










torch模块实现与源码详解 深度学习 Pytorch笔记 B站刘二大人 深度学习 Pytorch笔记 B站刘二大人(4/10)
介绍
至此开始,深度学习模型构建的预备知识已经完全准备完毕。
从本章开始就开始按照实际研究与开发中的流程进行深度学习模型的构建。
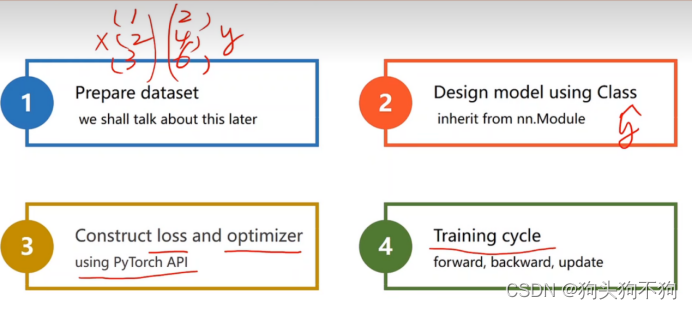
实现步骤:
- 准备数据集
- 设计深度学习模型,计算y_hat
- 用pytorch封装功能实现loss函数和 优化函数
- 进行顺序训练循环,前馈,反馈,更新
在构建的过程中同样需要注意,使用tensor数据类型,使用mini-batch形式:一次性求出多种样本的输出结果。
并运算思维转换为矩阵运算,在进行数据输入时要使用两个中括号

完成了数据的设置后,需要求解出权重w的关于损失函数loss的梯度解析式
大型项目通常使用pytorch封装好的模块,在计算过程中将自动生成运算图。
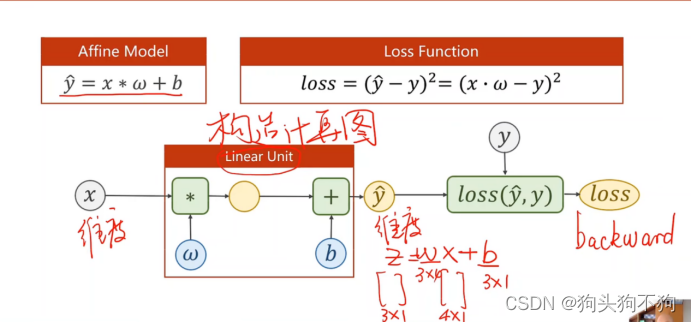
下图是一个最简单仿射模型,是一个基础线性单元:其数学表达式为
预测值y_hat = 权重w* 输入数据 x +偏置量b
当输出和输出维度不同时,例如下图输入x是41的向量,而输出是31的向量,按照矩阵乘法的运算规则,权重参数w应当是一个3*4的数值矩阵
基本模型类

上图是构建的运算模型,从torch中的深度学习模型类module进行继承,并通过魔法方法super进行重写,设置模型中仅有一个单输入单输出的线性层。使用该方法的好处是从moudel进行继承可以自动构造反向传播函数。
之后定义向前函数forward,记得要在原始函数后再加上形参x
完成模型构建后进行实例化:model = LinearModel()
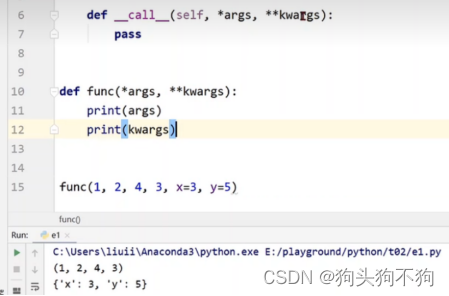
额外的python编程技巧
Python编程技巧,在定义对象可调用函数__call__()是,形参定义为*args和 *kwargs,其中args将输入的未命名的参数自动形成元组,kwargs将传递参数组成词典

