







 这篇文章介绍了美洲狮优化器(PumaOptimizer),一种模仿美洲狮觅食行为的新型元启发式算法。文章详细阐述了算法的不同阶段,包括无经验阶段的探索和开发,以及有经验阶段的优先级选择。性能测评显示PO在标准函数上表现出色。
这篇文章介绍了美洲狮优化器(PumaOptimizer),一种模仿美洲狮觅食行为的新型元启发式算法。文章详细阐述了算法的不同阶段,包括无经验阶段的探索和开发,以及有经验阶段的优先级选择。性能测评显示PO在标准函数上表现出色。
目录
美洲狮优化器(Puma Optimizer, PO)是一种新型的元启发式算法(智能优化算法),灵感来自美洲狮的智慧和生命。该成果由Abdollahzadeh等人于2024年1月发表在SCI期刊Cluster Computing上。

由于发表时间较短,谷歌学术上还无人引用!你先用,你就是创新!
原理简介
美洲狮是原产于美洲大陆的小型猫科动物亚科中的一种大型猫科动物这种动物的栖息地从南美洲的安第斯山脉到加拿大的育空地区。它是美洲仅次于美洲豹的最大猫科动物,也是一种适应性很强的动物,生活在不同的栖息地,以其他猎物为食。它主要是夜间活动,但可以在白天看到。
美洲狮是非常聪明的动物,有很好的记忆力。为了狩猎,他们经常去更有可能狩猎的地方,这是基于他们以前的经历。这些有针对性的狩猎之旅可以是他以前狩猎和隐藏猎物的地方。或者去一个他在前几个阶段没有狩猎过的新地方。在本文中,我们考虑了美洲狮前往以前有希望的地方的开发阶段和前往新地区的勘探阶段。为了改变阶段,受到pumas的智能和记忆以及首次提出的一种新的智能机制的启发,它可以被认为是一种先进的元启发式算法。

一、无经验阶段
美洲狮在其早期生活中没有太多经验,由于对其生活空间不熟悉,也不知道狩猎活动在其领土上的位置,因此经常同时进行勘探作业。另一方面,它在有利的地区狩猎。在Puma算法中,在前三次迭代中,同时执行探索操作和开发操作,直到在相变阶段完成初始化。在本节中,由于在每次迭代中都选择了一对开发和勘探阶段,因此只使用了两个函数(f1和f2),这两个函数是用等式(1-4)计算的:
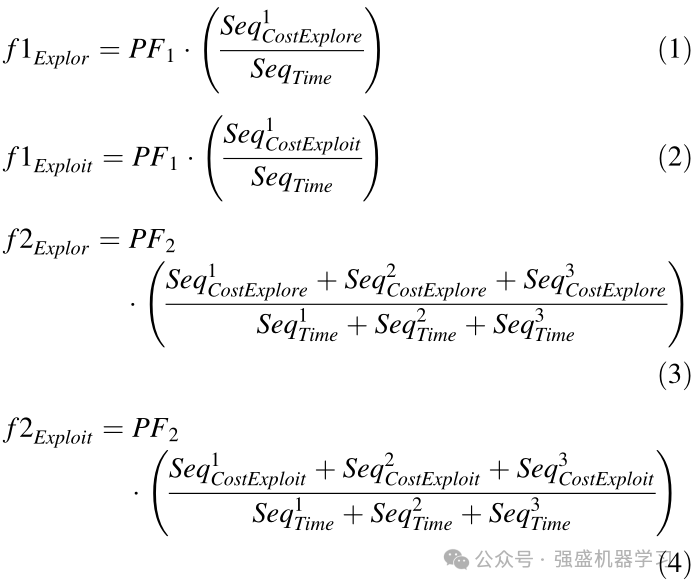
SeqCost的可变值与开采和勘探的每个阶段有关,由等式(1-4)计算。SeqTime也是一个常数值的变量,我们认为它是1。PF1和PF2都是具有固定值的参数,这些参数必须在优化过程之前设置,用于对f1和f2函数中的每一个进行优先级排序。

