







前言
关注👍部分!
引用格式:
[1] Kim H, Choi K-I, Choi S-I (2015) A Memory-Efficient Deterministic Finite Automaton-Based Bit-Split String Matching Scheme Using PatternUniqueness in Deep Packet Inspection. PLoS ONE10(5): e0126517. doi:10.1371/journal.pone.0126517
作者:
HyunJin Kim1, Kang-Il Choi2, Sang-Il Choi3*
1 School of Electronics and Electrical Engineering, Dankook University, Yongin-si, Republic of Korea,
2 Advanced Communications Research Laboratory, Electronics and Telecommunications Research
Institute, Daejeon, Republic of Korea, 3 Department of Applied Computer Engineering, Dankook University,
Yongin-si, Republic of Korea
- choisi@dankook.ac.kr
论文摘要
提出了一种用于深度包检测(DPI)的内存高效的位分割字符串匹配方案。当目标模式串的数量变得很大时,字符串匹配引擎的内存需求就成为一个关键问题。在基于确定性有限自动机(deterministic finite automaton, DFA)的位分割字符串匹配中,利用目标模式串的唯一性,提出的字符串匹配方案减少了内存需求。模式串分组从目标模式串中提取一组唯一的模式串。在一组唯一的模式串中,模式串不是任何其他模式串的后缀。因此,当在用一组唯一模式串构造的DFA中,一个输出状态下只能匹配一个模式串时。位分割字符串匹配采用具有多个输入位组的多个有限状态机(FSM)块,以减少存储状态转换的次数。但是,因为匹配向量中的每一位都用于标识其自身的模式串是否匹配,存储匹配向量的内存需求可能很大。
在本文,所提出的模式串分组被应用于位拆分字符串匹配中的多个FSM块。对于唯一模式串的集合,基于内存的位拆分字符串匹配引擎只存储每个状态的模式串匹配索引,以表示与自己的唯一模式串的匹配。因此,通过不在字符串匹配器中存储唯一的模式串集的匹配向量,内存需求大大降低。实验结果表明,与以前的位拆分字符串匹配方法相比,所提出的字符串匹配方案可以显著降低存储成本。
0. 总结
- 提出的字符串匹配方案可以应用于基于内存的位分割字符串匹配,消除对唯一模式串集的匹配向量,减少内存需求
- 提出的模式串分组是为了获得唯一模式串的集合
- 并行字符串匹配引擎采用了模式串划分和映射算法
- 所提出的字符串匹配方案具有位分并行字符串匹配引擎的规律性和可扩展性,大大降低了存储成本
1. 研究背景及依据
文献[6]提出了一个基于位匹配的字符串引擎,主要是将模式串的ASCII码按照两位进行拆分成4个输入位组,在4个FSM块上运行,用PMV表记录模式串匹配情况。

上图为文献[6]提出的高吞吐量体系结构的字符串匹配引擎。
- 左侧是完整的引擎结构,由一组规则模块组成。每个规则模块充当一个大型状态机,并且负责一组规则g。每个规则模块由一组块组成(该图四个片如上所示)。
- 右侧显示块的结构。每个块本质上都是一个表,具有一定数量的表项(此图中显示了 256 个表项),并且表中的每一行都是状态。每个状态都有一定数量的下一个状态指针(显示四个可能的下一个状态)和 长度为g的部分匹配向量。
规则模块在每个周期采用一个字符(8 位)作为输入,并输出每个切片的部分匹配向量的逻辑 AND 运算结果。
2. 提出的方法
本文基于文献[6]提出的方案进行改进,将模式串进行分组以减少内存需求。
2.1 👍算法架构

- 有四个FSM块,每个DFA都有两位的输入。
- 一个FSM块的输入可以从字节输入的mbs(最有效位)和lbs交替选择两个bit。
本文提出的架构似乎与[6]提出的没有区别?
仔细看该架构分为两个部分:
- Non-unique String Matchers的确与[6]提出相同;
- Unique String Matcher却有不同,请看FSM块处的PMI,这是Unique String独有的,也是本文的关键处。
👍 Unique String Matcher只需要PMI就可以找到匹配模式串,而Non-unique String Matchers在本文中另需一块内存存储PMV进行AND运算得到匹配结果。
非唯一模式串集合的字符串匹配器中的FSM块

