






 本文介绍了一种使用图神经网络(GNN)的捆绑推荐与生成方法。BGCN模型解决了用户与捆绑包交互信息稀疏的问题,通过异构图传播捕获用户偏好和捆绑包关联性。BGGN模型则通过图生成策略,考虑item间高阶关联,以生成多样性的捆绑包。模型训练中采用了硬负样本策略,提高推荐准确性。
本文介绍了一种使用图神经网络(GNN)的捆绑推荐与生成方法。BGCN模型解决了用户与捆绑包交互信息稀疏的问题,通过异构图传播捕获用户偏好和捆绑包关联性。BGGN模型则通过图生成策略,考虑item间高阶关联,以生成多样性的捆绑包。模型训练中采用了硬负样本策略,提高推荐准确性。
目录
原文:Bundle Recommendation and Generation with Graph Neural Networks
Introduction
bundle旨在推荐一个捆绑项目,从而让用户捆绑消费。Bundle也就是捆绑包,把多个相似或是互补的项目捆绑起来,来满足用户的复杂需求。类似于市场营销中的捆绑营销策略,如套餐、搭配购买价格更低、赠送赠品等。好的捆绑能够提升用户体验、激发购买欲望、满足更多需求。在电子商务等平台上,捆绑推荐成为一项重要任务。因此在构建捆包时,需要考虑包中物品的吸引力,如何最大化满足用户需求,捆绑包的语义表达(如捆绑包整体的信息,捆绑包的特征)
而由于这是一种较新的交互形式,用户和捆绑包之间的交互信息较少,因此在推断用户偏好时也存在较大困难。一般而言bundle recommendation可以分为两类:1、向用户推荐平台的预构建包(bundle推荐);2、为用户生产个性化捆绑包(bundle生成)
bundle推荐需要预测用户对于与构建的捆绑包的喜好。需要额外使用用户对物品的交互信息以及捆绑包和物品的附属信息作为辅助。bundle生成则是根据用户对现有捆绑包的喜好,生成一个最大满足用户喜好的捆绑包。因此,用户与捆绑包的交互信息较为重要。
本文中,根据以上两种方式分别给出了两种GNN模型,BGCN与BGGN。
Bundle Recommendation
preview
目前已有的工作中,通常把捆绑推荐分解为两个分离而独立的任务,通过共享参数来联系两个任务。在(Matching user with item set: collaborative bundle recommendation with deep attention network)中(DAM),提出了一个多任务框架,以多任务学习的方式结合了user-bundle的交互和user-item的交互,能够很好地缓解user-bundle交互的稀疏性。但仍然存在一些缺陷:
- 关联的实体分离建模。没有明确user、item、bundle之间的关系,并且难以平衡主辅任务的权重分配;
- 忽视了bundle之间的关联性,忽视了bundle的可替换关系;
- 忽视了user-bundle交互时的决策。用户喜欢捆绑包中的大多数项目,但仍然会因为一个不喜欢的项目而拒绝捆绑包
为了解决上述局限性,提出了BGCN,将user、item、bundle三种结点统一到一个异构图(heterogeneous graph)中,并以item为桥梁,链接user-bundle;图中的bundle-item-bundle反映了bundle的替换关系;添加hard-negative样本的训练,进一步探讨用户决策。
Problem Formulation
U
:
U:
U: 用户集合,大小为
M
M
M
B
:
B:
B: 捆绑包集合,大小为
N
N
N
I
:
I:
I: 物品集合,大小为
O
O
O
三者的交互矩阵为
X
M
×
N
,
Y
M
×
O
,
Z
N
×
O
X_{M\times N} ,Y_{M\times O} ,Z_{N\times O}
