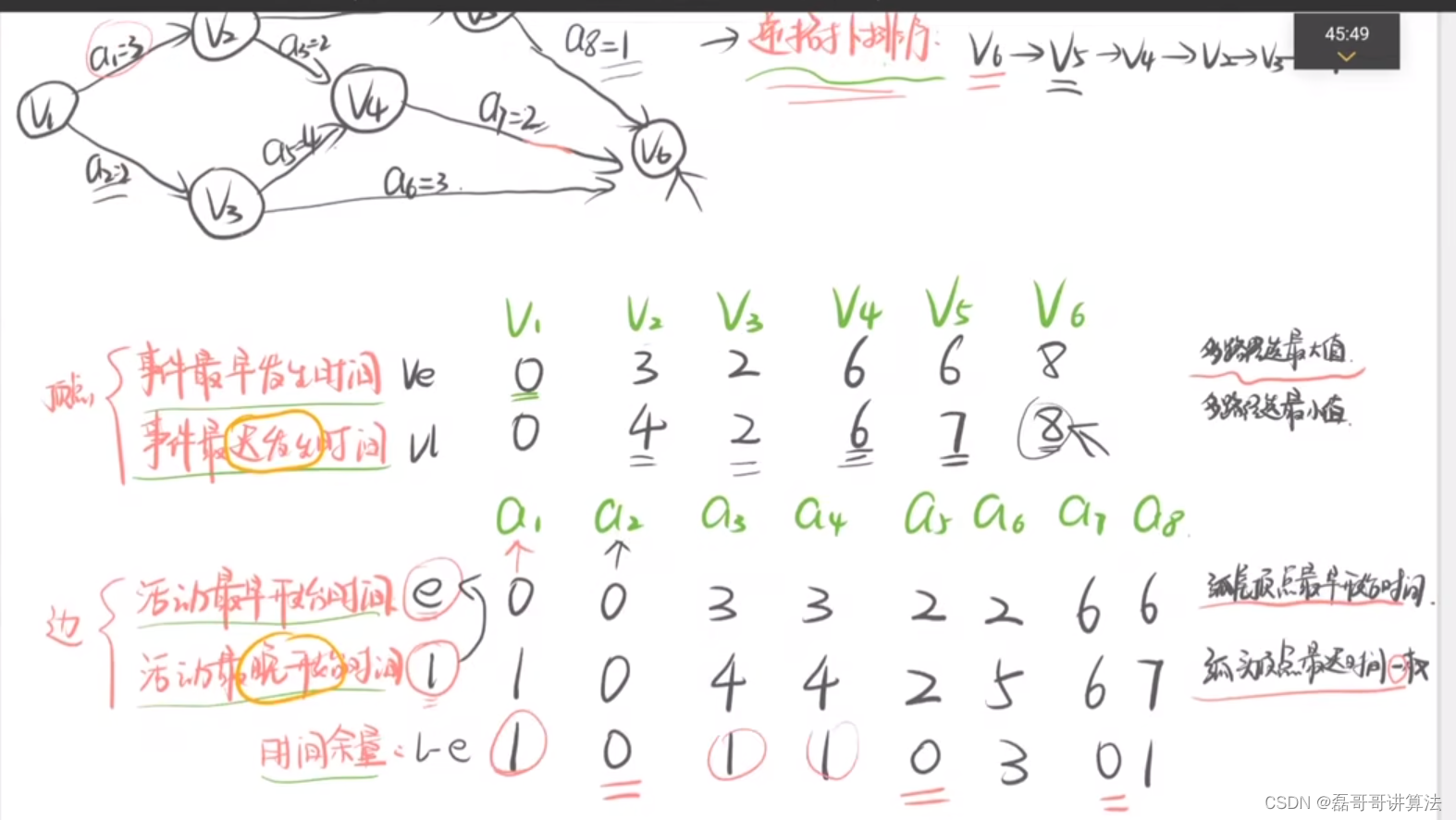
-
是求该事件最早发生的时间,实际上就是求之前路径的最大权值之和。因为只有所有事件都发生了,下面一个事件才能开始发生,也就是事件的最早开始时间
-
ltv是求事件最晚发生时间,就是只要那个大事件还未结束,它在它本身的边权值上时间之前发生即可,是倒着推时间减去对应的边权值
活动是弧线
关键活动是按照时间余量作差后相等就是关键事件
-
活动的最晚发生时间lte:就是在该事件最晚发生,减去该边的持续时间,就是事件最迟时间按照拓扑排序的顺序减去连接弧线的时间。操作的是弧首。
-
活动最早发生时间:就是该事件最早发生时。也就是正序拓扑的弧尾结点所需要的时间
-
当活动最早发生时间和活动最晚发生时间相等时,该活动所在的弧就是关键路径。
-
当活动最早发生时间和活动最晚发生时间相等时,该活动所在的弧就是关键路径。
#include<iostream>
using namespace std;
#define MAX 25
typedef char Vertype;
typedef int Edgetype;
typedef int Status;
//构造图的有向图的邻接表结构体
typedef struct EdgeNode//边表结点 存放每个顶点的邻接点
{
int adjvex;//边表下标
Edgetype weight;//边表权重 若边不存在时即无NULL
struct EdgeNode* next;//指向下一个邻接点
}EdgeNode;
typedef struct VerNode//顶点表 存放顶点
{
int in;
Vertype data;//顶点元素
EdgeNode* firstedge;
}VerNode, AdjList[MAX];//邻接表的 顶点元素 和指向邻点的指针
typedef struct
{
AdjList adjList;//邻接表
int numVer, numEdge;//顶点数目和边的数目
}GraphAdjList;
//构造两个栈
typedef struct Stack
{
int data[MAX];
//int pop;
}SqStack;
//生成邻接表
Status CreatGraph(GraphAdjList& G)
{
int i, j, k;
Edgetype w;
EdgeNode* e;
cout << "Enter the number of vertices :" << endl;
cin >> G.numVer;
cout << "Enter the number of Edges :" << endl;
cin >> G.numEdge;
cout << "Input vertex content :" << endl;
for (i = 0; i < G.numVer; i++)
{
cin >> G.adjList[i].data;//输入顶点元素
G.adjList[i].in = 0;
G.adjList[i].firstedge = NULL;//初始化邻边表为NULL;
}
for (k = 0; k < G.numEdge; k++)
{
cout << "Enter the vertex number of the edge (Vi->Vj)" << endl;
cin >> i;
cin >> j;
cout << "Enter the weight of edge" << i << "-" << j << endl;
cin >> w;
e = new EdgeNode;//将两个顶点相结即可。
e->adjvex = j;// 邻接序号为j
e->next = G.adjList[i].firstedge;//i的第一个邻接指针 为e的指针
e->weight = w;
G.adjList[i].firstedge = e;
G.adjList[j].in++;
//有向图则只有生成一次即可
/*
e = new EdgeNode;
e->adjvex = i;//无向图 重复一遍
e->next = G.adjList[j].firstedge;
G.adjList[j].firstedge = e;
e->weight = w;*/
}
return 0;
}
SqStack* etv, * stack2;