在等式(5和8)中,CostInitialBest initial是在初始化阶段产生的第一速率解决方案的成本,六个变量Cost1Explore、Cost2Explore,Cost3Explore和Cost1Exploit,Cost2Exploit、Cost3Exploit和Cost3Eexploit从开发和勘探的每个阶段获得的最佳解决方案的每个成本都是重复1、2和3。在第三次迭代结束时计算函数f1和f2之后,从现在起只选择勘探和开发阶段中的一个。因为其他美洲狮有着令人愉快的体验,所以要从两个阶段中选择一个阶段,开采和勘探阶段的两个点是使用等式11和12计算的。
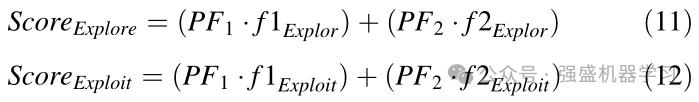
在计算ScoreExplore和ScoreExploit后,使用等式(11和12)进入勘探和开发的一个阶段,如果ScoreExploite大于等于ScoreExplore,则进入开发阶段,否则进入探索步骤,但关键的一点是,在第三次迭代结束时,每个步骤都会找到独立产生的解决方案,这比总种群数还要多。为了解决这个问题,在第三次迭代的最后一次计算两个阶段生成的解决方案的总成本,并且只有生成的整套解决方案中的最佳解决方案才等于替换当前解决方案的整个群体。
二、有经验阶段
经过三代之后,美洲狮有了可接受的经验来决定改变阶段,在迭代的继续中,他们只选择一个阶段进行优化操作。在这个阶段,使用三个不同的函数f1、f2和f3进行评分。第一个功能强调升级部分,并导致勘探和开发的两个阶段中的一个阶段的优先顺序,这两个阶段的选择和执行都比其他阶段更好。第一个功能更加强调勘探阶段。第一个函数是使用等式(1)计算的。
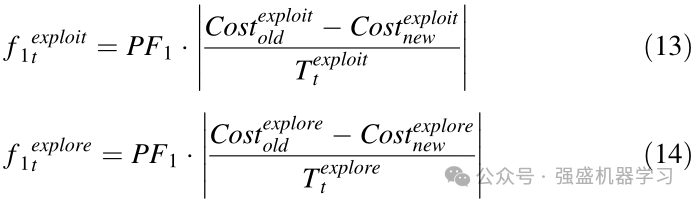
在等式(13和14)中,f 1exploitt和f 1exploret表示基于探索阶段或开发阶段的第一个函数的量,其中t表示当前迭代次数。CostexploreOld和CostexploreNew是当前选择中改进之前的最佳解决方案的成本。另一方面,Costexplorenew和CostexploreNew是改进当前选择后获得的最佳解决方案的成本。Texploret和Texploitt是从上一个选择到当前选择的未选择迭代次数。PF1是一个用户可调整的参数,在进行优化操作之前,必须将其设置为0到1之间的值。此参数决定第一个函数的重要性。并且它随着该函数的值的增加而被优先化,并且随着其优先级的降低而减小。第二个函数还强调谐振分量,并导致相位比其他优先相位表现得更好。良好的性能按顺序进行检查和测量。因此,该功能可以帮助开发阶段对其进行选择。使用等式(15和16)计算第二个函数。
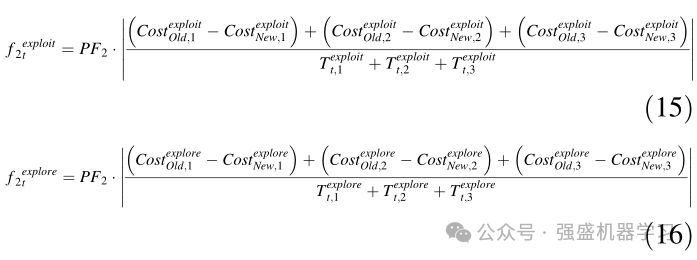