XM×N,YM×O,ZN×O,分别表示,user-bundle、user-item、bundle-item间的交互。
I
N
P
U
T
:
INPUT:
INPUT:
X
,
Y
,
Z
X,Y,Z
X,Y,Z
O
U
T
P
U
T
:
OUTPUT:
OUTPUT: 估计user与bundle交互的概率的模型
Methods
模型主要包含三个部分:异质图的构建,信息传播,硬负样本的训练
Heterogeneous graph construction
图 G = ( V , E ) G=(V,E) G=(V,E),结点 V V V包括三种(user、bundle、item), E E E也包括三种。对于三种结点,都采用one-hot编码,并且将其压缩为实值向量:
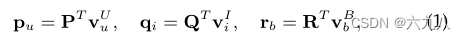
其中
v
u
U
v_u^U
vuU表示用户u,其他同理。
P
,
Q
,
R
P,Q,R
P,Q,R为embedding矩阵
Level propagation
Item level propagation
用户对于物品的偏好可以影响用户对捆绑包的兴趣。因此为了捕捉用户对物品的偏好和物品本身的特征,在user-item间构建一个传播层,并且从item级别获取到bundle的部分语义信息。
更新规则如下:
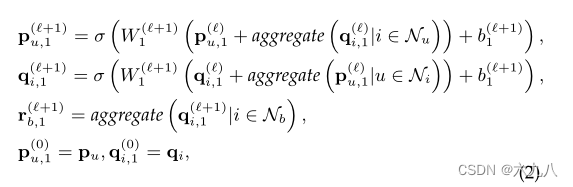
一行一行看上面的公式:
- user结点聚合邻居item结点的信息
- item结点聚合邻居user结点(第一步聚合过item后)的信息
- bundle聚合邻居item(第二步聚合过user后)的信息
- 初始化
Bundle level propagation
具有共享物品的捆绑包通常较为相似,相似性可以用共享物品的数量进行度量。设计了一个bundle-user的传播模块,来学习用户对捆绑包的偏好,并且在bundle-item-bundle路径上进行信息传播,来捕捉捆绑包之间的相似性。
更新规则如下:
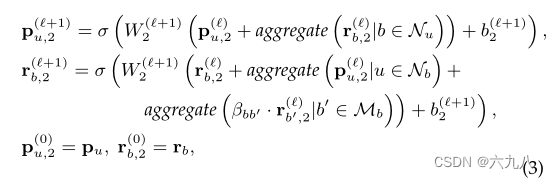
一行一行看上述公式:
- user聚合bundle信息
- bundle聚合user信息,并且聚合有相同item的bundle的信息(存在bundle-item-bundle链接)
- 初始化
Prediction
经过 L L L层的传播,得到了 L L L个user和bundle的embedding,将所有层的embedding连接起来,组合不同深度的邻居接收到的信息进行预测:
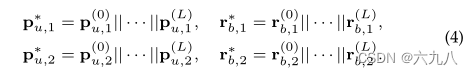
连接以后,采用内积进行最终预测:
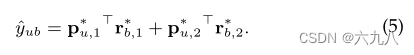
上式中,将两层传播的user、bundle的embedding作内积运算,得到预测结果
Training with hard negatives
由于捆绑包包含的物品更多,价格也更高,用户在捆绑包场景中做出决策或花钱时通常会保持谨慎,以避免不必要的风险。例如,即使用户喜欢捆绑包中的大多数项目,但可能会因为存在一个不喜欢的项目而拒绝捆绑包。对于两个高度相似的捆绑包,用户最终选择的关键是它们的非重叠部分。
为了优化我们的BGCN模型,并考虑用户在与包交互时的决策,设计了一种基于硬负样本的学习策略。在模型收敛后,以一定概率引入硬负样本进行更详细的训练。因此,将目标函数定义如下
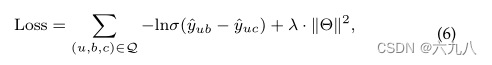
其中
Q
Q
Q表示具有负采样的成对训练数据
(
u
,
b
,
c
)
(u,b,c)
(u,b,c),
Q
=
{
(
u
,
b
,
c
)
∣
(
u
,
b
)
∈
Y
+
,
(
u
