






介绍
SAM(Segment Anything Model)是一个用于图像分割任务的深度学习模型,由Meta的研究者提出。SAM模型旨在提供一个通用的、交互式的图像分割工具,它能够根据用户提供的简单交互式提示(prompts)来分割图像中的任意对象。
SAM模型在图像分割领域提供了一种新的交互方式,它降低了用户参与的门槛,使得没有专业知识的用户也能够进行图像分割任务。此外,它的交互式特性也使得它在某些应用场景下比全自动的分割模型更加灵活和准确。
Segment Anything Model 的目标是生成高质量的对象遮罩(masks),这些遮罩可以通过输入提示(如点或框)从图像中生成。它旨在为图像中的所有对象生成遮罩,具有强大的零样本(zero-shot)性能,能够处理各种图像分割任务
特点
高质量遮罩生成: SAM能够从简单的输入提示生成精确的对象遮罩。
零样本性能: 即使没有针对特定任务的训练,SAM也能在多种分割任务上表现出色。
大规模数据集训练 :SAM在1100万个图像和11亿个遮罩的数据集上进行了训练
支持的不同模式
基于提示的分割: SAM可以根据用户给出的点或框等提示生成特定对象的遮罩。
自动遮罩生成: SAM还可以自动为整个图像生成遮罩。
编程架构
Python:主要的编程语言,用于实现模型和相关工具。
PyTorch:用于深度学习模型的构建和训练。
TorchVision:用于图像处理和转换。
用途扩展
ONNX导出:SAM的轻量级遮罩解码器可以导出为ONNX格式,以便在任何支持ONNX运行时的环境中运行,例如在浏览器中。
Web演示:提供了一个简单的React应用程序,展示了如何在Web浏览器中使用导出的ONNX模型进行遮罩预测。
模型检查点:提供了不同后端大小的三个模型版本。
数据集:提供了数据集的概述和下载链接,以及如何加载和解码遮罩数据的说明
项目网站

线上demo
在线测试网址
和项目一样,线上测试网站同样有两种使用方法,全图分割和主动选择
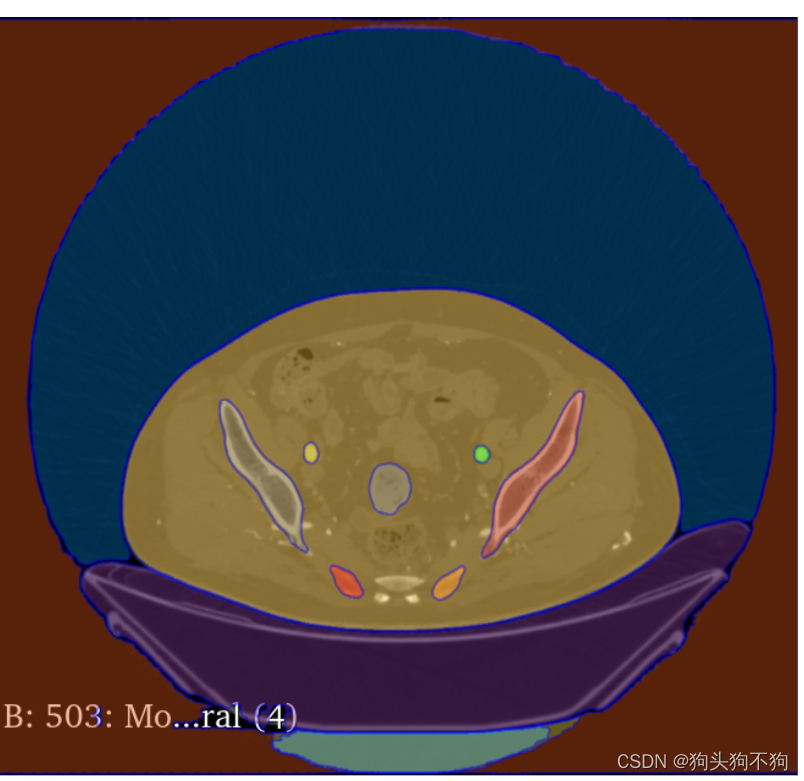
除了网站提供的图像之外,还支持自己上传图像,以人体的CT扫描图像为例