SqStack* ltv;/*事件最晚发生时间*/
int top2;
//拓扑排序
Status TOpologicalSort(GraphAdjList& G)
{
EdgeNode* e;
//SqStack Q;
int i, j, k, gettop;
int top = 0;
int count = 0;
SqStack* Q;
Q = new SqStack;
for (i = 0; i < G.numVer; i++)
{
if (G.adjList[i].in == 0)
Q->data[++top] = i;//存放入度为0的顶点
}
top2 = 0;/*初始化 事件最早发生的时间为0*/
//SqStack *etv,*stack2;
etv = new SqStack;
for (i = 0; i < G.numVer; i++)
{
etv->data[i] = 0;
}
stack2 = new SqStack;
while (top != 0)
{
gettop = Q->data[top--];//弹出入度为0的下标
stack2->data[++top2] = gettop;//按照拓扑顺序保存弹出顶点下标
count++;//统计拓扑网顶点数目
//后面输出其边顶点
//并删除边,使得边顶点入度-1
for (e = G.adjList[gettop].firstedge; e; e = e->next)
{
j = e->adjvex;
if (!(--G.adjList[j].in))//如果入度为1时 自减后进入循环 如果入度不为1,自减后 相当于边的数目减1
{
Q->data[++top] = j;//保存后续入度为0的顶点
}
/**/
if ((etv->data[gettop] + e->weight) > etv->data[j])
{
etv->data[j] = etv->data[gettop] + e->weight;//保存权值 etv初始化都为0,
}
}
}
if (count < G.numVer)
{
cout << "不是一个网图" << endl;
return 1;
}
else
{
cout << "是一个网图" << endl;
return 0;
}
//return 0;
}
Status CriticalPath(GraphAdjList& G)
{
EdgeNode* e;
int i, j, k, gettop;
int ete, lte;/*活动最早发生时间ele 活动最迟发生时间lte*/
ltv = new SqStack;
/*初始化ltv*/
for (i = 0; i < G.numVer; i++)
{
ltv->data[i] = etv->data[G.numVer - 1];
}
while (top2 != 0)
{
gettop = stack2->data[top2--];
for (e = G.adjList[gettop].firstedge; e; e = e->next)
{
k = e->adjvex;
if (ltv->data[k] - e->weight < ltv->data[gettop])
{
ltv->data[gettop] = ltv->data[k] - e->weight;
}
}
}
for (j = 0; j < G.numVer; j++)
{
for (e = G.adjList[j].firstedge; e; e = e->next)
{
k = e->adjvex;
ete = etv->data[j];
lte = ltv->data[k] - e->weight;
if (ete == lte)
{
cout << G.adjList[j].data << G.adjList[k].data << e->weight << endl;
}
}
}
return 0;
}
int main()
{
GraphAdjList G;
CreatGraph(G);
TOpologicalSort(G);
CriticalPath(G);
system("pause");
return 0;
}
















 5291
5291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











