







目录
0. 数据集CIFAR10
以数据集CIFAR10为例,搭建网络模型进行训练、验证。

pytorch上关于CIFAR10数据集的文档:
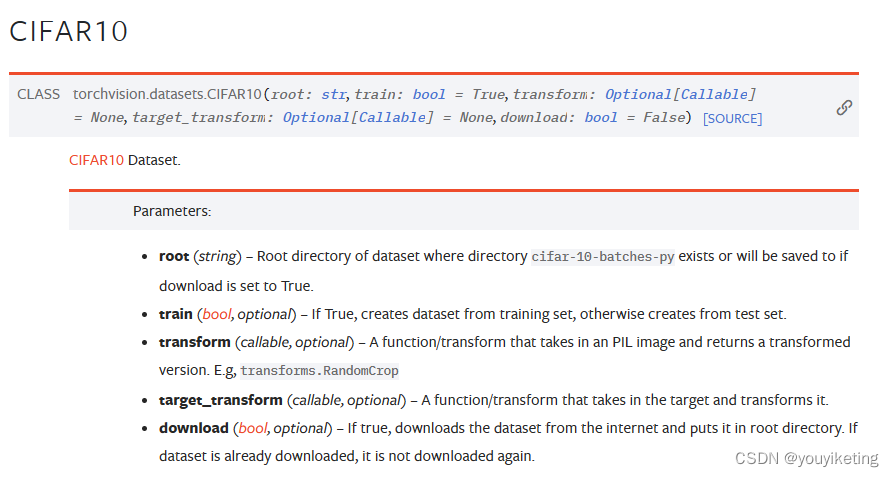
获取数据集:
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)debug结果: 可获取数据集 class 与 targets (即label)的关系。

1. 神经网络模型训练套路:
step1. 准备数据集dataset,及数据加载dataloader
step2.搭建网络模型
step3.创建损失函数、优化器
step4.设置训练参数(epoch..)
step5.网络进入训练状态(调用model.train())
(1) 从train_dataloader中加载数据
(2) 计算损失函数
(3) 反向传播,优化器优化
(4) print, tensorboard 展示输出
step7. 每个epoch训练完成后,网络进入测试状态(调用model.eval())
(1) 在with torch.no_grad下进行(只测试,无梯度优化)
(2) 从test_dataloader中加载数据
(3) 计算指标(loss,acc),展示模型效果
step8. 保存模型
PS: model.train() 和model.eval() 只对特定层作用,故可不调用,但网络中出现特定层时,必须调用。


1.1 网络模型搭建:
参考的网络模型结构:
(from:)https://www.researchgate.net/publication/312170477_On_Classification_of_Distorted_Images_with_Deep_Convolutional_Neural_Networks

import torch
from torch import nn
# 搭建神经网络
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=64 * 4 * 4, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self, x):
x = self.model(x)
return x
# # 验证模型是否搭建正确:4维张量(64,3,32,32) -> model -> 2维张量(64,10)
# if __name__ == '__main__':
# myModel = MyModel()
# input = torch.ones((64, 3, 32, 32))
# output = myModel(input)
# print("output.shape: ", output.shape)
#1.2 网络模型训练:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from Mymodel_CIFAR10 import * # 搭建的神经网络模型
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("train_data_size: {}".format(train_data_size))
print("test_data_size: {}".format(test_data_size))
# Dataloader 加载数据
train_data_loader = DataLoader(train_data, batch_size=64)
test_data_loader = DataLoader(test_data, batch_size=64)
# 搭建网络模型
myModel = MyModel()
myModel.to(device)
# 损失函数--交叉熵
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(myModel.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 30
# 添加tensorboard
writer = SummaryWriter("train_logs")
for i in range(epoch):
print("-----------------第{}轮训练开始--------------------".format(i+1))
# 训练步骤开始
myModel.train()
for data in train_data_loader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myModel(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清0
loss.backward() # 调用损失,反向传播
optimizer.step() # 对每一步进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始:
# 每跑完一轮,用测试数据测试模型,以测试数据损失及正确率评估该模型是否训练好
myModel.eval()
total_test_loss = 0
total_acc_sum = 0
with torch.no_grad():
for data in test_data_loader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = myModel(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
acc_sum = (outputs.argmax(1) == targets).sum()
total_acc_sum = total_acc_sum + acc_sum
print("整体测试数据集上的Loss: {}".format(total_test_loss))
print("整体测试数据集上的acc: {}".format(total_acc_sum/test_data_size))
total_test_step = i
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_acc", total_acc_sum/test_data_size, total_test_step)
# 法(一):保存模型+训练参数
torch.save(myModel, "saved_models/myModel_{}.path".format(i))
# # 法(二):仅保存模型参数
# torch.save(myModel.state_dict(), "myModel_{}.path".format(i))
print("模型已保存")
writer.close()
1.3 GPU加速:
将网络模型、输入数据(图片和label值) 、损失函数 加载至cuda上。
法(一):
# 网络模型
myModel = MyModel()
if torch.cuda.is_available():
myModel = myModel.cuda() # 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()# 输入数据(图片+label值)
for data in test_data_loader:
if torch.cuda.is_available():
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()法(二):
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 网络模型
myModel = MyModel()
myModel.to(device)# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)# 输入数据(图片+label值)
for data in test_data_loader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)1.4 网络模型保存
法(一)
# 模型保存方式1:模型结构+训练参数
torch.save(myModel, "save_models/CIFAR10model_save1.path")法(二)
# 模型保存方式2:模型训练参数(官方推荐)
torch.save(myModel.state_dict(), "save_models/CIFAR10model_save2.path")
1.5 训练结果
(30 个 epoch)



2. 神经网络模型验证套路
step1. 准备用于验证的图片
step2. 对验证图片进行transform预处理,以满足网络模型的输入要求
step3. 加载保存的网络模型
step4. 调用model.eval(),进入验证状态
(1) 在with torch.no_grad下进行(只测试,无梯度优化)
(2)输入验证图片,验证预测结果
2.1 网络模型加载
法(一):对应 模型保存方式1:模型结构+训练参数
# 模型结构+模型参数
model1 = torch.load("save_models/CIFAR10model_save1.path")
print(model1)
法(二): 对应 模型保存方式2:训练参数
# 模型参数
model2 = MyModel() # 定义网络模型结构
model2.load_state_dict(torch.load("save_models/CIFAR10model_save2.path"))
print(model2)2.2 网络模型验证
在网上下载一个小狗图片作为验证图片:

验证代码:
import torch
import torchvision.transforms
from PIL import Image
from Mymodel_CIFAR10 import * # 搭建的神经网络模型
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# CIFAR20: class_to_idx
class_to_idx = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# 准备用于验证的图片
image_path = "imgs/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB') # png图片是4通道
print(image)
# 对验证图片进行预处理,满足网络模型输入要求
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
image = torch.reshape(image, (1, 3, 32, 32)) # 3维张量[3,32,32] -> reshape -> 4维张量[1,3,32,32]
print(image.shape)
# 加载保存的网络模型
# (一)模型+模型参数
model = torch.load("saved_models/myModel_29.path") # GPU网络模型
# # (二)模型参数
# model = MyModel( ) # 定义网络模型结构
# model.to(device)
# model.load_state_dict(torch.load("myData_0.path"))
print(model)
# validate
model.eval()
with torch.no_grad():
image = image.to(device) # 将输入数据加载为GPU数据类型
output = model(image)
output_target = output.argmax(1).item()
print("scores: ", output)
print("prediction target: ", class_to_idx[output_target])
验证结果:

感谢B站的小土堆导师,入门啦入门啦!














 2537
2537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