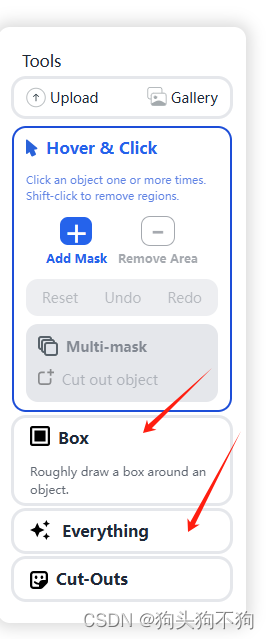
左侧选择栏给了三种模式,点击,框选,和整图分割
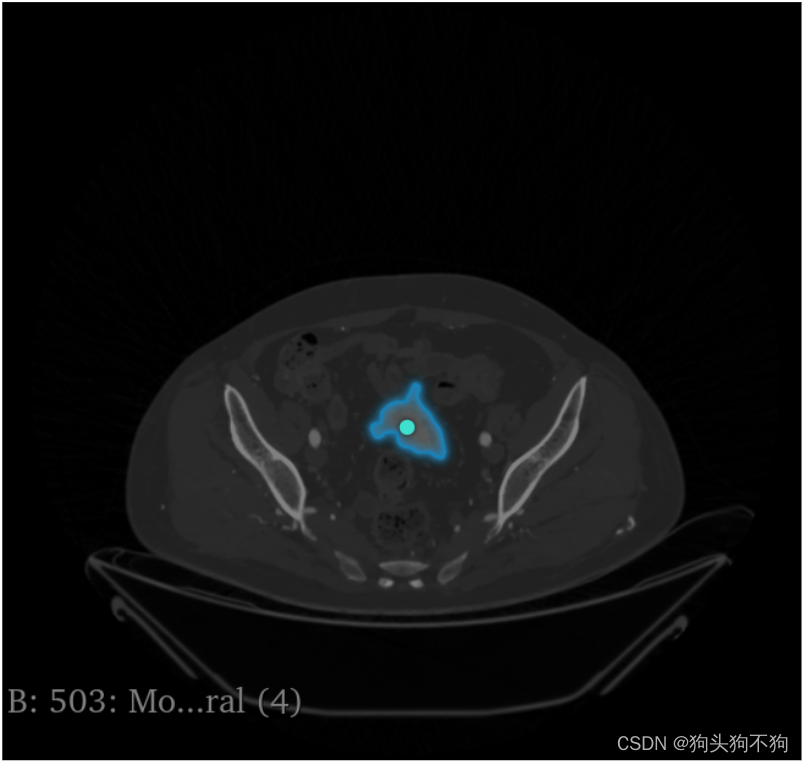
点击:
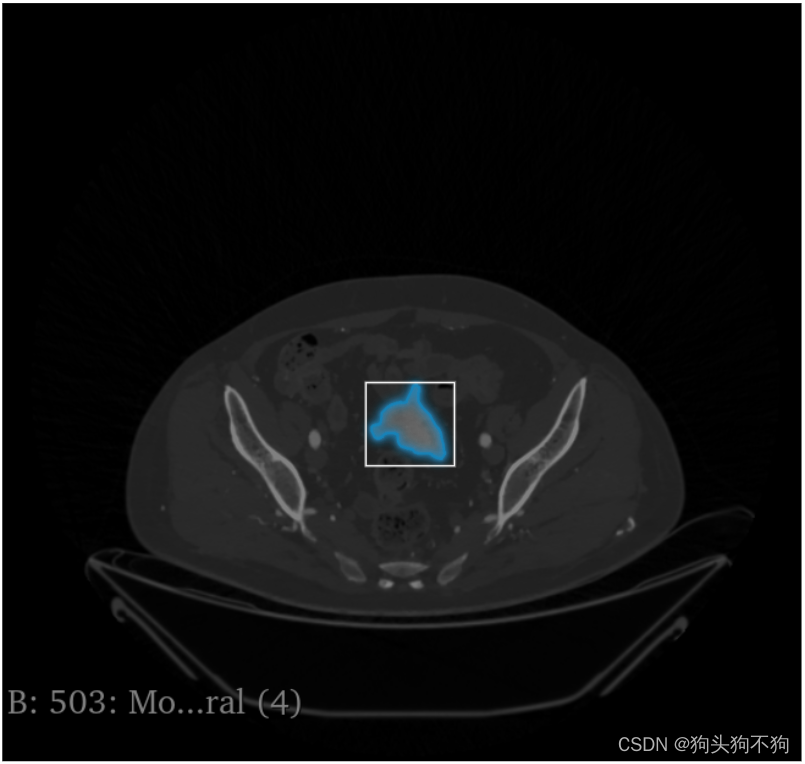
框选:
整图分割
下载
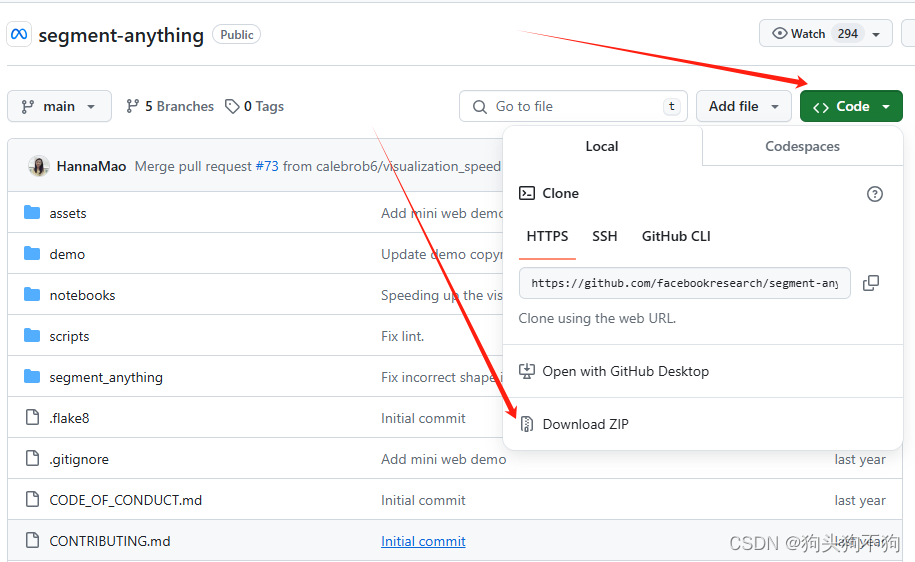
不过我个人还是建议用Ubuntu新建一个conda环境通过git进行下载
最大的好处是在后续的一系列使用中可以使用import segment_anything从而进行一系列的处理开发,环境配置和ubunut下的一系列开发在下一篇
都看到这了,点个赞再走吧彦祖


















 8891
8891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