对指向索引
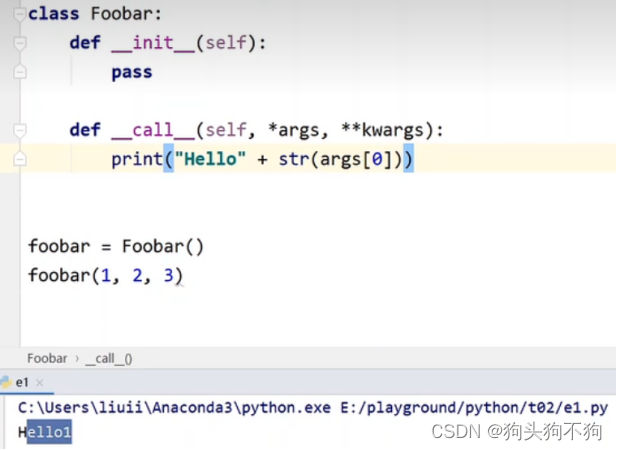
代码解读与实现
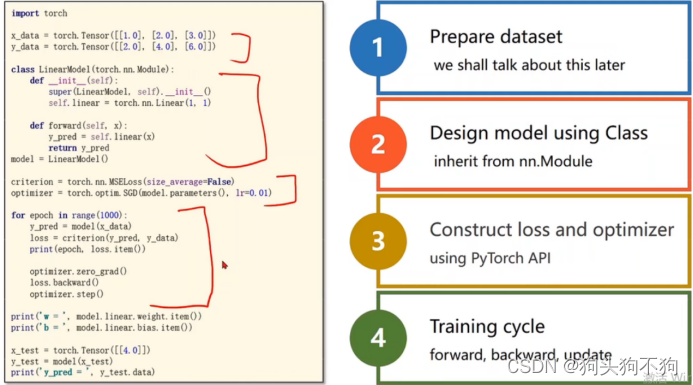
模板计算步骤:
1.计算y_hat
2.计算损失loss 2.5 之前的梯度清零
3. backward()计算累积梯度
4. update更新
"""
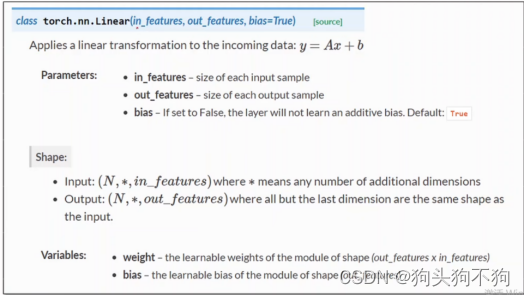
our model class should be inherit from nn.Module, which is base class for all neural network modules.
member methods __init__() and forward() have to be implemented
class nn.linear contain two member Tensors: weight and bias
class nn.Linear has implemented the magic method __call__(),which enable the instance of the class can
be called just like a function.Normally the forward() will be called
我们模型类应该继承自nn.Module,它是所有神经网络模块的基类。
必须实现成员方法__init__()和forward()
class nn.linear包含两个成员张量:权重和偏差
class nn.linear实现了魔法方法__call__(),这使得类的实例可以
就像函数一样被调用。通常会调用forward()
"""
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]]) # 第一个[]为将三个输入组合为一组输入向量,第二个[]将数据标志为Tensor数据类型
y_data = torch.Tensor([[2.0], [4.0], [6.0]]) # 同样第一个[]将输出组合为向量,第二个[]将数据标志为Tensor数据类型
class LinearModel(torch.nn.Module): # 定义类,从torch.nn.Module 继承
def __init__(self): # 魔法方法定义构造函数
super(LinearModel, self).__init__() # super继承父类的init函数
self.linear = torch.nn.Linear(1, 1) # 定义输入输出个数
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel() # 将定义的网络模型类实例化
criterion = torch.nn.MSELoss(size_average=False) # 通过MSE(交叉熵)计算损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 通过SGD方法(随机梯度下降法)进行动态更新优化
for epoch in range(150):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss)
optimizer.zero_grad() # 将上一次的梯度清零,释放内存
loss.backward() # 反向获取损失梯度
optimizer.step() # 根据损失梯度更新模型参数,进行性能优化
# Output weight and bias
print('w =', model.linear.weight.item())
print('b =', model.linear.bias.item())
# Test Model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred =', y_test.item())
作业
使用如下优化器尝试模型效果

















 2106
2106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