,
c
)
∈
Y
−
}
Q=\left\{ (u,b,c)|(u,b)\in Y^+,(u,c)\in Y^-\right\}
Q={(u,b,c)∣(u,b)∈Y+,(u,c)∈Y−},对于每一个三元组,c为hard negative,表示没有和u交互过的bundle,但是c中含有许多与u交互过的item,或是与b有重叠。
这个
L
O
S
S
LOSS
LOSS的意义主要在于,最小化损失函数,可以拉大正样本(ub有交互)和负样本(uc无交互)之间的差距
model
总体的模型图如下所示:
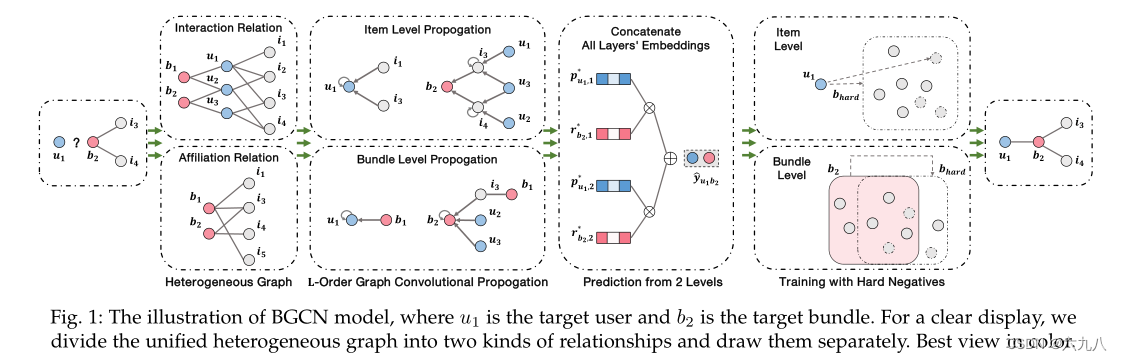
构建图的 → item级别信息传播 → bundle级别信息传播 → 得到embedding → embedding连接并做内积运算预测 → 采样硬负样本,引入训练 → 模型收敛,输出
Bundle Generation
preview
目前大多数工作仅仅解决单个bundle的生成,在最近的研究中,提出了生成bundle list的方法,将bundle生成作为一个结构预测问题。将bundle作为一个序列,内部的项目根据价格进行排序。这种方式主要存在三大局限性:
- 生成受序列顺序的影响。由于是按照价格排序的,因此在bundle中,两个相关的item有可能距离很远
- 只能生成较小的bundle。由于基于序列的方法(如RNN和LSTM)的长期瓶颈,它倾向于生成短句
- 无法区分item间的高阶关联。一个bundle中,并不是所有item都有直接关系,两个item可以通过一个中间item相连
为了解决这些局限性,提出了BGGN。利用图神经网络从复杂拓扑和高阶连通性中学习的强大能力,BGGN明确量化了bundle中item之间的直接和间接关系:a)将bundle构造为item为结点的图,并以自回归方式逐步生成图;b) 在每个生成步骤中,通过生成的图和检索到的节点之间的嵌入传播来预测下一个与生成的bundle密切相关的item;c) 通过在图上进行beam search(十分钟理解Beam search),提高了生成过程的鲁棒性和生成结果的多样性。
根据已有的bundles去生成类似的bundles
Method
模型主要分为三个部分:构造bundle graph、结点检索、边的构造
Bundle Graph
由于在大型的bundle中,item数量较多,构造为图比较困难(本人感觉在现实生活中,这么大型的捆绑包应该是极少数的)。并且一个bundle中并不是所有item是直接相关的,直接构造边不合理。
基于用户的监督信号,构建了bundle graph。基于bundle的popularity以及item共同出现的频率,来计算item-item的关联度。再利用伯努利分布,把bundle中每个关联度转换为0/1值,来判定两个item之间是否存在边。
计算关联度公式如下:
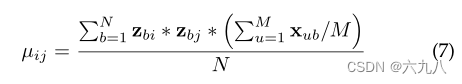
Nodes Retrieval
图生成的本质是预测邻接矩阵中可能的元素1 。由于item和bundle的数量不对等,在生成一个bundle时,如果把成千上万的item都作为候选项,那将产生巨大的消耗。
首先进行抽样,得到和bundle中item数量相同的负样本item,再根据BPR框架,采用下列公式获得候选item(拉大正负样本的距离,内积为计算评分):
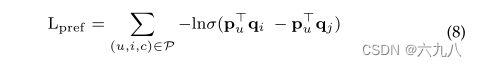
得到检索的结点集:
I
u
I_u
Iu,维度为
η
\eta
η
Edge Construction
使用GCN来学习bundle graph中的结构信息和高阶item-item关系。使用生成的图作为条件,采用自回归的方法从上一步获得的items中,逐步选择结点来构造边