在等式(15和16)中,f2exploitt和f2exploit表示与勘探阶段或开采步骤相关的第二个函数,其中t表示当前迭代次数。Costexplore-old1和Costexploit-old1是当前勘探和开发阶段选择中改进前最佳解决方案的成本;Costexplore-old2和Costexploit-old2是先前勘探和开发步骤选择中改进之前最佳解决方案;Costexploit-old3的和Costexplore-New3是在勘探和开采阶段的前两个选择中改进之前的最佳美洲狮的成本。Costexploit-New1和Costexplore-New1是在勘探和开采阶段的当前选择中改进后获得的最佳解决方案的成本;Costexploit-New2和Costexplore-New2是在开发和勘探阶段的先前选择中改进后获得的最佳搜索代理的成本;Costexploit-New3和Costexplore-New3是在勘探和开采阶段的前两个选择中改进后获得的最佳解决方案的成本。Texploret1和Texploitt1是在勘探和开采阶段中的每一个阶段中从先前选择到当前选择的未选择迭代的次数;Texploitt2和Texploret2是用于勘探和开发阶段的从两个先前选择到一个先前选择的未选择迭代的次数,并且Texploitt3和Texploret3是用于开采和勘探阶段的从三个先前选择到两个先前选择的未选择迭代的次数。PF2是一个参数,在进行优化操作之前,必须将其设置为0到1之间的值。
选择机制中的第三个函数强调多样性成分,使许多重复中未被选择的阶段也有机会被选择,因为一个相位的选择导致崩溃到局部最优陷阱中。该函数如等式17和18所示:

在等式(17和18)中,f3exploret和f3exploitt表示与开发阶段或勘探阶段相关的第三个函数,其中t表示当前迭代次数。根据等式(3),如果未选择其中一个阶段,则开采和勘探的每个阶段的第三个函数的值将在每次迭代中增加参数PF3;否则,它将被设置为零。PF3参数是用户可调整的参数,在进行优化操作之前,必须将其设置为0到1之间的值。PF3参数的值越接近1,得分低的阶段被选择的机会越高,并且选择的机会随着值的减小而减小。使用等式(19和20),计算相变函数的成本:

使用等式(19和20),计算每个开采和勘探阶段的最终成本。勘探和开采阶段的参数a和d分别根据从每个阶段获得的结果,在搜索操作期间的变量。多样性优先;否则,减少优先级分集分量,并且如果参数a的值接近1,则优先考虑谐振分量。根据等式(22),如果勘探阶段函数的成本大于开采函数,则开采函数的参数a的值将以0.01的值线性惩罚,另一方面,开采阶段的参数a值将具有接近1的最大值。但是,如果开采阶段函数的成本高于勘探函数,则上述过程将相反。lc是一组从开采和勘探阶段获得的改进计算成本差异,包括一组除零以外的值。