- 每行表示一个状态,其中存储状态转换和 状态的vertor指针。
- 每个状态中的vector指针表示它在单独的PMV表中的PMV。
- 第一行的数字分别表示状态转换指针、vertor指针和PMV的大小。
- 参数S表示FSM块最大状态数;参数P表示字符串匹配器中映射模式串数。
- 该FSM块利用有效负载的部分输入,选择下一个状态转换,下一个状态转换意味着FSM块中下一个状态的地址。
唯一模式串集的字符串匹配器中的FSM块

- 每个FSM块中只存储每个状态的唯一部分匹配索引(PMI),以显示匹配的模式串。
- 比较FSM块上的PMIs,检查所有的PMIs是否相等; 如果所有的PMI都是相同的,则生成的匹配索引指向匹配的模式串。
2.2 👍模式串分组
本节通过举例子说明,原始模式串集为{abcd,abfg,cfg,fg,d,cd}。
unique pattern和non-unique pattern是什么?
非唯一模式串是其他模式串的后缀。
- 当非唯一模式串集合中的模式串数量为N时,需要N个比特来表示哪些模式串被匹配。
Eg. 非唯一的模式串集合为{abcd,cd,d,fg} ,其中{cd,d}是模式串“abcd”的后缀。
唯一模式串不是任何模式串的后缀。
- 在唯一模式串集合中一个状态下只有一个模式串被匹配,只需要二进制索引来表示一个状态的模式串被匹配。
- 如果一个集合中有N个唯一模式串,二进制索引的大小为 l o g 2 N log_2N log2N。
举个简单分组例子

- 模式串 "fg"和"cd"分别是 "abfg "和 "abcd "的后缀,排除{“fg”、“cd”、“d”},那么{“abcd”、“abfg”、“cfg”}是唯一模式串的集合。
- 这些被排除的模式串可以是具有非唯一模式串的集合的元素,因为 "d "是 "cd "的后缀,换句话说,模式串 "d "和 "cd "都是非唯一的模式串。
但是本文是基于位匹配,需要基于ASCII码分组!
分组依据
先看一下位分割字符串匹配引擎架构图,可以看到每个块输入两位(i,j),i和j是ACII码中LSB输入符号位的位置。
可以看出来下图中的字符串匹配器应该是非唯一模式串的,因为需要存储PMV向量,最后FMV是通过PMV的位AND运算而来。

下面我们来了解一下 (i,j) 如何取值?
在文中是按ASCII码根据LSB(最低有效位)第 i 位与第 (7−i) 位取值,例如第一个FSM块(7,0)。
举个例子,为啥上面说基于ASCII码分组会不同?
还是同一个原始模式串集{abcd,abfg,cfg,fg,d,cd},唯一模式串集{abcd,abfg,cfg}
先查看各字符的ASCII码:
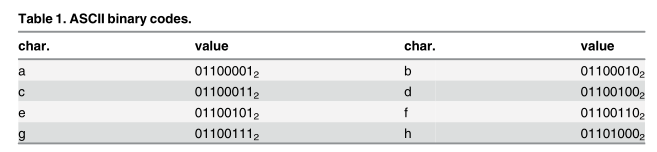
再看,根据LSB对输入位取值后的{abcd,abfg,cfg}向量:
👍 abcd中的pattern(7,0)=01->00->01->00怎么来的?
取abcd的各ascii的第7位和第0位(从最低位开始数)

画红框的部分表明:当pattern(4,3)时,abfg和abcd相同,因此abcd和abfg不是unique pattern;再看cfg是abfg和abcd的后缀,因此cfg也不是unique pattern!
但如果有一组模式串{“abfh”和“cfg”},如下表所示,没有“cfg”的pattern(i, j)是“abfh” pattern(i,j) 的后缀。
因此,对于两bit向量匹配的位拆分字符串,“abfh”和“cfg”是示例中的唯一模式串。

通过上面的例子应该了解了基于位的模式串分组跟基于字符的的不同了,下面讲述关于分组实现的算法。
分组实现算法
所有模式串分组为唯一模式集T-unique和非唯一模式集T-nonunique,便于后续将这两个集合映射到两种不同类型的字符串匹配器上。