每一步从
I
u
I_u
Iu中搜索最优item,再替换L中item
initialization
初始化
L
b
L_b
Lb,维度与
I
u
I_u
Iu一致,为
η
×
η
\eta\times\eta
η×η。生成
L
b
L_b
Lb的概率表示为:
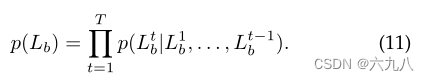
p
(
L
b
t
)
p(L_b^t)
p(Lbt)表示当前时刻生成某一个item的概率,其受到之前已生成的所有item的影响
embedding layer
将检索到的item表示为:
h
i
=
H
T
v
i
I
u
h_i=H^Tv_i^{I_u}
hi=HTviIu
H
H
H用于捕捉item之间的相关性
-
构建增广图 G ~ \tilde G G~:已构建的图G 加上 I u I_u Iu中的其他结点 I x I_x Ix,并将 I x I_x Ix中的结点与图G中的结点两两连接
-
采用GCN学习增广图 G ~ \tilde G G~的信息,得到每个item的embedding
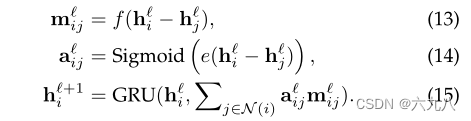
edges probability
经过GCN提取信息后,得到新的embedding: h i L h_i^L hiL,通过混合伯努利分布,计算每个item和当前图G生成边的概率:
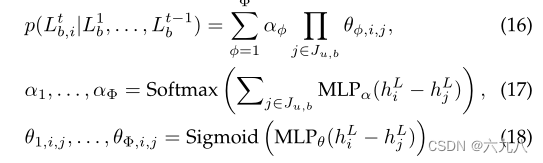
J
u
,
b
J_{u,b}
Ju,b为当前生成的图G中的结点集合
search and stop
计算新结点分数:新item和当前图与user的匹配分数+新item与其他item的匹配分数
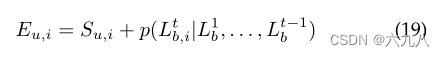
选取前w个分数高的结点作为备选
graph score
将w个结点分别与图G构造出w个子图,计算图分数,选择图分数最高的k子图,进入下一步循环。
图分数:更新后的图与user的匹配分数+更新图与内部item的匹配分数(密度,密度越大,item间的相关性就越高):
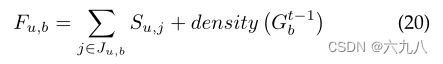
找到最大的
F
u
,
b
F_{u,b}
Fu,b对应的item的下标,成为当前步骤生成的结点(在
L
b
L_b
Lb与当前步骤行交换)。
diversified search
上述机制倾向于生成类似的bundle,为了使生成的bundle更具多样性,这篇文章提出了diversified beam search方法,将bundle划分为若干个group,再group之间实现多样性。
在原来的结点分数
E
u
,
i
E_{u,i}
Eu,i加入结点使用次数,实现更多的结点能够加入bundle:
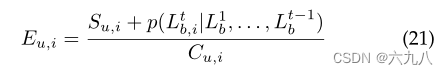
adaptive stop
特殊停止准则:基于PMF,或当图密度小于某个阈值时停止
model
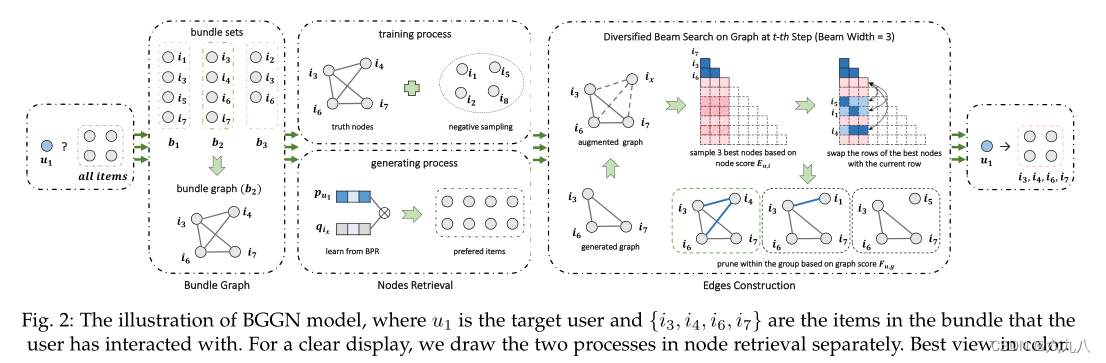
构建bundle图,加入负样本进行采用BPR训练,筛选出排名较前的item,进入循环:构建大小已知的
L
b
L_b
Lb(全填充0),每一行代表一个对应的item → 在当前行:构建增广图 → GCN得到embedding → 根据伯努利分布计算每个item与当前图生成边的概率 → 计算结点分数并选择前w个 , 分别构建新的图G → 计算新图分数,选择分数最大的新图,并把新加入的结点放入当前行 → 继续循环。


















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