三、勘探阶段
美洲狮经常在它们的领地上长途游荡寻找食物和狩猎。这种搜索可以是前往他以前有机会发现狩猎的地区,也可以是前往其领土内新的、没有在该地区获得狩猎和食物的地方进行搜索。在勘探阶段,我们受到美洲狮寻找食物的这些行为的启发。在这个阶段,美洲狮在自己的领地上随机搜索以寻找食物,或者随机靠近其他美洲狮并使用猎物。因此,美洲狮随机跳到搜索空间中或在美洲狮之间的空间中搜索食物。首先,整个种群按升序排序,然后美洲狮在勘探阶段使用等式25、56改进其解决方案:
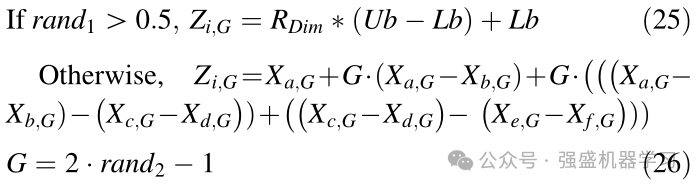
在等式(25)中,Ub和Lb是问题的下界和上界,RDim是在0和1的范围内随机生成的数字,并且在问题的维度上。rand1也是一个在0和1之间随机生成的数字。XaG、XbG、XcG、XdG、XeG和XfG是整个群体中的解,这些解是随机选择的面。G使用等式26计算。其中rand2是在0和1之间均匀分布的随机生成的数。根据等式25,选择两个方程中的一个来产生不同的解,然后应用生成的新解来改进当前解。
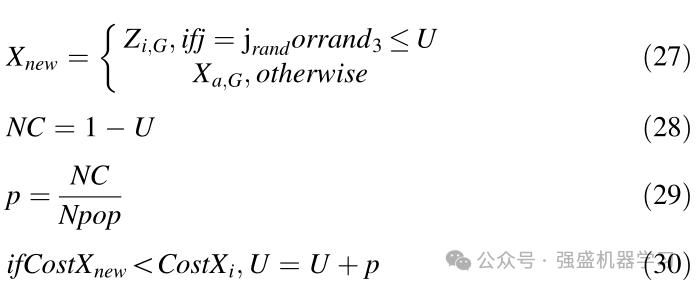
在等式27中,ZiG是使用等式(25)生成的解。jrand是问题维度范围内随机生成的整数。rand3也是在0和1之间产生的均匀分布中随机产生的数。NC也使用等式(28)进行计算。U是优化过程之前的参数集,其值是一个介于0和1之间的数字。在每次迭代中,根据等式32中的条件,被新解决方案替换的维度数量增加,并且这种增加是使用等式28-30完成的。在等式(29)中,Npop是美洲狮的总数。改进解决方案是根据方程(30)中的条件进行的,其中如果满足该条件,则仅更新解决方案的尺寸。这一行动避免了局部最优,并且产品解决方案具有良好的多样性。另一方面,在探索阶段解释的机制中,考虑到在探索阶段的每次迭代开始时,搜索代理根据其成本按升序排序,首先放置高质量的解决方案,然后根据等式28-30在开始时,由于U参数的值很小,所以质量解决方案不会发生很多变化。然而,后来,随着该参数的增加,在成本方面具有更高值的解决方案发生了许多变化,这种方法导致探索问题空间的更差解决方案,目的是在问题空间中找到重要的最优点。关键的一点是,如果产生的美洲狮不比目前的美洲狮好,则不会进行等式30,因为如果改进了,就没有必要增加多余的发现。但质量好的解决方案几乎没有变化,只是试图避免陷入局部最优的陷阱。最后,使用等式(31)将新生成的解替换为当前解。