- 模式串集T按照长度 升序 排序。
- 检查模式串t在一组模式串T中是否唯一,如算法第6行中的 Is_Unique(t, T)函数。
- 每检查一个模式串便剔除,如算法的第5行。
- 如果模式串 t 是唯一的,则它成为唯一模式串集合T-unique中的元素;
- 否则,模式串 t 成为具有非唯一模式串Tnon−unique集合的元素
重复for循环至初始模式串集合T为空,那就代表所有模式串都分组了。
DFA构成区别
了解一下,分组对DFA构成的影响:


- 图2(上图)是由初始模式串集构成的DFA,但省略了失败指针。
- 图3(下图)是对初始模式串集进行分组后,得到非唯一模式串集和非唯一模式串集构成的DFA。
可以看出来,分组后唯一模式串集构成的DFA的输出状态只有一种模式串!
下面了解一下模式串如何划分以及映射到字符串匹配器中。
2.3 👍模式串划分和映射实现

模式串划分算法: 使用唯一模式串集和非唯一模式串集
T
u
n
i
q
u
e
T_{unique}
Tunique和
T
n
o
n
−
u
n
i
q
u
e
T_{non-unique}
Tnon−unique及其字符串匹配器参数
M
u
n
i
q
u
e
M_{unique}
Munique和
M
n
o
n
−
u
n
i
q
u
e
M_{non−unique}
Mnon−unique作为模式串划分的输入参数。
两个while循环用于划分每个集合中的模式串:
- 对于唯一模式串集:
- 首先,按字典顺序排序。
- 然后,调用一个名为Pattern_Mapping的过程,获取字符串匹配器fsms的FSM块内容。
- 此外,还返回未映射的模式串 T u T_u Tu。字符串匹配器的FSM块内容存储在 v e c _ f s m s u n i q u e vec\_fsms_{unique} vec_fsmsunique中。
- 重复此唯一模式串集的循环,直到不再有未映射的唯一模式串。
- 对于非唯一模式串集:
- 首先,对模式串集T剩下的模式串按字典顺序排序。
- 然后,调用Pattern_Mapping获取非唯一模式串集的FSM块内容fsms。
- 返回未映射的模式串 T u T_u Tu。字符串匹配器的FSM块内容存储在 v e c _ f s m s n o n − u n i q u e vec\_fsms_{non-unique} vec_fsmsnon−unique中。
- 重复循环,直到没有模式串需要映射。
最后,返回FSM块内容 v e c _ f s m s u n i q u e vec\_fsms_{unique} vec_fsmsunique和 v e c _ f s m s n o n − u n i q u e vec\_fsms_{non-unique} vec_fsmsnon−unique给采用的多个字符串匹配器。
模式串映射的过程Pattern_Mapping:
可以根据[6]中的字典排序为字符串匹配器生成FSM块内容。在模式串映射中,会考虑几个硬件资源限制,比如要映射的模式串的最大数量P和状态S。模式串映射将映射到字符串匹配器的模式串数量最大化,如下所示:
- 首先,已排序的模式串集作为这个过程的输入,用从输入集中确定的前k个模式串构建FSM块的内容。
- 在第一次迭代中,k设为P。如果得到的FSM块的DFAs的状态个数大于同构FSM块的状态个数S,则不能将这些模式串映射到字符串匹配器上。在这种情况下,将k减1后,继续迭代,直到每个FSM块所需的状态数小于S为止。
- 迭代完成后,进行失败指针的添加。
- 最后,返回字符串匹配器的未映射的目标模式串和FSM块的内容。
3. 实验
实验表明本文提出的方法可以有效地减少内存需求。实验中采用了Snort和ClamAV规则集。此外,还使用几个统计生成的规则集来分析模式唯一性。
3.1 实验环境
A. 硬软环境
C++库
模式分组和映射运行环境:英特尔 Xeon E31270 CPU、8 GB主内存和CentOS 6.5 Linux操作系统
B. 测试模式串集合
- Snort v2.8规则中提取了四组目标模式串,分别表示backdoor、deleted、spyware、web-client
- 所有Snort v2.8规则中提取了一组总模式串total
- ClamAV 0.95.3中的一个规则集,称为ClamAV
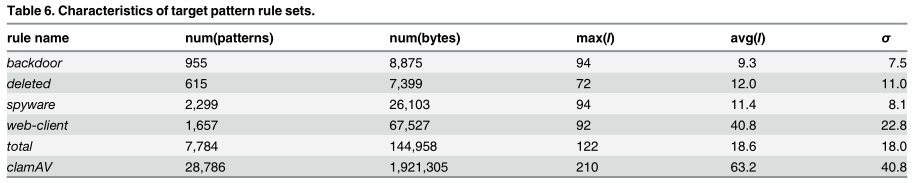
C. 模式串特征
- num(patterns)和num(bytes)分别表示目标模式串的数量和每个规则集的字符总数;
- max(l)和avg(l)分别为最大模式串长度和平均模式串长度;
- 最右边的列(σ)描述了模式串长度的标准差。
3.2 👍实验结果
Snort和ClamAV规则集的实验
内存单元需求数量
根据硬件限制和内存单元的单位大小,需要内存单元的数量:

- 与非唯一模式串集相比,唯一模式串集的字符串匹配器可以减少内存需求。
- 内存需求并没有随着P的增加而成比例增加,说明唯一性PMIs的内存需求较小。
模式串数量
六个规则集根据分组算法得到两个集合的模式串数量:
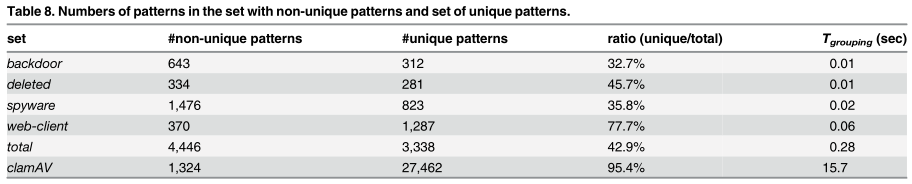
- 规则集中唯一模式串占所有目标模式串的比例为32.7% ~ 95.4%。
- 与之前的位分割字符串匹配[6]相比,模式串分组需要额外处理时间。所有Snort规则集的模式串分组在1秒内完成;对于ClamAV规则集,在模式串分组中需要的时间为15.7秒。
最小化的内存需求包含要映射模式串的最大数量P,以及不同内存单元大小的字符串匹配器的数量:

- 当存储单元的单位大小为1Kbits时,由于未使用的内存bit最少,因此内存需求最小。
- 对唯一模式串集:当P分别为16和32时,内存需求最小。
- 对非唯一模式串集:
- web-client和clamAV的非唯一模式串集,因平均模式串长度较长,P值分别为16和32时,所需内存最小。
- 其他Snort规则集的非唯一模式串集,由于平均模式串长度较短,P值为32或64,所需内存最小。
降低内存需求
本文提出的方案可以显著降低位分割字符串匹配体系结构的内存需求:
在使用1-Kbit和4-Kbit内存单元的情况下与[6,8 - 10]中的字符串匹配方案bit_split、ex_bit_split、shared和hetero标准化内存需求相比:
规则集的标准化内存需求=最小化的内存需求 / 规则集目标模式串的总字节数之和,单位为bytes/char
- 内存单元为1Kbit,标准化的内存需求范围为14.3到23.6(bytes/char)。
- 内存单元为4Kbit,标准化的内存需求范围为17.2到28.4(bytes/char)。
👍 由于未使用的内存bit 随着存储单元的单位大小而增加,标准化内存需求随着存储单位大小而增加。
- 使用1Kbit内存单元时,总内存需求相比于其他方案平均降低了31.8%、14.7%、8.0%和12.4%
- 使用4Kbit内存单元时,总内存需求相比于其他方案平均降低了29.8%、36.0%、19.1%和30.1%
👍 当存储单元较大时,本文所提出的字符串匹配方法更有效。


模式串唯一性实验
这里不做赘述了,大概就是生成几个具有随机模式串的规则集,进行结构和统计分析。 通过平均模式串长度、标准偏差和目标模式串数等几个参数来进行评估。
最后得出的结论:在一般规则集中唯一模式串占比较高,因此采用模式串分组实现减少内存是可行的。
本文关键reference
[6] Tan L, Brotherton B, Sherwood T. Bit-split string-matching engines for intrusion detection and prevention. ACM Transactions on Architecture and Code Optimization (TACO). 2006; 3(1):3–34. doi: 10.1145/1132462.1132464
















 1926
1926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