根据等式(31),如果新的生产解决方案具有比当前解决方案更好的成本,则它将取代当前解决方案。
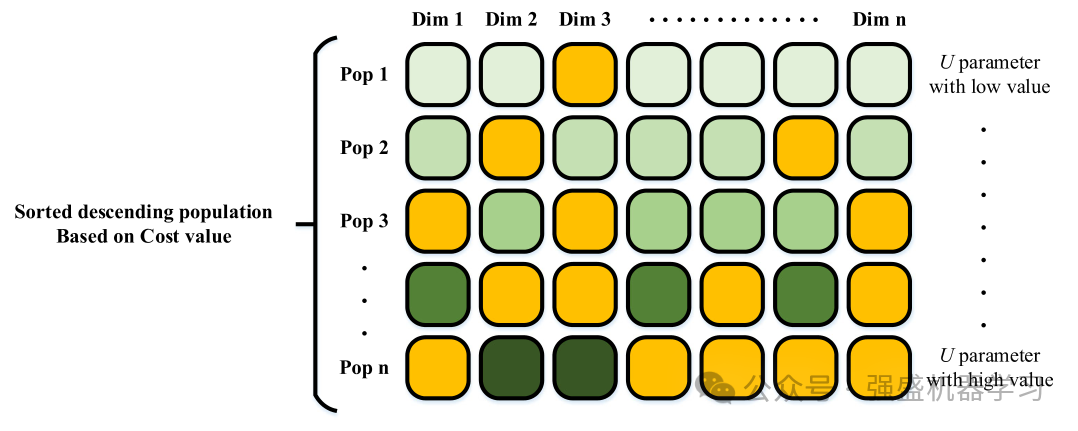
四、开发阶段
在开发阶段,PO算法利用两种不同的算子来改进解,这两种机制基于美洲狮的两种行为,即伏击狩猎和冲刺。在自然界中,美洲狮试图将猎物伏击在灌木丛或树木和岩石上。在某些情况下,它会追着猎物跑,这是使用该行为的等式(32)进行模拟的。

等式(32)显示了PO中使用的两种策略。考虑到在美洲狮中,为了在第一种模式下狩猎,在开发阶段,为了奔跑和伏击策略,使用了等式(32)中的情况1,并且一个师操作进行该操作以模拟美洲狮向猎物的快速奔跑。根据等式(32),如果rand5(0和1之间均匀分布的随机产生的数字)大于0.5,则执行快速奔跑策略,否则,选择伏击策略,伏击策略由两个不同的操作组成,第一个操作用于模拟美洲狮向其他美洲狮的狩猎短跳,第一只和第二只习惯于朝着最好的美洲狮狩猎方向跳远。
根据等式(32),均值表示均值函数,Soltotal表示所有解的总和,Npop是执行优化过程的总体数量。Xr1是整个群体中随机选择的解,b是随机产生的零或一。此外,Xi是当前迭代中的当前解,a和L是在优化过程之前必须调整的静态参数。此外,Pumamale是整个群体的最佳解,rand4、rand5、rand6、rand7、rand8和rand9是在0和1之间产生的随机数。此外,exp表示指数函数。randn1和randn2是正态分布和问题维度中随机生成的数字,Xr2是基于等式33选择的随机选择的解。
![]()
在等式(33)中,将X的每个元素四舍五入到最接近的整数,rand10是0到1之间随机产生的数字,Npop是美洲狮的总数。
最后,R、F1和F2分别通过等式34-36计算:
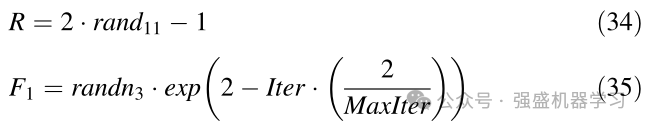
在等式(35)中,randn2是问题和正态分布维度上的随机数。Iter表示当前迭代次数,MaxIter表示执行优化操作的总迭代次数。exp表示指数函数。
![]()

在等式36-38中。randn4和randn5都是正态分布和问题维度中随机创建的数字。Cos表示余弦函数,rand12是0和1之间随机生成的数字。
最后,在该阶段结束时,如果新生产的解决方案的成本低于当前解决方案,则会对其进行更换。
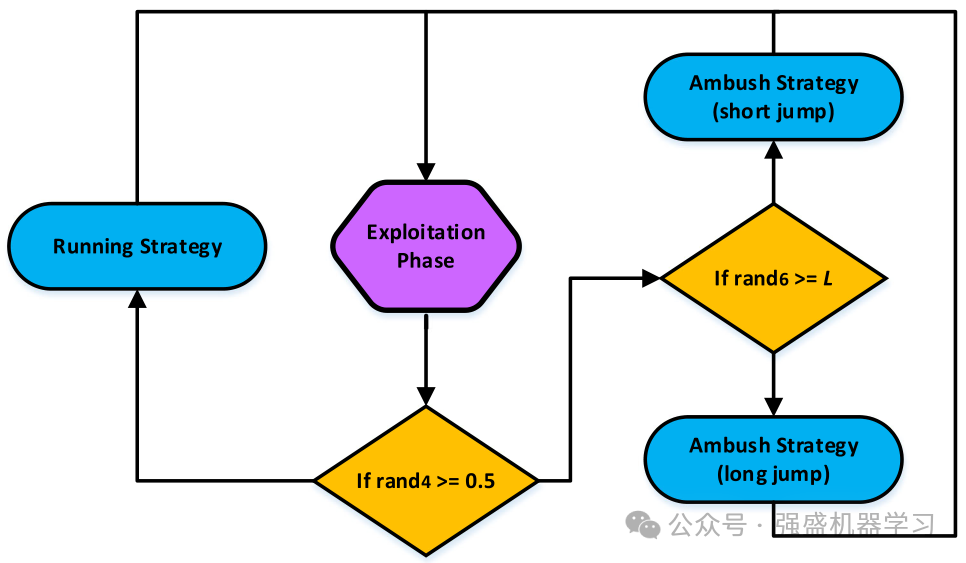
算法流程图与伪代码
为了使大家更好的理解,这边给出作者的流程图和伪代码,非常清晰!
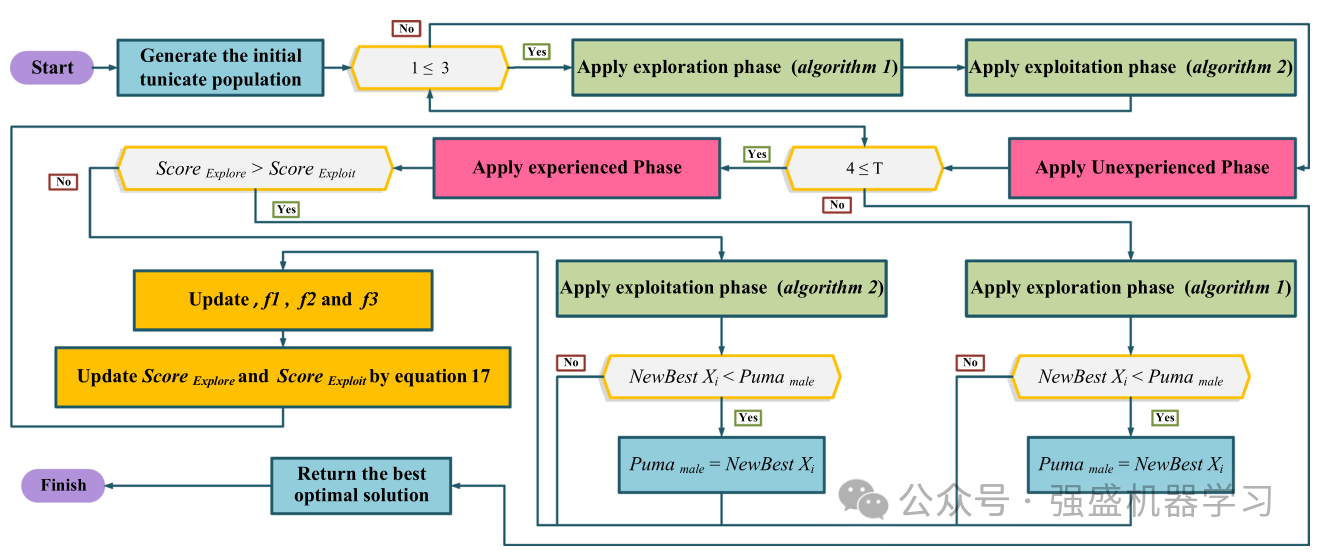

如果实在看不懂,不用担心,可以看下代码,再结合上文公式理解就一目了然了!
性能测评
原文作者采用23个标准函数和CEC2019函数对算法进行评价
这边为了方便大家对比与理解,采用23个标准测试函数,并与非常经典的鲸鱼算法进行比较,这边展示5个测试函数的图~
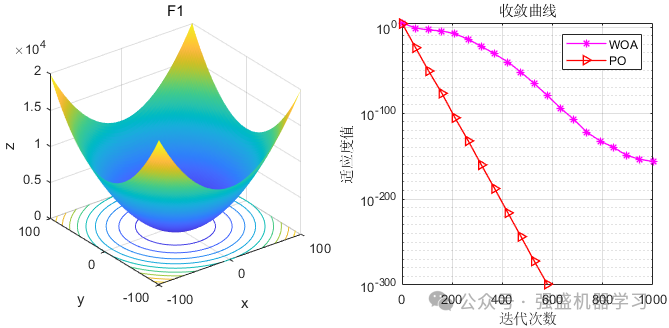
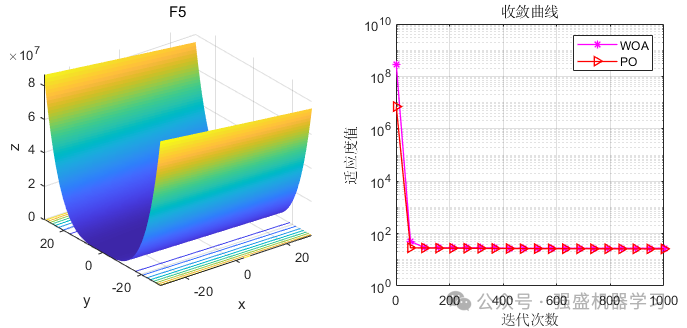
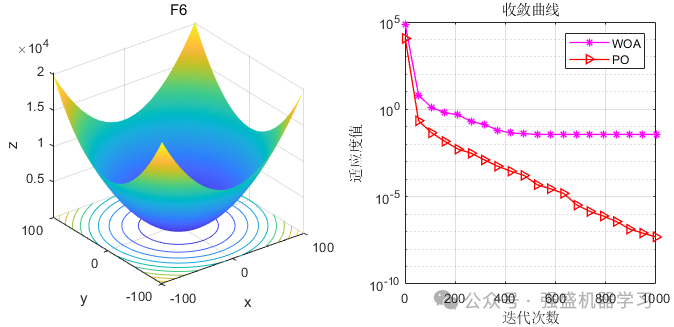
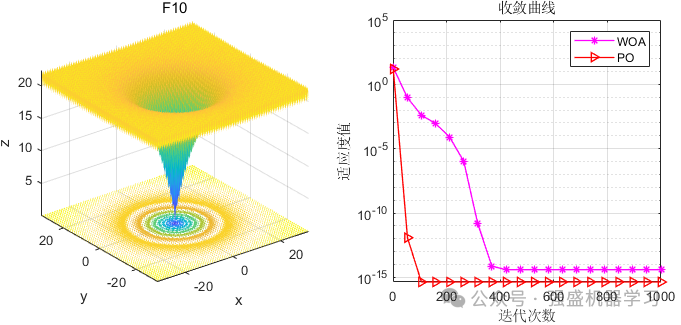
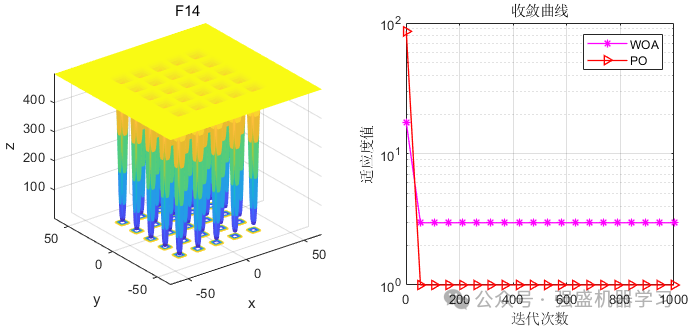
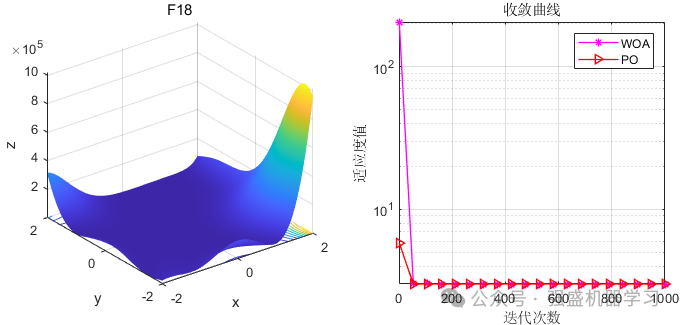
可以看到,PO的效果还是非常不错的!性能优越,收敛速度也非常快,可以较好的应用到各类实际问题应用中~
参考文献
[1]Abdollahzadeh B, Khodadadi N, Barshandeh S, et al. Puma optimizer (PO): a novel metaheuristic optimization algorithm and its application in machine learning[J]. Cluster Computing, 2024: 1-49.
完整代码
如果需要免费获得图中的完整测试代码,只需点击下方小卡片,后台回复关键字,不区分大小写:
PO
也可点击小卡片,后台回复个人需求定制PO优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、ESN等等均可~
2.组合预测类:CNN-SVM、CNN-LSTM/BiLSTM/GRU/BiGRU-Attention、Adaboost类、DBN-SVM等均可~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、CEEMDAN、ICEEMDAN、SVMD等分解模型均可~
4.其他:机器人路径规划、无人机三维路径规划、DBSCAN聚类、VRPTW路径优化、微电网优化、无线传感器覆盖优化、故障诊断等等均可~
5.原创改进优化算法(适合需要创新的同学):2024年的NRBO、CPO、SO、WOA等任意优化算法均可,保证测试函数效果!

















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









